一种水合物渗透率关联分析和模型预测的实时可视化方法
1.本发明涉及一种水合物渗透率关联分析和模型预测的实时可视化方法,其属于能源领域和地下流体流动及多孔介质流动相关领域,如天然气及其水合物开采等领域,以及需要现场进行水合物渗透率数据可视化分析、获得渗透率预测模型的研究领域。
背景技术:
2.天然气水合物蕴藏的甲烷资源量巨大,对全球碳循环以及能源储量具有重要意义。水合物储层的渗透率决定着储层内流体运移规律和热质传递过程,是影响甲烷泄露通量,水合物的赋存分布以及水合物藏产气效率的重要储层物性。因此,渗透率的精确预测将有利于深海海床的长期稳定性,涉及全球环境问题、并对经济型矿藏预测以及深海地质安全等诸多领域的研究有着不可或缺的影响。
3.水合物储层渗透率受沉积物种类以及水合物形成条件等因素影响。因此,不同地区水合物储层具有不同的渗透率
‑
水合物饱和度变化曲线。随着不同地区渗透率原位测量和保压岩心测量的持续进行,对各地区渗透率数据的合并分析、实现渗透率变化的规律性认识的工作需求越来越大。与此同时,大量的渗透率实验室测量工作提供了丰富的参考数据。根据沉积物种类及水合物生成条件对数据进行分类、合并、分析,处理后的数据可以间接为不同地区渗透率曲线的建立提供依据。渗透率预测模型是建立渗透率曲线的有效工具。不同模型与实际数据之间的匹配程度也各有不同。因此,需要依据不同模型与实际数据的匹配效果,为不同水合物储层优选出最为适用的渗透率模型。
4.目前,水合物渗透率数据分析及模型匹配研究存在如下问题:1)数据合并、分析功能欠缺,难以实现特定地区渗透率变化的规律性认识及不同地区间渗透率变化规律的差异分析;2)模型与实测数据匹配时效性差,无法在勘探过程中实时获得模型比对结果;3)数据处理效率低,缺少高效的人机交互方式。因此,亟需能够有效解决上述问题,以水合物渗透率为研究对象,可以进行实时多功能可视化分析的研究方法。
技术实现要素:
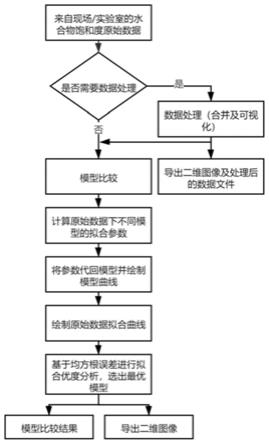
5.本发明的目的就是为了克服渗透率数据分析以及模型匹配应用上的不足,提出了一种水合物渗透率关联分析和模型预测的实时可视化方法。设计一种在保证模型与数据准确的前提下,满足水合物沉积物渗透率多任务分析需求、既面向船载水合物探测采集现场,又可满足实验室使用条件,让使用人员无需深入了解建模过程及模型内在机理便可获得所需结果,使面向对象更广。
6.本发明采用的技术方案为:一种水合物渗透率关联分析和模型预测的实时可视化方法,基于导入的水合物原始饱和度、渗透率原始数据完成水合物沉积物渗透率模型的最优拟合计算,得到可视化渗透率模型拟合曲线、渗透率拟合结果以及均方根误差计算结果,根据误差结果优选最佳模型,并支持多组原始数据的合并与展示。
7.使用水合物饱和度与渗透率的原始数据,代入masuda、patchy、g
‑
c、p
‑
f以及
hybrid五种渗透率模型计算公式中,利用最小二乘法原理和迭代法计算出不同模型在该组水合物饱和度原始数据下最合适的拟合参数(颗粒包裹(g
‑
c)模型和孔隙填充(p
‑
f)模型不需要计算拟合参数,参数为定值),将拟合参数代入对应的模型,在二维坐标系中显示计算出的模型曲线和原始数据点;利用最小二乘法的三次多项式拟合,拟合出一条原始数据的拟合曲线,用以与现有模型的曲线进行比较和分析;基于均方根误差进行拟合优度分析,计算每种模型对该组原始数据计算结果的均方根误差,来判断模型拟合情况是否优秀,优选最适合该组原始数据的拟合模型;使用原始数据,进行数据可视化和数据的合并处理,以实现数据对比的功能。数据进行处理:将水合物的饱和度数据绘制到二维图表以做到可视化;将潜在的同类别数据集(来自相同地区、水合物介质条件相似的探测数据)进行合并,可以增加数据集的规模,提高后期模型优度分析的准确性。
8.所述的水合物饱和度与渗透率的原始数据既可来自科研现场的船载检测仪器,也可来自实验室等研究场所。
9.所述方法既能够在水合物探测采集现场使用,也能够在实验室发挥作用。
10.本发明的有益效果是:本发明的研究方法使用二维图表直观显示原始数据点、合并后数据点及数据拟合后的模型曲线,能够实现对水合物探测采集现场和实验室等多种来源的水合物饱和度、渗透率原始数据进行快速可视化处理。本发明的方法还支持最优模型拟合参数的计算以及对导入的原始数据的最优模型筛选,节省计算工作。
附图说明
11.图1为本发明所述的一种水合物渗透率关联分析和模型预测的实时可视化方法的示意图。
12.图2为模型比较的输出结果示意图。
13.图3为三次多项式拟合后的原始数据拟合曲线图。
14.图4为模型优度输出示意图图5为数据比较的输出结果图。
具体实施方式
15.以下结合技术方案和附图详细叙述本发明的具体实施例。
16.数据代入及模型比较:导入来自水合物探测采集现场或实验室的水合物饱和度原始数据,代入软件搭载的masuda、patchy、g
‑
c、p
‑
f以及hybrid五种渗透率模型计算公式中,利用最小二乘法原理和迭代法计算出不同模型在该组水合物饱和度原始数据下最合适的拟合参数(颗粒包裹(g
‑
c)模型和孔隙填充(p
‑
f)模型不需要计算拟合参数,参数为定值),将拟合参数代入对应的模型,在二维坐标系中显示计算出的模型曲线和原始数据点,如图2所示。根据图中的坐标系图例可知:黑色散点代表原始数据,两条虚线分别代表g
‑
c模型曲线和p
‑
f模型曲线,其余三条实线代表拟合后的模型曲线。g
‑
c模型曲线和p
‑
f模型曲线起到参考和比较的作用:当拟合模型曲线在二维坐标系上更靠近p
‑
f时,代表在相同孔隙度下,该拟合模型中水合物在孔隙中的位置对渗透率影响更大,使渗透率减小得更严重;反之,当
拟合模型曲线在二维坐标系上更靠近g
‑
c时,代表在相同孔隙度下,该拟合模型中水合物在孔隙中的位置对渗透率影响偏小,使渗透率减小得比较缓慢。
17.如图3所示,根据导入的原始数据中水合物饱和度值和渗透率值之间的关系,按照最小二乘法的三次多项式拟合方式,拟合出一条原始数据的拟合曲线,该曲线与其他模型无关,不受其他模型的参数影响,只是观察原始数据点趋势。用以与现有模型的曲线进行比较和分析。
18.如图4所示,基于均方根误差进行拟合优度分析,计算每种模型对该组原始数据计算结果的均方根误差,来判断模型拟合情况是否优秀,优选最适合该组原始数据的拟合模型。图3中原始数据的曲线与图2中模型曲线进行均方根误差计算,得到masuda模型的均方根误差为0.0582085、patchy模型的均方根误差为0.0686589、g
‑
c模型的均方根误差为0.348056、p
‑
f模型的均方根误差为0.216289以及hybrid模型的均方根误差为0.0538934,根据以上结果得出hybrid模型为该组原始数据的优选拟合模型。
19.数据比较及合并:导入水合物饱和度原始数据,展示于二维坐标系,进行数据对比;支持数据集的处理,如数据合并。通过选择两组需要整合的原始数据进行合并,在合并数据前会将两组数据按饱和度从小到大的顺序排序,若饱和度数值相同,则按渗透率从小到大的顺序排序,最终整合成一组。合并后的数据同样可以在二维坐标系上展示。输出结果如图5所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1