一种基于不变信息蒸馏的无监督解耦图像生成方法
1.本发明隶属于计算机视觉领域,主要涉及图像的生成问题,主要应用于影视娱乐产业、产品设计以及机器视觉理解等方面。
背景技术:
2.图像生成是指利用计算机视觉技术、辅以深度学习方法理解图像内容表示,并实现图像生成的技术。按照是否具有明确的监督信息作为指导,可以分成有监督图像生成与无监督图像生成两大类。无监督图像生成方法通常以图像作为输入,通过一定学习方案和技术手段,从随机噪声分布中学习图像数据的分布,建立二者之间的映射。有监督图像生成方法则通过详细的标签、属性等细粒度信息,对图像生成过程予以准确的指导,以此推断图像数据分布情况。图像生成技术可以扩充图像数据的数目,挖掘图像数据包含的隐式信息,可以有效地缓解军事、医学等高新技术领域所面临的图像数据量不足的问题,同时,还具有丰富的趣味应用场景,在影视娱乐、产品设计、珍贵影视作品修复等领域具有很高的应用价值。
3.人类在图像识别与分析方面具有得天独厚的基因优势,对图像的边缘信息以及纹理特征十分敏感。此外,研究表明人类对于图像等数据信息具有很强的因果推理和思维拓展能力,这与人类的神经系统结构密切相关。受动物神经系统启发,科学家提出了人工神经网络来解决复杂的函数拟合问题,并在图像识别等领域取得了巨大突破。21世纪初,依赖深度神经网络的深度学习方法的巨大潜力被进一步挖掘,也涌现出一批在图像生成领域的先驱性工作,然而,早期的图像生成方法需要求解庞大复杂的概率模型,不仅对于研究人员的数学功底具有较高要求,同时还需要消耗大量的计算资源,并且高度依赖与图像相关的额外监督信息,这些缺陷限制了图像生成技术的发展与应用。
4.2014年,goodfellow等人提出了基于无监督方法的生成对抗网络,巧妙地避开了传统图像生成方法需要求解显式概率分布的难点,实现了图像生成技术的一个重大突破,也使得以生成对抗网络为基础的众多图像生成方法在不同应用场景取得了卓越的成效。生成对抗网络的优势在于,不预设图像数据的先验分布,而是通过零和博弈的思想,设计了生成图像的生成器以及鉴别图像真假的鉴别器两个模型,在训练时,通过这两个模型的彼此对立与博弈,最终使得生成器能够从随机噪声分布中隐式地推导出图像分布,实现图像生成。
5.然而,生成对抗网络地隐式分布推导过程在简化计算过程和训练难度的同时,也带来了模型训练不稳定、图像生成结果难以解释、训练不可控等问题。其中,如何建立输入噪声与生成图像之间的对应关系,是生成对抗网络模型亟待解决的难点之一,学会输入与输出之间的关系,不仅可以人为地控制图像生的过程,还可以提升模型图像生成结果的说服力,有助于生成对抗网络在高精尖领域的应用。
6.sudipto mukherjee等人以生成对抗网络为基础,依托聚类思想提出了无监督聚类生成对抗网络cluster-gan,实现了无监督解耦图像生成的重大突破。参考文献:
mukherjee s,asnani h,lin e,et al.clustergan:latent space clustering in generative adversarial networks[j].proceedings of the aaai conference on artificial intelligence,2019,33:4610-4617.该模型基于聚类思想,构造生成器输入噪声与生成图像类别之间的关系,在mnist、fashion-mnist等数据集上取得了良好效果。然而,该模型在更为复杂的cifar10数据集上并未能取得卓越表现,不仅如此,由于该模型使用的网络结构较为简单,其生成的图像质量难以达到实际应用的要求,其按类生成图像的准确率也较低,无法获得实际应用。
[0007]
近年来,基于无监督方法的分类模型在识别准确率上取得了长足进步,而cluster-gan模型由于其自身架构的缺陷,并未能充分利用图像数据的内隐信息,仍有提升空间。本发明受不变信息蒸馏聚类模型(invariant information distillation clustering model,简称iid)的启发,参考文献:[ji x,henriques j f,vedaldi a.invariant information clustering for unsupervised image classification and segmentation[j].2018.使用不变信息蒸馏方法,改进了现有无监督聚类解耦生成模型对图像信息利用不足的缺点,并充分考虑目前图像生成质量卓越的频谱归一化生成对抗网络(spectral normalization for generative adversarial networks,简称sngan)的理论优势,引入了图像生成质量更好的谱归一化残差神经网络作为函数拟合器,并成功与无监督聚类算法相结合,以在图像质量和按类图像生成准确率两个方面均取得了出色的成果。参考文献:miyato t,kataoka t,koyama m,et al.spectral normalization for generative adversarial networks[c]//international conference on learning representations.2018.
技术实现要素:
[0008]
本发明是一种无监督不变信息蒸馏聚类的解耦图像生成方法,主要解决现有的聚类生成对抗网络方法存在的图像生成质量差,按类生成图像效果不佳等问题。
[0009]
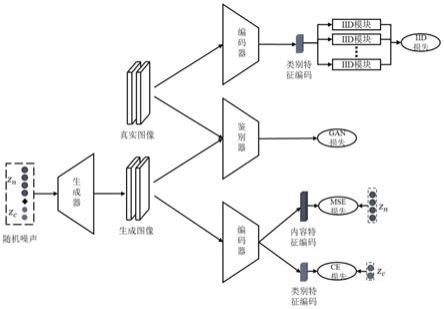
本发明方法是一种基于无监督聚类的解耦生成对抗网络框架,使用cifar10数据集作为实验数据来源。首先对训练图像进行归一化处理,从高斯分布中采样随机噪声用于训练。同时,为了实现按类图像生成的目的,在高斯噪声之外额外从均匀分布中采样类别噪声,并将其编码成one-hot向量,与高斯噪声进行拼接,共同作为生成对抗网络的噪声输入。为了实现按类图像生成,在生成器与鉴别器之外额外引入一个编码器,用于编码图像的相关信息。然后,以类别噪声作为生成图像的伪标签,使用交叉熵损失计算生成图像的分类损失,为了将类别噪声与其他噪声的功能进一步区分,对于高斯噪声,使用l2范数约束生成图像编码。为了提升编码器分类的准确性,给予生成器更正确的分类生成指导,使用iid损失,令编码器对真实图像进行聚类。同时,为了能够提升图像生成质量,又不牺牲无监督聚类算法的优势,使用谱归一化残差神经网络作为基本框架。实验证明,iid损失显著提升了编码器的分类准确率,并且成功地将类别信息应用于生成器的图像生成过程,提升了生成器按类生成图像的准确性。此外,谱归一化残差神经网络的应用显著提升了模型的生成质量,取得了良好表现。算法的总体结构示意图参见图1。
[0010]
为了更加明了地表述本发明的具体内容,首先对一些属于进行定义。
[0011]
定义1:正态分布。又称为高斯分布,是一个在物理、数学等领域具有重要地位的概
率分布,由于现实生活中许多规律符合正态分布,其具有十分广泛的应用面。假如一个随机变量x,其概率密度函数满足其中,μ为正态分布的数学期望,σ为正态分布的标准差,则称x满足正态分布,通常记为n(x|μ,σ2)的形式。
[0012]
定义2:残差神经网络。残差神经网络是对卷积神经网络的一个改进,相较于卷积神经网络,残差神经网络使用了一种称为“short-cut”的跨层连接的方法,在传统的卷积神经网络基础上进行层间的跨层信息交流,这种方法使得不同层之间的信息共享更加直接,实验表明,残差神经网络的表现优于同样层数的卷积神经网络。此外,残差神经网络相比于卷积神经网络,可以在更深的网络结构下保持训练稳定性,有助于更加充分地发挥神经网络对函数的拟合优势。
[0013]
定义3:平均池化。平均池化是一种将输入的图像划分为若干个矩形区域,对每个子区域进行平均操作的方法。对于一个给定特征图x,若将其划分成k个子区域,那么,子区域xk经过平均池化后的输出为其中,rk表示第k个子区域中的像素点个数,x
kab
表示处于第k个子区域中位于(a,b)处元素的值。平均池化通过提取每个矩形区域中的平均值,相比于最大池化方法,可以保留更多的图像背景信息。
[0014]
定义4:batch-norm批规范化函数。批规范化函数是为了解决同一任务的不同图像个体之间分布差异而提出的规范化方法。其核心思想在于求取同一批次图像数据的均值和方差,之后对样本进行归一化处理,使其大体上符合高斯分布,为了使归一化后的各个数据的差异性不至于消失,在归一化后还使用了平移和缩放操作来强调样本间的差异。批规范化函数在以卷积神经网络中具有非常广泛的应用,有助于提升模型的可训练性,使得模型更易于收敛。
[0015]
定义5:谱归一化函数。谱归一化函数是一种针对鉴别器网络权重所提出的一种归一化函数,其作用在于使鉴别器函数的输出使用满足1-lipshcitz连续,从而提升生成对抗网络的稳定性。其表达式为其中,w
l
表示网络第l层的权值矩阵,σ(
·
)表示矩阵的最大奇异值。
[0016]
定义6:relu函数。又称为分段线性函数,是人工神经网络中经常使用到的一种激活函数,其思想在于,将小于0的值置为0,而大于0的值不作改变,表达式为relu(x)=max(0,x)。
[0017]
定义7:tanh函数。即双曲正切函数。能够使输入和输出保持非线性单调上升和下降关系,比sigmoid函数具有更宽的梯度范围,有助于改善神经网络中常出现的梯度消失问题,表达式为
[0018]
定义8:ce损失。交叉熵损失,是一种常用的分类损失函数,给定一个分布为q的信息,假如希望使用分布p来表达这一信息,则传递的平均信息长度为最小化交叉熵函数,将会使两个分布之间距离不断拉近,。
[0019]
定义9:mse损失。最小均方误差损失,也称为l2损失,其作用是将目标值与估计值的差值的平方和最小化,常用于回归问题。假如目标值为x,估计值为f(x),那么其mse损失为xi为x的第i维元素的值,mse损失常简记为
[0020]
定义10:softmax函数。softmax也被称为归一化指数函数,其作用在于,将n维向量的所有数值压缩到[0,1]区间,并且所有数值之和为1。softmax函数常被用于概率预测模型的输出操作,其表达式为
[0021]
定义11:one-hot编码。one-hot编码是一种常用的计算机编码方法,将数据编码成二进制形式表示,比如对数字0~9进行one-hot编码,每个数字都将被编码成10维的二进制码,除对应数字i的第i个位置值为1外,其他维度的值均为0。
[0022]
定义12:上采样。上采样是一类使用双线性、最近邻、均值填充等手段扩大图像尺寸的插值方法的统称。本方法使用最近邻插值法,将输入的图像或特征图尺寸变为原来的两倍。最近邻插值法的计算公式为orix=neax
·
(oriw/neaw),oriy=neay
·
(orih/neah),其中,ori
·
、nea
·
分别表示插值前与插值后的对应参数,x、y分别表示像素点的横纵坐标,w、h分别表示图像的宽度和长度。
[0023]
定义13:生成对抗网络。生成对抗网络是一种基于深度学习的图像生成模型,整个网络鉴别器与生成器两部分组成,鉴别器的功能是鉴别输入的图像是生成的虚假图像还是真是图像,生成器的功能是生成尽可能逼真的图像。在实际训练过程中,鉴别器与生成器的训练目的正好相反,鉴别器希望尽可能区分来自生成器生成的图像与真实图像,而生成器希望生成逼真的图像以欺骗鉴别器,二者构成了一种零和博弈关系,通过这种对抗式学习,最终鉴别器将无法区分真实图像与生成图像,即意味着生成模型已经生成了足够逼真的图像。
[0024]
定义14:编码器。编码器是一种应用广泛的特征提取模型,对于给定的图像输入,编码器期望学习到图像数据的内在特征,从而提取出图像的抽象表示作为输出,以便进行后续的其他任务。编码器是一种类型多样的模型总称,其核心是一个特征提取网络,而提取出的特征形式随着具体任务的不同而不同。
[0025]
定义15:随机数据增强。也被称为随机数据增广,是一类为缓解数据不足而诞生的扩充数据数量方法的总称。图像随机数据增强方法多样,主要包括以人工添加噪声、随机裁剪、随机旋转与翻转、随机灰度值替换的手动方法以及使用深度学习模型进行数据增强两大类。
[0026]
定义16:不变信息蒸馏(iid)。是一种基于互信息的无监督聚类方法。其思想在于,对于同一图像的不同表达形式,比如图像与其对应的标签,或者图像的两张不同增强副本,尽管在表现形式上有所不同,但二者应该在大体上表达相同的信息,因此具有较大的互信息。信息不变性聚类方法基于此思想,通过最大化图像与其增强样本特征之间的互信息,以此拉近同一类样本之间的相似性,实现无监督的聚类。
[0027]
因而,本发明技术方案为:一种基于信息不变性蒸馏的无监督解耦图像生成方法,该方法包括:
[0028]
步骤1:进行实验数据的预处理;
[0029]
获取多个类别的图像,并对图像同意尺寸,再进行像素值归一化;
[0030]
步骤2:进行实验数据的随机数据增强操作;
[0031]
为经步骤1处理后的图像数据进行随机数据增强处理,一共使用包括随机裁剪、随机水平翻转、随机亮度改变和随机灰度化共四种操作;对每一张图像的具体随机数据增强过程为:
[0032]
第一步,随机从原图像中60%~100%的区域选定裁剪区域,并将裁剪后的图像恢复原尺寸大小;
[0033]
第二步,以50%的概率将图像进行水平翻转;
[0034]
第三步,分别将图像的亮度、对比度、饱和度随机变换为原图像的50%~150%之间,并且将图像的色调随机以-10%~10%之间的幅度进行偏移;
[0035]
第四步,以10%的概率将图像转换成灰度图像;经过上述步骤处理后,每张图像都将得到一张尺寸与原图像相同的随机增强样本;
[0036]
步骤3:构建深度神经网络;
[0037]
1)构建生成器网络:
[0038]
生成器的输入为由118维高斯噪声和10维one-hot编码组成的128维噪声向量,输出为图像;生成器网络结构由一个全连接层、一个由3个残差神经网络模块组成的残差神经网络和一个二维卷积层顺序连接组成,以全连接层作为输入端,以二维卷积层作为输出端;生成器网络结构如图2所示。
[0039]
2)构建鉴别器网络:
[0040]
鉴别器以真实图像和生成图像为输入,输出为1维向量,表示对输入图像属于真实图像的概率判断,其网络结构由四个谱归一化残差块、一个全局平均池化层和一个全连接层组成,四个谱归一化残差神经网络模块顺序连接,构成一个残差神经网络,鉴别器网络以残差神经网络、全局平均池化神经网络、全连接层的顺序依次顺序连接,以残差神经网络作为输入端,全连接层作为输出端;鉴别器网络结构如图3所示。
[0041]
3)构建编码器网络:
[0042]
编码器输入为生成图像、真实图像和真实图像的随机数据增强样本,输出为图像特征向量;编码器网络的主体结构由一个经四个残差神经网络模块组成的残差神经网络、一个全局平均池化层和两个全连接层顺序连接组成,以残差神经网络作为输入端,以最后一个全连接层作为输出端,输出为128维特征向量;对于编码器的输出,将特征向量的前118维作为内容特征向量,将后10维作为类别特征向量,额外将类别特征向量送入10个结构相同的全连接层,得到10个信息不变性特征向量;编码器网络结构如图4所示。
[0043]
步骤4:设计损失函数;
[0044]
将步骤1中获取的图像张量记为经过步骤2随机数据增强后的图像记为γ(x);记从正态分布中随机采样得到的118维高斯噪声向量为zn,记从均匀分布中以概率0.1采样得到的取值为0~9的随机整数为c,并将其对应的one-hot向量记为zc,将zn与zc进行拼接,得到128维的噪声向量分别记生成器、鉴别器、编码器网络为g、d、e;
[0045]
记生成器的输出为if,鉴别器以ir、if为输入得到的输出分别为df;
[0046]
1)生成器损失函数lg:
[0047]
生成器的优化目的是生成尽量真实的图像,同时,其生成的图像内容应尽可能对应噪声zn,图像类别应尽可能对应噪声zc,因此,生成器的损失包括生成对抗网络损失内容一致性损失和类别一致性损失三部分;其中:
[0048][0049][0050][0051]
上述公式中,表示对从分布中采样的若干个随机噪声的损失求期望,d(g(z))表示鉴别器以生成器生成图像为输入对应的输出,e(g(zn))、e(g(zc))分别表示编码器提取到的生成图像的118维内容特征向量和10维类别特征向量,同时,e(g(zc))经softmax操作归一化至[0,1]区间;ce(
·
)表示交叉熵损失;
[0052]
因此,生成器总损失函数为:
[0053][0054]
2)鉴别器损失函数ld:
[0055]
鉴别器的优化目的是尽可能准确地区分真实图像与生成图像,其损失函数为:
[0056][0057]
上式中,表示对从真实图像分布中随机采样的若干个样本求期望,d(x)表示鉴别器以真实图像为输入对应的输出,其余定义与生成器损失函数中的定义相同;
[0058]
3)编码器损失函数le:
[0059]
编码器的优化目的是尽可能准确地捕捉生成图像的内容和类别信息,即希望对生成图像编码得到的内容特征与类别特征尽可能与生成图像对应的内容和类别噪声一致;同时,使用不变信息蒸馏进行真实图像的无监督聚类,以便帮助编码器更好地提取类别特征;因此,编码器损失由内容一致性损失类别一致性损失和不变信息蒸馏损失三部分组成,其中:
[0060][0061][0062][0063]
上述公式中,内容一致性损失、类别一致性损失与生成器中的定义相同,i(
·
)表示互信息函数,e(xc)、e(γ(x)c表示编码器提取到的对应图像的类别特征;采用近似方法求解互信息函数,首先,将类别特征通过步骤3中提到的10个全连接层,得到10个10维信息不变性特征向量lm(m=1,2,...,10),然后,将这10个信息不变性特征向量分别进行softmax操作,归一化至[0,1]区间,每一个l均表示编码器对图像类别归属的概率分布,记与图像相
对应的随机增强图像的不变性特征向量为γ(l),令p=l
·
γ(l)
t
为一个10
×
10的联合概率分布矩阵,(c,c
′
)处的值p
cc
′
=p(l=c,γ(l)=c
′
),表示编码器预测图像属于类别c,对应随机增强图像属于类别c
′
的联合概率。同时为了保证对称性,令记p按行求和的结果为pc,按列求和的结果为pc′
,图像的第m个信息不变性向量的互信息可表示为:
[0064][0065]
最终的互信息为10个信息不变性向量互信息的均值:
[0066][0067]
因此,编码器总损失函数为:
[0068][0069]
步骤5:训练总神经网络;
[0070]
利用步骤3构建的三个神经网络,分别使用步骤4设计的对应损失函数进行训练,使用adam动量优化器,在更新生成器的网络参数时固定鉴别器、编码器的网络参数,更新鉴别器、编码器时采用同样的方案;
[0071]
步骤6:采用步骤5中训练好模型,保存模型参数,取生成器,按步骤4所述方法构造随机噪声变量,并输入生成器中,即可获得生成图像,不同的随机噪声输入将产生不同的生成图像。
[0072]
本发明包括如下改进点:
[0073]
a,针对当前依托于聚类的无监督解耦生成模型在复杂数据集上图像生成质量差的问题,使用谱归一化残差神经网络提升深度神经网络的拟合能力,提升了图像生成质量,网络结构如图1所示。
[0074]
b,针对当前无监督聚类解耦生成模型生成图像的解耦效果差、类别辨识度低的问题,引入信息不变性蒸馏无监督聚类方法,通过最大化图像及其对应随即增强图像类别特征之间的互信息,引入真实图像信息辅助编码器进行聚类,提升了生成对抗网络的无监督解耦图像生成能力,并没有使用额外的标签数据。
[0075]
c,我们将上述方案引入生成对抗网络中进行图像生成实验,并在实验中取得了更出色的图像生成质量和图像解耦生成效果。
[0076]
a中的改进可以在继续发挥无监督聚类思想优势的基础上,大幅提升图像生成质量,b中的改进可以在不引入额外标签等监督信息的基础上,显著提升模型的图像解耦生成效果,并且解耦能力比只使用1)方法的模型相比也具有显著提升,通过二者的结合,最终,我们的方法生成的图像质量在is评价指标下比其他基于聚类的无监督解耦图像生成方法提升了60%,生成对抗网络生成按类生成图像的解耦质量在聚类准确率指标上提升了12%,兰德指数提升了11%,标准化互信息提升了20%,即使在相同的谱归一化残差神经网络架构下,本发明方法在不降低图像质量的情况下解耦效果也大幅优于其他基于聚类的无监督解耦生成模型。
附图说明
[0077]
图1为本发明方法主要网络结构示意图,
[0078]
图2为本发明生成器网络结构详细示意图,
[0079]
图3为本发明鉴别器网络结构详细示意图,
[0080]
图4为本发明编码器和iid模块网络结构详细示意图。
具体实施方式
[0081]
步骤1:进行实验数据的预处理;
[0082]
从官方渠道获取cifar10数据集。cifar10数据集是由60000张彩色rgb图像组成的图像数据集,数据集中共包含10个类别,每个类别的图像数量相等,此外,数据集中每张图像的大小均为32
×
32,并且注明对应的类别信息。为了将图像数据转换成更易于深度学习模型学习的数据,将图像像素值归一化至[-1,1]区间内,并转换成张量形式储存。
[0083]
步骤2:进行实验数据的随机数据增强操作;
[0084]
为经步骤1处理后的图像数据进行随机数据增强处理,一共使用包括随机裁剪、随机水平翻转、随机亮度改变和随机灰度化共四种操作。对每一张图像的具体随机数据增强过程为:第一步,随机从原图像中60%~100%的区域选定裁剪区域,并将裁剪后的图像恢复至32
×
32大小;第二步,以50%的概率将图像进行水平翻转;第三步,分别将图像的亮度、对比度、饱和度随机变换为原图像的50%~150%之间,并且将图像的色调随机以-10%~10%之间的幅度进行偏移;第四步,以10%的概率将图像转换成灰度图像。经过上述步骤处理后,每张图像都将得到一张尺寸与原图像相同的随机增强样本,将随机增强图像同样保存为张量,一遍后续使用。
[0085]
步骤3:构建深度神经网络;
[0086]
1)构建生成器网络:
[0087]
生成器的输入为由118维高斯噪声和10维one-hot编码组成的128维噪声向量,输出维32
×
32大小的图像。生成器网络结构由一个全连接层、一个由3个残差神经网络模块组成的残差神经网络和一个二维卷积层顺序连接组成,以全连接层作为输入端,以二维卷积层作为输出端。生成器网络结构如图2所示。
[0088]
2)构建鉴别器网络:
[0089]
鉴别器以真实图像和生成图像为输入,输出为1维向量,表示对输入图像属于真实图像的概率判断,其网络结构由四个谱归一化残差块、一个全局平均池化层和一个全连接层组成,四个谱归一化残差神经网络模块顺序连接,构成一个残差神经网络,鉴别器网络以残差神经网络、全局平均池化神经网络、全连接层的顺序依次顺序连接,以残差神经网络作为输入端,全连接层作为输出端。鉴别器网络结构如图3所示。
[0090]
3)构建编码器网络:
[0091]
编码器输入为生成图像、真实图像和真实图像的随机数据增强样本,输出为图像特征向量。编码器网络的主体结构由一个经四个残差神经网络模块组成的残差神经网络、一个全局平均池化层和两个全连接层顺序连接组成,以残差神经网络作为输入端,以最后一个全连接层作为输出端,输出为128维特征向量。对于编码器的输出,将特征向量的前118维作为内容特征向量,将后10维作为类别特征向量,额外将类别特征向量送入10个结构相
同的全连接层,得到10个信息不变性特征向量。编码器网络结构如图4所示。
[0092]
步骤4:设计损失函数;
[0093]
将步骤1中获取的图像张量记为经过步骤2随机数据增强后的图像记为γ(x);记从正态分布中随机采样得到的118维高斯噪声向量为zn,记从均匀分布中以概率0.1采样得到的取值为0~9的随机整数为c,并将其对应的one-hot向量记为zc,将zn与zc进行拼接,得到128维的噪声向量分别记生成器、鉴别器、编码器网络为g、d、e。
[0094]
记生成器的输出为if,鉴别器以ir、if为输入得到的输出分别为df[0095]
1)生成器损失函数lg:
[0096]
生成器的优化目的是生成尽量真实的图像,同时,其生成的图像内容应尽可能对应噪声zn,图像类别应尽可能对应噪声zc,因此,生成器的损失包括生成对抗网络损失内容一致性损失和类别一致性损失三部分。其中:
[0097][0098][0099][0100]
上述公式中,表示对从分布中采样的若干个随机噪声的损失求期望,d(g(z))表示鉴别器以生成器生成图像为输入对应的输出,e(g(zn))、e(g(zc))分别表示编码器提取到的生成图像的118维内容特征向量和10维类别特征向量,同时,e(g(zc))经softmax操作归一化至[0,1]区间。ce(
·
)表示定义7中的交叉熵损失。
[0101]
因此,生成器总损失函数为:
[0102][0103]
2)鉴别器损失函数ld:
[0104]
鉴别器的优化目的是尽可能准确地区分真实图像与生成图像,其损失函数为:
[0105][0106]
上式中,表示对从真实图像分布中随机采样的若干个样本求期望,d(x)表示鉴别器以真实图像为输入对应的输出,其余定义与生成器损失函数中的定义相同。
[0107]
3)编码器损失函数le:
[0108]
编码器的优化目的是尽可能准确地捕捉生成图像的内容和类别信息,即希望对生成图像编码得到的内容特征与类别特征尽可能与生成图像对应的内容和类别噪声一致。同时,使用不变信息蒸馏进行真实图像的无监督聚类,以便帮助编码器更好地提取类别特征。因此,编码器损失由内容一致性损失类别一致性损失和不变信息蒸馏损失三部分组成,其中:
[0109]
[0110][0111][0112]
上述公式中,内容一致性损失、类别一致性损失与生成器中的定义相同,i(
·
)表示互信息函数,e(xc)、e(γ(x)c表示编码器提取到的对应图像的类别特征。本发明采用近似方法求解互信息函数,首先,将类别特征通过步骤3中提到的10个全连接层,得到10个10维信息不变性特征向量lm(m=1,2,...,10),然后,将这10个信息不变性特征向量分别进行softmax操作,归一化至[0,1]区间,每一个l均表示编码器对图像类别归属的概率分布,记与图像相对应的随机增强图像的不变性特征向量为γ(l),令p=l
·
γ(l)
t
为一个10
×
10的联合概率分布矩阵,(c,c
′
)处的值p
cc
′
=p(l=c,γ(l)=c
′
),表示编码器预测图像属于类别c,对应随机增强图像属于类别c
′
的联合概率。同时为了保证对称性,令记p按行求和的结果为pc,按列求和的结果为pc′
,图像的第m个信息不变性向量的互信息可表示为:
[0113][0114]
最终的互信息为10个信息不变性向量互信息的均值:
[0115][0116]
因此,编码器总损失函数为:
[0117][0118]
步骤5:训练总神经网络;
[0119]
利用步骤3构建的三个神经网络,分别使用步骤4设计的对应损失函数进行训练,使用adam动量优化器,设置学习率为0.0002,实验基于依托python语言的pytorch平台实现,使用的python版本为3.6,pytorch版本为1.4。在更新生成器的网络参数时固定鉴别器、编码器的网络参数,更新鉴别器、编码器时采用同样的方案。鉴别器每更新3次,生成器、编码器更新一次。实际训练中鉴别器每次送入64张生成图像与64张真实图像进行更新,生成器独立同分布采样128个随机噪声进行更新,编码器送入256张生成图像与64张真实图像进行更新。整个实验鉴别器一共使用完整数据集迭代500次。
[0120]
步骤6:测试总神经网络;
[0121]
在步骤6中训练好模型,保存模型参数,取生成器,按步骤4所述方法构造随机噪声变量,并输入生成器中,即可获得生成图像,不同的随机噪声输入将产生不同的生成图像。按此方法生成50000张生成图像,计算图像生成质量is指标,评估生成器的图像生成质量。取编码器,使用cifar10数据集中的10000张测试图像(未被用于网络训练),进行类别预测,计算聚类准确度acc、兰德指数ari、标准化互信息nmi指标,评估聚类准确性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1