一种卷积运算电路及其运算方法与流程
1.本发明涉及卷积运算技术领域,尤其是一种同时支持矩阵乘法运算和二维卷积运算的卷积运算电路及其运算方法。
背景技术:
2.卷积层是卷积神经网络的基础层之一,卷积运算是深度学习领域最主要的运算类型,可占卷积神经网络90%以上的运算量,而在剩余计算中,全连接层的计算又占了很大一部分。全连接层的计算可以视为矩阵乘法计算,因此,深度学习中的绝大部分计算是卷积运算和矩阵乘法计算。
3.有一种卷积运算方式是通过im2col运算,将卷积运算转换为矩阵乘法运算,该方式将卷积核展开为矩阵,将输入特征图也转换为矩阵。将卷积核中一个窗口的权重转换为另一个矩阵的一列,所有卷积核的权重组合在一起就形成了新的卷积核矩阵;将输入特征图中的每一个滑动窗口转换为矩阵的一行,所有滑动窗口的数据组合在一起就形成了新的特征图矩阵;卷积核矩阵与特征图矩阵进行矩阵乘法,即得卷积结果。
4.若通过软件实现im2col运算,由于同一特征图数据会出现在多个滑动窗口中,造成矩阵中存在大量重复元素,额外占用大量内存和带宽;若通过硬件实现im2col运算,则需要额外设计复杂的硬件电路。针对卷积运算,已有专门的硬件电路予以支持,此类硬件电路通常采用脉动阵列方式,将权重固定在运算单元上,将卷积产生的部分和在运算单元间流动并累加,直至完成所有部分和的累加,在最后一个运算单元上输出卷积结果。
5.然而,截至目前,深度学习领域尚未出现能够同时支持矩阵乘法运算和二维卷积运算的电路结构。
技术实现要素:
6.针对深度学习领域同时支持矩阵乘法运算和二维卷积运算的电路结构的空白,本发明提出一种同时支持矩阵乘法运算和二维卷积运算的卷积运算电路及其运算方法。
7.本发明保护一种卷积运算电路,由m行n列运算单元(pe:processing element)组成,同时支持矩阵乘法运算和二维卷积运算;
8.当执行矩阵乘法运算时,所述运算单元分别接收来自行方向上的左矩阵行输入和来自列方向上的右矩阵列输入,将两者相乘后累加到本地累加寄存器;
9.当执行二维卷积运算时,所述运算单元接收来自行方向上的输入特征图输入,将其与内部存储的卷积核权重相乘后与上一行运算单元输出的部分和进行累加,再向下一行输出累加后的部分和。
10.进一步的,所述运算单元主要由乘法器、累加器和权重寄存器构成;所述乘法器的行方向输入侧输入行方向上的输入;所述乘法器的列方向输入侧设置择一选择的两路输入,分别为列方向上的输入和来自所述权重寄存器的卷积核权重输入;所述累加器的部分和输入侧设置择一选择的两路输入,分别为来自本地累加寄存器和上一行运算单元输出的
部分和。
11.进一步的,每个运算单元内部设置有多个权重寄存器,权重以滑动窗口大小为单位折叠排列在运算单元上,所述权重寄存器与所述乘法器的列方向输入侧之间设有地址选择控制器,所述地址选择控制器根据地址选择寄存器的值对多个权重寄存器中存储的卷积核权重进行选择,参与卷积运算。
12.进一步的,每列运算单元的最后一行运算单元连接有fifo(first in first out:先进先出)存储器,fifo存储器输出连接至第一行运算单元。
13.本发明还保护上述卷积运算电路的运算方法,当执行矩阵乘法运算时,向运算单元乘法器的行方向输入侧广播输入左矩阵的对应行数据,向运算单元乘法器的列方向输入侧广播输入右矩阵的对应列数据,每个运算单元在每个周期内将行方向和列方向接收到的数据相乘后累加到本地累加寄存器。
14.当执行二维卷积运算时,每个卷积核的权重依序存储在运算电路对应列的运算单元权重寄存器中,若卷积核滑动窗口宽为c,高为r,则计算该卷积核在输入特征图矩阵对应行滑动的卷积运算结果时,将卷积核当下执行卷积操作的1
‑
r行输入特征图行数据,依次广播输入运算电路的第1到c行、第c+1到c行、...、第r*c
‑
c到r*c行;第i+1行的输入特征图行数据比第i行的输入特征图行数据推迟c个周期输入pe阵列,其中1≤i≤r;每行输入特征图行数据依序输入pe单元,每个周期输入一个数据;每个运算单元在每个周期内将行方向接收到的数据与经过地址选择控制器选择后的卷积核权重相乘后与上一行运算单元输出的部分和进行累加,并向下一行输出累加后的部分和,直至最后一行输出该列的卷积核计算结果。
15.进一步的,当卷积核滑动窗口过大,pe阵列的一列pe无法一次放下1个卷积核的全部权重数据时,按照如下方案进行权重分布:
16.针对单通道输入的卷积核,将剩余的权重数据重新从pe阵列的第1行依次向下折叠摆放,一次在pe阵列的一列上依次摆放行卷积核的权重,共摆放次,第i次折叠将权重摆放在运算单元内部的第i个权重寄存器中,其中次,第i次折叠将权重摆放在运算单元内部的第i个权重寄存器中,其中将卷积核权重如此排列后,当输入特征图输入pe阵列时,首先输入卷积核沿行方向滑动经过的前行数据,地址选择控制器选择第1个权重寄存器的值参与乘法运算,最后一行输出的是卷积运算的中间结果,在fifo存储器暂存;前行数据输入完成后,再输入第2个行输入特征图数据,地址选择控制器选择第2个权重寄存器的值参与乘法运算,同时fifo中暂存的中间结果从第1行输入,参与累加运算;剩余行的输入特征图数据按依此类推的方式输入pe阵列,直至卷积核沿行方向滑动经过的所有行输入特征图数据全部输入完毕,此时fifo中存储的就是最终的卷积结果。
17.针对多通道输入的卷积核,记输入通道数为i,按照单通道输入的卷积核的权重分布方案折叠摆放每一输入通道的卷积核权重;首先摆放第1输入通道的权重,每列仍然摆放行卷积核的权重,摆放次之后,依次向下折叠摆放第2个通道的权重,直至第i个通道的权重,共折叠摆放次;第i次折叠把权重摆放在pe内部第i个权重寄存器中,其中在这种情况下,当输入特征图输入pe阵列时,按下述顺序把输入特征图各通道沿卷积核在行方向上滑动经过的r行数据输入pe阵列。
从第1个通道的参与运算的第1行数据至最后1个通道参与运算的第r行数据,共有i*r行数据参与多通道二维卷积运算,分别记为参与运算的1至i*r行输入特征图数据。首先输入卷积核沿行方向滑动经过的前行数据,地址选择控制器选择第1个权重寄存器的值参与乘法运算,最后一行输出的是卷积运算的中间结果,在fifo存储器暂存;前行数据输入完成后,再输入第2个行输入特征图数据,地址选择控制器选择第2个权重寄存器的值参与乘法运算,同时fifo中暂存的中间结果从第1行输入,参与累加运算;剩余行的输入特征图数据按依次类推的方式输入pe阵列,直至卷积核沿行方向滑动经过的所有行输入特征图数据全部输入完毕,此时fifo中存储的就是最终的卷积结果。
18.本发明的有益效果:1、既可以高效执行矩阵乘法运算,也可以高效执行二维卷积运算;2、支持常见的多输入通道、多卷积核的二维卷积运算;3、当输入通道数很多,输入通道数乘以卷积核的滑动窗口中的权重数量大于pe阵列的高度时,通过pe阵列的fifo,对卷积计算的中间结果进行缓存,使卷积计算的中间结果不必移出pe阵列便可完成全部卷积计算;4、通过把权重折叠存储在pe内部的多个权重寄存器,使一个卷积核的权重数据可以一次全部导入pe阵列的一列,使权重数据在多次参与卷积运算时不需要反复导入pe阵列。
附图说明
19.图1为卷积运算电路示意图;
20.图2为运算单元内部结构示意图;
21.图3为运算单元在执行矩阵乘法运算时的内部工作电路;
22.图4为运算单元在执行矩阵乘法运算时的数据流动示意图;
23.图5为左、右矩阵相乘示意图;
24.图6为左矩阵的各行数据和右矩阵的各列数据输入运算电路的排列示意图;
25.图7为运算单元在执行二维卷积运算时的内部工作电路;
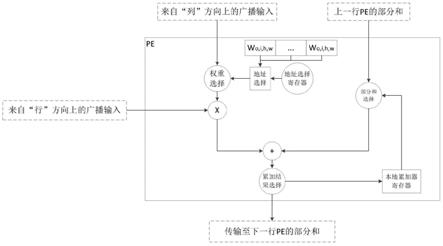
26.图8为输入特征图和卷积核的示意图;
27.图9为执行二维卷积运算时的数据流动示意图;
28.图10为未开始计算前准备阶段的数据状态图;
29.图11
‑
图21分别为二维卷积运算第一周期到第十一周期数据状态图。
具体实施方式
30.下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
31.实施例1
32.一种卷积运算电路,由m行n列运算单元pe组成(例如图1所示的卷积运算电路由4行8列运算单元pe构成),同时支持矩阵乘法运算和二维卷积运算两种工作模式。
33.当执行矩阵乘法运算时,所述运算单元分别接收来自行方向上的左矩阵行输入和来自列方向上的右矩阵列输入,将两者相乘后累加到本地累加寄存器。
34.当执行二维卷积运算时,所述运算单元接收来自行方向上的输入特征图输入,将其与内部存储的卷积核权重相乘后与上一行运算单元输出的部分和进行累加,再向下一行输出累加后的部分和。
35.为实现上述方案,在本实施例中,所述运算单元主要由乘法器、累加器和权重寄存器构成,如图2所示。
36.所述乘法器的行方向输入侧输入行方向上的输入。
37.所述乘法器的列方向输入侧设置择一选择的两路输入,分别为列方向上的输入和来自所述权重寄存器的卷积核权重输入。执行矩阵乘法运算时,选择来自列方向上的输入;执行二维卷积运算时,选择来自所述权重寄存器的卷积核权重输入。
38.所述累加器的部分和输入侧设置择一选择的两路输入,分别为来自本地累加寄存器和上一行运算单元输出的部分和。执行矩阵乘法运算时,选择本地累加寄存器;执行二维卷积运算时,选择上一行运算单元输出的部分和。
39.累加结果是输出到本地累加寄存器,还是向下一行运算单元输出累加后的部分和由累加结果选择器控制。执行矩阵乘法运算时,累加结果输出到本地累加寄存器;执行二维卷积运算时,累加结果输出到下一行相邻的运算单元。
40.下面结合本发明公开的卷积运算电路,对其数据流动方式阐述其卷积运算方法。
41.当卷积运算电路工作在矩阵乘法运算模式时,运算单元内部工作电路如图3所示,向运算单元乘法器的行方向输入侧广播输入左矩阵的对应行数据,向运算单元乘法器的列方向输入侧广播输入右矩阵的对应列数据,每个运算单元在每个周期内将行方向和列方向接收到的数据相乘后累加到本地累加寄存器,整体数据流动如图4所示。
42.以图5所示8
×
8左矩阵a与8
×
8右矩阵b进行乘法运算为例,执行矩阵乘法运算时,左矩阵的各行数据和右矩阵的各列数据按照图6所示排列并输入图1所示卷积运算电路对应的运算单元。每个运算单元将行方向上的广播输入数据和列方向上的广播输入数据进行乘法运算,再与本地累加寄存器中的数值进行加法运算,最后将运算结果存入本地累加寄存器。此时,pe阵列中各个本地累加寄存器中存储的数值就是结果矩阵各元素的值。
43.当左矩阵的行数大于pe阵列的行数或右矩阵的列数大于pe阵列的列数时,则需要对矩阵进行分块处理,使得两个进行相乘的分块矩阵都满足左分块矩阵的行数小于等于pe阵列的行数且右分块矩阵的列数小于等于pe阵列的列数。对分块处理后的各分块矩阵执行分块矩阵乘法运算,然后暂存运算结果,最后将各分块矩阵的运算结果进行组合,得到左矩阵与右矩阵的矩阵乘法运算结果。以图6为例,左矩阵和右矩阵均为8
×
8矩阵,而pe阵列为4行8列,右矩阵8列可以一次性输入pe阵列,而左矩阵需要进行分块处理,分割成两个4
×
8的分块矩阵进行处理。
44.当卷积运算电路工作在二维卷积运算模式时,运算单元内部工作电路如图7所示。一般而言,深度学习模型中的一个卷积层有多个卷积核,这些卷积核的计算无数据相关性,可以并行执行。在本实施例中,每列pe存储一个卷积核的数据,完成一个卷积核的卷积计算。一个卷积窗口的权重数据逐行依序排列在对应列pe的权重寄存器中,当针对第1输入通道卷积窗口的权重排列完后,再在该列上向下排列针对第2输入通道卷积窗口的权重,参照图9所示pe阵列最下方一行。因此,每个卷积核的权重依序存储在运算电路对应列的运算单元权重寄存器中,不仅指同一输入通道卷积窗口的权重依序排列,不同输入通道卷积窗口
的权重也是依序排列。
45.记卷积核滑动窗口宽为c,高为r,则计算该卷积核在输入特征图矩阵对应行滑动的卷积运算结果时,将卷积核当下执行卷积操作的1
‑
r行输入特征图行数据,依次广播输入运算电路的第1到c行、第c+1到c行、...、第r*c
‑
c到r*c行;第i+1行的输入特征图行数据比第i行的输入特征图行数据推迟c个周期输入pe阵列,其中1≤i≤r;每行输入特征图行数据依序输入pe单元,每个周期输入一个数据;每个运算单元在每个周期内将行方向接收到的数据与经过地址选择控制器选择后的卷积核权重相乘后与上一行运算单元输出的部分和进行累加,并向下一行输出累加后的部分和,直至最后一行输出该列的卷积核计算结果。
46.以图8所示,输入特征图为6
×
6矩阵,卷积核为3
×
3矩阵为例,其中卷积核权重在pe阵列中的分布情况如图9所示。图9中的xn,c,h,w表示从行方向输入的第n批数据第c个特征图的第h行第w列数据,wo,i,x,y表示权重寄存器中存储的第o个卷积核针对第i输入通道卷积窗口的第x行第y列权重。参照图9所示,第1个卷积核的权重排列在pe阵列的第1列;第2个卷积核的权重排列在pe阵列的第2列,其余以此类推。当卷积核数量大于pe阵列的列数时,进行前述类似拆分即可。按照这种方式,各列pe并行工作,针对相同输入特征图的不同卷积核可以同时并行执行卷积运算。
47.参照图9,卷积核存储情况具体为:将针对第0输入通道的卷积核第1行3个权重沿pe阵列的列方向由上到下依次存储于第1
‑
3个运算单元权重寄存器中,卷积核第2行3个权重沿pe阵列的列方向由上到下依次存储于第4
‑
6个运算单元权重寄存器中,卷积核第3行3个权重沿pe阵列的列方向由上到下依次存储于第7
‑
9个权重寄存器中。若pe阵列行数足够,当针对第0输入通道卷积窗口的权重排列完后,可以在该列上向下排列针对第1输入通道卷积窗口的权重,参照图9所示pe阵列最下方一行。
48.当计算该卷积核在输入特征图矩阵上三行滑动的卷积运算结果时,数据按图9所示输入pe阵列。若存在多通道输入,则针对第0输入通道卷积窗口的权重排列在第1
‑
9行,针对第1输入通道卷积窗口的权重排列在第10
‑
18行,以此类推。不同输入通道的输入特征图输入pe阵列相应输入通道卷积窗口的权重对应行即可。
49.图8示例中,由于是计算该卷积核在输入特征图矩阵上三行滑动的卷积运算结果,因此与之相对应的,将输入特征图的第1行数据广播输入至pe阵列的第1
‑
3行,输入特征图的第2行数据广播输入至pe阵列的第4
‑
6行,输入特征图的第3行数据广播输入至pe阵列的7
‑
9行。同理可推,当计算该卷积核在输入特征图矩阵下三行滑动的卷积运算结果时,将输入特征图的第4行数据广播输入至pe阵列的第1
‑
3行,输入特征图的第5行数据广播输入至pe阵列的第4
‑
6行,输入特征图的第6行数据广播输入至pe阵列的7
‑
9行。
50.为提高运算电路的适用性,每个运算单元内部可设置多个权重寄存器,权重折叠排列在运算单元上。
51.对于单输入通道的卷积核,记卷积核滑动窗口宽为c,高为r,当滑动窗口过大,pe阵列的一列pe无法一次放下全部权重数据,即r*c>m时,将剩余的权重数据重新从pe阵列的第1行依次向下折叠摆放;重新从第1行摆放权重应当保证一行权重摆放在连续的pe运算单元上。一次在pe阵列的一列上依次摆放行卷积核的权重,共摆放次;第i次折叠把权重摆放在pe内部第i个权重寄存器中,其中第i次折叠把权重摆放在pe内部第i个权重寄存器中,其中
52.对于多输入通道的卷积核,记卷积核滑动窗口宽为c,高为r,共有i个输入通道,首
先按照单通道的方式摆放第1个通道的权重,每列仍然摆放行卷积核的权重,摆放次之后,依次向下折叠摆放第2个通道的权重,直至第i个通道的权重,共折叠摆放次;第i次折叠把权重摆放在pe内部第i个权重寄存器中,其中
53.基于上述卷积核权重分布方案,可以将一个卷积核的所有权重一次性全部输入到pe阵列中,相比于逐个计算各个通道的卷积结果再进行累加,避免了卷积中间结果反复导出或导入pe阵列,提高了效率,降低了功耗。
54.下面以图9所示pe阵列的第1列为例对二维卷积运算的具体工作流程进行阐述。
55.图10为未开始计算前准备阶段的数据状态图,虚线表示输入数据的传播方向,实线表示卷积运算部分和的传播方向;图11
‑
图21分别为二维卷积运算第一周期到第十一周期数据状态图。图10中的x
1,7
‑
x
1,11
在输入特征图x中并无对应数据,可作零处理。
56.二维卷积运算第一周期:x
1,1
输入运算电路的第1行第1列pe中,与存储于该pe中的权重w
1,1
相乘,然后向下一行输出w
1,1*
x
1,1
,参照图11。
57.二维卷积运算第二周期:x
1,2
输入运算电路的第2行第1列pe中,与存储于该pe中的权重w
1,2
相乘,然后与上一行输出的w
1,1*
x
1,1
累加,向下一行输出w
1,1*
x
1,1
+w
1,2*
x
1,2
,参照图12。
58.以此类推,直至二维卷积的第九个周期:x
3,3
输入运算电路的第9行第1列pe中,与存储于该pe中的权重w
3,3
相乘,然后与上一行输出的累加,向下一行输出w
1,1*
x
1,1
+w
1,2*
x
1,2
+w
1,3*
x
1,3
+w
2,1*
x
2,1
+w
2,2*
x
2,2
+w
2,3*
x
2,3
+w
3,1*
x
3,1
+w
3,2*
x
3,2
+w
3,3*
x
3,3
,此即为3
×
3卷积核w位于6
×
6输入特征图中左上角时的卷积运算结果,参照图19。
59.二维卷积的第十个周期:x
3,4
输入运算电路的第9行第1列pe中,与存储于该pe中的权重w
3,3
相乘,然后与上一行输出的累加,向下一行输出w
1,1*
x
1,2
+w
1,2*
x
1,3
+w
1,3*
x
1,4
+w
2,1*
x
2,2
+w
2,2*
x
2,3
+w
2,3*
x
2,4
+w
3,1*
x
3,2
+w
3,2*
x
3,3
+w
3,3*
x
3,4
,此即为3
×
3卷积核w从图19所示位置向右滑动一格后的卷积运算结果,参照图20。
60.类推可知,二维卷积的第十一个周期:x
3,5
输入运算电路的第9行第1列pe中,与存储于该pe中的权重w
3,3
相乘,然后与上一行输出的累加,向下一行输出w
1,1*
x
1,3
+w
1,2*
x
1,4
+w
1,3*
x
1,5
+w
2,1*
x
2,3
+w
2,2*
x
2,4
+w
2,3*
x
2,5
+w
3,1*
x
3,3
+w
3,2*
x
3,4
+w
3,3*
x
3,5
,此即为3
×
3卷积核w从图20所示位置再次向右滑动一格后的卷积运算结果,参照图21。
61.每个运算单元在每个周期内将行方向和列方向接收到的数据相乘后与上一行运算单元输出的部分和进行累加,下一行输出累加后的部分和,直至最后一行输出该列的卷积核计算结果。
62.在每列pe的最后一行pe连接fifo存储器,fifo存储器输出连接至第一行pe,用于存储卷积计算的部分和。当输入通道数很多,输入通道数乘以卷积核的滑动窗口中的权重数量大于pe阵列的高度时,通过pe阵列的fifo,对卷积计算的中间结果进行缓存,使卷积计算的中间结果不必移出pe阵列便可完成全部卷积计算。
63.在执行单输入通道的二维卷积运算时,当滑动窗口过大,pe阵列无法全部一次放下权重数据时,即r*c>m时,将权重数据重新从第pe阵列的第1行依次向下折叠摆放;重新从第1行摆放权重应保证卷积核一行权重摆放在连续的pe运算单元上;一次在pe阵列的一列
上依次摆放行卷积核的权重,共摆放次;第i次折叠把权重摆放在pe内部第i个权重寄存器中,其中在这种情况下,当输入特征图输入pe阵列时,首先输入卷积核沿行方向滑动经过的前行数据,地址选择控制器选择第1个权重寄存器的值参与乘法运算,最后一行输出的是卷积运算的中间结果,在fifo存储器暂存;前行数据输入完成后,再输入第2个个输入特征图数据,地址选择控制器选择第2个权重寄存器的值参与乘法运算,同时fifo中暂存的中间结果从第1行输入,参与累加运算;剩余行的输入特征图数据按依次类推的方式输入pe阵列,直至卷积核沿行方向滑动经过的所有行输入特征图数据全部输入完毕,此时fifo中存储的就是最终的卷积结果。
64.在执行多输入通道的二维卷积运算时,记输入通道个数为i,当针对多输入通道特征图的卷积核权重过多,即i*r*c>m时,pe阵列的一列pe无法全部一次放下权重数据时,按照与上述类似的方式摆放所有卷积核权重;重新从第1行摆放权重应保证卷积核一行权重摆放在连续的pe运算单元上。同样,各通道的输入特征图传输进pe阵列时,也按照相应的方式折叠排列,以与参与计算的权重相对应的方式传输进pe阵列;按下述顺序把输入特征图各通道沿卷积核在行方向上滑动经过的r行数据输入pe阵列。共有i*r行数据参与多通道二维卷积运算,从第一个通道的参与运算的第1行数据至最后一个通道参与运算的第r行数据,分别记为参与运算的1至i*r行输入特征图数据。若r*c>m,即卷积核针对第一通道特征图的权重无法在一列pe内部依次全部摆放时,首先按照前述次序输入第1输入通道特征图的行数据。若r*c≤m,但i*r*c>m,即卷积核针对第一通道特征图的权重可以在一列pe内部依次全部摆放,但针对所有输入通道的权重无法在一列pe内部依次全部摆放时;按照前述次序输入第1输入通道特征图的r行数据以及第2输入通道特征图的前x行数据,x为使得(r+x)*c≤m的最大整数。这一批按次序输入的数据按行方向上的顺序逐个输入,直至所有行方向上的数据全部输入pe阵列。这一批按次序输入的数据与各pe中第1个储存权重的寄存器相乘。当第一批数据全部参与计算完毕后,fifo中存储的是输入特征图第1批行数据参与卷积运算后的中间结果。之后,再按照上述规律选择多通道输入特征图的上述参与运算的1至i*r行数据中的第2批数据,并按前述次序输入pe阵列。这批输入数据与各pe中第2个储存权重的寄存器相乘,与此同时,fifo中存储的卷积计算中间结果从第一行的pe依次输入,再以部分和的形式向下传递,参与到本批次的卷积计算过程中。每一批输入特征图数据参与计算完毕后,fifo中存储的是此前参与计算的所有输入特征图的卷积结果。当所有输入通道的r行数据(共i*r行数据)都已输入pe阵列后,fifo存储器中存储的就是该卷积核针对多通道输入特征图r行数据的卷积计算结果。n列pe的二维卷积计算并行执行,当所有输入通道的r行数据(共i*r行数据)都已输入pe阵列时,该pe阵列储存的n个卷积核针对多通道输入特征图的卷积计算结果的便计算完成,自fifo输出或在计算最后一批输入特征图的卷积计算结果时直接输出到卷积结果存储器。
65.显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域及相关领域的普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1