一种面向向量处理器的池化向量化实现方法
1.本发明涉及到深度学习、卷积神经网络领域技术领域,特别是涉及一种面向向量处理器的池化向量化实现方法。
背景技术:
2.卷积神经网络是当前深度学习模型中应用最广泛的一种神经网络模型,其在如图像分类等领域中特定任务上的性能已经超越了人类。卷积神经网络模型一般由卷积层、激活层、池化层以及全连接层等构成。
3.池化层位于卷积层之后,用于对卷积层提取到的特征进行聚合统计。卷积神经网络中,利用卷积操作对输入图像进行特征提取之后,将会产生多个特征图,利用所有的特征则计算量将会过于巨大,并且还可能会产生过拟合的问题,对不同位置的局部特征进行聚合统计可以有效解决这个问题。通常有两种方法进行聚合,分别是对特征图上不同位置的局部特征取最大值或平均值,即最大池化(max
‑
pooling)或平均值池化(average
‑
pooling)。相比之前提取到的特征图,通过池化之后的数据不仅具有更低维度,而且计算量显著减少,同时还避免了一定程度的过拟合改善了分类效果。总的来说,池化层具有降信息冗余、减少计算量以及防止过拟合等作用,是卷积神经网络的重要组成。
4.向量处理器是一种新型的体系结构,如图4所示,包含进行标量运算的标量处理单元(spu)和进行向量运算的向量处理单元(vpu),以及负责数据传输的直接存储器访问(direct memory access,dma)部件等。spu由标量处理部件spe和标量存储器sm构成。vpu由m个向量处理部件vpe和阵列存储器am构成,m个向量处理部件vpe以单指令多数据(simd)的方式协作运行,支持指定vpe部件的关闭与开启,但不支持多个vpe之间的数据交互。dma部件负责sm与ddr、am与ddr之间的数据传输。
5.目前,专利《cn 108205703 a
‑
多输入多输出矩阵平均值池化向量化实现方法》中提到的方法存在以下问题:(1)将输入特征图导入向量处理器核am空间之前,会对输入特征图进行重排,见第2页s2
‑
s3,极大地影响了处理效率;(2)如第二页第4、6、7页显示,分别要求特征图的高度和宽度相等,池化的水平移动步长和垂直移动步长相同、池化窗口高度和宽度相等,不支持不相等或者不相同的情况,即不支持非方阵的情况;(3)在卷积神经网络中,常通过对特征图进行填充(padding)来保持特征图边界上的有效信息,目前该文献不支持填充(padding)的情况。
6.因此,提供一种支持特征图填充、无需对特征图重排,可以支持非方形特征图、非方形移动步长、非方形池化窗口的面向向量处理器的池化向量化实现方法是本领域技术人员亟待解决的问题。
技术实现要素:
7.本发明的目的在于提供一种面向向量处理器的池化向量化实现方法,该方法逻辑清晰,安全、有效、可靠且操作简便,既能支持非方形特征图、非方形移动步长、非方形池化
窗口,又能支持特征图填充,无需对特征图重排,提高池化处理效率。
8.基于以上目的,本发明提供的技术方案如下:
9.一种面向向量处理器的池化向量化实现方法,包括如下步骤:
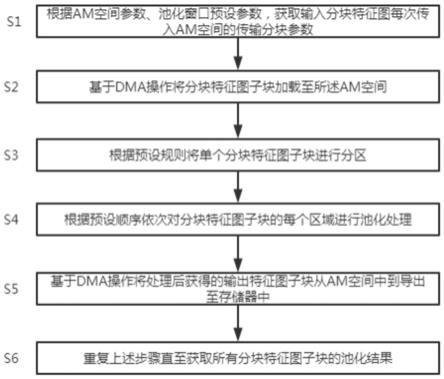
10.s1.根据am空间参数、池化窗口预设参数,获取输入分块特征图每次传入am空间的传输分块参数;
11.s2.基于dma操作将分块特征图子块加载至所述am空间;
12.s3.根据预设规则将单个所述分块特征图子块进行分区;
13.s4.根据预设顺序依次对分块特征图子块的每个区域进行池化处理;
14.s5.基于dma操作将处理后获得的输出特征图子块从所述am空间中到导出至存储器中;
15.s6.重复步骤s1
‑
s5直至获取所有分块特征图子块的池化结果。
16.优选地,所述am空间参数具体为am空间大小;
17.所述池化窗口预设参数具体为池化窗口高度、宽度、水平移动步长和垂直移动步长;
18.所述输入分块特征图每次传入am空间的传输分块参数具体为所述输入分块特征图传输子块的高度和宽度。
19.优选地,单个所述分块特征图子块具体为所述输入分块特征图传输子块的高度、所述输入分块特征图传输子块的宽度与向量处理器向量单元并行处理的数据宽度的乘积大小的输入特征图元素。
20.优选地,所述步骤s3具体为:
21.对单张所述分块特征图按照填充情况分为上、中、下、左、右共五个区;
22.步骤s4中预设顺序为上、下、左、右、中。
23.优选地,所述步骤s4具体包括:
24.a1.获取当前所在区的池化窗口非填充向量个数;
25.a2.初始化向量寄存器v0与i=0;
26.a3.从当前池化窗口中加载第i个l长的数据到向量寄存器v1中,其中l具体为向量处理器单元并行处理的数据宽度;
27.a4.根据池化模式选取预设计算规则,获取池化结果,并将池化结果存储在所述向量寄存器v0中;
28.a5.递增i,若i<非填充向量个数则返回步骤a3;
29.a6.根据所述池化模式处理所述向量寄存器v0中的每个元素,并将处理结果存储在所述向量寄存器v0中;
30.a7.存储所述向量寄存器v0至所述am空间中。
31.优选地,所述步骤a1还包括:若所述当前所在区为上区或下区,则获取第一个池化窗口的非填充向量个数与最后一个池化窗口的非填充向量个数。
32.优选地,所述池化模式具体为:平均值池化与最大值池化;
33.所述步骤a4中根据池化模式选取预设计算规则,获取池化结果具体为:
34.若所述池化模式为平均值池化,则获取所述向量寄存器v0与所述向量寄存器v1之和;
35.若所述池化模式为最大值池化,则获取所述向量寄存器v0与所述向量寄存器v1中分别对应的元素最大值。
36.优选地,所述步骤a6中根据所述池化模式,处理所述向量寄存器v0中的每个元素具体为:若所述池化模式为平均值池化,则获取所述向量寄存器v0中的每个元素与所述池化窗口宽度、高度的乘积之间的商值;
37.若所述池化模式为最大值池化,则跳过处理步骤。
38.本发明所提供的面向向量处理器的池化向量化实现方法,是通过am空间参数、池化窗口预设参数从而计算获取输入分块特征图每次传入am空间的传输分块参数;根据分块参数对输出特征图进行分块,得到分块特征图子块;通过dma操作将分块特征图子块加载至am空间中;通过预设规则将单个分块特征图子块进行分区;分区后按照预设顺序对分块特征图子块的每个区域进行池化处理;池化处理后的分块特征图子块为输出特征图子块;通过dma操作将输出特征图子块从am空间中导出至存储器中;多次重复上述步骤,直至获取所有分块特征图子块的池化结果。
39.本技术方案用广泛使用的分块特征图作为池化的输入输出,不用再对特征图进行重排,极大地减少了数据预处理的时间,提升平均值池化的效率;而且本技术方案通过分区后,对分块特征图子块的每个区域进行池化处理,从而支撑非方形特征图、非方形移动步长、非方形池化窗口;同时,分区的预设规则是根据填充情况制定。因此,本技术方案既能支持非方形特征图、非方形移动步长、非方形池化窗口,又能支持特征图填充,无需对特征图重排,可以显著提高池化处理效率。
附图说明
40.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
41.图1为本发明实施例提供的一种面向向量处理器的池化向量化实现方法流程图;
42.图2为本发明实施例提供的一种面向向量处理器的池化向量化实现方法中池化分区的结构示意图;
43.图3为本发明实施例提供的一种面向向量处理器的池化向量化实现方法中步骤s4的流程图;
44.图4为本发明实施例提供的向量处理器的一般体系结构示意图。
具体实施方式
45.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
46.本发明实施例采用递进的方式撰写。
47.本发明实施例提供了一种面向向量处理器的池化向量化实现方法。主要解决现有
技术中,需要对特征图重排导致处理时间较长、对特征图参数有特定要求、不支持填充的技术问题。
48.请参照图1,一种面向向量处理器的池化向量化实现方法,包括如下步骤:
49.s1.根据am空间参数、池化窗口预设参数,获取输入分块特征图每次传入am空间的传输分块参数;
50.s2.基于dma操作将分块特征图子块加载至am空间;
51.s3.根据预设规则将单个分块特征图子块进行分区;
52.s4.根据预设顺序依次对分块特征图子块的每个区域进行池化处理;
53.s5.基于dma操作将处理后获得的输出分块特征图子块从am空间中到导出至存储器中;
54.s6.重复步骤s1
‑
s5直至获取所有分块特征图子块的池化结果。
55.需要说明的是,am(array memory),是指阵列存储器,属于向量处理器上的片上存储空间,可以支持m路vpes的数据同时存取,速度较快。
56.dma(direct memory access)是指直接存储访问,由向量处理器上的标量处理单元spu来进行初始化,负责标量存储器sm与片外ddr、阵列存储器am与片外ddr之间的数据传输。
57.本技术方案用广泛使用的分块特征图作为池化的输入输出,不用再对特征图进行重排,极大地减少了数据预处理的时间,提升平均值池化的效率;而且本技术方案通过分区后,对分块特征图子块每个区域分别进行池化处理,从而支撑非方形特征图、非方形移动步长、非方形池化窗口;同时,分区的预设规则是根据填充情况制定的。因此,本技术方案既能支持非方形特征图、非方形移动步长、非方形池化窗口,又能支持特征图填充,无需对特征图重排,可以显著提高池化处理效率。
58.优选地,am空间参数具体为am空间大小;
59.池化窗口预设参数具体为池化窗口高度、宽度、水平移动步长和垂直移动步长;
60.输入分块特征图每次传入am空间的传输分块参数具体为输入分块特征图传输子块的高度和宽度。
61.实际运用过程中,采用广泛使用的分块特征图作为池化的输入输出,输入数据布局为i[n][c
dl
][h
i
][w
i
][l],池化输出结果也为[n][c
dl
][h
o
][w
o
][l],其中n表示小批量大小,h
i
和w
i
表示池化输入分块特征图的高度和宽度,h
o
和w
o
表示池化输出分块特征图的高度和宽度,l表示向量处理器向量单元并行处理的数据宽度,c
dl
表示特征图的通道数上的分块数,特征图的通道数为c
dl
×
l。
[0062]
优选地,单个分块特征图子块具体为输入分块特征图传输子块的高度、输入分块特征图传输子块的宽度与向量处理器向量单元并行处理的数据宽度的乘积大小的输入特征图元素。
[0063]
实际运用过程中,根据am空间的大小、池化窗口高度h
p
和宽度w
p
、水平s
w
和垂直s
h
移动步长,计算输入分块特征图的高度和宽度上的传输分块参数h
ib
和w
ib
,基于dma操作将分块特征图子块数据h
ib
×
w
ib
×
l,加载到am空间。
[0064]
优选地,步骤s3具体为:
[0065]
对单张分块特征图按照填充情况分为上、中、下、左、右共五个区;
[0066]
步骤s4中预设顺序为上、下、左、右、中。
[0067]
请参照图2,实际运用过程中,对单张特征图按照填充(padding)情况分为上(top)、下(bottom)、左(left)、右(right)以及中(middle)等5个区,对已经导入到am空间的分块特征图子块,按照其覆盖的区依次进行处理。按照上(top)、下(bottom)、左(left)、右(right)以及中(middle)的顺序分别进行处理。上(top)、下(bottom)、左(left)以及右(right)的填充(padding)大小分别为p
top
、p
bottom
、p
left
以及p
right
。图2中,黑色实线所围成的区域表示原始特征图,灰色虚线表示填充后的情况,灰色实线表示分区情况。
[0068]
请参照图3,优选地,步骤s4具体包括:
[0069]
a1.获取当前所在区的池化窗口非填充向量个数;
[0070]
a2.初始化向量寄存器v0与i=0;
[0071]
a3.从当前池化窗口中加载第i个l长的数据到向量寄存器v1中,其中l具体为向量处理器单元并行处理的数据宽度;
[0072]
a4.根据池化模式选取预设计算规则,获取池化结果,并将池化结果存储在向量寄存器v0中;
[0073]
a5.递增i,若i<非填充向量个数则返回步骤a3;
[0074]
a6.根据池化模式处理向量寄存器v0中的每个元素,并将处理结果存储在向量寄存器v0中;
[0075]
a7.存储向量寄存器v0至am空间中。
[0076]
优选地,步骤a1还包括:若当前所在区为上区或下区,则获取第一个池化窗口的非填充向量个数与最后一个池化窗口的非填充向量个数。
[0077]
实际运用过程中,对于步骤a1获取当前所在区的池化窗口非填充向量个数具体的实施操作为:
[0078]
上(top)区处理
[0079]
对于需要上部填充(top padding)的池化窗口均划分为top区;
[0080]
先进行top区第一个池化窗口的处理,其不仅需要top padding,还需要左边填充(left padding),采用向量加载第一个池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算(h
p
‑
p
top
)
×
(w
p
‑
p
left
)次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0081]
根据水平移动步长s
w
,移动到下一个池化窗口位置;
[0082]
采用向量加载当前池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算(h
p
‑
p
top
)
×
w
p
次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0083]
重复移动与计算步骤,直至完成只需top padding的所有池化窗口的处理;
[0084]
进行top区最后一个池化窗口的处理,其不仅需要top padding,还需要右边填充(right padding),采用向量加载top区最后一个池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算(h
p
‑
p
top
)
×
(w
p
‑
p
right
)次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0085]
下(bottom)区处理
[0086]
对于需要下部填充(bottom padding)的池化窗口均划分为bottom区;
[0087]
先进行bottom区第一个池化窗口的处理,其不仅需要bottom padding,还需要left padding,采用向量加载第一个池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算(h
p
‑
p
bottom
)
×
(w
p
‑
p
left
)次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0088]
根据水平移动步长s
w
,移动到下一个池化窗口位置;
[0089]
采用向量加载当前池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算(h
p
‑
p
bottom
)
×
w
p
次,将该计算数据根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0090]
重复移动与计算步骤,直至完成只需bottom padding的所有池化窗口的处理;
[0091]
进行bottom区最后一个池化窗口的处理,其不仅需要bottom padding,还需要right padding,采用向量加载bottom区最后一个池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算(h
p
‑
p
bottom
)
×
(w
p
‑
p
right
)次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0092]
左(left)区处理
[0093]
对于需要左部填充(left padding)并且只需left padding的池化窗口均划分为left区;
[0094]
采用向量加载当前池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算h
p
×
(w
p
‑
p
left
)次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0095]
根据垂直移动步长s
h
,移动到下一个池化窗口位置;
[0096]
重复移动与计算步骤,直至完成只需left padding的所有池化窗口的处理。
[0097]
右(right)区处理
[0098]
对于需要右部填充(right padding)并且只需right padding的池化窗口均划分为right区;
[0099]
采用向量加载当前池化窗口中所有非填充的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算h
p
×
(w
p
‑
p
right
)次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0100]
根据垂直移动步长s
h
,移动到下一个池化窗口位置;
[0101]
重复计算与移动步骤,直至完成只需right padding的所有池化窗口的处理;
[0102]
中(middle)区处理
[0103]
对于不需要任何填充(padding)的池化窗口均划分为middle区;
[0104]
采用向量加载当前池化窗口中所有的元素,并根据池化模式的不同选取不同的预设计算规则进行计算,共计计算h
p
×
w
p
次,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果。
[0105]
根据水平移动步长s
w
,移动到下一个池化窗口位置;
[0106]
重复计算与移动步骤,直至完成一行所有池化窗口的处理;
[0107]
根据垂直移动步长s
h
,移动到下一个池化窗口位置;
[0108]
重复计算与移动步骤,直到完成middle区所有行的所有池化窗口的处理。
[0109]
优选地,池化模式具体为:平均值池化与最大值池化;
[0110]
步骤a4中根据池化模式选取预设计算规则,获取池化结果具体为:
[0111]
若池化模式为平均值池化,则获取向量寄存器v0与向量寄存器v1之和;
[0112]
若池化模式为最大值池化,则获取向量寄存器v0与向量寄存器v1中分别对应的元素最大值。
[0113]
实际运用过程中,在步骤a4中,根据池化模式的不同选取不同的预设计算规则,若是平均值池化,则求v0+v1;若是最大池化,则求v0和v1中对应元素的最大值max(v0,v1)。
[0114]
优选地,步骤a6中根据池化模式,处理向量寄存器v0中的每个元素具体为:若池化模式为平均值池化,则获取向量寄存器v0中的每个元素与池化窗口宽度、高度的乘积之间的商值;
[0115]
若池化模式为最大值池化,则跳过处理步骤。
[0116]
实际运用过程中,在对当前所在区根据池化模式的不同选取不同的预设计算规则进行计算后,将该计算结果根据池化模式的不同选取不同的预设计算规则进行处理得到池化结果具体为:若池化模式为平均值池化,则将累加结果与1/(h
p
×
w
p
)相乘,得到处理后的池化结果;若池化模式为最大值池化,则跳过处理向量寄存器v0中的每个元素的步骤。
[0117]
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令及相关的硬件来完成,前述的程序指令可以存储于计算机可读取存储介质中,该程序指令在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(read only memory,rom)、磁碟或者光盘等各种可以存储程序代码的介质。
[0118]
还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0119]
以上对本发明所提供的一种面向向量处理器的池化向量化实现方法进行了详细介绍。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1