一种轻量级文本快速加密及解密方法与流程
1.本发明涉及数据管理保护技术领域,尤其涉及一种轻量级文本快速加密及解密方法。
背景技术:
2.随着现代化信息技术的发展,信息系统产生的数据体量越来越大,数据资产的价值体现越来越明显,为了有效保护这些数据,传统的技术往往使用权限管理、通用数据加密等方式。使用权限控制不能避免数据流通过程中被窃听、截取;通用的数据加密方式如aes、des等并不适合海量数据查询的场景,因为进行数据查询时,要么对全部数据进行解密,然后再根据查询条件进行匹配,这会对服务器产生巨大的计算压力,明显不能应用于实际的场景中;要么对查询条件进行加密,然后使用加密的结果进行匹配,但这只适用于精确查询,对于模糊查询,包括前匹配、后匹配并不适用。申请号为201911039012.4的信息安全加密方法及装置,在目标文本的字符之间插入随机获取的汉字的方式进行数据保护,这种方式也不适用于加密数据的查询,同时抗破解能力也有所欠缺。
技术实现要素:
3.本发明为克服上述的不足之处,目的在于提供一种轻量级文本快速加密及解密方法,本发明主要利用数组的下标(索引位置)与其位置存放的代码点的转换关系实现快速的加、解密,本发明面向文本字符,对文本数据一次读入即实现加解密,无需二次扫描,因此,能够满足大数据量的快速加密和解密要求。同时本发明在数据管理实际工作当中,可以实现不修改现有表结构定义(包括字段数据类型、字段数据长度)的情况下,对数据进行加密,同时满足加密数据不影响查询性能。
4.本发明是通过以下技术方案达到上述目的:一种轻量级文本快速加密及解密方法,包括如下步骤:
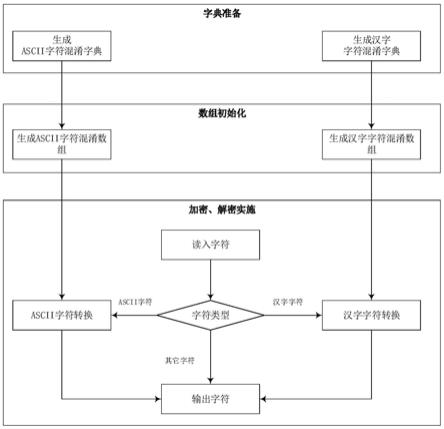
5.(1)分别对ascii字符集与汉字字符集进行混淆,得到ascii字符混淆字典与汉字字符混淆字典,并对上述两字典进行加密;
6.(2)分别对ascii字符混淆字典与汉字字符混淆字典进行数据初始化,得到ascii字符混淆数组与汉字字符混淆数组;
7.(3)读取待加密字符,判断并根据其字符类型进行ascii字符转换或汉字字符转换处理,输出加密字符,实现字符加密。
8.作为优选,所述的轻量级文本快速加密及解密方法还包括:
9.(4)读取待解密字符,判断并根据其字符类型进行ascii字符转换或汉字字符转换处理,输出解密字符,实现字符解密。
10.作为优选,所述步骤(1)具体如下:
11.(1.1)分别取ascii字符集、汉字字符集中的字符,按照utf-8代码点的大小排序,放到各自的字符数组中,假设ascii字符集的数组为arr_ascii、汉字字符集的数组为arr_
ch;
12.(1.2)由于arr_ascii、arr_ch数组长度已知,分别对arr_ascii、arr_ch数组进行混淆,得到ascii字符混淆字典与汉字字符混淆字典;
13.(1.3)将得到的ascii字符混淆字典与汉字字符混淆字典使用通用的加密算法进行加密后保存到文件中或数据库中。
14.作为优选,所述步骤(1.2)中,假设数组的长度为n,数组起始位置index为0,进行混淆的方法如下:
15.(i)生成一个index到n之间的随机数p,其中p不等于n;
16.(ii)将数组中位置为index的字符和位置为p的字符进行互换;
17.(iii)将index向后移一位,即index=index+1;
18.(iv)重复步骤(i)到步骤(iii),直到index到达数组末尾,即index=n-1,至此得到混淆的字典。
19.作为优选,所述步骤(2)具体如下:
20.(2.1)读取加密的文件或从数据库中读取加密的字符,并进行解密;(2.2)分别创建ascii字符集代码点数组arrascii和汉字字符集代码点数组arrchar,按照读取顺序,取其对应的utf-8代码点,依次放到对应的代码点数组中;
21.(2.3)分别创建ascii字符集代码点数组arrdestascii和汉字字符集代码点数组arrdestchar,按照读取顺序,取其对应的utf-8代码点,到对应的数组位置为utf-8代码点处写入顺序号;至此得到两套混淆数组,其中步骤(2.2)得到的数组用于加密,步骤(2.3)得到的数组用于解密。
22.作为优选,所述步骤(2)的数组初始化为一次性工作,无需每次加密、解密的过程均进行数组初始化,按照用户需求选择。
23.作为优选,所述步骤(3)具体如下:
24.(3.1)将待加密字符转换成一个字符数组,得到arr_str,假设arr_str的长度为n,数组arr_str的起始位置index为0;
25.(3.2)取arr_str位置index出字符的utf-8代码点,假设该代码点的数值为chr_num;
26.(3.3)根据chr_num数值范围判断其字符集类型,若chr_num数值大于等于32并且小于等于126为ascii字符,则到数组arrascii上进行操作;若chr_num数值大于等于19968且小于等于40869为汉字字符,则到数组arrchar上进行操作;
27.(3.4)根据引入的偏移量从对应数组的位置chr_num开始向后偏移,如果偏移位置超出数组最大长度,则从数组开始位置继续偏移,即取模;
28.(3.5)偏移结束后得到偏移的位置p_num,取数组位置p_num中的数值,得到val_num;
29.(3.6)得到的val_num即为字符的utf-8代码点,将val_num转换为字符,并替换数组arr_str位置为index处的字符,将index向后移一位,即index=index+1;
30.(3.7)重复步骤(3.2)至步骤(3.6),直到所有字符均替换完毕;
31.(3.8)将替换后的字符数组重新转换为字符串,完成加密。
32.作为优选,所述步骤(4)具体如下:
33.(4.1)将待解密字符转换成一个字符数组,得到arr_str,假设arr_str的长度为n,数组arr_str的起始位置index为0;
34.(4.2)取arr_str位置index出字符的utf-8代码点,假设该代码点的数值为chr_num;
35.(4.3)根据chr_num数值范围判断其字符集类型,若chr_num数值大于等于32并且小于等于126为ascii字符,则到数组arrdestascii上进行操作;若chr_num数值大于等于19968且小于等于40869为汉字字符,则到数组arrdestchar上进行操作;
36.(4.4)到对应的数组的位置chr_num处获取代码点val_num;
37.(4.5)根据引入的偏移量从对应数组的位置val_num开始向前偏移,如果偏移位置超出数组最小位置,则从数组最后位置继续向前偏移,即取模;偏移结束后得到偏移的位置p_num;
38.(4.6)p_num转换为字符,并替换数组arr_str位置为index处的字符,将index向后移一位,即index=index+1;
39.(4.7)重复步骤(4.2)至步骤(4.6),直到所有字符均替换完毕;
40.(4.8)将替换后的字符数组重新转换为字符串,完成解密。
41.本发明的有益效果在于:本发明利用数组的下标(索引位置)与其位置存放的代码点的转换关系实现快速的加、解密,本发明面向文本字符,对文本数据一次读入即实现加解密,无需二次扫描,因此,能够满足大数据量的快速加密和解密要求。同时本发明在数据管理实际工作当中,可以实现不修改现有表结构定义(包括字段数据类型、字段数据长度)的情况下,对数据进行加密,同时满足加密数据不影响查询性能。
附图说明
42.图1是本发明的方法流程示意图。
具体实施方式
43.下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
44.实施例1:本实施例以ascii字符集、汉字字符集为例,鉴于部分开发语言的数组下标(索引位置)不一定从0开始,那么arrascii、arrdestascii的下标(索引位置)可以从32(utf-8代码点中ascii第一个可见字符)开始,arrchar、arrdestchar的下标(索引位置)可以从19968(utf-8代码点中汉字的第一个字符)开始;但是有些开发语言的数组下标(索引位置)必须从0开始。从通用性角度考虑,本实施案例的数组的下标(索引位置)设定为从0开始。
45.本发明是利用数组的下标(索引位置)与其位置存放的代码点的转换关系实现加、解密,所以,对于数组下标(索引位置)必须为0的语言,数组的代码点需要进行适当的转换才能与其下标(索引位置)进行互换,为止需要引入几个常量,如表1所示:
[0046][0047]
表1
[0048]
一种轻量级文本快速加密方法,流程如图1所示,具体包括以下步骤:
[0049]
(1)混淆字典准备
[0050]
步骤1分别取ascii字符集、汉字字符集中的字符,按照utf-8代码点的大小排序,放到各自的字符数组中,假设ascii字符集的数组为arr_ascii、汉字字符集的数组为arr_ch。
[0051]
步骤2此时,arr_ascii、arr_ch数组长度已知,分别对arr_ascii、arr_ch数组进行混淆。
[0052]
假设数组的长度为n,数组起始位置index为0,混淆的方法如下:
[0053]
1、生成一个index到n之间的随机数(不包括n)p;
[0054]
2、将数组中位置为index的字符和位置为p的字符进行互换;
[0055]
3、将index向后移一位,即index=index+1;
[0056]
4、重复1到3的步骤,直到index到达数组末尾,即index=n-1。
[0057]
至此得到混淆的字典
[0058]
步骤3将得到字符混淆字典使用通用的加密算法进行加密后保存到文件中或数据库中。
[0059]
(2)数组初始化
[0060]
数组初始化为一次性工作,不是每次加密、解密的过程都要进行数组初始化。
[0061]
步骤1数组构造
[0062]
分别定义四个数组,arrchar[char_len]、arrascii[ascii_len]、arrdestchar[char_len]、arrdestascii[ascii_len],其中前两个数组用于加密,后两个数组用于解密。
[0063]
步骤2填充数组
[0064]
读取加密的ascii混淆字典和汉字混淆字典,进行解密,按照混淆字典里字符的顺序依次读取字符,顺序号从0开始。
[0065]
由于数组的下表(索引位置)是从0开始,解密后得到的字符转换为utf-8代码点后需要根据所属的字符集,分别减去start_char或start_ascii后再写入arrchar或arrascii。
[0066]
同理,解密后得到的字符转换为utf-8代码点后需要根据所属的字符集,分别减去start_char或start_ascii后到对应的arrchar或arrascii数组下标(索引位置)上写入顺序号(顺序号从0开始)
[0067]
由此得到加密数组和解密数组。
[0068]
(3)文本加密
[0069]
假设需要对个人信息进行加密,使用数值型的用户id或用户出生日期转化为数值型或使用用户年龄作为偏移量,实施时根据实际的情况灵活选择,此处以用户id为例。
[0070]
步骤1将待加密字符转换成一个字符数组,得到arr_str,假设arr_str的长度为n,数组arr_str的起始位置index为0。
[0071]
步骤2取arr_str位置index处字符的utf-8代码点,假设该代码点的数值为chr_num
[0072]
步骤3根据chr_num数值范围判断属于什么字符集,大于等于32并且小于等于126则为ascii字符,需要减去常量start_ascii再到数组arrascii上进行操作;大于等于19968小于等于40869则为汉字字符,需要减去常量start_char再到数组arrchar上进行操作。
[0073]
步骤4根据引入的偏移量用户id,从对应数组的位置chr_num(chr_num已减去常量)开始向后偏移,如果偏移位置超出数组最大长度,则从数组开始位置继续偏移。
[0074]
步骤5偏移结束后得到偏移的位置p_num,取数组位置p_num中的数值,得到val_num。
[0075]
步骤6val_num即为字符的utf-8代码点,将val_num转换为字符,并替换数组arr_str位置为index处的字符,将index向后移一位,即index=index+1
[0076]
步骤7重复步骤2至步骤6,直到所有字符均替换完毕
[0077]
步骤8将替换后的字符数组重新转换为字符串,完成加密。
[0078]
综上所述,加密效果有如下优点:
[0079]
1、由于将用户id作为偏移量引入,不同的用户信息中即使有相同的字符,加密的密文也不相同,有效的防止了通过数据比对等手段进行还原。
[0080]
2、加密后的数据无需解密即可实现数据精确查询和模糊查询,方法是将查询条件用上面的加密方法进行加密,加密后即可进行精确查询和迷糊查询,对数据库几乎没有添加额外的压力。
[0081]
3、加密后的字符串没有扩张,数据库表进行加密后原有的字段大小无需进行调整,及其方便使用。
[0082]
实施例2:一种轻量级文本快速解密方法,具体包括以下步骤:
[0083]
(1)混淆字典准备
[0084]
步骤1分别取ascii字符集、汉字字符集中的字符,按照utf-8代码点的大小排序,放到各自的字符数组中,假设ascii字符集的数组为arr_ascii、汉字字符集的数组为arr_ch。
[0085]
步骤2此时,arr_ascii、arr_ch数组长度已知,分别对arr_ascii、arr_ch数组进行混淆。
[0086]
假设数组的长度为n,数组起始位置index为0,混淆的方法如下:
[0087]
1、生成一个index到n之间的随机数(不包括n)p;
[0088]
2、将数组中位置为index的字符和位置为p的字符进行互换;
[0089]
3、将index向后移一位,即index=index+1;
[0090]
4、重复1到3的步骤,直到index到达数组末尾,即index=n-1。
[0091]
至此得到混淆的字典
[0092]
步骤3将得到字符混淆字典使用通用的加密算法进行加密后保存到文件中或数据
库中。
[0093]
(2)数组初始化
[0094]
数组初始化为一次性工作,不是每次加密、解密的过程都要进行数组初始化。
[0095]
步骤1数组构造
[0096]
分别定义四个数组,arrchar[char_len]、arrascii[ascii_len]、arrdestchar[char_len]、arrdestascii[ascii_len],其中前两个数组用于加密,后两个数组用于解密。
[0097]
步骤2填充数组
[0098]
读取加密的ascii混淆字典和汉字混淆字典,进行解密,按照混淆字典里字符的顺序依次读取字符,顺序号从0开始。
[0099]
由于数组的下表(索引位置)是从0开始,解密后得到的字符转换为utf-8代码点后需要根据所属的字符集,分别减去start_char或start_ascii后再写入arrchar或arrascii。
[0100]
同理,解密后得到的字符转换为utf-8代码点后需要根据所属的字符集,分别减去start_char或start_ascii后到对应的arrchar或arrascii数组下标(索引位置)上写入顺序号(顺序号从0开始)
[0101]
由此得到加密数组和解密数组。
[0102]
(3)文本解密
[0103]
步骤1将待解密字符转换成一个字符数组,得到arr_str,假设arr_str的长度为n,数组arr_str的起始位置index为0。
[0104]
步骤2取arr_str位置index出字符的utf-8代码点,假设该代码点的数值为chr_num
[0105]
步骤3根据chr_num数值范围判断属于什么字符集,大于等于32并且小于等于126为ascii字符,需要减去常量start_ascii再到数组arrdestascii上进行操作;大于等于19968小于等于40869为汉字字符,需要减去常量start_char再到数组arrdestchar上进行操作。
[0106]
步骤4到对应的数组的位置chr_num(chr_num已经减去常量)处获取代码点val_num。
[0107]
步骤5根据引入的偏移量从对应数组的位置val_num开始向前偏移,如果偏移位置超出数组最小位置,则从数组最后位置继续向前偏移。
[0108]
步骤5偏移结束后得到偏移的位置p_num。
[0109]
步骤6p_num转换为字符,并替换数组arr_str位置为index处的字符,将index向后移一位,即index=index+1
[0110]
步骤7重复步骤2至步骤6,直到所有字符均替换完毕
[0111]
步骤8将替换后的字符数组重新转换为字符串,完成解密。
[0112]
以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1