面向向量处理器的低位宽数据矩阵向量化转置方法及系统
1.本发明涉及向量处理器技术领域,尤其涉及一种面向向量处理器的低位宽数据矩阵向量化转置方法及系统。
背景技术:
2.向量处理器是一种新型的体系结构,如图1所示,包含进行标量运算的标量处理单元(spu)和进行向量运算的向量处理单元(vpu),以及负责数据传输的直接存储器访问(direct memory access,dma)部件等。spu由标量处理部件spe和标量存储器sm构成。vpu由l个向量处理部件vpe和阵列存储器am构成,l个向量处理部件vpe以单指令多数据(simd)的方式协作运行,支持指定vpe 部件的关闭与开启,但不支持多个vpe之间的数据交互。单个vpe一次可以处理1个8字节数据(如fp64、int64),也可以处理2个4字节数据(如fp32,int32)。dma部件负责sm与ddr、am与ddr之间的数据传输,其操作的最小粒度也是8字节。
3.矩阵转置是矩阵运算中最常见的一种操作,其效率高低对应用的性能影响较大。对于单个元素位宽为8字节的矩阵来说,只需通过dma操作将数据在向量处理器的am空间与片外ddr之间进行搬移,便可高效完成整个矩阵的转置操作。如上述所述,dma操作的最小粒度是8字节。因此仅通过dma操作的方式来进行矩阵转置操作将不再适合于单个元素位宽为4字节的矩阵。
4.因此,如何高效实现低位宽数据矩阵的转置操作,是一项亟待解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种面向向量处理器的低位宽数据矩阵向量化转置方法,能够高效的实现低位宽数据矩阵的转置操作。
6.本发明提供了一种面向向量处理器的低位宽数据矩阵向量化转置方法,包括:将低位宽数据矩阵存储在双倍速率同步动态随机存储器中;调用直接存储器访问操作,将所述低位宽数据矩阵从所述双倍速率同步动态随机存储器加载到片上空间;在所述阵列存储器空间中,对加载到所述片上阵列存储器空间后的矩阵进行转置处理,得到转置后的矩阵。
7.其中,所述低位宽数据矩阵的维度为;其中,所述调用直接存储器访问操作,将低位宽数据矩阵从双倍速率同步动态随机存储器加载到片上阵列存储器空间,包括:调用直接存储器访问操作,将所述低位宽数据矩阵的子矩阵加载到片上阵列存储器空间中,变为,其中
、,和的大小均由阵列存储器的空间大小来决定,其中l表示向量处理单元中向量处理部件的数量。
8.优选地,所述在所述阵列存储器空间中,对加载到所述片上阵列存储器空间后的矩阵进行转置处理,得到转置后的矩阵,包括:步骤1、初始化i=0,其中,i表示m维上的块index;步骤2、初始化j=0,其中,j表示n维上的块index;步骤3、将所述阵列存储器空间中的低位宽数据矩阵的大小为的子块矩阵的数据加载到4个向量寄存器vr0、vr1、vr2和vr3中;步骤4、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr4中;步骤5、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr6中;步骤6、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr5中;步骤7、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr7中;步骤8、将向量寄存器vr4和向量寄存器vr5中的数据以地址取模方式交错地存回阵列存储器空间;步骤9、将阵列存储器空间中位置大小为的数据加载到向量寄存器vr0和向量寄存器vr1中;步骤10、将向量寄存器vr6和向量寄存器vr7中的数据以地址取模方式交错地存回阵列存储器空间;步骤11、将阵列存储器空间中位置大小为的数据加载到向量寄存器vr2和向量寄存器vr3中;步骤12、初始化k=0,其中,k表示处理向量处理部件的index;步骤13、通过设置向量单元的mask状态开启第k个与k+1个向量处理部件,其他向量处理部件均关闭,将向量寄存器vr0
‑
vr1中对应第k和k+1个向量处理部件的数据存储回阵列存储器空间对应位置;将向量寄存器vr2和向量寄存器vr3中对应第k和k+1个向量处理部件的数据存储回阵列存储器空间对应位置;步骤14、令k = k + 2;步骤15、判断k是否小于l,若是,则返回步骤13,若否,则执行步骤16;步骤16、通过设置向量单元的mask状态,开启所有l个向量处理部件;
步骤17、令j = j + 1;步骤18、判断j是否小于,若是,则返回步骤3,若否,则执行步骤19;步骤19、令i = i + 1;步骤20、判断i是否小于,若是,则返回步骤2,若否,则执行步骤21步骤21、调用直接存储器访问操作,将所述转置后的矩阵的子矩阵从所述阵列存储器空间存储至双倍速率同步动态随机存储器指定位置;步骤22、判断的子矩阵是否处理完毕,若否,则循环执行以上加载、转置步骤,直到完成所有子矩阵的转置。
9.一种面向向量处理器的低位宽数据矩阵向量化转置系统,包括:存储模块,用于将低位宽数据矩阵存储在双倍速率同步动态随机存储器中;加载模块,用于调用直接存储器访问操作,将所述低位宽数据矩阵从所述双倍速率同步动态随机存储器加载到片上阵列存储器空间;转置处理模块,用于在所述阵列存储器空间中,对加载到所述片上阵列存储器空间后的矩阵进行转置处理,得到转置后的矩阵;其中,所述低位宽数据矩阵的维度为;其中,所述加载模块具体用于:调用直接存储器访问操作,将所述低位宽数据矩阵的子矩阵加载到片上阵列存储器空间中,变为,其中、,和的大小均由阵列存储器的空间大小来决定,其中l表示向量处理单元中向量处理部件的数量。
10.优选地,所述转置处理模块具体用于:步骤1、初始化i=0,其中,i表示m维上的块index;步骤2、初始化j=0,其中,j表示n维上的块index;步骤3、将所述阵列存储器空间中的低位宽数据矩阵的大小为的子块矩阵的数据加载到4个向量寄存器vr0、vr1、vr2和vr3中;步骤4、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行低打包操作,
将低打包后结果存储在向量寄存器vr4中;步骤5、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr6中;步骤6、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr5中;步骤7、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr7中;步骤8、将向量寄存器vr4和向量寄存器vr5中的数据以地址取模方式交错地存回阵列存储器空间;步骤9、将阵列存储器空间中位置大小为的数据加载到向量寄存器vr0和向量寄存器vr1中;步骤10、将向量寄存器vr6和向量寄存器vr7中的数据以地址取模方式交错地存回阵列存储器空间;步骤11、将阵列存储器空间中位置大小为的数据加载到向量寄存器vr2和向量寄存器vr3中;步骤12、初始化k=0,其中,k表示处理向量处理部件的index;步骤13、通过设置向量单元的mask状态开启第k个与k+1个向量处理部件,其他向量处理部件均关闭,将向量寄存器vr0
‑
vr1中对应第k和k+1个向量处理部件的数据存储回阵列存储器空间对应位置;将向量寄存器vr2和向量寄存器vr3中对应第k和k+1个向量处理部件的数据存储回阵列存储器空间对应位置;步骤14、令k = k + 2;步骤15、判断k是否小于l,若是,则返回步骤13,若否,则执行步骤16;步骤16、通过设置向量单元的mask状态,开启所有l个向量处理部件;步骤17、令j = j + 1;步骤18、判断j是否小于,若是,则返回步骤3,若否,则执行步骤19;步骤19、令i = i + 1;步骤20、判断i是否小于,若是,则返回步骤2,若否,则执行步骤21;步骤21、调用直接存储器访问操作,将所述转置后的矩阵的子矩阵从所述阵列存储器空间存储至双倍速率同步动态随机存储器指定位置;
步骤22、判断的子矩阵是否处理完毕,若否,则循环执行以上加载、转置步骤,直到完成所有子矩阵的转置。
11.综上所述,本发明公开了一种面向向量处理器的低位宽数据矩阵向量化转置方法,当需要对低位宽数据矩阵进行向量化转置时,将低位宽数据矩阵存储在双倍速率同步动态随机存储器中,然后调用直接存储器访问操作,将低位宽数据矩阵从双倍速率同步动态随机存储器加载到片上阵列存储器空间;在阵列存储器空间中,对加载到片上阵列存储器空间后的矩阵进行转置处理,得到转置后的矩阵。本发明能够高效的实现低位宽数据矩阵的转置操作。
附图说明
12.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
13.图1为向量处理器的一般体系结构示意图;图2为本发明公开的一种面向向量处理器的低位宽数据矩阵向量化转置方法实施例的方法流程图;图3为本发明公开的一种低打包操作示意图;图4为本发明公开的一种高打包操作示意图;图5为本发明公开的一种以取模方式交错存储的示意图;图6为本发明公开的一种面向向量处理器的低位宽数据矩阵向量化转置系统实施例的结构示意图。
具体实施方式
14.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
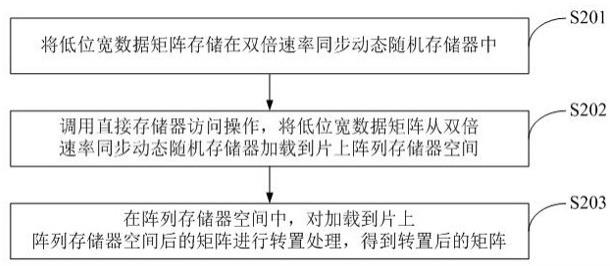
15.如图2所示,为本发明公开的一种面向向量处理器的低位宽数据矩阵向量化转置方法实施例的流程图,所述方法可以包括以下步骤:s201、将低位宽数据矩阵存储在双倍速率同步动态随机存储器中;当需要对面向向量处理器的低位宽数据矩阵进行向量化转置时,首先将低位宽数据矩阵存储在ddr(双倍速率同步动态随机存储器)中。其中,低位宽数据矩阵的维度为。
16.s202、调用直接存储器访问操作,将低位宽数据矩阵从双倍速率同步动态随机存储器加载到片上阵列存储器空间;
具体的,调用直接存储器访问操作,将低位宽数据矩阵的子矩阵加载到片上am(阵列存储器)空间中,变为,其中、,和的大小均由am的空间大小来决定,其中l表示向量处理单元中向量处理部件的数量。
17.s203、在阵列存储器空间中,对加载到片上阵列存储器空间后的矩阵进行转置处理,得到转置后的矩阵。
18.具体的,可以包括以下步骤:步骤1、初始化i=0,其中,i表示m维上的块index;步骤2、初始化j=0,其中,j表示n维上的块index;步骤3、将所述am空间中的低位宽数据矩阵的大小为的子块矩阵的数据加载到4个向量寄存器vr0、vr1、vr2和vr3中;例如,以fp32矩阵和l=8为例,使用向量加载指令,将fp32 4x16的数据一次性加载到4个向量寄存器vr0、vr1、vr2和vr3中的结果如表1所示。
19.表1 将fp32 4x32的数据一次性加载到4个向量寄存器vr0、vr1、vr2和vr3中的结果步骤4、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr4中,如图3所示;步骤5、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr6中,如图4所示;例如,以fp32矩阵和l=8为例,对vr0和vr1中的数据进行低打包操作与高打包操作,结果分别存储在vr4和vr6中的结果如表2所示。
20.表2 对vr0和vr1中的数据进行低打包操作与高打包操作,结果分别存储在vr4和vr6中的结果步骤6、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr5中;步骤7、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr7中;例如,以fp32矩阵和l=8为例,对vr2和vr3中的数据进行低打包操作与高打包操
作,结果分别存储在vr5和vr7中的结果如表3所示。
21.表3 对vr2和vr3中的数据进行低打包操作与高打包操作,结果分别存储在vr5和vr7中的结果步骤8、将向量寄存器vr4和向量寄存器vr5中的数据以地址取模方式交错地存回am空间,如图5所示。
22.例如,以fp32矩阵和l=8为例,对将vr4和vr5中的数据以地址取模方式交错地存回am空间的结果如表4所示。
23.表4 对将vr4和vr5中的数据以地址取模方式交错地存回am空间的结果步骤9、将am空间中位置大小为的数据加载到向量寄存器vr0和向量寄存器vr1中;例如,以fp32矩阵和l=8为例,将存回am空间的数据加载到寄存器vr0和vr1中的结果如表5所示。
24.表5 将存回am空间的数据加载到寄存器vr0和vr1中的结果步骤10、将向量寄存器vr6和向量寄存器vr7中的数据以地址取模方式交错地存回am空间;例如,以fp32矩阵和l=8为例,对将vr6和vr7中的数据以地址取模方式交错地存回am空间的结果如表6所示。
25.表6 对将vr6和vr7中的数据以地址取模方式交错地存回am空间的结果步骤11、将am空间中位置大小为的数据加载到向量寄存器vr2和向量寄存器vr3中;例如,以fp32矩阵和l=8为例,将存回am空间的数据加载到寄存器vr2和vr3中的结果如表7所示。
26.表7 将存回am空间的数据加载到寄存器vr2和vr3中的结果
步骤12、初始化k=0,其中,k表示向量处理部件的index;步骤13、通过设置向量单元的mask状态开启第k个与k+1个向量处理部件,其他向量处理部件均关闭,将向量寄存器vr0
‑
vr1中对应第k和k+1个向量处理部件的数据存储回am空间对应位置;将向量寄存器vr2和向量寄存器vr3中对应第k和k+1个向量处理部件的数据存储回am空间对应位置;例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第1
‑
2个向量处理部件,将vr0
‑
vr3中第1
‑
2个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果如表8所示。
27.表8 通过设置向量单元的mask状态来开启第1
‑
2个向量处理部件,将vr0
‑
vr3中第1
‑
2个vpe对应的数据存储回am空间中,完成后am空间中的数据的结果例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第3
‑
4个向量处理部件,将vr0
‑
vr3中第3
‑
4个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果如表9所示。
28.表9 通过设置向量单元的mask状态来开启第3
‑
4个向量处理部件,将vr0
‑
vr3中第3
‑
4个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第5
‑
6个向量处理部件,将vr0
‑
vr3中第5
‑
6个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果如表10所示。
29.表10 通过设置向量单元的mask状态来开启第5
‑
6个向量处理部件,将vr0
‑
vr3中第5
‑
6个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果
例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第7
‑
8个vpe,将vr0
‑
vr3中第7
‑
8个vpe对应的数据存储回am空间中,完成后am空间中的数据的结果如表11所示。
30.表11 通过设置向量单元的mask状态来开启第7
‑
8个vpe,将vr0
‑
vr3中第7
‑
8个vpe对应的数据存储回am空间中,完成后am空间中的数据的结果步骤14、令k = k + 2;步骤15、判断k是否小于l,若是,则返回步骤13,若否,则执行步骤16;步骤16、通过设置向量单元的mask状态,开启所有l个向量处理部件;步骤17、令j = j + 1;步骤18、判断j是否小于,若是,则返回步骤3,若否,则执行步骤19;步骤19、令i = i + 1;
步骤20、判断i是否小于,若是,则返回步骤2,若否,则执行步骤21;步骤21、调用直接存储器访问操作,将所述转置后的矩阵的子矩阵从所述am空间存储至双倍速率同步动态随机存储器指定位置;步骤22、判断的子矩阵是否处理完毕,若否,则循环执行以上加载、转置两个步骤,直到完成所有子矩阵的转置。
31.综上所述,本发明提供的面向向量处理器的低位宽数据矩阵向量化转置方法,能够处理任意维度大小的低位宽数据矩阵的转置操作,基于dma和向量单元完成,所需dma操作数量显著降低,降低了转置开销;基于向量load/store以及向量打包单元,实现矩阵转置的向量化操作,有效利用am空间的带宽,显著提升了低位宽数据转置的性能。
32.如图6所示,为本发明公开的一种面向向量处理器的低位宽数据矩阵向量化转置系统实施例的结构示意图,所述系统可以包括:存储模块601,用于将低位宽数据矩阵存储在双倍速率同步动态随机存储器中;当需要对面向向量处理器的低位宽数据矩阵进行向量化转置时,首先将低位宽数据矩阵存储在ddr(双倍速率同步动态随机存储器)中。其中,低位宽数据矩阵的维度为。
33.加载模块602,用于调用直接存储器访问操作,将低位宽数据矩阵从双倍速率同步动态随机存储器加载到片上阵列存储器空间;具体的,调用直接存储器访问操作,将低位宽数据矩阵的子矩阵加载到片上am(阵列存储器)空间中,变为,其中、,和的大小均由am的空间大小来决定,其中l表示向量处理单元中向量处理部件的数量。
34.转置处理模块603,用于在阵列存储器空间中,对加载到片上阵列存储器空间后的矩阵进行转置处理,得到转置后的矩阵。
35.具体的,可以包括以下步骤:步骤1、初始化i=0,其中,i表示m维上的块index;步骤2、初始化j=0,其中,j表示n维上的块index;步骤3、将所述am空间中的低位宽数据矩阵的大小为的子块矩阵的数据加载到4个向量寄存器vr0、vr1、vr2和vr3中;
例如,以fp32矩阵和l=8为例,使用向量加载指令,将fp32 4x16的数据一次性加载到4个向量寄存器vr0、vr1、vr2和vr3中的结果如表1所示。
36.步骤4、基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr4中,如图3所示;步骤5基于向量寄存器vr0和向量寄存器vr1,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr6中,如图4所示;例如,以fp32矩阵和l=8为例,对vr0和vr1中的数据进行低打包操作与高打包操作,结果分别存储在vr4和vr6中的结果如表2所示。
37.步骤6、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行低打包操作,将低打包后结果存储在向量寄存器vr5中;步骤7、基于向量寄存器vr2和向量寄存器vr3,l个向量处理部件进行高打包操作,将高打包后结果存储在向量寄存器vr7中;例如,以fp32矩阵和l=8为例,对vr2和vr3中的数据进行低打包操作与高打包操作,结果分别存储在vr5和vr7中的结果如表3所示。
38.步骤8、将向量寄存器vr4和向量寄存器vr5中的数据以地址取模方式交错地存回am空间 ,如图5所示。
39.例如,以fp32矩阵和l=8为例,对将vr4和vr5中的数据以地址取模方式交错地存回am空间的结果如表4所示。
40.步骤9、将am空间中位置大小为的数据加载到向量寄存器vr0和向量寄存器vr1中;例如,以fp32矩阵和l=8为例,将存回am空间的数据加载到寄存器vr0和vr1中的结果如表5所示。
41.步骤10、将向量寄存器vr6和向量寄存器vr7中的数据以地址取模方式交错地存回am空间;例如,以fp32矩阵和l=8为例,对将vr6和vr7中的数据以地址取模方式交错地存回am空间的结果如表6所示。
42.步骤11、将am空间中位置大小为的数据加载到向量寄存器vr2和向量寄存器vr3中;例如,以fp32矩阵和l=8为例,将存回am空间的数据加载到寄存器vr2和vr3中的结果如表7所示。
43.步骤12、初始化k=0,其中,k表示向量处理部件的index;步骤13、通过设置向量单元的mask状态开启第k个与k+1个向量处理部件,其他向量处理部件均关闭,将向量寄存器vr0
‑
vr1中对应第k和k+1个向量处理部件的数据存储回am空间对应位置;将向量寄存器vr2和向量寄存器vr3中对应第k和k+1个向量处理部件的数据存储回am空间对应位置;例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第1
‑
2个向量
处理部件,将vr0
‑
vr3中第1
‑
2个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果如表8所示。
44.例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第3
‑
4个向量处理部件,将vr0
‑
vr3中第3
‑
4个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果如表9所示。
45.例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第5
‑
6个向量处理部件,将vr0
‑
vr3中第5
‑
6个向量处理部件对应的数据存储回am空间中,完成后am空间中的数据的结果如表10所示。
46.例如,以fp32矩阵和l=8为例,通过设置向量单元的mask状态来开启第7
‑
8个vpe,将vr0
‑
vr3中第7
‑
8个vpe对应的数据存储回am空间中,完成后am空间中的数据的结果如表11所示。
47.步骤14、令k = k + 2;步骤15、判断k是否小于l,若是,则返回步骤13,若否,执行步骤16;步骤16、通过设置向量单元的mask状态,开启所有l个向量处理部件;步骤17、令j = j + 1;步骤18、判断j是否小于,若是,则返回步骤3,若否,执行步骤19;步骤19、令i = i + 1;步骤20、判断i是否小于,若是,则返回步骤2,若否,执行步骤21;步骤21、调用直接存储器访问操作,将所述转置后的矩阵的子矩阵从所述am空间存储至双倍速率同步动态随机存储器指定位置;步骤22、判断的子矩阵是否处理完毕,若否,则循环执行以上加载、转置两个步骤,直到完成所有子矩阵的转置。
48.综上所述,本发明提供的面向向量处理器的低位宽数据矩阵向量化转置系统,能够处理任意维度大小的低位宽数据矩阵的转置操作,基于dma和向量单元完成,所需dma操作数量显著降低,降低了转置开销;基于向量load/store以及向量打包单元,实现矩阵转置的向量化操作,有效利用am空间的带宽,显著提升了低位宽数据转置的性能。
49.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
50.专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和
软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
51.结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd
‑
rom、或技术领域内所公知的任意其它形式的存储介质中。
52.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1