基于yolov5的遥感有向目标检测方法
1.本发明涉及数字电影技术领域,尤其涉及一种数字电影拷贝接收终端。
背景技术:
2.高分辨率遥感图像目标检测是光学遥感图像处理领域中最重要的任务之一,致力于定位并识别高分辨率遥感图像中的高价值地物目标。传统的高分辨率遥感图像目标检例如:多实例判别学习的弱监督检测算法sift和hog特征,结合多实例svm分类器实现车辆检测;多尺度混合模型和部件集合模型的高分遥感图像多类目标检测方法;基于空间约束稀疏表达词袋模型的遥感图像目标检测方法。但上述方法使用的特征本质上都是手工设计特征,不仅表达能力有限,而且泛化能力较弱(特征针对性较强,很难、、单一特征来适用所有应用场合),因此需要研究人员具备大量相关领域的知识才能设计出对某一类应用具有较好适应性的特征。相比手工设计特征,深度学习特征的表达能力和通用性更强,基于深度学习特征的目标检测方法已取得了里程碑式的突破,目前的主流是基于区域建议的方法,典型目标检测方法包括r-cnn系列:r-cnn、fast r-cnn和faster r-cnn,但这些检测方法在密集小物体上检测并没有清晰的目标方向,而且主要通过水平矩形窗口对地物目标进行定位,并给出目标的类别和得分,这与自然场景图像目标检测的输出形式基本一致,检测的精度没有取得很好的效果。然而,高分遥感图像与自然场景图像成像方式差别较大,图中地物目标的方向具有多样性,且在某些场景中,地物目标十分密集,此时若仍使用水平矩形框进行检测,则定位精度较差。
技术实现要素:
3.本发明的目的在于提供基于yolov5的遥感有向目标检测方法,以解决上述背景技术中提出的问题。
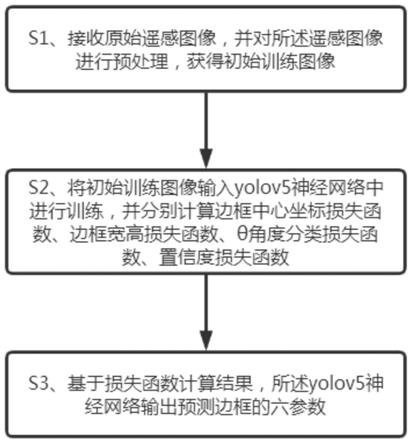
4.本发明是通过以下技术方案实现的:基于yolov5的遥感有向目标检测方法,包括下列步骤:
5.接收原始遥感图像,并对所述遥感图像进行预处理,获得初始训练图像;
6.将所述初始训练图像输入yolov5神经网络中进行训练,在训练过程中分别计算边框中心坐标损失函数、边框宽高损失函数、θ角度分类损失函数、置信度损失函数;
7.基于损失函数计算结果,所述yolov5神经网络输出预测边框的六参数。
8.可选的,所述yolov5神经网络的输出为[classid,x_c,y_c,longside,shortside,θ],式中,classid为类别的编号,,x_c为目标的中心点所处的x轴坐标,y_c为目标的中心点所处的y轴坐标,longside为旋转矩形框的最长边,shortside是与最长边对应的另一边,θ为x轴顺时针旋转遇到最长边所经过的角度。
[0009]
可选的,对所述遥感图像进行预处理,包括:将原始遥感图像输入数据加载器中进行数据增强,并对增强后的原始遥感图像进行裁剪、平移、透视操作,而后统一缩放到一个标准尺寸进行focus切片操作,获得初始训练图像。
[0010]
可选的,在进行角度的预测中添加圆形平滑标签这一技术,将连续的角度进行离散化,180个角度每个角度设置为一类,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
[0011]
可选的,所述yolov5神经网络包括:
[0012]
backbone层,用于实现初始训练图片的特征提取;
[0013]
neck层,用于裁剪图像特征,并将裁剪后的图像特征传递到head层;
[0014]
head,对图像特征进行预测,对于每个anchor point生成3种scale
×
3种ratio
×
6种角度的anchor框。
[0015]
可选的,在训练过程中通过下式计算边框中心坐标损失:
[0016][0017]
式中,(xi,yi)是预测边界框的位置,是从训练数据中得到的实际位置,表示该单元格i中的第j个边界框预测变量,λ为给定的常数,b为边界框预测值,s2为网格单元。
[0018]
可选的,在训练过程中通过下式计算边界框的宽高损失:
[0019][0020]
式中,wi为宽的预测值,为宽的实际值,hi为高的预测值,为高的实际值。
[0021]
可选的,在训练过程中通过下式对预测的类别做损失:
[0022][0023]
式中,pi(c)为预测类别概率,为真实类别概率。
[0024]
可选的,在训练过程中通过下式对预测的置信度做损失:
[0025][0026]
式中,ci是预测置信度,是真实置信度。
[0027]
与现有技术相比,本发明达到的有益效果如下:
[0028]
本发明提供的基于yolov5的遥感有向目标检测方法,能够更准确的提供目标方向和位置,同时该模型不仅可以充分挖掘同类目标之间的相似信息,而且可以在人工标注数据较少的情况下,较为精确的检测高分遥感图像中任意方向的地物目标,规避由于类内目标多样性引起的误检。
shortside]视为水平目标边框,然后在数据加载部分需要在标签原始数据的基础上添加一个θ维度,在角度中采用圆形平滑标签这一技术,将连续的角度进行离散化,180个角度每个角度设置为一类,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
[0043]
旋转后的图像大小表示不变。下面是计算旋转后目标相对旋转过后的图像的位置:
[0044]
x0=(poly[0][0]-a)*math.cos(pi_angle)-(poly[0][1]-b)*math.sin(pi_angle)+a
[0045]
y0=(poly[0][0]-a)*math.sin(pi_angle)+(poly[0][1]-b)*math.cos(pi_angle)+b
[0046]
x1=(poly[1][0]-a)*math.cos(pi_angle)-(poly[1][1]-b)*math.sin(pi_angle)+a
[0047]
y1=(poly[1][0]-a)*math.sin(pi_angle)+(poly[1][1]-b)*math.cos(pi_angle)+b
[0048]
x2=(poly[2][0]-a)*math.cos(pi_angle)-(poly[2][1]-b)*math.sin(pi_angle)+a
[0049]
y2=(poly[2][0]-a)*math.sin(pi_angle)+(poly[2][1]-b)*math.cos(pi_angle)+b
[0050]
x3=(poly[3][0]-a)*math.cos(pi_angle)-(poly[3][1]-b)*math.sin(pi_angle)+a
[0051]
y3=(poly[3][0]-a)*math.sin(pi_angle)+(poly[3][1]-b)*math.cos(pi_angle)+b
[0052]
另外,在预处理过程中,还包括:将四点坐标归一化,得到最小外接矩形的(中心(x,y),(宽,高),旋转角度)。因为长边定义法中的longside和shorside与图像的宽高没有严格的对应关系,因此网络输入的图像尺寸高度必须等于宽度,在数据加载器中使用大量的归一化和反归一化的操作,以及大量涉及到图像宽高度的数据变化。
[0053]
在数据加载器中,采用三类数据增强方式:mosaic,random_perspective以及普通数据增强方式。其中mosaic,仿射矩阵增强都是针对(x_lt,y_lt,x_rb,y_rb)数据格式进行增强,其中mosaic在增强中添加θ维度,将4张图片融合在一张图片里进行计算,通过随机缩放、随机裁减、随机排布的方式进行拼接。丰富检测物体的背景和小目标,并且在计算batch normalization的时候一次会计算四张图片的数据,使得mini-batch大小不需要很大,一个gpu就可以达到比较好的效果。在仿射矩阵增强函数内旋转与形变仿射的变换会引起目标角度上的改变,设置旋转和缩放的仿射矩阵并进行旋转和缩放,行数为3,对角线为1,其余为0的矩阵,随机生成[-degrees,degrees)的实数,即为旋转角度,负数则代表逆时针旋转,获得以(0,0)为中心的旋转仿射变化矩阵,设置裁剪的仿射矩阵系数、平移的仿射系数然后融合仿射矩阵并作用在图片上,最后将角度的增强放在最后的普通数据增强方式中;
[0054]
需要说明的是,本实施例所公开的focus切片操作,是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,没有信息丢失,可以将w、h信息集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的rgb
三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图,特征提取得更加的充分。
[0055]
另外,参见图3,本发明还采用圆形平滑标签技术,将连续的角度进行离散化,180个角度每个角度设置为一类,使得预测正负样本的输出值差别不那么大,从而避免过拟合,提高模型的泛化能力。
[0056]
s2、将所述初始训练图像输入yolov5神经网络中进行训练,在训练过程中分别进行边框中心坐标损失、边框宽高损失、θ角度分类损失、置信度损失计算;
[0057]
在本步骤中,所述yolov5神经网络包括:backbone层,用于实现初始训练图片的特征提取;
[0058]
neck层,用于裁剪图像特征,并将裁剪后的图像特征传递到head层;
[0059]
head,对图像特征进行预测,对于每个anchor point(锚点)生成3种scale
×
3种ratio
×
6种角度的anchor框;
[0060]
在本实施例中,选择是cspdarknet53网络作为backbone,如图3所示,拥有更高的的网络输入尺度(分辨率)—用于检测不同尺度的物体,更多的层数,从而拥有更大的感受野以覆盖扩大尺度的网络输入以及更多的参数,提高模型在单个图像中检测不同大小的多个对象的能力;
[0061]
对于head层,通过卷积操作输出我们想要尺寸的tensor(张量),也是网络原始输出,将θ转为分类问题,每个anchor负责预测的参数数量为(x_c y_clongside shortside score)+num_classes+angle_classes。修改detect类的构造函数,增加180个角度分类通道;
[0062]
anchor在neck部分生成的featuremap上裁剪特征,并提交给后续网络。通过更精准的标注方式,提供给网络更少的冗余信息。设计anchor的生成方式越符合目标特征,就越利于网络的收敛,因此选择每个anchor point(锚点)生成3种scale
×
3种ratio
×
6种角度的anchor框(目的框)。
[0063]
可选的,在训练过程中通过下式计算边框中心坐标损失:
[0064][0065]
式中,(xi,yi)是预测边界框的位置,是从训练数据中得到的实际位置,表示该单元格i中的第j个边界框预测变量,λ为给定的常数,b为边界框预测值,s2为网格单元,该等式计算了相对于预测的边界框位置(xi,yi)的loss数值,该函数计算了每一个网格单元(i=0,
…
,s2)的每一个边界框预测值(j=0,...,b)的总和;
[0066]
表示该单元格i中的第j个边界框预测变量对此object预测负责。就是第i个网格单元中的b个bounding box中与该物体的ground truth box的iou在所有bounding box中与该物体的ground truth box中的iou最大,那么负责对object进行预测。
[0067]
定义如下:
[0068]
如果网格单元i中存在目标,则第j个边界框预测值对该预测有效并记为1。
[0069]
如果网格单元i中不存在目标并记为0。
[0070]
对每一个网格单元yolo预测到对个边界框。在训练时,我们对每一个目标只希望有一个边界框预测器。我们根据哪个预测有最高的实时iou和基本事实,来确认其对于预测一个目标有效。
[0071]
可选的,在训练过程中通过下式计算边界框的宽高损失:
[0072][0073]
式中,wi为宽的预测值,为宽的实际值,hi为高的预测值,为高的实际值。
[0074]
通过预测边界框的宽度和高度的平方根,而不是直接预测宽度和高度,用为同样的宽和高对于小边界框的精度影响更大。同时也将θ视为分类任务来处理,相当于将角度信息与边框参数信息解耦,所以旋转框的损失计算部分也分为角度损失和水平边框损失两个部分,因此边框回归损失部分依旧采用iou/giou/ciou/diou损失函数。
[0075]
可选的,在训练过程中通过下式对预测的类别做损失:
[0076][0077]
进行判断是否有无目标损失,从而预测iou的真实预测值,同时归一化后又开方,目的是使变化更平缓。采用交叉熵损失,在目标检测中,采用二元交叉熵损失,对每一个类别计算交叉熵损失,进行求和。
[0078]
可选的,在训练过程中通过下式对预测的置信度做损失:
[0079][0080]
此处我们计算了与每个边界框预测值的置信度得分相关的损失。c是置信度得分,是预测边界框与基本事实的交叉部分,当在一个单元格中有对象时,等于1,否则取值为0。
[0081]
上述公式λ
coord
和λ
noobj
为平衡系数,用来平衡各个损失之间的权重,这对于提高模型的稳定性是十分可靠度的。最高惩罚(λ
coord
=5)是对于坐标预测,当没有探测到目标时,即为最低的置信度预测惩罚(λ
noobj
=0.5),以此降低没有物体的网络权重。同时在yolov5中gt水平边框与预测水平边框的iou/giou/ciou/diou值作为该预测框的置信度分支的权重系数,也就是完全解耦预测角度与预测置信度之间的关联。
[0082]
s3、基于损失计算结果,所述yolov5神经网络输出预测边框的六参数。
[0083]
可选的,所述yolov5神经网络的输出为[classid,x_c,y_c,longside,shortside,θ],式中,classid为类别的编号,,x_c为目标的中心点所处的x轴坐标,y_c为目标的中心点所处的y轴坐标,longside为旋转矩形框的最长边,shortside是与最长边对应的另一边,θ为x轴顺时针旋转遇到最长边所经过的角度。
[0084]
综上,本发明所提供的基于yolov5的遥感有向目标检测方法,能够更准确的提供目标方向和位置,具有重要的民用和军事价值。在民用领域,可以为地质分析,抗震救灾,监控特定港口或海域的海运交通,辅助遇难船只的救援,打击非法捕鱼、非法倾倒油污、走私
和海盗等方面提供重要的信息支撑;军事领域,可以监视敌方重点港口和海域的舰船部署,分析敌方的海上作战实力,评估战时海上打击效果,形成海上作战情报等。同时该模型不仅可以充分挖掘同类目标之间的相似信息,而且可以在人工标注数据较少的情况下,较为精确的检测高分遥感图像中任意方向的地物目标,规避由于类内目标多样性引起的误检。
[0085]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1