一种基于RS数据流的卷积硬件加速器及其方法
一种基于rs数据流的卷积硬件加速器及其方法
技术领域
1.本发明涉及一种基于行固定(rs)数据流的卷积硬件加速器架构及其方法,属于硬件加速神经网络的技术领域。
背景技术:
2.近些年来,随着计算机科学与互联网技术的发展,世界数据规模呈爆发式增长,人工智能也从早期人工特征工程到能够从大量数据中学习的转变。受脑神经学科的启发,经过许多年的演变而形成的神经网络模型在机器学习领域取得了很大的成效,并在计算机视觉、语音识别和自然语言处理等领域得到广泛应用。
3.为了处理复杂问题或者提高模型准确率,神经网络模型的规模越来越大,导致需要大量的运算资源。大规模的神经网络算法给底层硬件带来了能效和吞吐量两方面的挑战,据统计,卷积计算占卷积神经网络cnn中90%以上的计算量。虽然可以将卷积神经网络模型部署在具有高并行度的图形处理器gpu上进行训练或推理,从而可以有很大的速度优势,但由于其功耗和成本等因素,在神经网络算法实际应用部署上还有很多限制。
4.为了更好地在硬件系统上部署神经网络模型,需要优化计算资源消耗以及大量数据访存所带来的吞吐率损失,如何合理设计数据流以及计算模块架构成为了优化的重点。
技术实现要素:
5.针对上述技术问题,本发明旨在提供一种基于rs数据流的卷积硬件加速器,以最大化卷积计算过程中的数据重用,减少数据搬运过程,提高系统吞吐率以及能效。本发明同时提供一种利用上述硬件加速器的方法。
6.本发明采用的技术方案为:
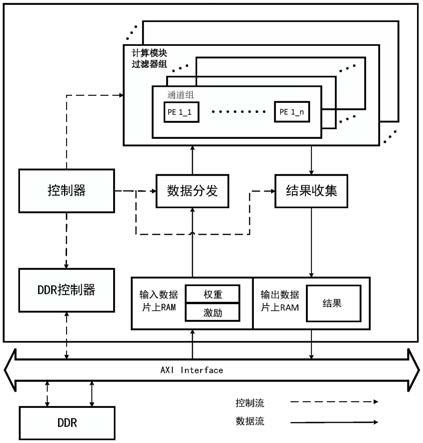
7.一种基于rs数据流的卷积硬件加速器,包括:
8.片外ddr存储器,用于存储原始图像数据和神经网络推理结果数据;
9.片上缓存模块,用于存储从片外ddr存储器读取的原始图像数据、卷积核权重数据和卷积计算中间结果;
10.ddr控制器,用于控制片外ddr存储器与片上缓存模块的数据交互;
11.数据分发模块,用于根据当前计算配置信息和光电计算模块的计算规律将需要的权重与激励数据传送给光电计算模块;
12.光电计算模块,用于完成各层网络的卷积运算;
13.结果收集模块,用于接收光电计算模块的卷积结果,并将结果拼接,得到下一层的输入,或者将拼接结果存储到片外ddr存储器中;
14.控制器,用于存储配置信息,根据当前运算状态协调ddr控制器、数据分发模块、光电计算模块和结果收集模块的运行。
15.进一步地,所述数据分发模块包括数据读取模块fifo缓存器、乒乓寄存器组和地址计算单元,数据读取模块fifo缓存器与所述片上缓存模块相连,地址计算单元分别和乒
乓寄存器组与所述片上缓存模块相连;所述数据读取模块fifo缓存器用于实现片外ddr存储器和片上缓存模块数据交互时的缓冲和位宽匹配,所述乒乓寄存器组用于存储从片上缓存模块中读取的权重数据和激励数据,将数据组装拼接成计算模块所需的形式并输出,所述地址计算单元用于控制对片上缓存模块进行读数据和写数据的地址。
16.进一步地,所述光电计算模块包括多个光电计算阵列和累加模块;所述光电计算阵列用于完成权重窗口和对应激励窗口的乘累加操作,所述累加模块用于对光电计算阵列计算结果进行累加计算。
17.进一步地,所述光电计算阵列包括m个卷积过滤器组,每个卷积过滤器组是由一组计算单元组成的阵列,每个卷积过滤器组包括c个通道组,每个通道组包含n个计算单元;m个卷积过滤器组之间共享相同的特征图数据,输入不同的卷积核;c个通道组对应c个输入通道,每个通道输入特征图和卷积核的对应通道数据;通道组中的每个计算单元共享相同的权重数据。
18.本发明还提供一种基于rs数据流的卷积硬件加速器的加速方法,包括以下步骤:
19.1)开始计算之前,控制器向ddr控制器发送读权重和读激励请求,ddr控制器将特征图数据和卷积核数据从片外ddr存储器搬运到数据分发模块中的片上缓存模块;
20.2)根据当前卷积计算阶段,数据分发模块计算出所需的下一批激励数据和权重数据在片上缓存模块中的存储地址,并将下一批激励数据和权重数据分别读取到数据分发模块中;
21.3)将数据分发模块中存储的权重和激励数据展开并拼接成光电计算模块接口所需的格式,并根据计算顺序分发给光电计算模块;
22.4)光电计算模块计算完成后,由结果收集模块接收并存储卷积计算结果;如果接收到的是最后一层卷积结果,控制器向ddr控制器发送写结果请求,将最终结果保存到片外ddr 存储器中。
23.进一步地,特征图在片上缓存模块中按照列-通道-行的顺序存储,即一个地址存放一个通道的一行激励;先存放完一个分块一行所有通道的数据,再存放下一行的数据;每一层的激励存储在不同的片上缓存模块中,卷积核在片上缓存模块中按照卷积过滤器存储,一个地址存储一个卷积过滤器的c个通道的权重,并且先存储一个卷积过滤器所有通道的权重后,再存储下一个卷积过滤器。
24.进一步地,步骤2)中,所述数据分发模块包括数据读取模块fifo缓存器、乒乓寄存器组和地址计算单元,所述乒乓寄存器组分为激励乒乓寄存器组和权重乒乓寄存器组,激励乒乓寄存器组用于存储激励数据,权重乒乓寄存器组用于存储权重数据;其中,权重数据每次需要更新m个卷积核的c个通道,需要读取m个地址的权重数据;假设卷积核尺寸为k,激励数据每次更新需要k*c个地址的激励数据。
25.进一步地,步骤3)中,所述光电计算模块包括多个光电计算阵列和累加模块,光电计算阵列包括m个卷积过滤器组,每个卷积过滤器组是由一组计算单元组成的阵列,数据分发模块将数据从乒乓寄存器组分发到光电计算阵列中,具体分发顺序为:对于权重数据,数据分发模块先分发一层卷积的m个卷积核的c个通道权重数据,然后分发当前m个卷积核的接下来 c个通道权重数据;当前m个卷积核的全部通道权重数据分发完成后再分发接下来m个卷积核的权重数据;其中所分发的m个卷积核权重数据分别输入到光电计算模块对应的
卷积过滤器组;所分发的一个卷积核权重中c个通道的权重数据分别输入到卷积过滤器组中对应的通道组;卷积过滤器组同一通道组中的所有计算单元共享相同的权重数据;对于激励数据,数据分发模块先分发特征图一行的c个通道,然后再分发接下来的c个通道;当输出结果一行的所有通道计算完成后再分发下一行的激励数据;所分发的激励数据复制m份,分别输入到光电计算模块的m个卷积过滤器组;所分发的激励数据的c个通道分别输入到卷积过滤器组中的c个通道组
26.利用本发明提出的一种基于rs数据流的卷积硬件加速器,可以根据硬件资源和所部署的神经网络模型参数合理地设计卷积计算硬件架构,并不同程度地利用数据的可重用性,可以灵活地将不同神经网络算法映射到硬件上。在保证硬件资源的高利用率的同时提高了系统的吞吐率,可为神经网络模型进行硬件加速。
附图说明
27.图1是本发明一种基于rs行固定数据流卷积硬件加速器的结构框图;
28.图2是本发明卷积神经网络加速器的运行流程图;
29.图3是一维卷积的处理过程;
30.图4是一个逻辑pe集的二维卷积运算数据流示意图;
31.图5是本实施例中的cnn网络模型示意图;
32.图6是本实施例中pe计算阵列结构示意图;
33.图7是数据分发示意图。
具体实施方式
34.下面结合附图对本发明方案进行详细说明,
35.如图1所示的基于rs行固定数据流卷积硬件加速器的结构框图,包括控制器、ddr控制器、片上数据缓存单元(ram)、片外ddr存储器、数据分发模块、光电计算模块和结果收集模块。片外ddr存储器,用于存储原始图像数据和神经网络推理结果数据。片上数据缓存单元,用于存储从片外ddr存储器读取的原始图像数据、卷积核权重数据和卷积计算中间结果。ddr控制器,用于控制片外ddr存储器与片上数据缓存单元的数据交互。光电计算模块用于完成各层网络的卷积运算,包括多个光电计算阵列(pe计算阵列),每个pe计算阵列包括多个pe计算单元。控制器与ddr控制器、数据分发模块、pe计算阵列模块和结果收集模块连接,用于存储配置信息,根据当前运算状态协调各个模块的运行。数据分发模块与pe计算阵列和片上数据缓存单元连接,用于根据当前计算配置信息和光电计算模块的计算规律将需要的权重与激励数据传送给光电计算模块。结果收集模块与pe计算阵列和片上数据缓存单元连接,用于接收光电计算模块的卷积结果,并将结果拼接,得到下一层的输入,或者将拼接结果存储到片外ddr存储器中。片上数据缓存单元包括权重缓存单元和激励缓存单元,ddr控制器通过总线访问片外ddr存储器,将权重数据和激励数据读取到对应的缓存单元。数据分发模块包括数据读取模块fifo缓存器、乒乓寄存器组和地址计算单元,数据读取模块fifo 缓存器用于实现片外ddr存储器和片上数据缓存单元数据交互时的缓冲和位宽匹配;乒乓寄存器组用于存储从片上数据缓存单元中读取的权重数据和激励数据,将数据组装拼接成计算模块所需的形式并输出;地址计算单元用于控制对片上数据缓存单元进行读
数据和写数据的地址。数据读取模块fifo缓存器与片上数据缓存单元写数据线相连,乒乓寄存器组与片上数据缓存单元读数据线相连,地址计算单元与片上数据缓存单元读写地址线相连。
36.图2所示为上述卷积神经网络加速器的运行流程图。系统启动后,控制器根据配置信息通过状态机状态转换控制整个计算流程,保证各模块协调运行。首先,控制器配置完成后进入准备状态,ddr控制器将所有权重数据和输入图像的一个分块搬运到片上数据缓存单元,控制器控制数据分发模块按照pe计算阵列的计算顺序向pe计算阵列发送激励和权重数据,pe计算阵列按顺序进行卷积操作,同时结果收集模块接收并存储pe计算阵列的计算结果。当前层卷积全部计算完成后判断是否为卷积最后一层,如果不是,结果收集模块整合的卷积结果将作为输入开始下一层卷积计算;如果是,将结果搬运到片外ddr存储器中。
37.图3所示为一维卷积的处理过程。计算机视觉上的神经网络模型中的卷积运算一般都是三维卷积运算。可以分解为多个二维卷积运算的组合,而二维卷积运算操作的基本单元又是一维卷积运算。图4所示为一个逻辑pe集的二维卷积运算数据流示意图,首先一个一维卷积运算映射到逻辑pe集中的一个pe计算单元,多个pe单元组成一个逻辑pe集。权重数据的一行在逻辑pe集中的水平方向重用,输入激励的一行在逻辑pe集中对角线方向重用,逻辑pe集垂直方向累计得到卷积输出结果的一行。神经网络模型中一个卷积层输入特征图的通道数为 c,卷积核数目为m,那么对一个特征图完成该层卷积运算需要c*m个逻辑pe集。其中,m 个集合之间可以共享相同的特征图,c个集合的乘加结果再通过累加模块加在一起。根据所部署的神经网络模型具体参数和设计寄存器大小对逻辑pe集在m和c两个维度上进行折叠和空间映射,确定物理pe计算阵列的设计大小。
38.图5为本实施例中的cnn网络模型示意图。一共有四层卷积,第一层输入特征图尺寸为 w1*h1*4通道,卷积核为3*3*4通道,卷积核个数为16;第二层卷积输入特征图尺寸为 w2*h2*16通道,卷积核为3*3*16通道,卷积核个数为32;第三层卷积输入特征图尺寸为 w3*h3*32通道,卷积核为3*3*32通道,卷积核个数为32;第四层卷积输入特征图尺寸为 w4*h4*32通道,卷积核为3*3*32通道,卷积核个数为32。根据上述基于rs数据流的卷积映射方式,计算一层卷积最多需要c*n个逻辑pe集,c为输入特征图通道数,n为卷积核个数,结合硬件计算资源和寄存器资源,将逻辑pe集进行折叠和空间映射。图6所示为本实施例中pe计算阵列结构示意图。pe阵列负责主要负责多层网络的卷积运算。在pe阵列设计上,将c*n个逻辑pe集在c维度上折叠为4,在n维度上折叠为4。pe阵列包括4个卷积过滤器组,每个卷积过滤器组包括4个通道。4个卷积过滤器组输入不同的卷积核,共享相同的特征图数据。特征图数据复用4次。4个通道在通道方向进行累加。每个通道中分为8个部分,每个部分分担一行卷积的一部分,8个并行运算,减少运算时间。8个部分共享相同的权重,权重数据复用8次。计算时,先计算输入一层卷积特征图前4通道的3行激励数据与前4组卷积核的前4通道权重。4个卷积过滤器组的累加模块分别将4个通道的卷积结果进行累加和寄存。然后计算特征图的第5到8通道数据和前4组卷积核的5到8通道数据。以此类推,所有通道计算完成后4个卷积过滤器组的累加模块输出1到4输出通道的1行卷积结果。然后更换为第 5到8组卷积核,以此类推计算完所有输出通道1行的卷积结果后,计算下一行卷积。以此类推完成该层所有卷积计算。
39.图7所示为数据分发模块示意图,包括权重分发模块和激励分发模块。权重分发模
块包括权重缓存单元、权重地址计算模块和权重乒乓寄存器组。控制器在配置状态下将所有权重从ddr存储器搬运到权重缓存单元中。权重在缓存单元中按照过滤器存储,先存储第一个过滤器所有通道的权重,再存储第二个过滤器,以此类推。运算过程中,需要将pe计算阵列每次计算所用到的权重转换为pe计算阵列运算所需的权重矩阵形式,并行发送给pe计算阵列,并从ram中读取下一批需要的权重数据到权重乒乓寄存器组中。以第二层为例,该层输入特征图为w2*h2*16,卷积核为3*3*16通道,卷积核个数为32。权重分发模块先分发第1到4 个卷积核的1到4个通道,然后分发5到8通道权重,以此类推。当所有通道权重分发完,开始分发第5到8个卷积核,以此类推,分发完所有卷积核数据。激励分发模块包括激励缓存单元、激励地址计算模块和激励乒乓寄存器组。激励分发模块主要负责在运算过程中,按照计算模块的计算顺序从激励缓存单元中取出一次激励更新中更新的激励数据,将激励数据展开成 pe计算阵列运算所需的激励矩阵形式。激励分发采用乒乓reg组,以配合pe计算速度。4个卷积过滤器组共享相同的激励数据。一个卷积过滤器组中同一通道组中的8个部分共同负责一行激励数据与卷积权重的计算。先分发一行激励的1到4通道,再分发5到8通道,直到一行的4个输出通道计算完毕。重复上述分发过程,一行所有输出通道计算完毕后,再开始分发下一行激励数据。
40.本发明基于rs数据流方式进行卷积运算,最大化数据重用,降低了对片外ddr的访问,提高了能效。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1