可重构并行处理的制作方法
可重构并行处理
1.分案申请
2.本技术为申请号2018800171891、申请日2018年3月13日、题为“可重构并行处理”的分案申请。
3.相关申请
4.本技术要求于2017年3月14日提交的题为“reconfigurable parallel processing”的美国临时申请62/471,340、2017年3月15日提交的题为“circular reconfiguration for reconfigurableparallel processor”的美国临时申请62/471,367、2017年3月15日提交的题为“private memorystructure for reconfigurable parallel processor”的美国临时申请62/471,368、2017年3月15日提交的题为“shared memory structure for reconfigurable parallel processor”的美国临时申请 62/471,372、2017年3月17日提交的题为“static shared memory access for reconfigurableparallel processor”的美国临时申请62/472,579的优先权,这些申请的内容通过引用整体并入本文。
技术领域
5.本文的公开内容涉及计算机架构,特别地涉及可重构处理器。
背景技术:
6.具有大量处理阵列的可重构计算架构可以满足计算能力的需求,同时保持功率和硅面积高效。与现场可编程门阵列(field-programmable gate array,fpga)不同,粗粒度可重构架构(coarse-grained reconfigurable architecture,cgra)利用如算术逻辑单元(arithmetic logicunit,alu)等更大的处理单元作为其构建模块。其提供了使用高级语言来快速编程处理单元 (pe)阵列的可重构性特征。cgra的一个典型设计在图1中示出。其由pe阵列、配置内存、作为帧缓冲器的内存单元、pe之间的以及pe到帧缓冲器的互连件组成。
7.一般而言,cgra是用于探索回路级并行性的方法。其不是专门针对处理线程级并行性的。由于从一次迭代到下一次迭代的任何数据依赖性,并行性在很大程度上是有限的。因此,在大多数设计中,2d阵列的大小旨在限制于8
×
8pe阵列。
8.图形处理单元(graphics processing unit,gpu)架构已提供了以相同指令多线程(sameinstruction multiple thread,simt)方式执行并行线程的方法。其特别适合大规模并行计算应用。在这些应用中,通常假定线程之间没有依赖性。这种类型的并行性超出了软件任务内的回路级并行性(cgra是针对回路级并行性而设计的)。线程级并行性可以容易地扩展超过单核执行到多核执行。线程并行性提供了优化机会,并且使pe阵列更高效和更有能力,并且其易于制造得大于8
×
8。然而,gpu是不可重构的。因此,本领域需要开发能够利用cgra 和gpu两者的处理能力的下一代处理器。
技术实现要素:
9.本公开内容描述了用于大规模并行数据处理的装置、方法和系统。根据本公开内容的各种实施方案的处理器可以设计为使用类似于cgra的可编程处理器阵列来利用类似于gpu 的大规模线程级并行性。在一个实施方案中,处理器可以有效地处理彼此相同但具有不同数据的线程,类似于simt架构。软件程序的数据依赖图可以映射到具有无限长度的虚拟数据路径。然后虚拟数据路径可以分割为可以适合多个物理数据路径的段,每个物理数据路径可以具有其配置环境。序列发生器可以将每个pe的配置分配到其配置fifo中,并类似的将每个数据交换盒配置分配到数据交换盒。垫片内存(gasket memory)可以用于临时存储一个物理数据路径配置的输出,并将其返回给处于下一配置的处理单元。内存端口可以用于计算读取和写入的地址。fifo可以用于允许每个pe独立操作。存储在内存单元中的数据可以通过私有或共享内存访问方法来访问。相同的数据在软件程序的不同部分中可以通过不同访问方法来访问,以减少内存之间的数据移动。
10.在示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe),该多个处理单元各自包括配置缓冲器;序列发生器,该序列发生器耦合到该多个pe中的每一个的配置缓冲器并配置成将一个或多个pe配置分配给该多个pe;以及垫片内存,该垫片内存耦合到该多个pe并配置成存储至少一个pe执行结果以在下一pe配置期间供多个pe中的至少一个使用。
11.根据实施方案,处理器可以进一步包括耦合到序列发生器以从序列发生器接收数据交换盒配置的多个数据交换盒,该多个数据交换盒中的每一个可以与多个pe中的相应pe相关联,并且配置成根据数据交换盒配置为相应pe提供输入数据切换。
12.根据实施方案,多个数据交换盒及其相关联的pe可以布置在多个列中,该多个列的第一列中的第一数据交换盒可以耦合在垫片内存和多个列的第一列中的第一个pe之间,并且多个列的最后一列中的第二个pe可以耦合到垫片内存。
13.根据实施方案,处理器可以进一步包括:内存单元,该内存单元用于为多个pe提供数据存储;以及多个内存端口,该多个内存端口各自布置在多个列的不同列中,用于多个pe 访问内存单元。
14.根据实施方案,处理器可以进一步包括多个列间数据交换盒(inter-column switch box, icsb),其耦合到序列发生器以从序列发生器接收icsb配置,该多个icsb可以配置成根据 icsb配置在多个列中的相邻列之间提供数据切换。
15.根据实施方案,多个内存端口(mp)可以耦合到序列发生器以从序列发生器接收mp配置,并且配置成在一个mp配置期间以私有访问模式或共享访问模式操作。
16.根据实施方案,存储在内存单元中的一段数据可以在程序的不同部分中通过私有访问模式和共享访问模式来访问,而无需在内存单元中移动。
17.根据实施方案,多个列中的每一列包括一个pe,多个pe可以是相同的,并且形成一行重复的相同pe。
18.根据实施方案,多个列中的每一列可以包括两个或更多个pe,并且多个pe形成两行或更多行。
19.根据实施方案,第一行pe可以配置成实施第一组指令,并且第二行pe可以配置成实施第二组指令,该第二组指令中的至少一个指令不在该第一组指令中,并且多个列可以
相同并形成重复的列。
20.根据实施方案,多个pe中的每一个可以包括多个算术逻辑单元(alu),这些算术逻辑单元可以配置成在并行线程中执行相同的指令。
21.根据实施方案,多个pe中的每一个可以包括用于多个alu的多个数据缓冲器,并且可以配置成独立操作。
22.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址访问内存单元,并且在私有访问模式下,向量地址中的一个地址可以根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据可以位于同一内存组中。
23.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址来访问内存单元,并且在共享访问模式下,向量地址中的一个地址无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据可以分布在所有内存组中。
24.在另一示例性实施方案中,提供了一种方法,该方法包括:在处理器处将执行内核映射到虚拟数据路径,其中该执行内核包括要由处理器执行的指令序列,并且处理器包括各种可重构单元,这些可重构单元包括垫片内存;将虚拟数据路径分割为一个或多个物理数据路径;将配置递送给处理器的各种可重构单元,以供各种可重构单元形成用于执行该指令序列的一个或多个物理数据路径;以及执行处理器以通过根据配置来操作各种可重构单元来完成一个或多个物理数据路径,包括将数据从一个物理数据路径路由到垫片内存以在未来的物理数据路径中作为输入使用。
25.根据实施方案,各种可重构单元可以进一步包括多个处理单元、各自与不同处理单元相关联的多个数据交换盒、为该多个处理单元提供对内存单元的访问的多个内存端口、以及多个列间数据交换盒,其中各种可重构单元中的每一个通过下一配置来重构并独立于其他可重构单元应用。
26.根据实施方案,多个pe中的每一个可以包括多个算术逻辑单元(alu),这些算术逻辑单元可以配置成在并行线程中执行相同的指令。
27.根据实施方案,多个内存端口中的每一个可以配置成在一个配置期间以私有访问模式或共享访问模式操作。
28.根据实施方案,该方法还可以进一步包括在不同的物理数据路径中通过私有访问模式和共享访问模式访问存储在内存单元中的一段数据,而无需在内存单元中移动。
29.根据实施方案,内存端口中的每一个可以配置成使用向量地址访问内存单元,并且在私有访问模式下,向量地址中的一个地址可以根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据可以位于同一内存组中,并且在共享访问模式下,向量地址中的一个地址可以在无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据可以分布在所有内存组中。
30.根据实施方案,多个pe中的每一个可以包括用于多个alu的多个数据缓冲器,并且可以配置成在一个物理数据路径期间独立操作。
31.根据实施方案,多个pe可以形成pe阵列,并且执行内核可以基于pe阵列的大小、多个pe之间的连接以及内存访问能力映射到处理器上的一个或多个物理数据路径中。
32.根据实施方案,各种可重构单元可以形成多个重复列,并且一个或多个物理数据路径中的每一个可以适配到多个重复列中,并且重复列之间的数据流可以在一个方向上。
33.在又一示例性实施方案中,提供了一种系统,该系统包括:处理器,该处理器包括:序列发生器,该序列发生器配置成将要由处理器执行的执行内核映射到虚拟数据路径中,并将虚拟数据路径分割成一个或多个物理数据路径;耦合到该序列发生器的多个处理单元(pe),该多个pe中的每一个包括配置缓冲器,该配置缓冲器配置成从该序列发生器接收用于一个或多个物理数据路径的pe配置;以及垫片内存,该垫片内存耦合到多个pe,并且配置成存储来自一个或多个物理数据路径中的一个的数据,以由该一个或多个物理数据路径中的另一物理数据路径作为输入使用。
34.根据实施方案,处理器可以进一步包括耦合到序列发生器的多个数据交换盒(sb),以从该序列发生器接收用于一个或多个物理数据路径的sb配置,该多个sb中的每一个与多个 pe中的相应pe相关联,并且配置成根据sb配置为相应pe提供输入数据切换。
35.根据实施方案,多个数据交换盒及其相关联的pe可以布置在多个列中,该多个列的第一列中的第一数据交换盒可以耦合在垫片内存和多个列的第一列中的第一个pe之间,并且多个列的最后一列中的第二个pe可以耦合到垫片内存。
36.根据实施方案,处理器可以进一步包括用于为多个pe提供数据存储的内存单元;以及多个内存端口,多个内存端口各自布置在多个列的不同列中,用于多个pe访问内存单元。
37.根据实施方案,处理器可以进一步包括多个列间数据交换盒(icsb),其耦合到序列发生器以从序列发生器接收用于一个或多个物理数据路径的icsb配置,该多个icsb配置成根据icsb配置在多个列中的相邻列之间提供数据切换。
38.根据实施方案,多个内存端口(mp)可以耦合到序列发生器以从序列发生器接收用于一个或多个物理数据路径的mp配置,并且配置成在一个mp配置期间以私有访问模式或共享访问模式操作。
39.根据实施方案,存储在内存单元中的一段数据可以在一个或多个物理数据路径的不同物理数据路径中通过私有访问模式和共享访问模式来访问,而无需在内存单元中移动。
40.根据实施方案,多个列中的每一列可以包括一个pe,并且多个pe可以是相同的,并且可以形成一行重复的相同pe。
41.根据实施方案,多个列中的每一列可以包括两个或更多个pe,并且多个pe形成两行或更多行。
42.根据实施方案,第一行pe可以配置成实施第一组指令,并且第二行pe可以配置成实施第二组指令,该第二组指令中的至少一个指令可以不在该第一组指令中,并且多个列可以相同并可以形成重复的列。
43.根据实施方案,多个pe中的每一个可以包括多个算术逻辑单元(alu),这些算术逻辑单元可以配置成在并行线程中执行相同的指令。
44.根据实施方案,多个pe中的每一个可以包括用于多个alu的多个数据缓冲器,并且可以配置成独立操作。
45.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址访问内存单元,并且在私有访问模式下,向量地址中的一个地址可以根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据可以位于同一内存组中。
46.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址来访问内存单元,并且在共享访问模式下,向量地址中的一个地址可以在无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据可以分布在所有内存组中。
47.根据实施方案,多个pe可以形成pe阵列,并且执行内核可以基于pe阵列的大小、多个pe之间的连接以及内存访问能力映射到处理器上的一个或多个物理数据路径中。
48.在又一示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe);多个数据交换盒,该多个数据交换盒布置在多个列中,多个数据交换盒中的每一个与相应的 pe相关联,并且配置成为相应的pe提供输入数据切换;多个内存端口,该多个内存端口布置在多个列中,并且耦合到内存单元和多个列的每一列中的顶部数据交换盒,多个内存端口中的每一个配置成为相应列中的一个或多个数据交换盒提供对内存单元的数据访问;多个列间数据交换盒(icsb),该多个列间数据交换盒各自耦合到多个列的每一列中的底部数据交换盒;以及垫片内存,其中其输入耦合到多个列的最后一列中的内存端口、pe、一个或多个数据交换盒和icsb,并且其输出耦合到多个列的第一列中的内存端口、一个或多个数据交换盒和icsb。
49.根据实施方案,处理器可以进一步包括耦合到多个pe、多个数据交换盒、多个icsb、多个内存端口和垫片内存以将配置递送到这些组件的序列发生器。
50.根据实施方案,处理器可以进一步包括耦合到序列发生器以存储用于序列发生器解码和递送的编译配置的配置内存。
51.根据实施方案,处理器可以进一步包括用于为处理器提供数据存储的内存单元。
52.在另一示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe),该多个处理单元各自包括配置缓冲器和多个算术逻辑单元(alu),并且各自配置成根据存储在配置缓冲器中的相应pe配置独立操作;以及垫片内存,该垫片内存耦合到该多个pe并配置成存储至少一个pe执行结果以在下一pe配置期间由多个pe中的至少一个使用。
53.根据实施方案,处理器可以进一步包括多个数据交换盒,该多个数据交换盒各自包括配置成存储数据交换盒配置的配置缓冲器,多个数据交换盒中的每一个与多个pe中的相应pe 相关联,并且配置成根据数据交换盒配置为相应pe提供输入数据切换。
54.根据实施方案,多个数据交换盒及其相关联的pe可以布置在多个列中,该多个列的第一列中的第一数据交换盒可以耦合在垫片内存和多个列的第一列中的第一个pe之间,并且多个列的最后一列中的第二个pe可以耦合到垫片内存。
55.根据实施方案,处理器可以进一步包括:内存单元,该内存单元用于为多个pe提供数据存储;以及多个内存端口,该多个内存端口各自布置在多个列的不同列中,用于多个pe 访问内存单元。
56.根据实施方案,处理器可以进一步包括多个列间数据交换盒(icsb),该多个列间数据交换盒各自包括配置成存储icsb配置的配置缓冲器,多个icsb可以配置为根据icsb配置在多个列中的相邻列之间提供数据切换。
57.根据实施方案,多个内存端口(mp)中的每一个可以包括配置缓冲器以存储mp配置,并且可以配置成在一个mp配置期间以私有访问模式或共享访问模式操作。
58.根据实施方案,存储在内存单元中的一段数据可以在程序的不同部分中通过私有访问模式和共享访问模式来访问,而无需在内存单元中移动。
59.根据实施方案,多个列中的每一列可以包括一个pe,多个pe是相同的,并且形成一行重复的相同pe。
60.根据实施方案,多个列中的每一列可以包括两个或更多个pe,并且多个pe形成两行或更多行。
61.根据实施方案,第一行pe可以配置成实施第一组指令,并且第二行pe可以配置成实施第二组指令,该第二组指令中的至少一个指令不在该第一组指令中,并且多个列可以相同并形成重复的列。
62.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址访问内存单元,并且在私有访问模式下,向量地址中的一个地址可以根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据可以位于同一内存组中。
63.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址来访问内存单元,并且在共享访问模式下,向量地址中的一个地址可以无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据可以分布在所有内存组中。
64.根据实施方案,多个pe中的每一个可以包括用于多个alu的多个数据缓冲器,并且可以配置成独立操作。
65.在又一示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe);该多个处理单元布置在多个列中;多个数据交换盒(sb),该多个数据交换盒各自与多个pe 中的不同pe相关联,以提供数据切换;以及垫片内存,该垫片内存耦合到多个pe,并且配置成存储至少一个pe执行结果,该至少一个pe执行结果将经由数据交换盒递送到多个pe 中的至少一个以便于该pe执行结果在下一个pe配置期间用作输入数据。
66.在另一示例性实施方案中,提供了一种方法,该方法包括将执行内核映射到虚拟数据路径中。执行内核可以包括要由处理器执行的指令序列,并且处理器可以包括形成重复列的各种可重构单元。该方法可以进一步包括:将虚拟数据路径分割成一个或多个物理数据路径,以将每个物理数据路径分别适配到重复列中;以及将配置递送给处理器的各种可重构单元,以供各种可重构单元形成用于执行该指令序列的一个或多个物理数据路径。
67.在又一示例性实施方案中,提供了一种方法,该方法包括:将执行内核映射到虚拟数据路径中以便处理器执行,该处理器包括形成重复列的各种可重构单元;将虚拟数据路径分割成多个物理数据路径,该多个物理数据路径包括适配到重复列中的第一物理数据路径和适配到重复列中的第二物理数据路径;以及将配置递送给重复列的各种可重构单元,以形成用于执行该执行内核的第一部分的第一物理数据路径,以及形成用于执行该执行内核的第二部分的第二物理数据路径。
68.在又一示例性实施方案中,提供了一种处理器,该处理器包括:多个可重构单元,该多个可重构单元包括多个处理单元(pe)和用于多个pe访问内存单元的多个内存端口(mp),多个可重构单元中的每一个包括配置缓冲器和重构计数器;以及序列发生器,该序列发生器耦合到多个可重构单元中的每一个的配置缓冲器,并且配置成将多个配置分配给用于多个pe 和多个内存端口的多个可重构单元以执行指令序列。
69.根据实施方案,多个配置中的每一个可以包括指定的次数,并且多个pe和多个内存端口中的每一个的重构计数器可以配置成对相应的pe或mp进行计数,以将指令序列中的指令重复指定的次数。
70.根据实施方案,多个可重构单元可以进一步包括多个数据切换单元,多个数据切换单元中的每一个可以配置成根据当前数据切换配置进行指定次数的数据切换设置。
71.根据实施方案,多个可重构单元可以进一步包括垫片内存,垫片内存可以包括多个数据缓冲器、输入配置缓冲器、输出配置缓冲器、多个输入重构计数器和多个输出重构计数器,并且垫片内存可以配置成独立地执行用于输入和输出的重构。
72.根据实施方案,多个配置可以包括用于多个可重构单元形成第一物理数据路径的第一组配置,以及用于多个可重构单元形成第二物理数据路径的第二组配置,垫片内存可以配置成存储来自第一物理数据路径的数据以用作对第二物理数据路径的输入。
73.根据实施方案,多个可重构单元中的每一个可以配置成在其重构计数器达到指定次数之后独立地切换到下一配置。
74.根据实施方案,多个内存端口中的每一个可以配置成在一个配置期间以私有内存访问模式或共享内存访问模式操作。
75.根据实施方案,存储在内存单元中的一段数据可以在不同物理数据路径的配置中通过私有内存访问模式和共享内存访问模式来访问,而无需在内存单元中移动。
76.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址访问内存单元,并且在私有内存访问模式下,向量地址中的一个地址可以根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据可以位于同一内存组中。
77.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址来访问内存单元,并且在共享内存访问模式下,向量地址中的一个地址可以无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据可以分布在所有内存组中。
78.根据实施方案,多个pe中的每一个可以包括多个算术逻辑单元(alu),这些算术逻辑单元可以配置成在并行线程中执行相同的指令。
79.根据实施方案,多个pe中的每一个可以包括多个数据缓冲器,并且可以配置成独立操作。
80.根据实施方案,多个pe可以形成两行或更多行。根据实施方案,第一行pe可以配置成实施第一组指令,并且第二行pe可以配置成实施第二组指令,该第二组指令中的至少一个指令不在该第一组指令中。
81.根据实施方案,多个pe和多个内存端口(mp)可以布置在重复的列中。
82.根据实施方案,指令序列中的每一个可以根据相应的配置由多个pe中的一个pe或多个内存端口中的一个内存端口作为流水线级来执行。
83.在又一示例性实施方案中,提供了一种方法,该方法包括:将多个配置递送到处理器的多个可重构单元,以便于多个可重构单元形成用于执行指令序列的多个物理数据路径,多个配置中的每一个包括指定的次数;在多个可重构单元的每一个处重复相应的操作指定次数,包括在第一物理数据路径中根据第一配置在第一可重构处理单元(pe)处执行指令序列中的第一指令指定次数;以及在重复相应操作指定次数之后将多个重构单元中的每一个重构为新配置,包括在第二物理数据路径中根据第二配置,在第一可重构pe处执行指令序列中的第二指令指定次数。
84.根据实施方案,多个重构单元可以包括多个pe和多个内存端口,并且指令序列中的至少一个指令可以是内存访问指令,并且在通过应用下一内存端口配置来重构内存端口
之前由内存端口执行指定次数。
85.根据实施方案,多个可重构单元可以进一步包括多个数据切换单元,并且多个数据切换单元中的每一个可以配置成通过将根据当前数据切换配置的数据切换设置应用指定次数来重复相应的操作。
86.根据实施方案,该方法可以进一步包括垫片内存。垫片内存可以包括多个数据缓冲器、输入配置缓冲器、输出配置缓冲器、多个输入重构计数器和多个输出重构计数器。以及垫片内存可以配置成独立地执行用于输入和输出的重构。
87.根据实施方案,该方法可以进一步包括将来自第一物理数据路径的数据存储在垫片内存中,以用作对第二物理数据路径的输入。
88.根据实施方案,多个pe中的每一个可以包括多个算术逻辑单元(alu),这些算术逻辑单元可以配置成在并行线程中执行相同的指令。
89.根据实施方案,多个内存端口中的每一个可以配置成在一个配置期间以私有内存访问模式或共享内存访问模式操作。
90.根据实施方案,该方法还可以进一步包括在不同的物理数据路径中通过私有内存访问模式和共享内存访问模式访问存储在内存单元中的一段数据,而无需在内存单元中移动。
91.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址访问内存单元,并且在私有内存访问模式下,向量地址中的一个地址根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据位于同一内存组中。
92.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址来访问内存单元,并且在共享内存访问模式下,向量地址中的一个地址可以无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据分布在所有内存组中。
93.根据实施方案,多个pe中的每一个可以包括多个数据缓冲器,并且可以配置成在一个物理数据路径配置期间独立操作。
94.根据实施方案,多个pe可以形成pe阵列,并且指令序列可以基于pe阵列的大小、多个pe之间的连接以及内存访问能力映射到处理器上的一个或多个物理数据路径中。
95.在又一示例性实施方案中,提供了一种方法,该方法包括:将第一组配置递送到处理器的多个可重构单元,以便于多个可重构单元形成用于执行指令序列的第一部分的第一物理数据路径,第一组配置中的每一个包括指定的次数;将第二组配置递送到多个可重构单元,以便于多个可重构单元形成用于执行指令序列的第二部分的第二物理数据路径,第二组配置中的每一个包括指定的次数;在多个可重构单元处应用第一组配置,以便于多个可重构单元中的每一个将相应的操作重复指定次数,从而执行第一物理数据路径;将来自第一物理数据路径的数据存储到垫片内存;以及在多个可重构单元处应用第二组配置,以便于多个可重构单元中的每一个将相应的操作重复指定次数,从而执行第二物理数据路径,同时存储在垫片内存中的数据作为对第二物理数据路径的输入。
96.根据实施方案,垫片内存可以包括多个数据缓冲器、输入配置缓冲器、输出配置缓冲器、多个输入重构计数器和多个输出重构计数器,并且其中垫片内存可以配置成独立地执行用于输入和输出的重构。
97.根据实施方案,多个重构单元可以包括多个pe和多个内存端口,并且指令序列中
的至少一个指令可以是内存访问指令,并且在可以通过应用下一内存端口配置来重构内存端口之前由内存端口执行指定次数。
98.根据实施方案,多个可重构单元可以进一步包括多个数据切换单元,并且多个数据切换单元中的每一个可以配置成通过将根据当前数据切换配置的数据切换设置应用指定次数来重复相应的操作。
99.根据实施方案,多个pe中的每一个可以包括多个算术逻辑单元(alu),这些算术逻辑单元可以配置成在并行线程中执行相同的指令。
100.根据实施方案,多个内存端口中的每一个可以配置成在一个配置期间以私有内存访问模式或共享内存访问模式操作。
101.根据实施方案,该方法还可以进一步包括在不同的物理数据路径中通过私有内存访问模式和共享内存访问模式访问存储在内存单元中的一段数据,而无需在内存单元中移动。
102.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址访问内存单元,其中在私有内存访问模式下,向量地址中的一个地址可以根据线程索引路由到内存单元的一个内存组,并且一个线程的所有私有数据位于同一内存组中。
103.根据实施方案,多个内存端口中的每一个可以配置成使用向量地址来访问内存单元,并且在共享内存访问模式下,向量地址中的一个地址可以无论线程索引如何而在一个指定区域中跨内存组路由,并且共享给所有线程的数据可以分布在所有内存组中。
104.根据实施方案,多个pe中的每一个可以包括多个数据缓冲器,并且可以配置成在一个物理数据路径配置期间独立操作。
105.根据实施方案,多个pe可以形成pe阵列,并且指令序列可以基于pe阵列的大小、多个pe之间的连接以及内存访问能力映射到处理器上的一个或多个物理数据路径中。
106.在另一示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe),该多个处理单元各自具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及多个内存端口(mp),该多个内存端口用于多个pe访问内存单元,多个mp中的每一个包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的不同内存组。
107.根据实施方案,地址计算单元可以具有:耦合到基地址输入的第一输入,基地址输入提供所有线程公用的基地址;耦合到向量地址的第二输入,向量地址为每个线程单独提供地址偏移;以及耦合到计数器的第三输入,计数器配置用于提供线程索引。
108.根据实施方案,向量地址中的一个地址可以根据线程索引路由到一个内存组。
109.根据实施方案,内存单元可以包括多个内存高速缓存,该多个内存高速缓存各自与一个不同的内存组相关联。
110.根据实施方案,多个内存端口中的每一个可以耦合到多个内存高速缓存。
111.根据实施方案,每个内存组可以包括多个内存字,并且内存高速缓存中的高速缓存未命中导致从与内存高速缓存相关联的内存组中提取字。
112.根据实施方案,多个pe中的每一个可以包括用于分开地存储每个线程的数据的多个数据缓冲器。
113.根据实施方案,处理器可以进一步包括耦合到多个内存端口的序列发生器,并且
多个内存端口中的每一个可以包括配置缓冲器以从序列发生器接收一个或多个配置,并且每个内存端口可以配置成在一个配置期间提供相同的内存访问模式。
114.根据实施方案,一个线程的连续数据段可以位于内存组的一个字中,并在内存组的下一个字中继续。
115.根据实施方案,一个线程的连续数据段可以位于内存组的连续字的相同位置。
116.根据实施方案,多个mp可以配置成一列模式,其中一个mp可以配置成针对一个pe中的所有并发线程访问内存单元,并且地址偏移对于每个线程来说可以是独立的。
117.根据实施方案,多个mp可以配置成线性模式,其中多个mp可以配置成访问内存单元,其中第一个mp可以配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp 可以配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp中的地址偏移可以与第一个mp中的地址偏移成线性。
118.根据实施方案,多个mp可以配置成反线性模式,其中多个mp可以配置成访问内存单元,其中第一个mp可以配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个 mp可以配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp中的地址偏移可以与第一个mp中的地址偏移成反线性。
119.根据实施方案,多个mp可以配置成重叠模式,其中多个mp配置成访问内存单元,其中第一个mp配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp中的地址偏移与第一个mp中的地址偏移有重叠。
120.根据实施方案,多个mp可以配置成非单位步幅模式,其中多个mp配置成访问内存单元,其中第一个mp配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp 配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp中的地址偏移和第一个 mp中的地址偏移可以以步幅间隔开。
121.根据实施方案,多个mp可以配置成随机模式,其中多个mp可以配置成访问内存单元,并且不同mp中的地址偏移可以是随机数。
122.根据实施方案,内存单元可以包括多个内存高速缓存,该多个内存高速缓存各自与一个不同的内存组相关联,并且随机数可以在取决于内存高速缓存大小的范围内。
123.根据实施方案,内存单元可以配置成用作寄存器,以存储用于寄存器溢出的溢出变量。
124.在另一示例性实施方案中,提供了一种方法,该方法包括:由多个内存端口中的一内存端口中的地址计算单元生成多个内存地址,其中多个内存端口为多个处理单元(pe)提供对内存单元的访问,该多个处理单元各自具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及使用多个内存地址访问内存单元中的多个内存组,其中每个线程访问内存单元中的不同内存组。
125.根据实施方案,地址计算单元可以具有:耦合到基地址输入的第一输入,基地址输入提供所有线程公用的基地址;耦合到向量地址的第二输入,向量地址为每个线程单独提供地址偏移;以及耦合到计数器的第三输入,计数器配置用于提供线程索引,并且地址计算单元可以配置成使用第一输入、第二输入和第三输入来生成多个内存地址。
126.根据实施方案,向量地址中的一个地址可以根据线程索引路由到一个内存组。
127.根据实施方案,内存单元可以包括多个内存高速缓存,该多个内存高速缓存各自与一个不同的内存组相关联,并且访问内存单元中的多个内存组可以包括访问多个内存高速缓存。
128.根据实施方案,多个内存端口中的每一个可以耦合到多个内存高速缓存。
129.根据实施方案,该方法可以进一步包括当与内存组相关联的内存高速缓存中存在高速缓存未命中时,从内存组的多个字中提取字。
130.根据实施方案,该方法可以进一步包括将每个线程的数据存储在多个pe的每个pe中的不同数据缓冲器中。
131.根据实施方案,该方法可以进一步包括由内存端口从序列发生器接收一个或多个配置,并且内存端口可以配置成在一个配置期间提供相同的内存访问模式。
132.根据实施方案,一个线程的连续数据段可以位于内存组的一个字中,并在内存组的下一个字中继续。
133.根据实施方案,一个线程的连续数据段可以位于内存组的连续字的相同位置。
134.根据实施方案,访问内存单元中的多个内存组可以使用一列模式,其中一个mp可以配置成针对一个pe中的所有并发线程访问内存单元,并且地址偏移对于每个线程来说是独立的。
135.根据实施方案,访问内存单元中的多个内存组可以使用线性模式,其中多个mp可以配置成访问内存单元,并且第一个mp可以配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp可以配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp 中的地址偏移可以与第一个mp中的地址偏移成线性。
136.根据实施方案,访问内存单元中的多个内存组可以使用反线性模式,其中多个mp可以配置成访问内存单元,并且第一个mp可以配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp可以配置成针对第二个pe中的所有并发线程访问内存单元,第二个 mp中的地址偏移可以与第一个mp中的地址偏移成反线性。
137.根据实施方案,访问内存单元中的多个内存组可以使用重叠模式,其中多个mp可以配置成访问内存单元,并且第一个mp可以配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp可以配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp 中的地址偏移可以与第一个mp中的地址偏移有重叠。
138.根据实施方案,访问内存单元中的多个内存组可以使用非单位步幅模式,其中多个mp 可以配置成访问内存单元,并且第一个mp可以配置成针对第一个pe中的所有并发线程访问内存单元,并且第二个mp可以配置成针对第二个pe中的所有并发线程访问内存单元,第二个mp中的地址偏移和第一个mp中的地址偏移可以以步幅间隔开。
139.根据实施方案,访问内存单元中的多个内存组可以使用随机模式,其中多个mp可以配置成访问内存单元,并且不同mp中的地址偏移可以是随机数。
140.根据实施方案,内存单元可以包括多个内存高速缓存,该多个内存高速缓存各自与一个不同的内存组相关联,并且随机数可以在取决于内存高速缓存大小的范围内。
141.根据实施方案,该方法可以进一步包括存储用于寄存器溢出的变量。
142.在示例性实施方案中,提供了一种处理器,该处理器包括:内存单元,该内存单元包括多个内存组;多个处理单元(pe),该多个处理单元各自具有配置成在并行线程中执行
相同指令的多个算术逻辑单元(alu);以及多个内存端口(mp),该多个内存端口用于多个pe 访问内存单元,多个mp中的每一个包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的不同内存组。
143.根据实施方案,地址计算单元可以具有:耦合到基地址输入的第一输入,基地址输入提供所有线程公用的基地址;耦合到向量地址的第二输入,向量地址为每个线程单独提供地址偏移;以及耦合到计数器的第三输入,计数器配置用于提供线程索引。
144.在例性实施方案中,提供了一种处理器,该处理器包括:处理单元(pe),该处理单元具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及内存端口(mp),该内存端口用于pe访问内存单元,该mp包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的不同内存组。
145.根据实施方案,pe可以是多个pe中的一个,该多个pe各自具有配置成在并行线程中执行相同指令的多个alu。
146.根据实施方案,该mp可以是多个mp中的一个,该多个mp各自具有地址计算单元,该地址计算单元配置成为多个pe的一个pe中的每个线程生成各自的内存地址,以访问内存单元中的不同内存组。
147.在另一示例性实施方案中,提供了一种方法,该方法包括:由内存端口中的地址计算单元生成多个内存地址,其中内存端口为处理单元(pe)提供对内存单元的访问,该处理单元具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及使用多个内存地址访问内存单元中的多个内存组,其中每个线程访问内存单元中的不同内存组。
148.根据实施方案,pe可以是多个pe中的一个,该多个pe各自可以具有配置成在并行线程中执行相同指令的多个alu。
149.根据实施方案,该mp可以是多个mp中的一个,该多个mp各自可以具有地址计算单元,该地址计算单元配置成为多个pe的一个pe中的每个线程生成各自的内存地址,以访问内存单元中的不同内存组。
150.在示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe),该多个处理单元各自具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及多个内存端口(mp),该多个内存端口用于多个pe访问内存单元,多个mp中的每一个包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的公用区域。
151.根据实施方案,地址计算单元可以具有:耦合到基地址输入的第一输入,基地址输入提供所有线程公用的基地址;以及耦合到向量地址的第二输入,向量地址为每个线程单独提供地址偏移。
152.根据实施方案,地址计算单元可以配置成生成与pe中的多个线程匹配的多个内存地址。
153.根据实施方案,多个mp中的每一个可以进一步包括耦合到多个内存地址的多个选择单元,多个选择单元中的每一个可以配置成选择零个或更多个内存地址以将其路由到内存单元的一个内存组。
154.根据实施方案,每个选择单元可以配置成用一个掩码来选择内存单元的不同内存组。
155.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,并且地址偏移对于所有线程而言可以是相同的。
156.根据实施方案,多个mp可以配置成针对不同pe中的线程访问内存单元,地址偏移在一个mp中可以相同,但是对于不同mp则不同。
157.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,并且地址偏移在mp中可以是顺序的。
158.根据实施方案,多个mp可以配置成针对不同pe中的线程访问内存单元,地址偏移可以在每个mp内分别是顺序的。
159.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,地址偏移可以是顺序的,具有不连续性。
160.根据实施方案,多个mp可以配置成针对不同pe中的不同线程访问内存单元,地址偏移分别在mp中的每一个中可以是顺序的,具有不连续性。
161.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,地址偏移可以是线性的,具有非单位步幅。
162.根据实施方案,多个mp可以配置成针对一个pe中的所有线程访问内存单元,地址偏移可以是随机的,但是在一个小范围c到c+r内,小范围c到c+r取决于内存高速缓存的大小。
163.根据实施方案,多个mp可以配置成针对不同pe中的线程访问内存单元,地址偏移可以是随机的,但是具有一个小范围c到c+r内,小范围c到c+r取决于内存高速缓存的大小。
164.根据实施方案,公用区域可以包括内存单元的所有内存组。
165.根据实施方案,内存单元可以包括多个内存高速缓存,该多个内存高速缓存各自与一个不同的内存组相关联。
166.根据实施方案,多个内存端口中的每一个可以耦合到多个内存高速缓存。
167.根据实施方案,每个内存组可以包括多个内存字,并且内存高速缓存中的高速缓存未命中导致从与内存高速缓存相关联的内存组中提取内存字。
168.根据实施方案,多个pe中的每一个可以包括用于分开地存储每个线程的数据的多个数据缓冲器。
169.根据实施方案,处理器可以包括耦合到多个内存端口的序列发生器,并且多个内存端口中的每一个可以包括配置缓冲器以从序列发生器接收一个或多个配置,并且每个内存端口可以配置成在一个配置期间提供相同的内存访问模式。
170.在又一示例性实施方案中,提供了一种方法,该方法包括:由多个内存端口中的一内存端口中的地址计算单元生成多个内存地址,其中多个内存端口为多个处理单元(pe)提供对内存单元的访问,该多个处理单元各自具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及使用多个内存地址访问内存单元中的多个内存组,其中所有线程访问内存单元中的公用区域。
171.根据实施方案,地址计算单元可以将所有线程公用的基地址取为第一输入,并且将为每个线程单独提供地址偏移的向量地址取为第二输入,以生成多个内存地址。
172.根据实施方案,地址计算单元可以配置成生成与pe中的多个线程匹配的多个内存地址。
173.根据实施方案,访问多个内存组可以包括分别使用多个选择单元选择零个或更多个内存地址以将其路由到内存单元的一个内存组。
174.根据实施方案,每个选择单元可以配置成用一个掩码来选择内存单元的不同内存组。
175.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,并且地址偏移对于所有线程而言可以是相同的。
176.根据实施方案,多个mp可以配置成针对不同pe中的线程访问内存单元,地址偏移在一个mp中可以相同,但是对于不同mp则不同。
177.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,并且地址偏移在mp中可以是顺序的。
178.根据实施方案,多个mp可以配置成针对不同pe中的线程访问内存单元,地址偏移可以在每个mp内分别是顺序的。
179.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,地址偏移可以是顺序的,具有不连续性。
180.根据实施方案,多个mp可以配置成针对不同pe中的不同线程访问内存单元,地址偏移分别在mp中的每一个中可以是顺序的,具有不连续性。
181.根据实施方案,一个mp可以配置成针对一个pe中的所有线程访问内存单元,地址偏移可以是线性的,具有非单位步幅。
182.根据实施方案,多个mp可以配置成针对一个pe中的所有线程访问内存单元,地址偏移可以是随机的,但是在一个小范围c到c+r内,小范围c到c+r取决于内存高速缓存的大小。
183.根据实施方案,多个mp可以配置成针对不同pe中的线程访问内存单元,地址偏移可以是随机的,但是具有一个小范围c到c+r内,小范围c到c+r取决于内存高速缓存的大小。
184.根据实施方案,公用区域可以包括内存单元的所有内存组。
185.根据实施方案,内存单元可以包括多个内存高速缓存,该多个内存高速缓存各自与一个不同的内存组相关联。
186.根据实施方案,多个内存端口中的每一个可以耦合到多个内存高速缓存。
187.根据实施方案,每个内存组可以包括多个内存字,并且内存高速缓存中的高速缓存未命中导致从与内存高速缓存相关联的内存组中提取内存字。
188.根据实施方案,多个pe中的每一个可以包括用于分开地存储每个线程的数据的多个数据缓冲器。
189.根据实施方案,该方法可以进一步包括从序列发生器接收用于多个内存端口中的每一个的一个或多个配置,其中每个内存端口配置成在一个配置期间提供相同的内存访问模式。
190.在又一示例性实施方案中,提供了一种处理器,该处理器包括:内存单元,该内存单元包括多个内存组;多个处理单元(pe),该多个处理单元各自具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及多个内存端口(mp),该多个内存端口用于多个 pe访问内存单元,多个mp中的每一个包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的多个内存组上的公用区域。
191.在例性实施方案中,提供了一种处理器,该处理器包括:处理单元(pe),该处理单元具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及内存端口(mp),该内存端口用于pe访问内存单元,该mp包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的公用区域。
192.根据实施方案,pe可以是多个pe中的一个,该多个pe各自可以具有配置成在并行线程中执行相同指令的多个alu。
193.根据实施方案,该mp可以是多个mp中的一个,该多个mp各自可以具有地址计算单元,该地址计算单元配置成为多个pe的一个pe中的每个线程生成各自的内存地址,以访问内存单元中的公用区域。
194.在另一示例性实施方案中,提供了一种方法,该方法包括:由内存端口中的地址计算单元生成多个内存地址,其中内存端口为处理单元(pe)提供对内存单元的访问,该处理单元具有配置成在并行线程中执行相同指令的多个算术逻辑单元(alu);以及使用多个内存地址访问内存单元中的多个内存组,其中每个线程访问内存单元中的公用区域。
195.根据实施方案,pe可以是多个pe中的一个,该多个pe各自可以具有配置成在并行线程中执行相同指令的多个alu。
196.根据实施方案,该mp可以是多个mp中的一个,该多个mp各自可以具有地址计算单元,该地址计算单元配置成为多个pe的一个pe中的每个线程生成各自的内存地址,以访问内存单元中的公用区域。
197.在又一示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe),该多个处理单元各自包括:算术逻辑单元(alu);与alu相关联的数据缓冲器;以及与数据缓冲器相关联的指示器,用于指示数据缓冲器内的一段数据是否将被流水线的一级重复执行的一个指令重复使用。
198.根据实施方案,处理器进一步包括多个内存端口(mp),该多个内存端口用于多个pe 访问内存单元,多个mp中的每一个可以包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的公用区域,并且多个mp中负责从内存单元加载一段数据以便于该段数据在pe处被重复使用的一个mp可以配置成仅加载该段数据一次。
199.根据实施方案,负责加载将被重复使用的该段数据的mp可以配置成通过确定要在pe 处执行的多个线程正在使用相同的内存地址加载该段数据来确定将重复使用该段数据。
200.根据实施方案,被重复使用的至少一段数据可以是由多个pe中的一个pe生成的执行结果。
201.根据实施方案,多个pe中的每一个pe可以进一步包括用于存储用于每个pe的配置的配置缓冲器和用于对重复执行的次数进行计数的重构计数器,每个配置可以指定要由相应pe 执行的指令和在相应配置期间要重复指令的次数。
202.根据实施方案,alu可以是向量alu,并且数据缓冲器可以是向量数据缓冲器,向量数据缓冲器的每个数据缓冲器可以与向量alu的一个alu相关联。
203.根据实施方案,处理器可以进一步包括多个内存端口(mp),该多个内存端口用于多个 pe访问内存单元,多个mp中的每一个可以包括地址计算单元,该地址计算单元配置成
为每个线程生成相应的内存地址,以访问内存单元中的公用区域,并且多个mp中的每一个mp 可以包括至少一个数据缓冲器,用于临时存储从内存单元加载的数据,并且至少一个数据缓冲器中的每一个可以具有与之相关联的指示器,用于指示存储在其中的一段数据是否将重复用于其他加载操作。
204.根据实施方案,每个pe可以包括与alu相关联的多个数据缓冲器,多个数据缓冲器中的每一个可以配置成存储用于alu的分开的输入,并且可以具有相关联的指示器,用于指示相应的输入是否将在重复的执行中被重复使用。
205.在又一示例性实施方案中,提供了一种方法,该方法包括:确定在处理器的处理单元(pe) 处施加的一个配置期间,一段数据将在处理器的处理单元(pe)处由所有线程共享和重复使用;将该段数据加载一次到pe的数据缓冲器中;设置与数据缓冲器相关联的指示器,用于指示该段数据将被重复使用;以及利用该段数据作为pe处的输入作为流水线的一级重复地执行相同的指令多次,相同的指令和次数由配置指定。
206.根据实施方案,该方法可以进一步包括从内存单元加载该段数据以便于该段数据被加载到pe的数据缓冲器中,其中处理器包括多个pe和用于多个pe访问内存单元的多个内存端口(mp),其中多个mp中负责从内存单元加载该段数据的一个mp配置成仅加载该段数据一次。
207.根据实施方案,该方法可以进一步包括由处理器的多个pe中的一个生成该段数据作为执行结果。
208.根据实施方案,该方法可以进一步包括接收配置并将该配置存储在pe的配置缓冲器中,其中该配置可以指定要由pe执行的指令和指令要重复的次数。
209.根据实施方案,确定该段数据可以将在pe处由所有线程共享和重复使用包括确定所有线程可以正在使用相同的内存地址来访问该段数据。
210.根据一个实施方案,该方法可以进一步包括将该段数据加载一次到内存端口的数据缓冲器中,该内存端口为pe提供对内存单元的访问;设置与内存端口的数据缓冲器相关联的指示器,用于指示该段数据将重复用于访问相同内存地址的其他加载操作。
211.在又一示例性实施方案中,提供了一种处理器,该处理器包括:多个处理单元(pe),该多个处理单元各自包括:向量算术逻辑单元(alu),该向量算术逻辑单元包括多个alu;与多个alu中的每一个相关联的多个数据缓冲器;以及各自与不同的数据缓冲器相关联的多个指示器,用于指示相应的数据缓冲器内的一段数据是否将被流水线的一级重复执行的一个指令重复使用。
212.根据实施方案,处理器可以进一步包括多个内存端口(mp),该多个内存端口用于多个 pe访问内存单元,多个mp中的每一个可以包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的公用区域,其中,多个mp中负责从内存单元加载一段数据以便于该段数据在pe处被重复使用的一个mp可以配置成仅加载一次该段数据。
213.根据实施方案,负责加载将被重复使用的该段数据的mp可以配置成通过确定要在pe 处执行的多个线程可以正在使用相同的内存地址加载该段数据来确定将可以重复使用该段数据。
214.根据实施方案,被重复使用的至少一段数据可以是由多个pe中的一个pe生成的执
行结果。
215.根据实施方案,处理器可以进一步包括多个内存端口(mp),该多个内存端口用于多个 pe访问内存单元,多个mp中的每一个可以包括地址计算单元,该地址计算单元配置成为每个线程生成相应的内存地址,以访问内存单元中的公用区域,并且多个mp中的每一个mp 可以包括至少一个数据缓冲器,用于临时存储从内存单元加载的数据,并且至少一个数据缓冲器中的每一个可以具有与之相关联的指示器,用于指示存储在其中的一段数据是否将可以重复用于其他加载操作。
216.根据实施方案,多个数据缓冲器中的每一个可以是具有多个数据缓冲器单元的向量数据缓冲器,并且将重复执行所重复使用的一段数据可以复制在一个向量数据缓冲器的所有数据缓冲器单元中。
217.根据实施方案,多个数据缓冲器中的每一个可以是具有多个数据缓冲器单元的向量数据缓冲器,并且将重复执行所重复使用的一段数据可以仅存储在一个向量数据缓冲器的一个数据缓冲器单元中。
218.在又一示例性实施方案中,提供了一种方法,该方法包括:在处理器的可重构单元处接收第一配置和第二配置,该可重构单元具有用于存储第一配置和第二配置的配置缓冲器;根据第一配置执行第一操作第一次数,第一配置是用于执行指令序列的第一部分的第一物理数据路径的部分;以及重构可重构单元以根据第二配置执行第二操作第二次数,第二配置是用于执行指令序列的第二部分的第二物理数据路径的部分。
219.在另一示例性实施方案中,提供了一种方法,该方法包括:根据第一配置,在可重构处理单元处执行第一指令多次,该可重构处理单元配置成在第一配置期间是第一物理数据路径的部分;在第一指令的每次执行之后,将来自可重构处理单元的执行结果递送到垫片内存,以临时存储该执行结果;以及将存储在垫片内存中的执行结果馈送到第二物理数据路径。
附图说明
220.图1示意性地示出了具有pe阵列的现有技术cgra。
221.图2示意性示出了根据本公开的一个实施方案的一个处理器。
222.图3a示意性示出了根据本公开的一个实施方案的用于处理器的一个内存系统。
223.图3b示意性示出了根据本公开的一个实施方案的用于私有内存访问模式的一个第一内存映射。
224.图3c示意性示出了根据本公开的一个实施方案的用于私有内存访问模式的一个第二内存映射。
225.图3d示意性示出了根据本公开的一个实施方案的用于共享内存访问的一个内存映射。
226.图4a示意性示出了根据本公开的一个实施方案的用于一个内存端口的一个第一内存访问配置。
227.图4b示意性示出了根据本公开的一个实施方案的用于一个内存端口的一个第二内存访问配置。
228.图5示意性示出了根据本公开的一个实施方案的用于一个处理器的一个数据交换
盒。
229.图6a示意性示出了根据本公开的一个实施方案的用于一个处理器的一个处理单元。
230.图6b示意性示出了根据本公开的一个实施方案的用于一个处理器的另一个处理单元。
231.图7示意性示出了根据本公开的一个实施方案的用于一个处理器的一个列间数据交换盒。
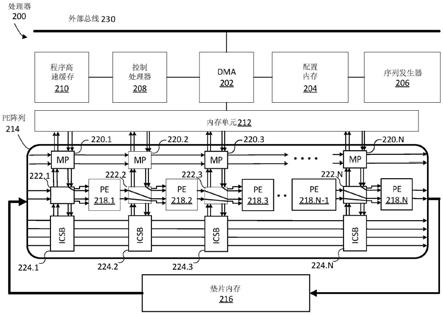
232.图8示意性示出了根据本公开的一个实施方案的用于一个处理器的一个垫片内存。
233.图9a示意性示出了根据本公开的一个实施方案的一个执行内核的一个依赖图。
234.图9b示意性示出了根据本公开的一个实施方案将图9a的执行内核映射到一个处理器的一个虚拟数据路径的依赖图。
235.图9c示意性地示出了根据本公开的一个实施方案将图9b的虚拟数据路径划分为一个处理器的物理数据路径。
236.图10示意性示出了根据本公开的一个实施方案的一个处理器的一个流水线操作。
237.图11a至图11i示意性示出了根据本公开的一个实施方案的一个处理器的一个配置过程。
238.图12a示意性示出了根据本公开的一个实施方案的一个处理器执行一个指令流的一个流水线操作。
239.图12b示意性示出了根据本公开的一个实施方案的一个处理器执行一个指令流的精简流水线操作。
240.图13是根据本公开的一个实施方案的执行一个执行内核的方法的一个流程图。
241.图14是根据本公开的一个实施方案的一个重构方法的一个流程图。
242.图15是根据本公开的一个实施方案的另一个重构方法的一个流程图。
243.图16是根据本公开的一个实施方案的另一个重构方法的一个流程图。
244.图17是根据本公开的一个实施方案的一个访问内存的方法的一个流程图。
245.图18是根据本公开的一个实施方案的另一个访问内存的方法的一个流程图。
246.图19是根据本公开的一个实施方案的一个重复使用一段数据的方法的一个流程图。
具体实施方式
247.现在将详细参考本教导的实施方案,其示例在附图中示出。为了一致性,不同附图中的相同元件通过相同的附图标记表示。虽然将结合实施方案描述本教导,但是应当理解的是,其并不旨在将本教导限制于这些实施方案。相反,本教导旨在覆盖替换方案、修改和等同物,这些替换方案、修改和等同物可以包括在由所附权利要求限定的本教导的精神和范围内。
248.此外,在本教导的实施方案的以下详细描述中,阐述了许多具体细节,以便提供对本教导的透彻理解。然而,本领域普通技术人员将认识到,在没有这些具体细节的情况下也可以实践本教导。在其他情况下,没有详细描述众所周知的方法、过程、组件和电路,以免不
必要地模糊本教导的实施方案的各个方面。
249.图2示意性示出了根据处理器的一个实施方案的处理器200。处理器200可以包括直接内存访问(dma)模块202、配置内存204、序列发生器206、控制处理器208、程序高速缓存210、内存单元212、pe阵列214和垫片内存216。dma模块202可以耦合到外部总线230,并且可以由控制处理器208控制。dma模块202可以负责将可执行指令和不可执行数据从外部总线230移入和移出。程序高速缓存210可以存储由控制处理器208用于控制dma模块 202的操作的指令和数据。在一个实施方案中,存储在程序高速缓存210中的指令和数据可以由控制处理器208用于处理序列发生器程序。
250.应当注意的是,如本文所使用的,两个组件之间的“耦合”(诸如一个组件“耦合”到另一组件)可以指两个组件之间的电子连接,其可以包括但不限于通过电子布线、通过电子元件(例如电阻器、晶体管)等。而且,在一些实施方案中,处理器200可以配置成用于大规模线程级并行处理。例如,pe阵列214中的一个处理单元(pe)可以包括多个算术逻辑单元 (alu),这些算术逻辑单元可以配置成(例如,每个在单独的线程中)对不同的数据执行相同的操作。也就是说,在具有多个alu的这些实施方案中,每个pe可以配置成以单指令多线程(single instruction multiple threads,simt)方式操作。在一个实施方案中,具有向量地址和向量数据输入的pe可以生成向量数据输出。在一些实施方案中,线程也可被称为流。
251.为了为将被同时执行的多线程提供数据,在一些实施方案中,处理器200的组件之间的一些相关电子连接可以呈向量形式。例如,hxg的向量地址可以具有h个g比特地址,kxw 的向量数据连接可以具有k个w比特数据。还应当注意的是,尽管未在任何附图中示出,但是不同组件之间的数据或地址连接可以伴随有一个或多个信号线。例如,忙信号线可以存在于第一组件和第二组件之间,并且可以由第一组件用于向第二组件传送指示第一组件没有准备好接受有效数据或地址信号的忙信号。而且,有效信号线也可以存在于第一和第二组件之间,并且可以由第二组件用于向第一组件传送指示有效数据或地址信号已经被放在连接线上的有效信号。
252.配置内存204可以存储由用于一个或多个数据路径的可执行指令和/或数据加载指令组成的数据路径程序。在一个实施方案中,存储在配置内存204中的数据路径程序可以是编译指令的(多个)序列。例如,数据路径程序可以包括要由pe阵列214执行的指令,该指令表示当条件满足时要由哪个pe执行的配置信息,以及每个数据路径组件可以如何保存或发送数据。
253.序列发生器206可以解码存储在配置内存204中的指令,并将解码的指令移动到内存单元212和物理数据路径中。物理数据路径可以包括pe阵列214的各种组件(例如,pe阵列 214中将参与数据的执行、暂存和/或移动的组件)和垫片内存216。解码的指令可用包递送到各个组件,该包可被称为配置包或简单地称为配置。除了解码的指令之外,一个组件的配置包可以包括一些其他参数(例如,在一个配置设置中指定指令被重复执行多少次或者数据通过一个数据切换单元多少次)。在一个实施方案中,物理数据路径配置可被称为物理数据路径程序,该物理数据路径程序可以包括物理数据路径中包括的各种组件的各个配置。尽管未示出,但是可以有一个将序列发生器206连接到数据路径的各个组件的配置总线,用于各个配置分别经由总线递送到这些组件。
254.内存单元212可以是数据暂存区,用于存储从外部总线230接收的数据,并存储由
220.1和icsb224.1之间路由数据。作为另一示例,数据交换盒222.2可以配置成提供数据切换,用于将数据从处理单元218.1、mp 220.2和icsb 224.2递送到处理单元218.2。而且,数据交换盒222.2 可以配置成在处理单元218.2、mp 220.2和icsb 224.2之间路由数据。作为又一示例,数据交换盒222.n可以配置成提供数据切换,用于将数据从pe 218.n-1、mp 220.n和icsb 224.n 递送到处理单元218.n。而且,数据交换盒222.n可以配置成在pe 218.n-1、mp 220.n和icsb224.n之间路由数据。sb也可被称为数据切换单元。
259.示例性数据路径可以通过mp 222.1至222.n的示例性内部连接来说明。例如,如图2所示,mp 222.1示出pe 218.1的两个输入可以耦合到来自mp 2201的两个输出,sb222.2示出 pe 218.2的两个输入可以耦合到来自mp 220.2的两个输出,以及pe 218.2的两个输入可以耦合到来自pe 218.1的两个输出,sb 222.3示出pe 218.3的两个输入可以耦合到来自mp 220.3 的两个输出,以及pe 218.3的两个输入可以耦合到来自pe 218.2的两个输出,依此类推,直到sb222.n示出pe 218.n的两个输入可以耦合到来自mp 220.n的两个输出以及pe 218.n的两个输入可以耦合到来自pe 218.n-1的两个输出。
260.为简化措辞,mp 220可指mp 220.1至220.n中的一个,sb 222可以指sb 222.1至222.n 中的一个,pe 218可以指pe218.1至218.n中的一个,以及icsb 224可以指icsb 224.1至 224.n中的一个。
261.图3a示意性示出了根据本公开的一个实施方案的用于处理器的一个内存系统。内存系统可以包括内存单元300和多个内存端口220.1至220.n。内存单元300可以是图2中内存单元212的实施方案,并且可以包括多个内存组(例如,表示为302.1的内存组0、表示为302.n 的内存组1、表示为302.n的内存组n-1等)和多个内存高速缓存304.1至304.n。内存组302 中的每一个可以耦合一个相应的高速缓存304。例如,内存组302.1可以耦合到高速缓存304.1,内存组302.2可以耦合到高速缓存304.2,内存组302.n可以耦合到高速缓存304.n,依此类推。每个高速缓存304可以单独耦合到所有的多个内存端口220.1-220.n。例如,高速缓存304.1 可以耦合到mp 220.1至220.n,高速缓存304.2可以耦合到mp 220.1至220.n,高速缓存304.n 可以耦合到mp 220.1至220.n,依此类推。
262.除了单独耦合到内存单元300的所有高速缓存304.1至304.n之外,mp 220.1至220.4 可以链接形成行方向数据路由总线,同时mp 220.1和mp 220.n分别在一端处耦合到垫片内存216(如图2所示)。mp 220.1至220.n中的每一个可以进一步包括写数入据(wdata)输入306和读取数据(rdata)输出308。例如,mp 220.1可以包括写入数据输入306.1和读取数据输出308.1,mp 220.2可以包括写入数据输入306.2和读取数据输出308.2,mp 220.n可以包括写入数据输入306.n和读取取数据输出308.n,依此类推。写入数据输入306和读取数据输出308可以耦合到sb 222.1至222.n的相应输出和输入。在一个实施方案中,写入数据输入306中的每一个和读取数据输出308中的每一个可以配置用于向量数据连接。例如,写入数据输入306.1可以是一个32x32输入或两个32x16输入,并且读取数据输出308.1可以是一个32x32输出或两个32x32输出。如本文所使用的,数据输入或数据输出也可被称为数据端口。
263.内存单元300和mp 220.1至220.n可以支持两种访问模式:私有内存访问模式和共享内存访问模式,其也可以称为私有内存访问方法和共享内存访问方法。在一个mp中,可以使用向量地址读取或写入多个数据单元。一个向量中的这些地址可能彼此不同。在私有内
存访问模式中,向量地址中的一个地址可以根据线程索引路由到一个内存组。一个线程的所有私有数据可以位于同一内存组中。在共享内存访问模式中,每个mp都可以访问一个指定区域中的任何位置,无论线程索引如何。共享给所有线程的数据可以分布在所有内存组中。
264.作为一个示例,对于pe阵列的每一列,其可能具有多个总线通过的一个mp。内存端口可以配置成共享的(例如,共享内存访问模式)或私有的(例如,私有内存访问模式)。每个内存端口可以进一步耦合到数据高速缓存网络。
265.图3b示意性示出了根据本公开的一个实施方案的用于私有内存访问模式的第一内存映射。每个内存组302.1到302.n可以包括多个“字(word)”。在图3b中所示的实施方案中,内存组的每个字可以是512位宽,并且可以包含32个数据单元,这些数据单元各自可以是 16位。线程“i”的连续数据单元可被称为si(0)、si(1)、
……
,并且存储在内存组i中。例如,用于线程零(“0”)的数据单元s0(0)、s0(1)到s0(31)可以存储在内存组302.1 中的第一个字中,并且用于线程0的数据单元s0(32)、s0(33)到s0(63)可以存储在内存组302.1中的第二个字中,依此类推。类似地,用于线程一(“1”)的数据单元s1(0)、s1 (1)到s1(31)可以存储在内存组302.2中的第一个字中,并且用于线程1的数据单元s1 (32)、s1(33)到s1(63)可以存储在内存组302.2中的第二个字中,依此类推。并且用于线程31的数据单元s31(0)、s31(1)到s31(31)可以存储在内存组302.n中的第一个字中,并且用于线程31的数据单元s31(32)、s31(33)到s31(63)可以存储在内存组n-1 中的第二个字中,依此类推。
266.在这个第一内存映射的一个实施方案中,用于不同线程的数据单元可以旨在存储在不同的内存组中并且绕回到用于线程n的第一组。例如,对于n等于32,用于第32个线程的数据单元可以存储到内存组0(例如,内存组0中的数据单元s32(0)到s32(31)),用于第 33个线程的数据单元可以存储到内存组1(例如,内存组1中的数据单元s33(0)到s33(31)),用于第63个线程的数据单元可以存储到内存组n-1(例如,内存组0中的数据单元s63(0) 到s63(31)),依此类推。
267.对于图3b的相同内存结构,可以以不同的方式映射数据。图3c示意性示出了根据本公开的实施方案的用于私有内存访问模式的第二内存映射。图3c中示出的内存单元300可以包括与图3a中相同的多个内存组,以及图3c的内存组302.1至302.n中的每个字也可以是 512位宽,并且每个数据单元是16位宽。线程i的连续数据单元仍然可以存储在内存组i中,但存储在不同的字中。例如,用于线程0的数据单元s0(0)、s0(1)等可以在内存组302.1 中在列方向上存储在不同的字中;用于线程1的数据单元s1(0)、s0(1)等可以在内存组 302.2中在列方向上存储在不同的字中;用于线程32的数据单元s31(0)、s31(1)等可以在内存组302.n中在列方向上存储在不同的字中;依此类推。
268.在这个第二内存映射的一个实施方案中,用于不同线程的数据单元可以旨在存储在不同的内存组中并且对于线程n和n的整数倍(例如,2n、3n等)的绕回第一组。而且,具有相同索引的一组不同线程的数据单元可以映射到内存组的相同字。例如,对于n等于32,用于第32线程的数据单元可以存储到内存组302.1的不同字中(例如,内存组302.1第二列中的数据单元s32(0)到s32(99),其中数据单元s0(m)和s32(m)在相同的字中,m是线程中的数据单元的索引),用于第33线程的数据单元可以存储到内存组302.2的不同字中 (例如,内存组302.2中的第二列数据单元s33(0)至s33(99),其中数据单元s1(m)和 s33(m)在同一字
中,m是线程中的数据单元的索引),用于第63线程的数据单元可以存储到内存组302.n(例如,内存组0中的数据单元s63(0)至s63(99),其中数据单元s3l(m) 和s63(m)在同一字中,m是线程中的数据单元的索引),依此类推。因为每个字具有32 个数据单元,所以内存组302.1的第一行中的最后的数据单元可以是线程992的第一数据单元s992(0),内存组302.2的第一行中的最后数据单元可以是线程993的第一数据单元s993 (0),依此类推,直到内存组302.n的第一行中的最后的数据单元可以是线程1023的第一数据单元s1023(0)。应当注意的是,线程可以具有99个以上的数据单元并且si(99)(例如 s0(99)等)可能不是线程的最后的数据单元,并且点划线可能表示更多的数据单元可能存在并存储在内存组中。
269.用于线程1024和更多线程的数据单元可以循环回内存组0的第一列来存储,依此类推。例如,在m为索引的情况下,用于线程1024、1056依此类推直到2016的数据单元(例如, s1024(m)、s1056(m)等直到s2016(m))可以在内存组0的一个字中;用于线程1025、 1057依此类推直到1057的数据单元(例如,s1025(m)、s1057(m)依此类推直到s2017 (m))可以在内存组1的一个字中;以及用于线程105、1087依此类推直到2047的数据单元(例如,s1055(m)、s1087(m)依此类推直到s2047(m))可以在内存组n-1的一个字中。
270.图3d示意性示出了根据本公开的实施方案的用于共享内存访问的内存映射的一个示例。图3d中示出的内存单元300可以包括与图3a中相同的多个内存组,图3d的内存组302.1 至302.n中的每个字也可以是512位宽,并且每个数据单元是16位宽。在这个示例中,用于共享内存访问的内存映射(连续数据单元a(0)、a(1))可以以交错的方式存储在不同的内存组中。例如,对于n等于32,a(0)、a(1)、a(2)等可以分布在n个内存组中,其中a(1)在内存组0中、a(2)在内存组1中,依此类推,直到a(31)在内存组n-1中;并且绕回,其中a(n)在内存组0中、在与a(0)相同的字中,a(n+1)在内存组1中、在与a(1)相同的字中,依此类推,直到a(n+31)在内存组n-1中、在与a(31)相同的字中;并且以此类推绕回,直到a(992)(例如,a(31n))在内存组0中、在与a(0) 相同的字中,a(993)(例如,a(31n+1))在内存组1中、在与a(1)相同的字中,依此类推直到a(1023)(例如,a(31n+31))在内存组n-1中、在与a(31)相同的字中。在可以填充内存组的一个字之后,更多连续的数据单元可以分布在内存组的另一字中。例如, a(1024)、a(1056)到a(2016)可以在内存组0中的另一字中;a(1025)、a(1057) 到a(2017)可以在内存组1中的另一字中;依此类推,直到a(1055)、a(1087)到a(2047) 可以在内存组n-1中的另一字中。
271.不管私有或共享内存访问模式,存储单元300的高速缓存304.1-304.n中的每一个可以包括多个高速缓存线,该多个高速缓存线各自可以临时存储来自相应内存组的内存字。例如,高速缓存304.1可以包括多个高速缓存线,该多个高速缓存线各自可以配置成临时存储从内存组302.1(例如,内存组0)取回的一个字,高速缓存304.2可以包括多个高速缓存线,该多个高速缓存线各自配置成临时存储从内存组302.2(例如,内存组1)取回的一个字,高速缓存304.n可以包括多个高速缓存线,该多个高速缓存线各自配置成临时存储从内存组302.n (例如,内存组n-1)取回的一个字,依此类推。当所请求的一个或多个数据段(例如,一个或多个数据单元)不在高速缓存中时,可能会产生高速缓存未命中。在一个实施方案中,当存在高速缓存未命中时,可以将存储单元300的内存组(例如,在图3b、图3c或图3d 中)的一个内存字作为一个高速缓存线提取到高速缓存中。一般而言,高速缓存大小越大,则越多的高速缓存线可以用来存储内存字,并且可以预期越低的高速缓存未命中率。在一
些实施方案中,高速缓存中的存储单元可以实施为寄存器。
272.内存单元212中的数据存储可以由mp 220.1至220.n通过高速缓存304.1至304.n访问。每一列处的内存端口(mp)可以配置有相同的组件来执行内存操作,例如,计算地址和发布读取和/或存储操作。在一些实施方案中,一个高速缓存304可以同时被多个mp访问。mp 中的每一个可以配置成提供两种访问模式:私有内存访问模式和共享内存访问模式。由于 simt的特性,映射到一个mp的内存不同线程的读取或写入指令属于同一类型,即共享的或私有的。而且,mp可以配置成私有或共享内存访问模式持续一个配置的持续时间。
273.图4a示意性示出了根据本公开的实施方案的用于内存端口(mp)400的第一内存访问配置。mp 400可以是内存端口220的一个实施方案。图4a中示出的第一内存访问配置可以是用于私有内存访问模式的一个示例配置。在操作期间,mp 400可以从序列发生器接收用于物理数据路径的内存端口(mp)配置,并且mp配置可以指定对于该物理数据路径,mp 400 可以配置成用于私有内存访问模式。mp 400可以包括地址计算单元402和计数器404。地址计算单元402可以将基地址取为第一输入,将偏移取为第二输入,并且从计数器404取第三输入。基地址可以是对于所有线程的公用地址。偏移可以耦合到mp 400的地址输入端口,该端口可以配置成接受向量地址。向量地址可以包括用于每一个并发线程的各个地址,并且这些地址可被称为地址偏移。在一个实施方案中,第一内存访问配置中的基地址可以包含线程0的数据单元0(例如s0(0))的起始地址。并发线程的数量可能受到pe中alu的数量以及向量地址和向量数据总线的宽度的限制。例如,如果pe的alu向量中的alu的数量是n,并且向量地址可以包括n个地址,并且向量数据总线可以包括n个数据总线,则可以有n个并发线程。偏移输入可以是用于n个线程的向量地址。每一个地址偏移(例如,向量地址中的每一个地址)可以独立编程/计算。
274.来自计数器404的第三输入可以为地址计算单元402提供线程号(例如,索引),并且因此,计数器404可被称为线程计数器。在一个实施方案中,地址向量、读取数据向量和写入数据向量可以利用一对一映射简单地分进每个内存组,使得不同线程的数据可以映射到不同的内存组。例如,向量地址中的第i个地址可以用于线程i(小写字母“i”表示线程号,对于第一个线程可以从零开始),并且计数器404可以向地址计算单元402提供线程号向量,使得地址计算单元402可以将n个地址生成为a_0、a_1、
……
、a_n-1,在这个示例中,其对应于alu的向量大小。向量地址中的每个地址可以映射到地址a_i和相应内存组的相应地址输出(例如,a_0耦合到用于内存组0高速缓存304.1的地址端口410.1,a_n-1耦合到用于内存组n-1高速缓存304的地址端口410.n等)。向量写入数据端口wdata 406中的第i个数据线可以映射到wd_i(例如,wd_0耦合到用于内存组0高速缓存304.1的写入数据端口 412.1,wd_n-1耦合用于内存组n-1高速缓存304.n的写入数据端口412.n,等等)。向量读取数据端口rdata 408中的第i个数据线可以映射到rd_i(例如,rd_0耦合到用于内存组0 高速缓存304.1的读取数据端口414.1,rd_n-1耦合用于内存组n-1高速缓存304.n的读取数据端口414.n,等等)。对这个配置来说可能不需要总线开关,并且在这个级上可能没有内存争用。
275.应该注意的是,内存组的数量不需要与向量大小相同。例如,向量(例如,向量alu、向量地址、向量数据端口)可以具有向量大小=v,pe阵列可以具有列数=n,并且内存单元可以具有内存组数=m,并且v、n和m可以全部不同。为了方便起见,大写字母n在本文可以用于表示向量大小、pe的列数和内存组的数量,但是在不同的组件中由n表示的数量可以相等
或不同。
276.对于大于数字n的线程数,地址计算单元402和计数器404可以生成到n个内存组的循环内存映射。例如,线程32可以映射到内存组0高速缓存304.1(例如,在图3b和图3c中 s32(0)映射到内存组302.1),线程63可以映射到内存组n-1高速缓存304.n(例如,在图 3b和图3c中s63(0)映射到内存组302.n)。
277.图4b示意性示出了根据本公开的实施方案的用于mp 400的第二内存访问配置。图4b 中示出的第二内存访问配置可以是用于共享内存访问模式的一个示例配置。在操作期间,mp400可以从序列发生器接收用于物理数据路径的内存端口(mp)配置,并且mp配置可以指定对于该物理数据路径,mp 400可以配置成用于共享内存访问模式。地址计算单元402可以将基地址取为第一输入,并且将偏移量取为第二输入,与图4a中的第一内存访问配置相同。但是计数器404不用于共享内存访问模式,并且可以忽略来自计数器404的输入。共享内存的基地址对所有线程都是公用的,但是偏移在每个线程中可能不同。地址计算单元402可以将n个地址生成为a_0、a_1、
……
、a_n-1,在这个示例中,其对应于alu的向量大小。与图4a中的第一内存访问配置(其中每个地址a_i可以映射到一个内存组)相反,在第二内存访问配置中,来自地址计算单元402的n个地址可以递送到多个地址选择单元(例如,“选择2”单元416.1至416.n)。每个地址选择单元416.1至416.n也可以采用掩码作为输入 (例如“组0”、
……
、和“组n-1”),并且针对特定内存组的地址可以由相应的选择单元仲裁,使得可以选择几个地址。可以选择的地址的上限数量可以取决于设计考虑,例如2、3或更多。并且因为向量地址可以具有固定数量的地址,如果不止一个地址指向一个内存组,则可能有一个或多个内存组没有被地址指向。所选择的地址可以映射到用于内存组高速缓存的内存端口(例如,用于内存组0高速缓存304.1的地址端口426.1,用于内存组n-1高速缓存 304.n的地址端口426.n等)。例如,在一个实施方案中,可以从n个地址中选择多达两个地址并且每个地址端口426.1至426.n可以配置成为相应的内存组递送多达两个内存地址。
278.因为可以为一个内存组选择多个地址,所以可以提供写入数据选择单元(例如,“选择2”单元418.1至418.n)和读取数据选择单元(例如,“选择”单元420.1至420.n)来将多个数据端口从向量数据端口wdata 406和rdata 408映射到一个内存组。写入数据选择单元418.1 至418.n中的每一个可以从相应的数据选择单元416.1至416.n获取输入,并且将来自写入数据线wd_0到wd_n-1中的多个写入数据线映射到用于所选内存组的相应写入数据端口 (例如,用于内存组0高速缓存304.1的写入数据端口422.1,用于内存组n-1高速缓存304.n 的写入数据端口422.n)。读取数据选择单元420.1至420.n中的每一个可以从由相应选择单元418.1至418.n传递的相应数据选择单元416.1至416.n获取输入,并且将来自读取数据线 rd_0到rd_n-1中的多个读取数据线映射到用于所选内存组的相应读取数据端口(例如,用于内存组0高速缓存304.1的读取数据端口424.1,用于内存组n-1高速缓存304.n的读取数据端口422.n)。在可以从n个地址中选择多达两个地址的实施方案中,地址端口426.1至 426.n、写入数据端口422.1至422.n和读取数据端口424.1至424.n的宽度可以是地址端口 410.1到410.n、写入数据端口412.1至412.n和读取数据端口414.n的宽度的两倍。
279.处理器的实施方案可以包括大量的alu并支持大规模并行线程。内存访问可能非常繁忙。使用多端口内存来满足要求可能极其昂贵。如果使用大量的内存组,则复杂性也可
能变得非常高。示例私有内存访问可以降低内存结构的复杂性,并支持用于并行处理的许多典型内存模式。下列给出了一些典型的私有内存访问模式。
[0280][0281][0282]
表1私有内存访问模式
[0283]
在一些实施方案中,私有内存访问可以同时允许来自从所有线程的随机访问数据,但是对于每个线程访问不同的内存区域。这使得程序员能够以传统的风格编写软件,而无需复杂的数据向量化和底层处理器硬件架构的详细知识。这可以使相同指令多线程(simt)编程能够可应用于pe阵列的实施方案。也就是说,一个指令可以由一个pe中的多个线程同时执行。
[0284]
由于不重叠的性质,总吞吐量可能是所有线程的吞吐量之和。私有内存访问模式的实施方案可以支持来自每个线程的同时访问的大吞吐量。第一和第二内存数据映射可以在典型的私有数据访问模式中允许最小的内存争用。私有内存访问的实施方案也可以降低内存系统的复杂性。可以显著减少内存组的数量。并行高速缓存结构还可以减小总的高速缓存大小,因为高速缓存中的每个内容可以是唯一的。而且,私有内存访问的实施方案可以通过允许来自多个内存端口的同时的高速缓存访问来显著减少对内存组的访问。
[0285]
在一个实施方案中,对于具有32x32 alu的pe阵列大小,使用私有内存访问配置可能只需要32个内存组(例如,如图4a所示)。这可以从传统设计用于支持由每个线程使用的不同地址所需的1024个内存组中大大减少内存组数量。
[0286]
不同的内存访问模式可以使用不同的映射方法,图3b和图3c中的映射可以由图4a中示出的内存访问配置的实施方案使用地址生成指令来支持。
[0287]
图3b中的第一内存映射可以很好地处理表1中的案例1、案例2、案例3和案例4。在表1中的案例6中,如果范围在缓存大小内,则也可以很好地处理。图3c中的第二内存映射可以很好地处理表1中的例1、案例2、案例3和案例5。
[0288]
在一些实施方案中,可能发生寄存器溢出。寄存器溢出可能是指这样的场景,即当编译器正生成机器代码时,存在多于机器可能拥有的寄存器数量的活动变量,并且因此一些变量可能会转移或溢出到内存中。用于寄存器溢出的内存可能对每个线程都是私有的,这些溢出的变量可能需要存储在私有内存中。由于用于寄存器溢出的所有地址偏移对于每个线程可能相同,因此其类似于表1的案例5中的非单位步幅模式,溢出的变量可以使用第二内存映射来存储,如图3c所示,并且可能没有内存争用。
[0289]
示例共享内存访问模式也可以降低内存结构的复杂性,并支持用于并行处理的许多典型内存模式。下列给出了一些典型的共享内存访问模式。
[0290]
[0291][0292]
表2共享内存访问模式
[0293]
在一些实施方案中,共享内存访问可以同时允许来自每个并行线程的随机数据访问。所有线程都可以访问内存单元中公用区域中的任何地方。在一个实施方案中,公用区域可以是包括所有内存组的共享内存空间。在另一实施方案中,公用区域可以是跨多个内存组的共享内存空间。这可能使程序员能够以传统风格编写软件,而无需复杂的数据向量化和底层处理器硬件架构的详细知识。这也可以使得simt编程能够可应用于pe阵列的实施方案。
[0294]
共享内存访问的实施方案可以降低内存系统的复杂性。可以显著减少内存组的数量。并行高速缓存结构还可以减小总的高速缓存大小,因为高速缓存中的每个内容可以是唯一的。而且,共享内存访问的实施方案可以通过允许来自多个内存端口的同时的高速缓
514.1和514.2可以耦合到一个pe 218或垫片内存216。数据输入512.1和512.2以及数据输出510.1和510.2可以耦合到另一sb 222(例如,在多行pe阵列中)或一个icsb 224。数据输出506.1、506.2、508.1和508.2可以耦合到一个pe 218。从数据输出506.1、506.2、508.1 和508.2输出的数据信号可以表示为a、b、c、d,并且从数据输入514.1和514.2输入的数据信号可以表示为x、y。这些数据信号a、b、c、d和x、y可以是到一个pe 218的输入数据信号,和来自一个pe 218的输出数据信号,如本文所述。
[0300]
数据输出处的计数器520.1-520.8中的每一个可以独立地负责计数通过的数据。当一个或多个配置可以加载到c-fifo 518中时,每个配置可以指定计数的数量。在一个配置的执行期间,所有计数器可以独立地计数数据已经通过多少次。当所有计数器达到配置中指定的计数数量时,可以应用下一个配置。类似的方法可以应用在icsb 224、pe 218、垫片内存216和内存端口220内部。因为这些计数器可以帮助具有此类计数器的每个组件的配置和重构,所以这些计数器可被称为重构计数器,并且具有这样的计数器的组件可被称为可重构单元。处理器200的实施方案可以使用各种可重构单元提供大规模并行数据处理,并且可被称为可重构并行处理器(reconfigurable parallel processor,rpp)。
[0301]
图6示意性示出了根据本公开的实施方案的处理单元(pe)600。pe 600可以是pe 218 的一个实施方案。pe 600可以包括算术逻辑单元(alu)602、多个数据缓冲器(例如,d-fifo604.1、604.2、604.3和604.4)、计数器606、多个数据输出(例如,608.1和608.2)、多个数据输入(例如,610.1、610.2、610.3和610.4)、配置输入612和配置缓冲器(例如c-fifo) 614)。在一个实施方案中,alu 602可以是一个alu(例如,一个alu配置成一次处理一段数据,并且可被称为标量alu)。在一些其他实施方案中,alu 602可以是alu的向量(或称为向量alu),例如,n个alu(其中n可以称为alu的向量大小),并且相同指令多数据(simd)操作可以应用于向量的所有alu。请注意,标量alu可能是向量大小为1的向量alu的特例。
[0302]
从数据输入610.1、610.2、610.3和610.4接收的数据信号可以表示为a、b、c、d,并且从数据输出608.1和608.2输出的数据信号可以表示为x、y。在alu 602可以是一个alu 的实施方案中,每个数据输入610.1、610.2、610.3或610.4以及每个数据输出608.1或608.2 可以具有m比特宽度(其可以与alu的宽度匹配)。例如,对于8比特的alu,每个输入和输出可以是8比特的;对于16比特的alu,每个输入和输出可以是16比特的;对于32 比特的alu,每个输入和输出可以是32比特的;以此类推。并且每个输入数据信号a、b、 c、d和每个输出信号x、y可以是m比特。在alu 602可以是alu向量的实施方案中,每个数据输入610.1、610.2、610.3或610.4可以是n个m比特输入的向量,并且每个数据输出608.1或608.2可以是n个m比特输出的向量。并且每个输入数据信号a、b、c、d和每个输出数据信号x、y可以是nxm比特。
[0303]
数据缓冲器604.1至604.4可以耦合到输入610.1、610.2、610.3和610.4,以临时存储数据段。然而,在一些实施方案中,数据缓冲器可以定位为输出。d-fifo 604.1至604.4可以用于去耦pe的时序,以允许pe独立地工作。在一个实施方案中,缓冲器可以实施为fifo (例如,用于数据缓冲器的d-fifo,用于配置缓冲器的c-fifo)。
[0304]
配置缓冲器c-fifo 614可以从配置输入612接收配置,该配置输入可以经由配置总线从外部耦合到序列发生器206,并且在数据路径的任何执行开始之前存储接收到的配置。用于 pe 600的配置可被称为pe配置。pe 600可以为一个配置的指令被静态编程,例如,指令可以作为流水线一级编程到pe 600。在一个配置期间,无指令可以改变。一旦进行了配
置,如果d-fifo 610.1、610.2、610.3和610.4具有数据并且输出端口608.1和608.2不忙,则可以触发alu 602(例如,取决于特定实施方案的一个alu或alu的向量)的操作。配置参数中的一个可以指令的指定执行次数。计数器606可以利用指定的次数来编程,并计数已经通过执行指令来处理数据的次数。当执行的数量达到指定数量时,可以应用新的配置。因此,可以在每个pe中提供重构能力。在一个实施方案中,这个指定执行次数可被称为 num_exec,并且这个num_exec可以在用于一个配置的数据路径上使用。
[0305]
在具有多行pe阵列214的一个实施方案中,每列中的pe可以在功能上彼此不同,但是沿着每行的pe遵循重复的模式(例如,功能上是重复的)。例如,第一行pe中的alu可以实施第一组指令,以及第二行pe中的alu可以实施不同于第一组指令的第二组指令。也就是说,在pe 600的不同实施方案中,alu 602可以包括不同的结构或不同的功能性组件。在一些实施方案中,处理器的一行或多行pe可以包括相对简单并且使用较少空间的alu,并且同一处理器的另一行pe可以包括可能相对更复杂并且使用更多空间的alu。相对简单的 alu实施的一组指令可以不同于由相对复杂的alu实施的一组指令。例如,pe 600的一个实施方案可以具有实施一组指令的alu 602(例如,一个alu或alu的向量),这些指令需要相对简单的结构,诸如但不限于加法(例如,a+b)、减法(例如,a-b)等;而pe 600 的另一实施方案可以具有alu 602实施一些指令需要相对更加复杂的结构,诸如但不限于乘法(例如,a乘以b(a*b))、mad(用于乘法-累加(mac)操作)(例如,a*b+c)。
[0306]
图6b示意性示出了根据本公开的另一实施方案的另一处理单元(pe)620。处理单元620 可以是pe 218的一个替代性实施方案。如图6b所示,pe 620可以具有类似于处理单元600 的结构,不同之处在于具有多个指示器“s”622.1至622.4,这些指示器中的每一个可以与一个相应的d-fifo相关联。例如,指示器622.1可以与d-fifo 604.1相关联,指示器622.2可以与d-fifo 604.2相关联,指示器622.3可以与d-fifo 604.3相关联,并且指示器622.4可以与d-fifo 604.4相关联。这些指示器可以用于静态读取配置(也称为静态加载配置)。例如,在一个配置期间,可以根据该配置将指令设置为由pe执行指定次数(例如, num_exec=3)。执行一个指令可以使用来自所有四个d-fifo 604.1到604.4的数据。可以设定指示器622.2,而不设定其他指示器622.1、622.3和622.4。在重复指令的同时,可以重新使用d-fifo 604.2中的数据,但是d-fifo 604.1、604.3和604中的新数据可以用于指令的每一个重复。
[0307]
图7示意性示出了根据本公开的实施方案的列间数据交换盒(icsb)700。icsb 700可以是icsb 224的一个实施方案,并且可以包括多个数据输入和数据输出,以及将数据输出耦合到数据输入以进行数据切换的互连件。icsb 700的数据输入可以包括数据输入704.1、704.2 和710.1至710.4。icsb 700的数据输出可以包括数据输出506.1、506.2、506.1和708.1至 708.4。icsb 700可以进一步包括配置缓冲器702和相应的配置输入712。配置缓冲器702可以实施为先进先出缓冲器,并被称为c-fifo 702。配置输入712可以从外部耦合到配置总线,该配置总线耦合到序列发生器206。另外,icsb 700可以进一步包括多个计数器714.1至714.6,该多个计数器各自对应于数据输出,例如,计数器714.1用于数据输出708.1、计数器714.2 用于数据输出708.2、计数器714.3用于数据输出708.3、计数器714.4用于数据输出708.4、计数器714.5用于数据输出706.1、以及计数器714.6用于数据输出706.2。
[0308]
icsb 700的每个数据输入可以耦合到一些所选择的数据输出。例如,数据输入704.1可以耦合到数据输出708.1至708.4;数据输入704.2可以耦合到数据输出708.1至708.4;数据输入710.1可以耦合到数据输出706.1至706.2、以及708.1;数据输入710.2.2可以耦合到数据输出706.1至706.2、以及708.2;数据输入710.3可以耦合到数据输出706.1至706.2、以及708.3;以及数据输入710.4可以耦合到数据输出706.1至706.2、以及708.4。
[0309]
在外部,数据输入704.1和704.2以及数据输出706.1和706.2可以耦合到sb 222。数据输入710.1至710.4可以耦合到相邻的icsb 224或垫片内存216。数据输出708.1至708.4可以耦合到另一相邻的icsb 224或垫片内存216。
[0310]
数据输出处的计数器714.1-714.6中的每一个可以独立地负责计数通过的数据。当一个或多个配置可以加载到c-fifo 702中时,每个配置可以指定计数的数量。用于icsb 700的配置可以称为icsb配置。在pe阵列214的一个配置的执行期间,所有计数器可以独立地计数数据已经通过多少次。当所有计数器达到配置中指定的计数数量时,可以应用下一个配置。这种实施方式可以类似于可以应用在sb 222、pe 218、垫片内存216和内存端口220内部的实施方式。
[0311]
图8示意性示出了根据本公开的实施方案的垫片内存800。垫片内存800可以是图2中示出的垫片内存216的一个实施方案。垫片内存800可以包括用于临时存储数据的多个数据缓冲器。数据缓冲器可以实施为先进先出(fifo)缓冲器,并且被称为d-fifo(例如,d-fifo802.1至802.f,f是等于或大于8的整数)。此外,垫片内存800可以包括多个数据输入(例如,814.1至814.2、816.1至816.2和818.1至818.4)、多个数据输出(例如,808.1至808.2、 810.1至810.2和812.1至812.4)、输入配置缓冲器(例如,输入c-fifo 804)、输出配置缓冲器(例如,输出c-fifo 806)、配置输入816、多个输入计数器820.1至820.l(l是等于或大于4的整数)、以及多个输出计数器822.1至822.4。
[0312]
来自mp 220.n、pe 218.n和icsb 224.n的外部连接可以分别作为数据输入814.1至 814.2、816.1至816.2和818.1至818.4处的输入。并且到mp 220.1、sb 222.1和icsb 224.1 的外部连接可以分别在数据输出808.1至808.2、810.1至810.2和812.1至814.4处产生输出。配置输入816可以经由用于垫片内存800的配置总线从外部耦合到序列发生器206,以从序列发生器206接收配置。用于垫片内存800的配置可被称为垫片内存配置。可以从序列发生器206接收两种类型的配置:输入配置和输出配置。输入c-fifo 804可以存储输入配置用于将输入icsb端口818.1至818.4耦合到从l个d-fifo 802.5至802.f中选择的一些数据fifo 的,作为这些选择的d-fifo的输入。输出c-fifo 806可以存储配置用于从l个d-fifo 802.5 至802.f中选择一些数据fifo耦合到icsb端口812.1至812.4的。
[0313]
存储icsb输入的垫片式d-fifo 802.5到802.f的数量可能大于或等于输入或输出icsb 端口的数量。在一些实施方案中,如本文所述,可以存在一个数据连接可以绕过物理数据路径的至少一部分。例如,在相同的物理数据路径配置中,由一个pe 218生成的执行结果对于另一pe 218而言可能是不需要的,但是可以在未来的配置中使用。执行结果的这些数据信号可以经由sb 222和icsb 224路由到垫片内存216,并存储在垫片内存216的d-fifo中,用于未来的配置。因此,在一些实施方案中,垫片内存800可以具有比输入或输出端口的数量更多的d-fifo。
[0314]
数据输入处的输入计数器820.1至820.l中的每一个和数据输出处的输出计数器
822.1至 822.4中的每一个可以独立地负责对通过的数据进行计数。当一个或多个输入配置和输出配置可以加载到输入c-fifo 804和输出c-fifo 806中时,每个配置可以指定计数的数量。在一个配置的执行期间,所有计数器可以独立地计数数据已经通过多少次。当所有计数器达到配置中指定的计数数量时,可以应用下一个配置。
[0315]
图9a示意性示出了根据本公开的实施方案的执行内核900的示例依赖图。在一个实施方案中,可以在一个回路(例如,一个例程或一个子例程)中运行的指令序列可被称为一个执行内核或简单地称为内核。群组中的指令可能有一些依赖性。例如,内核900可以具有在依赖图中表示为a到k的指令。指令a可以是内核900的依赖图中的第一条指令。指令b 和指令c可能需要指令a的输出。指令d和指令k两者可能需要指令b的输出。指令d也可能需要指令c的输出。指令e和指令f两者可能都需要指令d的输出。指令g、指令h 和指令i可能需要指令f的输出。除了指令f的输出之外,指令g还可能需要指令e的输出。指令j可能分别需要指令g、指令h和指令i的输出。并且最后,指令k可能需要指令b和指令i的输出。根据本公开的实施方案,内核900的依赖图可以映射到要由一个处理器执行的数据路径。
[0316]
图9b示意性示出了根据本公开的实施方案的映射到处理器的虚拟数据路径(virtual datapath,vdp)中的图9a的执行内核900的依赖图。在一些实施方案中,内核的依赖图到处理器的映射可能受到多个因素的限制,例如,pe阵列的大小、pe之间的连接、内存访问能力等。应当注意的是,图2中的处理器200示意性地示出了具有一行pe的处理器的一个实施方案,但是在图9b所示的实施方案中,内核900的虚拟数据路径可以映射到具有两(“2”) 行pe的处理器。一般而言,根据本公开内容的实施方案的处理器可以利用1-d或2-d数据路径(包括处理单元(pe)阵列和互连件)来处理大规模并行数据。每个数据路径可以分割成多个区段。在1-d数据路径中,区段可以在一列中包括内存端口、数据交换盒、pe和icsb;在2-d数据路径中,区段可以在一列中包括内存端口、两个或更多个数据交换盒、两个或更多个pe以及icsb。可以使数据路径在每个区段中相同。这允许内核的依赖图映射到虚拟数据路径中,该虚拟数据路径在一维上可以包括数据路径区段的任意需要数量的重复(例如,不受限的或者甚至理论上无限的)。例如,内核的指令可以映射到pe的列,并在行方向上重复地扩展(例如,如果需要的话,从行的开头循环回来)。
[0317]
图9c示意性地示出了根据本公开的实施方案的划分为处理器的物理数据路径的图9b的虚拟数据路径。在一个实施方案中,为了简化编译器工作,可以使物理数据路径(pdp)具有重复的结构。例如,每个列可以是相同的,并且每个pdp可以包括相同量的重复列。如图 9c所示,对于2x2 pe阵列,图9b的vdp可以分成三个pdp(例如,pdpl、pdp2和pdp3),并且因此这三个pdp可以具有相同的结构。2x2 pe阵列可以是rpp的实施方案的整个pe阵列,或者可以是rpp的另一实施方案的nxn(例如,作为示例n为32)pe阵列的一部分。一个pdp中的pe之间(例如,从a到b和c、从b到d、从c到d等)、两个连续的pdp 之间(例如,从d到e和f、从g到j、从h到j、从f到i等)和不连续的pdp之间(例如,从b到k)可能存在许多连接。在一个pdp中,pe阵列中的所有pe可以应用用于当前 pdp的配置,并且来自一个指令的数据可以根据依赖性直接流到另一指令。例如,pe可以配置成在pdpl中执行指令a,并且来自这个pe的数据可以直接从这个pe流到配置成执行指令b和c的pe。在pdp之间,来自一个pdp的数据可以流入垫片内存以便于临时存储。数据也可以从垫片内存流出,作为对新配置中的下一物理数据路径的输入。例如,在一个配置中,pe可以配置成在pdpl中执行指令b,并且来自这个
pe的数据可以存储到垫片内存,并用作配置成在未来配置中在pdp3中执行指令k的pe的输入。
[0318]
图10示意性示出了根据本公开的实施方案的用于处理器的一个流水线操作。图10中示出的流水线操作的示例可以是图9c的映射到四个pe(pe0、pe1、pe2和pe3)的2x2 pe 阵列的物理数据路径。虚拟数据路径的a、b、c、
……
、k的指令可以被分割成多个pdp: pdp1、pdp2和pdp3,如图9c所示。pe0可以配置成在pdpl中执行指令a、在pdp2中执行指令e和在pdp3中执行指令i。pe1可以配置成在pdpl中执行指令b、在pdp2中执行指令f和在pdp3中执行指令j。pe2可以配置成在pdpl中执行指令c、在pdp2中执行指令g和在pdp3中执行指令k。pe3可以配置成在pdp1中执行指令d、在pdp2中执行指令 h以及在pdp3中不执行指令。
[0319]
在操作期间,一个pe中的所有并发线程可以执行相同的指令,并且每个指令可以在一个pe中作为一个流水线级执行多次。也就是说,每个pe可以配置成作为一个流水线级执行指令num_exec次。例如,在每个pe包括向量大小为1的alu向量的一个实施方案中,每个指令可以配置成在每个pe处由alu向量执行4次。4次执行可以由4个线程表示,该四个线程以每个线程处于不同的阴影进行处理。例如,在pdpl中,pe0可以配置成执行指令 a四次,pe1可以配置成执行指令b四次,pe2可以配置成执行指令c四次,并且pe3可以配置成执行指令d四次。在pdp2中,pe0可以配置成执行指令e四次,pe1可以配置成执行指令f四次,pe2可以配置成执行指令g四次,并且pe3可以配置成执行指令h四次。在 pdp3中,pe0可以配置成执行指令i四次,pe1可以配置成执行指令j四次,pe2可以配置成执行指令k四次,并且pe3可以没有配置指令。在这个实施方案中,因为不同指令之间可能存在数据依赖性,所以执行取决于另一指令的指令的线程可以在时间上稍后执行。例如,指令b可以取决于来自指令a的执行结果的数据,并且因此,执行指令b的第一线程可以在执行指令a的第一线程之后的一个周期中跟随执行,执行指令b的第二线程可以在执行指令 a的第二线程之后的一个周期中跟随执行,执行指令b的第三线程可以在执行指令a的第三线程之后的一个周期中跟随执行,并且执行指令b的第四线程可以在执行指令a的第四线程之后的一个周期中跟随执行。由于静态重构方案和指令的依赖性,在dpd重构期间可能会有一些时间损失,例如,在pdpl到pdp2转换期间,pe2可能有一个空闲周期。在每个pe具有向量大小n大于1的向量alu的实施方案中,每个pe可以一次执行n个并发线程,并且图10中的每个阴影线程可以表示n个并发线程。
[0320]
在各种实施方案中,垫片内存可以提供在重构期间降低效率损失的方法。例如,即使在重构(例如,在pdp1的指令c和pdp2的指令g之间的pe2的重构)期间可能有一些空闲时隙,如果使用更大数量的线程,则与总的繁忙周期相比,空闲时隙可能是不重要的。
[0321]
图11a至图11i示意性示出了根据本公开的实施方案的处理器的一个配置过程。配置过程可示出数据路径(dp)配置和重构。序列发生器单元(seq)1102可以是序列发生器206 的一个实施方案,并且可以负责为每个pe(例如,pe_0 1104、pe_1 1106和pe_2 1108)和数据交换盒(sb)(例如,sb_1 1110、sb_2 1112、icsb_1 1114和icsb_2 1116)调度指令/ 配置。pe 1104、1106和1108中的每一个都可以是pe 218的实施方案。sb 1110和1112中的每一个都可以是sb 222的实施方案。icsb 1114和1116中的每一个都可以是icsb 224的实施方案。图11a的pe和sb(包括sb和icsb)中的每一个都可以经由配置总线(示出为从 seq 1102开始的点划线)耦合到seq 1102。在这个示例中,执行内核的虚拟数据路径(vdp) 可以映射
为两个物理数据路径(pdp)。应当注意的是,这个示例内核可以不同于图9a至图 9c和图10所示的数据路径示例。pe可以表示为数字前面具有下划线(诸如图11a至图11i 中的pe_0、pe_1和pe_2),以区别图10中的示例pe0、pe1、pe2和pe3。
[0322]
在图11a至图11i中的示例配置过程中,第一pdp(例如,其可被称为在数字前面具有下划线的pdp_1,以区别于图9c的数据路径示例)可以使用数据路由pe_0
→
pe_1、 pe_1
→
pe_2,并且第二pdp(例如,其可被称为pdp_2以区别于图9c的数据路径示例) 可以使用不同的路由pe_0
→
pe_1、(pe_0,pe_1)
→
pe_2。也就是说,在第一个pdp中, pe_1可以依赖pe_0的输出用于其操作,pe_2可以依赖pe_l的输出用于其操作;在第二个 pdp中,pe_1可以依赖pe_0的输出用于其操作,pe_2可以依赖pe_1的输出和pe_1的输出两者用于其操作。
[0323]
图11a示出了最初整个dp还没有经过配置。所有pe可能处于默认状态。在一个实施方案中,这个默认状态可以由称为stall的默认操作指令来实施。虽然pe可以被编程为 stall,但是其各自的输入数据fifo可以是空的并且准备好接收数据。然而,忙信号可以被设置为0。因此,所有sb都可能停止(stalled),并且可以没有信号路由。例如,组件之间的所有数据连接可以点划线示出,以指示没有数据可以通过(例如,pe_0 1104和sb_1110 之间、sb_1 1110和icsb_1 1114之间、sb_1 1110和pe_1 1106之间、pe_1 1106和sb_2 1112 之间、sb_2 1112和icsb_2 1116之间以及sb_2 1112和pe_2 1108之间的数据连接)。
[0324]
图11b示出了seq 1102可以开始将第一指令ins1加载到pe_0 1104中,但是sb_1 1110 和icsb_1 1114仍然可能停止。例如,从seq 1102到pe_0 1104的配置连接可以是断开的,并示出为虚线,相反,其他配置连接可以是闭合的,并以点划线示出。因为inst1可以是该执行内核中的第一条指令,并且不依赖于任何其他条件,所以pe_0 1104可以准备好生成输出,但是被来自sb_1 1110的输出忙信号阻塞。在这一步,没有数据可以通过组件之间的任何数据连接,并且数据连接可以以点划线示出。
[0325]
如图11c所示,在这一步,seq 1102可能已经对sb_1 1110和icsb_1 1114两者进行了编程,并且可以断开来自pe_0
→
pe_1的数据路由。例如,从seq 1102到sb_1 1110和icsb_11114的配置连接可以是断开的,并示出为虚线,相反,其他配置连接可以是闭合的,并以点划线示出。pe_0 1104可以生成输出,并且这些输出可以经由sb_1 1110(例如,sb_1 1110 内部的点划线以示出内部连接断开)路由到pe_1 1106。pe_1 1106可以接收来自pe_0 1104 的输出,并且即使当pe_1 1106还没有经过配置时,也可以将这些数据信号存储在其数据缓冲器(例如,d-fifo)中。pe_0 1104和sb_1 1110之间以及sb_1 1110和pe_1 1106之间的数据连接可以以实线示出,以指示数据可以通过。双线箭头1118可以示出这个数据流。
[0326]
因为在第一个pdp中,来自pe_0 1104的输出可能仅pe_1 1106需要,因此此时没有数据需要通过icsb_1 1114。因此,尽管icsb_1 1114的配置可能已经被编程(例如,其内部连接以虚线示出),但是没有数据到达icsb_1 1114(例如,其以虚线连接到sb_1 1110)并且 icsb_1 1114可能保持静止。
[0327]
在图11d所示的一步中,从seq 1102到pe_1 1106的配置连接可以是断开的,并示出为虚线。相反,其他配置连接可以是闭合的,并以点划线示出。seq 1102现在可以将第二指令ins2配置到pe_1 1106,并且pe_1 1106可以准备好执行和生成输出,但是被来自sb_2 1112 的输出忙信号阻塞。同时,从pe_0 1104产生的数据可以连续地发送到pe_1 1106的d-fifo。在这一步,组件之间的所有数据连接可以与图11c中相同。
[0328]
在图11e中,在这一步,从seq 1102到sb_2 1112和icsb 1116的配置连接可以是断开的,并示出为虚线。相反,其他配置连接可以是闭合的,并以点划线示出。当sb_2 1112可以被配置和断开时,pe_1 1106可以开始执行ins2并生成输出。这些输出可以经由sb_2 1112 (例如,sb_2 1112内部的点划线以示出内部连接断开)路由到pe_2 1108。pe_2 1108可以接收来自pe_1 1106的输出,并且即使当pe_2 1108还没有经过配置时,也可以将这些数据信号存储在其数据缓冲器(例如,d-fifo)中。pe_1 1106和sb_2 1112之间以及sb_2 1112 和pe_2 1108之间的数据连接可以以实线示出,以指示数据可以通过。双线箭头1120可以示出这个数据流。
[0329]
因为在第一个pdp中,对pe_2 1108的输入可能仅来自pe_1 1106,因此此时没有数据需要通过icsb_2 1116。因此,尽管icsb_1 1116的配置可能已经被编程(例如,其内部连接以虚线示出),但是没有数据通过icsb_2 1116(例如,其以虚线连接到sb_2 1112)并且icsb_21116可能保持静止。
[0330]
在图11f所示的一步中,从seq 1102到pe_2 1108的配置连接可以是断开的,并示出为虚线。相反,其他配置连接可以是闭合的,并以点划线示出。并且第一pdp的最后指令ins3 可以被编程到pe_2 1108。虽然未示出,但是在这一步,到垫片内存(例如,垫片内存216 的实施方案)的配置连接也可以断开,并且垫片内存的数据连接也可以被编程。现在pe_2 1108 可以执行ins3,并且结果可以存储到垫片内存中。在一个实施方案中,到目前为止,整个 pdp_1配置可以完成,并且每个pe(例如,pe_0 1104、pe_1 1106和pe_2 1108)可以独立地执行相应指令指定次数(例如,num_exec)。每个sb(例如,sb_1 1110和sb_2 1112) 和每个icsb(例如,icsb_1 1114和icsb_2 1116)也可以为pdp_1执行其各自的配置指定次数(例如,num_exec)。
[0331]
在一些实施方案中,用于vdp的pdp的配置(例如,执行内核的依赖图的)可以被独立地发送到组件,同时每个组件可以根据当前配置操作。例如,在pe(例如,pe_0 1104、 pe_1 1106和pe_2 1108)、sb(例如,sb_1 1110和sb_2 1112)和icsb(例如,icsb_1 1114 和icsb_2 1116)可以在其用于pdp_1的相应第一配置下操作的同时,可以从seq 1102接收相同vdp的其他pdp用于这些组件中的每一个的后续配置。在一个实施方案中,可以经由配置总线从序列发生器206批量发送用于一个组件的多个配置,只要发送用于一个组件的多个配置不会减慢或阻碍任何其他组件的操作。
[0332]
因此,虽然在执行pdp_1,但组件可能已经接收到用于pdp_2的所有配置。如图11g所示,在这个一步,直到pe_0 1104上的所有线程(例如,alu向量602中的所有alu)已经完成pdp_1时,pe_0 1104可以重构到第四指令ins4。例如,pe_0 1104可以通过应用已经在其配置缓冲器c-fifo 614中的pdp 2配置来自行重构。类似地,一旦来自ins1的最后数据已经通过sb_1 1114,sb_1 1114也可以重构。由于sb_1 1110上的新pdp_2配置,来自ins4 的第一输出数据可以递送到icsb_1 1114(例如,连接到icsb_1 1114的新虚线)。然而,到 icsb_1 1114的数据信号可能被来自icsb_2 1116的忙信号阻塞,因为icsb_2 1116可能还没有重构。
[0333]
在图11h所示的一步,pe_1 1106、sb_2 1112、icsb_2 1116在pdp 1中可能已经达到指定的执行次数,并且可以重构。例如,pe_1 1106可以重构到第五指令ins5,并且sb_2 1112 和icsb_2 1116也可以重构为使得来自pe_0 1104的数据也可以经由icsb_1 1114到
达pe_21108的d-fifo。sb_2 1112内部的新虚线可以示出为经由sb_2 1112将icsb_2 1116连接到 pe_2 1108。从pe_0 1104到pe_2 1108的数据流可以由双线箭头1122(例如,从pe_0 1104 到icsb_1 1114)和1124(例如,从icsb_1 1114到pe_2 1108)示出。
[0334]
在图11i所示的级,最终,pe_2 1108可以达到用于pdp_1的指定的执行次数,并且可以重构到用于pdp_2的最后指令ins6。整个pdp_2配置可以应用于数据路径组件。用于 pdp_2配置的组件可以各自针对pdp_2配置运行指定次数,以完成整个执行内核。
[0335]
图12a示意性示出了根据本公开的实施方案的用于使用处理器执行指令流的流水线操作。在共享内存访问模式中,可以由执行相同指令的所有线程访问同一个内存地址。为了从相同的地址为所有线程加载数据,流水线可以继续为所有这些线程提取相同的数据,并在内存单元中产生不必要的流量。这个示例中的指令可以表示为数字前面具有下划线,以区别图 11a至图11i中示出的示例指令。在图12a中示出的示例流水线式指令执行中,指令ins_0 可以是数据加载指令“加载x[j]”,并且内存端口可以配置成作为流水线级1202执行ins_0三次(例如,对于配置成执行加载指令的内存端口,num_exec为3)。数据段x[j]可以是所有线程公用的,并且从相同的地址加载。例如,数据段x[j]可以是向量x中的第j个数据段,并且这个第j个数据段可以由所有线程使用。在一个pe中具有n个alu的实施方案中,可以存在由一个块(例如,一个线程块)表示的n个并发线程,并且流水线级1202可以配置成执行ins_0 3xn次。
[0336]
指令ins_1可以是数据加载指令“加载a[k][j]”,并且内存端口可以配置成作为流水线级 1204执行ins_1三次。要由ins_1加载的数据段对于不同的线程可能是不同的,并且对于不同的线程,可以从不同的地址加载。例如,a[k][j]可以是第k个线程的第j个数据段,其中对于第一个线程块中的每个线程,k可以是0到n-1(包括端点)之间的整数,对于第二个线程块中的每个线程,k可以是n到2n-1(包括端点)之间的整数,对于第三个线程块中的每个线程,k可以是2n到3n-1(包括端点)之间的整数。
[0337]
在一个实施方案中,如果内存端口配置成并行执行两个数据加载指令,则流水线级1202 和1204可以在同一内存端口处执行。例如,在图2中示出了mp 220中的每一个和内存单元 212之间的两个并行读取数据线和两个并行写入数据线。而且,数据交换盒500示出了并行输入数据线如何切换到pe(例如,502.1和502.2切换到506.1、506.2、508.1或508.2)。在另一实施方案中,流水线级1202和1204可以在两个不同的内存端口处执行。
[0338]
指令ins_2可以是乘法指令“y=a[k][j]*x[j]”,其中数据段x[j]由ins_0加载,并且a[k][j] 由ins_1加载,并且pe可以配置成作为流水线级1206执行ins_2三次(例如,num_exec 为3,其中对于所有线程来说为总共3xn次)。因此,每个pe或mp可以配置成作为流水线级执行num_exec个指令量。
[0339]
指令ins_4可以是数据加载指令“加载x[j+l]”,并且内存端口可以配置成作为流水线级 1208执行ins_4三次。数据段x[j+l]可以是所有线程公用的,并且从相同的地址加载。例如,数据段x[j+l]可以是向量x中的第j+l个数据段,并且这个第j+l个数据段可以由所有线程使用。指令ins_5可以是数据加载指令“加载a[k][j+l]”,并且内存端口可以配置成作为流水线级1210执行ins_5三次。要由ins_5加载的数据段对于不同的线程可能是不同的,并且对于不同的线程,可以从不同的地址加载。例如,a[k][j+l]可以是第k个线程的第j+l个数据段,其中对于第一个线程块中的每个线程,k可以是0到n-1(包括端点)之间的整
数,对于第二个线程块中的每个线程,k可以是n到2n-1(包括端点)之间的整数,对于第三个线程块中的每个线程,k可以是2n到3n-1(包括端点)之间的整数。在一个实施方案中,如果内存端口配置成并行执行两个数据加载指令,则流水线级1208和1210可以在同一内存端口处执行。在另一实施方案中,流水线级1208和1210可以在两个不同的内存端口处执行。
[0340]
指令ins_6可以是乘法指令“y=a[k][j+l]*x[j+l]”,其中数据段x[j+l]由ins_4加载,并且 a[k][j+l]由ins_5加载,并且pe可以配置成作为流水线级1212执行ins_6三次。
[0341]
在图12a的示例流水线式指令执行中,ins_0和ins_4可以重复,尽管许多重复的内存读取可能不是必需的。图12b示意性示出了根据本公开的实施方案的用于使用处理器执行指令流的精简流水线操作。在一个实施方案中,编译器或其他方法(例如,序列发生器)可以识别图12a中的指令序列中的静态读取,并且重复操作可以减少到一次。例如,静态加载指令 (例如ins_0和ins_4)可以利用num_exec=1编程(例如,这可以应用于将执行数据提取的mp)。如图12b所示,流水线级1202a和1208a可以分别是一个块。在一个实施方案中,指示器s可以在与pe的或mp的d-fifo相邻的pe和mp中实施(例如,pe 620中的指示器622),并且对于从静态负载接收数据的任何pe和mp,可以设置与从静态负载接收数据的、 pe的或mp的d-fifo相邻的指示器s。例如,配置成在流水线级1206处执行ins_2的pe 可以包括分别从配置成用于流水线级1202a的(多个)mp和mp 1204接收数据的d-fifo,并且可以将指示器s设置与从流水线级1202a接收数据的d-fifo相邻。类似地,配置成在流水线级1212处执行ins_6的pe可以包括从分别配置成用于流水线级1208a和1210的(多个)mp接收数据的d-fifo,并且可以将指示器s设置与从流水线级1208a接收数据的d-fifo 相邻。在num_exec=1的情况下,流水线级1202a和1208a中的数据加载操作对于该配置可以仅执行一次。给定静态指示s的情况下,配置成执行流水线级1206和1212的pe可以执行其操作三次(例如,其num_exec仍然等于3),但是来自具有指示s的d-fifo的数据可以被重新使用num_exec次。
[0342]
在一些实施方案中,精简流水线级的这种操作模式可以推广到其他指令。在一个实施方案中,对于可以为不同线程生成相同结果的指令,可以使用相同的方法来降低功耗。例如,来自一个pe的结果可以用作同一物理数据路径中的另一pe中的不同线程的输入,或者来自一个物理数据路径的pe的结果可以用作另一物理数据路径中的一个pe中的不同线程的输入,该结果可以仅加载一次,其中指示s设置为相应的d-fifo并被重新使用。
[0343]
参照图13,根据本公开的实施方案示意了用于执行执行内核的方法1300的一个流程图。在框1302处,一个执行内核可以在一个处理器处被映射到虚拟数据路径中。例如,如图9b 所示,可以由示例处理器200将执行内核映射到虚拟数据路径中。执行内核可以包括要由处理器执行的指令序列。在一个实施方案中,处理器可以包括各种可重构单元,该各种可重构单元包括垫片内存。而且,在一个实施方案中,该过程可以包括形成重复列的各种可重构单元。在框1304处,虚拟数据路径可以分割为一个或多个物理数据路径。例如,如图9c所示,虚拟数据路径可以分割为三个物理数据路径。在一个实施方案中,各种可重构单元可以形成用于执行指令序列的一个或多个物理数据路径。而且,在一个实施方案中,一个或多个物理数据路径中的每一个可以分别适配到重复列中。例如,第一物理数据路径和第二物理数据路径可以分别适配到重复列中。在框1306处,配置可以递送到处理器的各种可重构单元。各种可重构单元可以根据配置形成用于执行指令序列的一个或多个物理数据路径。在框1308处,执行处理器以通过根据配置操作各种可重构单元来完成一个或多个物理数据
路径。在一个实施方案中,来自一个物理数据路径的数据可以路由到垫片内存,以在一个未来的物理数据路径中用作输入。
[0344]
参考图14,根据本公开的实施方案示意了用于重构一个处理器的方法1400的流程图。在框1402处,可以将多个配置递送到处理器的多个可重构单元。多个配置可以用于多个可重构单元以形成用于执行指令序列的多个物理数据路径。在一个实施方案中,多个配置中的每一个可以包括一个指定次数(例如,本文描述的num_exec数量)。在框1404处,可以在多个可重构单元中的每一个处重复相应的操作指定次数。例如,多个可重构单元可以包括第一可重构处理单元(pe),并且第一可重构pe可以在多个物理数据路径的第一物理数据路径中执行指令序列中的第一指令指定次数。在框1406处,每个可重构单元可以重构成新的配置。在一个实施方案中,在每个可重构单元已经重复其相应的操作指定次数之后,每个可重构单元可以重构。例如,第一可重构pe可以重构为在多个物理数据路径中的第二物理数据路径中根据第二配置,执行指令序列中的第二指令指定次数。
[0345]
参考图15,根据本公开的实施方案示意了用于重构一个处理器的方法1500的流程图。在框1502处,可以在处理器的可重构单元处接收第一配置和第二配置。例如,图11a至图 11i中的pe_0 1104可以接收第一配置和第二配置,第一配置可以包括第一指令ins1,第二配置可以包括第四指令ins4。pe_0 1104可以将这些配置存储在其配置缓冲器(例如,c-fifo614)中。在框1504处,第一操作可以根据第一配置被执行第一次数。例如,pe_0 1104可以根据第一配置中的num_exec执行指令ins1多次。第一配置可以是用于执行指令序列的第一部分的第一物理数据路径(例如,pdp_1)的部分。在框1506处,可重构单元可以重构为根据第二配置执行第二操作第二次数。例如,可以通过应用第二配置来重构pe_0 1104使其根据第二配置中的num_exec执行指令ins4多次。第二配置可以是用于执行指令序列的第二部分的第二物理数据路径(例如,pdp_2)的部分。
[0346]
参考图16,根据本公开的实施方案示意了用于重构处理器的方法1600的流程图。在框 1602处,第一指令可以在一个可重构的处理单元处被执行多次。该执行可以根据作为第一物理数据路径的部分的第一配置来执行。例如,pe_2可以配置成根据作为pdp_1的部分的配置来执行num_exec次ins3。在框1604处,来自可重构单元的执行结果可以递送到垫片内存。例如,来自pe_2的执行ins3的执行结果可以递送到垫片内存。在一个实施方案中,如果第一指令要在可重构单元处执行多次,则执行结果可以在第一指令的每次执行之后递送到垫片内存。例如,垫片内存可能已经将连续执行结果存储在其数据缓冲器中的一个(例如, d-fifo 802.3至802.f中的一个)中。在框1606处,存储在垫片内存中的执行结果可以从垫片内存馈送到第二物理数据路径。例如,来自执行指令ins3的pe_2的执行结果可以用作要在第二物理数据路径中由一个pe执行的一个指令的输入。存储在垫片内存中的执行结果可以从垫片内存递送到这个pe,用于执行第二物理数据路径。
[0347]
参考图17,根据本公开的实施方案示意了用于访问内存的方法1700的流程图。在框1702 处,用于内存单元的多个内存地址可以由内存端口中的地址计算单元为多个并行线程生成。例如,内存端口可以为处理单元(pe)提供对内存单元的内存访问,该处理单元可以具有多个算术逻辑单元(alu),这些算术逻辑单元配置成以并行线程执行相同的指令。在一个实施方案中,内存端口可以是为多个处理单元(pe)提供对内存单元的访问的多个内存端口中的一个。多个pe中的每一个可以具有多个算术逻辑单元(alu),这些算术逻辑单元配
置成在并行线程中执行相同的指令。在框1704处,可以访问内存单元中的多个内存组,其中每个线程访问不同的内存组。在一个实施方案中,在私有内存访问模式下,每个线程可以访问不同的内存组以获得其数据。
[0348]
参考图18,根据本公开的实施方案示意了用于访问内存的方法1800的流程图。在框1802 处,用于内存单元的多个内存地址可以由内存端口中的地址计算单元为多个并行线程生成。内存端口可以为具有多个算术逻辑单元(alu)的处理单元提供内存访问,这些算术逻辑单元配置成在并行线程中执行相同的指令。在一个实施方案中,内存端口可以是多个内存端口中的一个,这些内存端口为多个处理单元(pe)提供对内存单元的访问,该多个处理单元各自具有多个算术逻辑单元(alu),这些算术逻辑单元配置成在并行线程中执行相同的指令。在框1804处,可以访问内存单元中的多个内存组,其中所有线程访问内存单元中的一个公用区域。在一个实施方案中,在共享内存访问模式下,由pe并行执行的每一个线程可以访问公用区域中的任何地方。也就是说,公用区域可以是所有线程的共享内存空间。
[0349]
参考图19,根据本公开的实施方案示意了用于重新使用一段数据的方法1900的流程图。在框1902处,可以确定在pe的一个配置期间,一段数据将在处理器的处理单元(pe)处由所有线程共享和重复使用。例如,在一个实施方案中,共享内存访问模式可以在pe的一个配置期间被应用。一段数据(例如常数)可以是所有线程公用的,并且可以由所有线程共享和重复使用。在框1904处,可以将该段数据加载一次到pe的数据缓冲器中。在一个实施方案中,因为该段数据可以被共享和重复使用。数据加载操作可能只需要执行一次。在框1906 处,可以设置与数据缓冲器相关联的指示器,以指示该段数据将被重复使用。在一个实施方案中,pe内部的数据缓冲器可以具有指示器比特“s”,并且如果数据缓冲器中的一段数据应该被重复使用,则可以设置这个指示器“s”。在框1908处,可以通过重复使用该数据段作为输入,来执行相同的指令多次。在一个实施方案中,pe可以根据由配置指定的数量(例如, num_exec)作为流水线级重复地执行相同的指令。
[0350]
本公开内容提供了可重构并行处理的装置、系统和方法。例如,rpp的实施方案可以利用由处理单元(pe)阵列和互连件组成的1-d或2-d数据路径来处理大规模并行数据。可以使数据路径在每个区段(例如,(多个)pe的一个列、mp和数据路由单元)中相同,这可以允许内核的依赖图映射到虚拟数据路径,该虚拟数据路径在一维上可以是数据路径区段的无限重复。
[0351]
rpp的实施方案还可以在虚拟数据路径被分割成物理数据路径的分割点利用垫片内存来临时存储数据路径的数据输出,。垫片内存可以像数据缓冲器(例如fifo)一样起作用,以将数据反馈到下一配置的物理数据路径中。
[0352]
rpp的实施方案还可以具有一维内存单元,其中内存端口(mp)连接到每一列数据路径。在整个虚拟数据路径上访问的所有数据可以存储在内存单元中。每次,对于新的配置,mp 可以重构为以不同的方式访问内存单元,而数据可以保持不变。rpp的实施方案可以将对私有内存访问和共享内存访问的内存访问类型分开。私有内存访问可以专用于特定线程,同时不同线程之间不允许重叠访问。共享内存访问可以允许所有线程访问公用区域。而不是为共享和私有类型定义不同的内存。rpp的实施方案可以将数据存储到相同的内存空间中,但是提供不同的访问方法。这消除了从私有内存到共享内存的不必要的数据移动,反之亦然。
[0353]
可以优化rpp的实施方案以允许用于多线程处理的大规模并行性。在一个示例中,在具有一行32个pe且每个pe具有32个算术和逻辑单元(alu)的情况下,1024个alu可以包括在一个rpp内核中。在一些实施方案中,多核处理器可以包括多个rpp。
[0354]
rpp的实施方案可以根据重构机制来重构。包括一个或多个重构计数器的rpp的各种组件可被称为可重构单元。例如,pe(例如pe 218)、数据切换单元(例如sb 222和icsb 224) 和内存单元(例如mp 220、垫片内存216)中的每一个可以包括一个或多个重构计数器,诸如pe中的计数器606、sb中的计数器520、icsb中的计数器714、垫片内存中的计数器820 和822以及mp中的类似计数器(图4a或图4b中未示出)。当线程之间可能没有依赖性时,数据处理可以是流水线式的。相同的指令可以被执行多次,直到所有线程(例如,用于一个物理数据路径的四个线程块)均得到处理。当可重构单元中的计数器达到编程的数量并且可重构单元可以将其配置替换为新的环境时。这种重构可以在每个pe、数据切换单元和内存访问单元中以相同的方式完成。可以用最小的切换空闲时间来实现自重新配置。
[0355]
示例性重构机制可以减少在配置上花费的功率,因为配置仅在所有线程都已经被处理之后被切换一次。这也可以通过在最早时间独立地切换每个pe来减少配置之间的空闲时间。通过这样做,也可以减少存储中间数据所需的内存。
[0356]
在一些实施方案中,在共享内存访问模式下,所有线程可以使用相同的地址加载数据。由于操作的流水线式性质,可能只需要执行所有线程的第一个数据加载指令。所加载的数据可以与所有线程共享,以减少内存访问流量和功耗。
[0357]
本文描述的技术可以在数字逻辑门中的一个或多个专用集成电路(asic)中实施,或者由执行存储在有形处理器可读内存存储介质中的指令的处理器实施。
[0358]
在一个实施方案中,任何公开的方法和操作可以以软件实现,该软件包括存储在一个或多个计算机可读存储介质上的计算机可执行指令。一个或多个计算机可读存储介质可以包括非暂时性计算机可读介质(诸如可移动或不可移动磁盘、磁带或盒式磁带、固态驱动器(ssd)、混合硬盘驱动器、cd-rom、cd-rw、dvd或任何其他有形存储介质)、易失性内存组件(诸如dram或sram)或非易失性内存组件(诸如硬盘驱动器)。计算机可执行指令可以在处理器(例如,微控制器、微处理器、数字信号处理器等)上执行。而且,本公开内容的实施方案可以用作通用处理器、图形处理器、微控制器、微处理器或数字信号处理器。
[0359]
虽然本文已经公开了各种方面和实施方案,但是其他方面和实施方案对于本领域技术人员来说将是显而易见的。本文公开的各种方面和实施方案是为了说明的目的,而不是旨在是限制性的,同时真正的范围和精神由所附权利要求指示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1