一种训练眼底图像分割模型的方法以及动静脉分割方法与流程
1.本发明涉及医疗图像处理领域,具体来说涉及眼底图像分割领域,更具体地说,涉及一种训练眼底图像分割模型的方法以及动静脉分割方法。
背景技术:
2.视网膜是全身唯一可以直接观察到血管和神经的部位。许多心血管疾病会反映在视网膜血管的变化中,包括动脉和静脉。对于不同的心血管疾病,动脉和静脉的表现也不相同。大量的研究表明,视网膜动静脉的不对称性变化与多种心血管疾病有关。此外,临床研究还发现,视网膜小动脉口径变窄与高血压风险相关。因此,对眼底的动静脉的自动精确分割具有重要的临床意义。
3.最近,人工智能,特别是基于深度学习方法在许多计算机视觉任务中都显示出了它的卓越之处,包括图像分割领域。目前,已经提出了许多针对医疗影像的区域分割的方法。但现有的其它基于神经网络的分割训练方法,使用传统的分割损失评估方法,只适用精准的分割标注数据集。
4.现有技术的一种方法是让人类专家对训练集中所有的眼底图像进行标注;但是眼底的动脉和静脉,由于其形状结构一致,且像素颜色相近,所以有些区域,即使人类专家也难于区分,难以生成精确分割标注的数据集,影响模型的精度。
5.现有技术的另一种方法是让多个人类专家分别基于自己的理解对训练集中的各眼底图像分别进行标注,然后基于多数意见形成新标签,但这样仍存在较多的噪声,难以生成精确分割标注的数据集,影响模型的精度。
技术实现要素:
6.因此,本发明的目的在于克服上述现有技术的缺陷,提供一种训练眼底图像分割模型的方法以及动静脉分割方法。
7.本发明的目的是通过以下技术方案实现的:
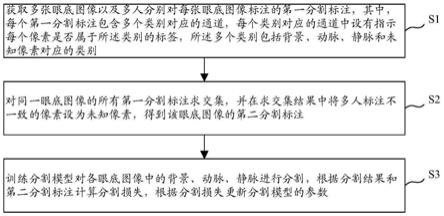
8.根据本发明的第一方面,提供一种训练眼底图像分割模型的方法,包括:获取多张眼底图像以及多人分别对每张眼底图像标注的第一分割标注,其中,每个第一分割标注包含多个类别对应的通道,每个类别对应的通道中设有指示每个像素是否属于所述类别的标签,所述多个类别包括背景、动脉、静脉和未知像素对应的类别;对同一眼底图像的所有第一分割标注求交集,并在求交集结果中将多人标注不一致的像素设为未知像素,得到该眼底图像的第二分割标注;训练分割模型对各眼底图像中的背景、动脉、静脉进行分割,根据分割结果和第二分割标注计算分割损失,根据分割损失更新分割模型的参数。
9.在本发明的一些实施例中,所述分割损失根据分割结果和第二分割标注中背景、动脉、静脉对应的通道进行计算,并且在计算分割损失时忽略所有未知像素处的损失。
10.在本发明的一些实施例中,在第一分割标注、第二分割标注中,若像素属于一个类别,则该类别对应的通道中所述像素对应的标签为1,否则为0;所述在计算分割损失时忽略
所有未知像素处的损失包括:获取第二分割标注中未知像素对应的通道中标签的值并进行翻转,得到损失计算用掩模;将每个像素处的损失与所述损失计算用掩模中相应位置的掩模值的乘积进行求和,得到所述分割损失。
11.在本发明的一些实施例中,所述分割损失的计算方式为:
[0012][0013]
其中,c代表通道的序号,用0、1、2分别表示背景、动脉、静脉对应的通道,h表示图像中指示像素高度位置的索引,w表示图像中指示像素宽度位置的索引,q
c,h,w
表示h,w位置的像素在第二分割标注的通道c中的标签,p
c,h,w
表示h,w位置的像素在分割结果的通道c中的预测值,v
h,w
表示h,w位置的像素在损失计算用掩模中的掩模值,v
h,w
∈{0,1},若位于h,w位置的像素属于未知像素,则该掩模值为0,否则为1。
[0014]
根据本发明的第二方面,提供一种眼底图像的动静脉分割方法,包括:获取待分割的眼底图像;利用第一方面的方法训练得到的分割模型对所述待分割的眼底图像中的背景、动脉、静脉对应的类别进行分割,得到所述眼底图像的分割结果。
[0015]
根据本发明的第三方面,提供一种测量动静脉管径比的方法,包括:获取待分析的眼底图像;利用第一方面的方法训练得到的分割模型对所述待分析的眼底图像中的背景、动脉、静脉对应的类别进行分割,得到所述眼底图像的分割结果;对所述待分析的眼底图像进行感兴趣区域定位,得到感兴趣区域的位置信息;根据分割结果和感兴趣区域的位置信息,确定感兴趣区域内的动静脉管径比。
[0016]
在本发明的一些实施例中,对所述待分析的眼底图像进行感兴趣区域定位,得到感兴趣区域的位置信息包括:利用预先训练的视盘分割模型对待分析的眼底图像进行分割,得到视盘区域;确定视盘区域的中心点并以其为圆心生成环形区域作为感兴趣区域,环形区域的内圈半径为视盘的参考尺寸的第一预定倍数,外圈半径为视盘的参考尺寸的第二预定倍数。
[0017]
在本发明的一些实施例中,所述根据分割结果和感兴趣区域的位置信息,确定感兴趣区域内的动静脉管径比包括:根据感兴趣区域的位置信息从分割结果中截取感兴趣区域内的血管片段;计算各血管片段的半径,按照半径由大到小排序分别取动脉和静脉对应的血管片段中排序靠前的预定数量的血管片段用于计算动静脉管径比。
[0018]
根据本发明的第四方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储可执行指令;所述一个或多个处理器被配置为经由执行所述可执行指令以实现第一方面、第二方面或者第三方面所述方法的步骤。
[0019]
与现有技术相比,本发明的优点在于:
[0020]
本发明获得的第一分割标签中具有未知像素对应的通道,由此,标注者在标注时不确定像素类别时可以将其分到未知像素对应的通道,而不用强行分到其并不确定的某些类别(比如动脉、静脉、背景),由此避免训练时引入过多的噪声,减少对模型训练精度的影响,提高训练的分割模型准确度;
[0021]
本发明还对多个标注者(如n个医生)的标注信息进行结合(即根据多个第一分割标签生成第二分割标签),在背景、动脉、静脉对应通道中仅保留多个标注者意见统一的标签,使得有效区域的标签的准确度更高,进一步减少噪声,使得训练的分割模型准确度更
高;
[0022]
本发明提出了忽略不确定性(即忽略未知像素)的损失评估方法进行分割模型训练,使得模型在训练中减少不确定性标签噪声的干扰,使得损失评估值更准确,有利于分割模型性能的提升。
附图说明
[0023]
以下参照附图对本发明实施例作进一步说明,其中:
[0024]
图1为根据本发明实施例的训练眼底图像分割模型的方法的流程示意图;
[0025]
图2为根据本发明实施例的训练眼底图像分割模型的方法中进行损失计算的示意图;
[0026]
图3为根据本发明实施例的第二分割标注的局部示意图以及损失计算用掩模的局部示意图;
[0027]
图4为眼底相机采集到的一张示意性的眼底相片;
[0028]
图5为预处理后得到的眼底图像;
[0029]
图6为根据本发明实施例的训练眼底图像分割模型的方法得到分割模型对图5所示眼底图像进行分割后得到的分割结果;
[0030]
图7为对感兴趣区域进行定位后得到的感兴趣区域的位置信息的示意图;
[0031]
图8为根据本发明实施例的感兴趣区域内的血管片段;
[0032]
图9为对图5所示眼底图像中的血管提取的骨架的示意图;
[0033]
图10为管径值测量所选取的血管以及对应中心线的示意图;
[0034]
图11为根据本发明实施例的训练眼底图像分割模型的方法得到分割模型与现有基础分割方法对应的分割模型的分割效果对比的roc曲线;
[0035]
图12为根据本发明实施例的训练眼底图像分割模型的方法得到分割模型与现有基础分割方法对应的分割模型的分割效果的可视化对比示意图。
具体实施方式
[0036]
为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0037]
如在背景技术部分提到的,现有技术难以生成精确分割标注的数据集,影响模型的精度。现有方法中,如果要进行分割标注,通常只给出任务所需的标注类别(如本发明的背景像素、动脉像素和静脉像素),标注者仅在这些所关注的类别中对像素进行标注,但是,实际上,由于拍摄效果和/或标注者认知水平的原因,必然有些像素在标注时实际上不容易分类到背景像素、动脉像素和静脉像素中,但因为未提供未知像素对应的类别,标注者不得不将其标注到背景像素、动脉像素或静脉像素中,这样会极大地影响模型的性能。基于上述存在的问题,除背景像素、动脉像素和静脉像素对应的标注通道外,本发明还提供未知像素对应的通道,标注人员可以将其难以确定的像素标注为未知像素,而且,本发明联合多个标注人员的标注(本技术称为第一分割标注),将多个标注人员标注不一致的部分再归类为未知像素,从而得到具有更精准的第二分割标注,基于第二分割标注来训练模型,从而得到精
度更高的分割模型。
[0038]
在对本发明的实施例进行具体介绍之前,先对其中使用到的部分术语作如下解释:
[0039]
眼底,是指眼球内后部的区域,包括视网膜、视乳头、黄斑、动脉、静脉等解剖结构。在本技术中,主要是为了分割属于动脉和静脉的像素,因此,像素级的类别包括动脉、静脉、背景和未知像素对应的类别;在标注时,视网膜、视乳头、黄斑等解剖结构可以归于背景对应的类别;标注者难以区分是动脉、静脉、背景的像素或者多人标注不一致的像素归为未知像素。
[0040]
视盘(optic disc),是指视神经盘,也叫视神经乳头。视网膜由黄斑向鼻侧约3mm处有一直径约1.5mm,境界清楚的淡红色圆盘状结构,称为视神经盘,简称视盘。
[0041]
血管的骨架,是指各血管的中心线构成的骨架,也称血管的骨架线或者中心线。通常是把输入的图像中具有一定宽度的血管轮廓去掉边缘的像素最终变为宽度仅为一个像素的骨架。
[0042]
根据本发明的一个实施例,本发明的训练眼底图像分割模型的方法的一个概括的实施步骤如图1所示,包括步骤s1:获取多张眼底图像以及多人分别对每张眼底图像标注的第一分割标注,其中,每个第一分割标注包含多个类别对应的通道,每个类别对应的通道中设有指示每个像素是否属于所述类别的标签,所述多个类别包括背景、动脉、静脉和未知像素对应的类别;s2:对同一眼底图像的所有第一分割标注求交集,并在求交集结果中将多人标注不一致的像素设为未知像素,得到该眼底图像的第二分割标注;s3:训练分割模型对各眼底图像中的背景、动脉、静脉进行分割,根据分割结果和第二分割标注计算分割损失,根据分割损失更新分割模型的参数。
[0043]
根据本发明的一个实施例,多种类型的分割网络均可用于眼底图像的分割,例如,fcn、deeplabv3、全卷积的u型连接分割网络(如:unet、unet++、denseunet)。
[0044]
根据本发明的一个实施例,本发明可采用任意眼底图像的数据集。但是,分割标注需要重新设置。例如,可采用kaggle平台(一个大型的国际数据科学平台)公开的眼底图像数据,随机采样100张,并邀请多位眼科医学专家分别对每张眼底图像进行背景、动脉、静脉、未知像素的分割标注,得到每张眼底图像对应的第一分割标注,所有眼底图像及其中每张眼底图像对应的多张第一分割标注组成原始数据集。对于原始数据集中每张眼底图像,对该眼底图像的所有第一分割标注求交集,并在求交集结果中将多人标注不一致的像素设为未知像素,得到该眼底图像的第二分割标注。即:将所有第一分割标注中标注一致的部分予以保留,用以设置第二分割标注的背景、动脉、静脉和未知像素,标注不一致的部分设置为第二分割标注的未知像素。
[0045]
作为示例,以三个医学专家进行标注为例,获得第二分割标注的过程包括:
[0046]
1)获得多个医学专家的第一分割标注:首先让三个医学专家对同一张眼底图像进行分割标注。对于每一张眼底图像,三个医学专家分别进行独立标注,标注背景、动脉、静脉以及未知像素,得到第一分割标注其中,i代表眼底图像的序号,l代表医学专家的序号,l∈{1,2,3}。标注的每个第一分割标注包含背景、动脉、静脉以及未知像素4个类别的像素级的分割标签(即类别的标签)。
[0047]
2)生成第二分割标注(即基于第一分割标注中4个类别的分割标签生成新标签):步骤1)中,每一张眼底图像得到4个分割标注,即每张眼底图像的每个像素包含4个类别的标签。对于眼底图像的每个像素,如果4个类别的标签完全相同,则该类别作为第二分割标注中对应像素的类别,如果4个类别的标签不是完全相同的,则用未知像素作为对应像素的类别。即生成的每张眼底图像的第二分割标注中,背景、动脉以及静脉这三个分割标签是3个医学专家标注一致的,其余部分均作为未知像素类别。
[0048]
根据本发明的一个实施例,在训练模型的过程中,将多张眼底图像以及对应的第二分割标注(对应于新标签)作为训练数据集。训练流程如图2所示,输入眼底图像xi,分割模型对眼底图像xi进行分割,得到分割结果yi,基于该分割结构和新标签进行损失评估,得到分割损失,根据分割损失计算梯度并反向传播更新模型参数。
[0049]
作为示例,训练时,输入的是尺寸为1024
×
1024
×
3的rgb眼底图像xi,1024
×
1024表示图像的长和宽,3表示红绿蓝三个通道;输出是1024
×
1024
×
3的分割结果yi,1024
×
1024表示图像的长和宽,3表示背景、动脉、静脉对应的三个通道,即分割结果yi中包含背景、动脉以及静脉的像素分类信息。基于输出的分割结果yi和新标签计算损失值,根据损失值来优化分割模型的权重参数。
[0050]
在一个实施例中,可以基于所有像素的损失来计算分割损失,即分割损失的计算方式为:其中,其中,c代表通道的序号,用0、1、2分别表示背景、动脉、静脉对应通道,h表示图像中指示像素高度位置的索引,w表示图像中指示像素宽度位置的索引,q
c,h,w
表示h,w位置的像素在第二分割标注的通道c中的标签,p
c,h,w
表示h,w位置的像素在分割结果的通道c中的预测值。
[0051]
但是,基于所有像素的损失来计算分割损失时,容易受到多个标注者标注意见不统一处对应损失的影响,从而导致模型的精度降低。因此,根据本发明的另一个实施例,分割损失根据分割结果和第二分割标注中背景、动脉、静脉对应的多个通道进行计算,并且在计算分割损失时忽略属于未知像素处的损失。由此,本发明可以忽略不确定性,使得模型在训练中减少不确定性标签噪声的干扰,使得损失评估值更准确,有利于分割模型性能的提升。例如,在计算分割损失时可根据未知像素对应的通道计算的损失计算用掩模来忽略属于未知像素处的损失。优选的,分割损失的计算方式为:
[0052][0053]
其中,c代表通道的序号,用0、1、2分别表示背景、动脉、静脉对应的通道,h表示图像中指示像素高度位置的索引,w表示图像中指示像素宽度位置的索引,q
c,h,w
表示h,w位置的像素在第二分割标注的通道c中的标签,p
c,h,w
表示h,w位置的像素在分割结果的通道c中的预测值,v
h,w
表示h,w位置的像素在损失计算用掩模中的掩模值,v
h,w
∈{0,1},若位于h,w位置的像素属于未知像素,则该掩模值为0,否则为1。q
c,h,w
直接采用第二分割标注中背景、动脉、静脉对应通道中的值,损失计算用掩模中的值为第二分割标注中未知像素对应
通道中的值的翻转值,即将未知像素对应的通道中的原有的0变为1,原有的1变为0,得到损失计算用掩模,从而使得未知像素处的掩模值为0,在损失加和时该未知像素处的损失会乘以0,从而被忽略。为了便于理解此处的原理,参见图3,其以包含四个像素的图像为例,简化地示出了图像局部的2x2的图像矩阵对应的第二分割标注(局部)以及损失计算用掩码(局部),其中左上角的像素为背景像素,右上角的像素为动脉像素,左下角的像素为静脉像素,右下角的像素为未知像素;图3a示出了第二分割标注的4个通道中局部的4个像素位置的标签,所代表的含义为左上角的像素属于背景,右上角的像素属于动脉,左下角的像素属于静脉,右下角的像素属于未知像素,对未知像素对应的通道中的值进行翻转,则得到图3b所示的损失计算用掩码,从而在计算分割损失时未知像素处(右下角的像素)的损失会乘以掩模值0,则会被忽略。本技术使用忽略不确定性的损失评估的方式(即忽略未知像素处的损失)训练分割模型,能够自动分割出更精确的动静脉区域,具有很大的临床意义。
[0054]
应当理解,以上两种计算分割损失的计算公式是针对单张眼底图像计算的分割损失,如果采用随机梯度下降,则直接使用相应公式求梯度并反向传播更新模型参数;如果采用批量梯度下降,则对一批中的多张图像,将按照上述公式分别计算其中单张眼底图像的分割损失,求和得到最终的分割损失(或者求和后求均值得到最终的分割损失),然后根据最终的分割损失求梯度并反向传播更新模型参数。
[0055]
本发明的技术方案至少能够实现以下有益技术效果:
[0056]
本发明获得的第一分割标签中具有未知像素对应的通道,由此,标注者在标注时不确定像素类别时可以将其分到未知像素对应的通道,而不用强行分到其并不确定的某些类别(比如动脉、静脉、背景),由此避免训练时引入过多的噪声,减少对模型训练精度的影响,提高训练的分割模型准确度;
[0057]
本发明还对多个标注者(如n个医生)的标注信息进行结合(即根据多个第一分割标签生成第二分割标签),在背景、动脉、静脉对应通道中仅保留多个标注者意见统一的标签,使得有效区域的标签的准确度更高,进一步减少噪声,使得训练的分割模型准确度更高;
[0058]
本发明提出了忽略不确定性(即忽略未知像素)的损失评估方法进行分割模型训练,使得模型在训练中减少不确定性标签噪声的干扰,使得损失评估值更准确,有利于分割模型性能的提升。
[0059]
本发明的一个直接的应用场景是直接根据该分割模型获得可区分动静脉的分割结果,以便医生或者后续的应用程序根据该分割结果进行分析。因此,根据本发明的一个实施例,本发明还提供一种眼底图像的动静脉分割方法,包括:获取待分割的眼底图像;利用本发明的训练眼底图像分割模型的方法训练得到的分割模型对所述待分割的眼底图像中的背景、动脉、静脉对应的类别进行分割,得到分割结果。
[0060]
另外,也可结合具体的分析场景来进一步利用分割结果,例如,心血管疾病是我国居民首要死因,早期识别心血管疾病高危个体是心血管疾病防治工作的关键所在,是当前国内外相关疾病防治指南的重要内容。大量临床研究表明,眼底动静脉血管管径的变化在一定程度上能反映出高血压、冠心病、脑卒中等心脑血管疾病病发的潜在风险。因此,本发明可使用深度学习技术对视网膜中的动静脉和视盘进行分割,然后对感兴趣区域的动脉和静脉分别进行管径的自动测量,从而高效、准确地得到管径比值,降低医务人员劳动强度、
辅助医务人员对患者病情进行更准确的分析。根据本发明的一个实施例,本发明还提供一种测量动静脉管径比的方法,包括:b1、获取待分析的眼底图像;b2、利用前述眼底图像的动静脉分割方法训练得到的分割模型对所述待分析的眼底图像中的背景、动脉、静脉对应的类别进行分割,得到分割结果;b3、对所述待分析的眼底图像进行感兴趣区域定位,得到感兴趣区域的位置信息;b4、根据分割结果和感兴趣区域的位置信息,确定感兴趣区域内的动静脉管径比。
[0061]
在步骤b1中,待分析的眼底图像是对眼底图像采集的眼底相片进行预处理后得到的。例如,眼底相片的示意图如图4所示,预处理包括对眼底相片去除纯黑边界以及进行直方图均衡化处理。去除纯黑边界可基于像素值判断的方法实现,包括:从眼底相片的上、下、左、右四个边界分别往图像中心逐行或逐列进行像素判断,如果整行或整列都是黑色像素,则去除该行或该列。以上方为例,即逐行往下进行整行的像素值判断,去除纯黑边界。预处理后得到的待分析的眼底图像如图5所示。
[0062]
在步骤b2中,用前述眼底图像的动静脉分割方法训练得到的分割模型对所述待分析的眼底图像中的背景、动脉、静脉对应的类别进行分割,得到背景、动脉、静脉的分割结果。对图5进行分割后的结果如图6所示,其中,深灰色对应静脉,灰白色对应动脉。应当理解,实际上,在输出显示结果时,可以对动脉、静脉采用不同的颜色区分显示,以便于观察,例如,动脉采用红色、静脉采用蓝色。
[0063]
在步骤b3中,对所述待分析的眼底图像进行感兴趣区域定位,得到感兴趣区域的位置信息。根据本发明的一个实施例,该感兴趣区域定位可以采用预训练的视盘分割模型来先确定视盘的位置。预训练的视盘分割模型可以采用现有的方法训练,例如,预先人工标注训练集中的眼底图像,形成视盘分割标签,该视盘分割标签包括两个通道,分别指示相应像素是否属于视盘或者非视盘对应的类别,用该训练集训练视盘分割模型分割视盘和非视盘区域,根据视盘分割结果和视盘分割标签计算损失值,根据损失值求梯度和更新视盘分割模型的模型参数。然后,确定视盘区域的中心点以其为圆心生成环形区域作为感兴趣区域,环形区域的内圈半径为视盘的参考尺寸的第一预定倍数,外圈半径为视盘的参考尺寸的第二预定倍数。例如,取中心点作为圆点p,取过圆点的横轴和纵轴的长度的平均值作为视盘的参考尺寸d(一些文献称为视盘的直径)。假设第一预定倍数设为1,第二预定倍数设为1.5,则以p为圆点,以1倍d至1.5倍d作为半径形成的环形区域生成感兴趣区域的位置信息,参见图7,中间类椭圆的灰白色区域为视盘,1d-1.5d的环形区域为感兴趣区域。
[0064]
在步骤b4中,根据分割结果和感兴趣区域的位置信息,确定感兴趣区域内的动静脉管径比。优选的,步骤b4包括根据感兴趣区域的位置信息从分割结果中截取感兴趣区域内的血管片段;计算各血管片段的半径,按照半径由大到小排序分别取动脉和静脉对应的血管片段中排序靠前的预定数量的血管片段用于计算动静脉管径比。如图8所示,本模块取动静脉的分割结果以及感兴趣区域的位置信息,得到感兴趣区域内的动脉和静脉的血管片段,其中灰白色的片段为动脉血管片段,深灰色的片段为静脉血管片段。本发明使用已有的骨架提取算法,对动脉以及静脉对应的分割结果进行处理,得到动脉和静脉对应血管的骨架(如图9所示),作为血管的中心区域。然后使用已有的距离计算算法,得到血管的每个中心点到背景区域的最短距离,作为血管在该处的半径值。本发明取目标血管的片段的每个中心点的距离值的平均值作为该血管片段的半径值。如图10所示,有白色中心线的血管即
为所选择的血管,血管中标记的白点为血管的中心点。测量每个白点到背景的最短距离即血管的管径的半径。若预定数量为2,则最后按照取动脉的2个最大管径值的平均值以及静脉的2个最大管径值的平均值,两者相除,得到动静脉管径比。
[0065]
为了验证本发明的眼底图像的分割效果,申请人进行了相应的实验:
[0066]
1)实验方案说明:
[0067]
本次实验采用的模型为unet,数据集为kaggle(一个大型的国际数据科学平台)公开的眼底图像数据,随机采样100张,并邀请3位北京大学医学院的教授专家分别对每一张进行动静脉分割标注,当做训练数据集。采用公开的drive(衡量视网膜血管分割方法性能好坏的最常用数据库)当做标准测试数据集。然后将本发明的方法与现有的基础分割方法进行实验效果对比,方案详情如表1所示:
[0068]
表1:实验方案的详情对比(每个方法的训练过程参数相同)
[0069][0070]
2)实验结果对比:
[0071]ⅰ、量化指标对比:
[0072]
表2:量化结果对比
[0073][0074][0075]
从量化的结果上看,本发明方法的在多项指标的值都比现有基础分割方法高好几个百分点,其中miou(平均交并比)以及auc(roc曲线下的面积)这两个综合性质的量化指标都显著提升。
[0076]ⅱ、roc曲线图对比
[0077]
roc曲线是常用的模型评估指标,曲线下的面积越大,表示模型性能越好。从图11中可以看出,本发明方法(实线)的roc-动脉(对应于图11a)和roc-静脉(对应于图11b)的曲
线效果都更好。
[0078]ⅲ、可视化效果对比:
[0079]
参见图12,其中,图12a是眼底图像,图12b是现有基础分割方法结果的可视化,图12c是本发明方法结果的可视化,图12a和图12c中,颜色相对较深的为静脉,相对较浅的为动脉。
[0080]
从可视化的情况来看,本发明方法的结果(图12c)动静脉的线条更贴合实际血管走向,并且明显更少的动静脉混合情况(一根血管分割同时存在动脉和静脉的结果)。
[0081]
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
[0082]
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
[0083]
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
[0084]
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1