一种基于Flink的数据标签系统的制作方法
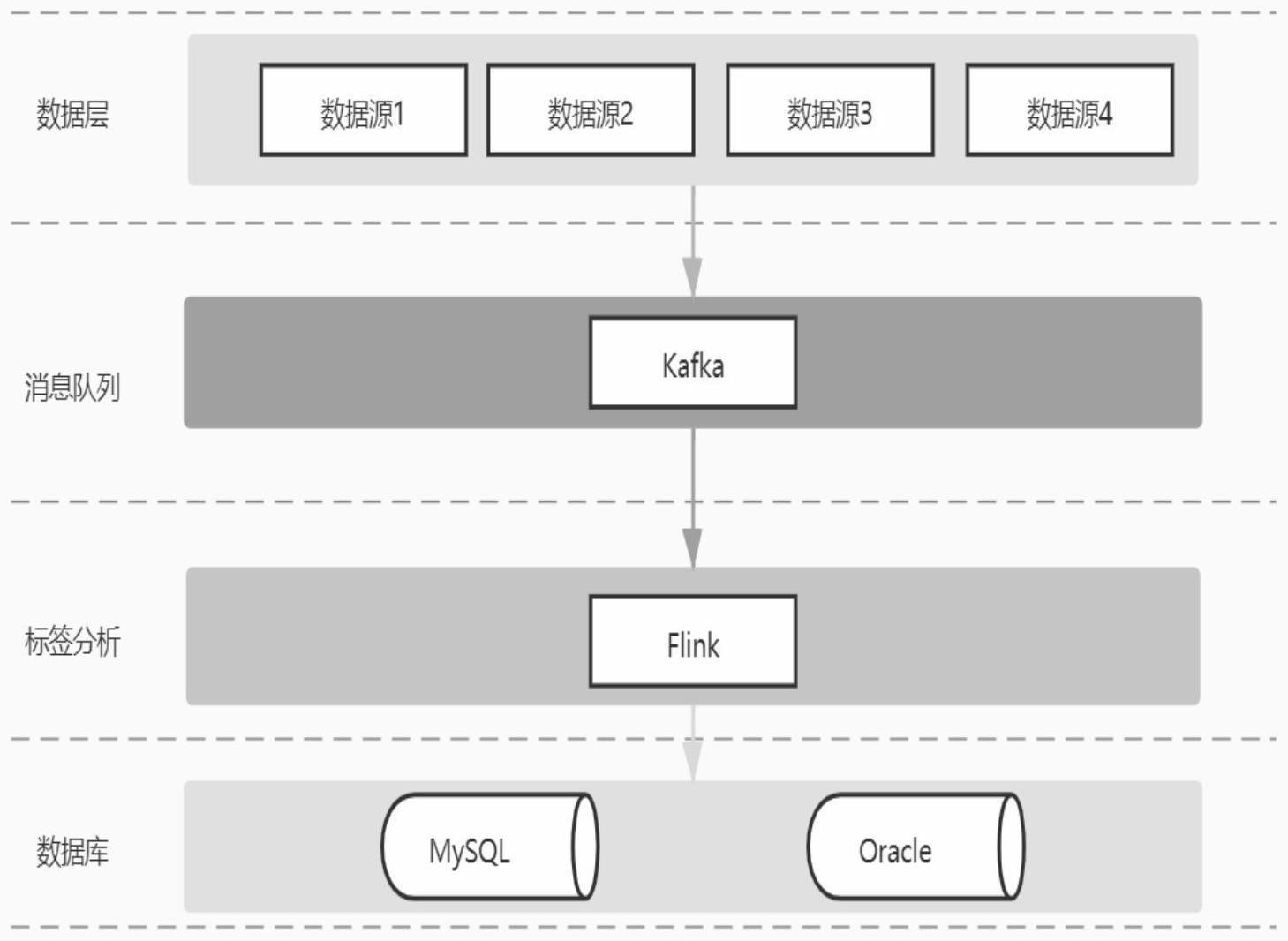
本发明属于数据处理,涉及一种基于flink的数据标签系统。
背景技术:
1、从概念模型上讲,标签体系就是围绕多个实体对象以及实体之间的关系,建立标签化描述的方法,作为一个应用体系,各种层级的标签结合在一起使用才有意义。所以可以说标签体系是业务层面、数据特征值的集合,是基于数据层体现业务层,标签体系是数据治理及数据整合的手段和成果之一。
2、在标签管理方面,可围绕标签业务主题和应用主题,建设多层级的标签管理体系构建标签市场。在标签建模方面,flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算,基于flink实现了大流量数据的实时标注和海量数据的离线标注,同时为了降低标签建模的复杂度,采用可视化拖拽实现快速标签分析模型的快速配置,并结合建模工具实现复杂的标签建模。
技术实现思路
1、本发明的目的在于提供一种基于flink的数据标签系统,通过flink实现大流量数据的实时标注和海量数据的离线标注。
2、本发明的技术方案如下:
3、一种基于flink的数据标签系统,其特征在于,包括以下模块:
4、模块1,标签解析模块:通过flink实现大流量数据的实时标注和海量数据的离线标注;
5、模块2,标签关键字模块:实现标签关键字管理功能,通过关键字与标签进行绑定,用于匹配出某个人应有哪些标签;
6、模块3,标签类别模块:根据业务需求对标签体系进行分类管理;
7、模块4,标签列表模块,包括:
8、(1)数据标签化:通过制定容器、规则、条件将业务对象信息转化为标签数据;
9、(2)标签数据管理:对海量标签数据进行管理、去重、合并、转义操作;
10、模块5,标签查询应用模块:通过对标签进行“与”、“或”、“非”组合条件,筛选出满足条件标签的人,同时可以统计出带有该标签的人数;
11、模块6,标签数据表模块:用于绑定动态标签统计的数据源;
12、模块7,动态标签支撑条件模块:标签支撑条件用于动态标签进行统计时的支撑;可以通过选取字段以及统计条件等生成sql,也可直接写统计sql。
13、本发明能够实现大流量数据的实时标注和海量数据的离线标注。
技术特征:
1.一种基于flink的数据标签系统,其特征在于,包括以下模块:
技术总结
本发明涉及一种基于Flink的数据标签系统,包括:标签解析模块,通过Flink实现大流量数据的实时标注和海量数据的离线标注;标签关键字模块,实现标签关键字管理功能;标签类别模块,根据业务需求对标签体系进行分类管理;标签列表模块,将业务对象信息转化为标签数据,并对海量标签数据进行管理、去重、合并、转义操作;标签查询应用模块,通过对标签进行“与”、“或”、“非”组合条件,筛选出满足条件标签的人;标签数据表模块,用于绑定动态标签统计的数据源;动态标签支撑条件模块,用于动态标签进行统计时的支撑。本发明能实现大流量数据的实时标注和海量数据的离线标注。
技术研发人员:贾承翰
受保护的技术使用者:北京航天长峰科技工业集团有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!