译后编辑方法和装置、电子设备及存储介质与流程
本公开涉及机器翻译技术,更具体地,涉及译后编辑方法和装置、电子设备及存储介质。
背景技术:
1、机器翻译在日常生活中的应用十分广泛,也是机器学习在语言处理领域的一个重要研究方向。在使用机器翻译得到机器翻译文本之后,用户还可以利用译后编辑模型对机器翻译文本进行再次编辑调整。目前译后编辑模型存在耗时严重、编辑效果不佳的问题。
技术实现思路
1、本公开实施例提供译后编辑方法和装置、电子设备及存储介质,以提升翻译文本的准确性。
2、根据本公开的实施例的第一方面,提供了一种译后编辑方法,该译后编辑方法包括:
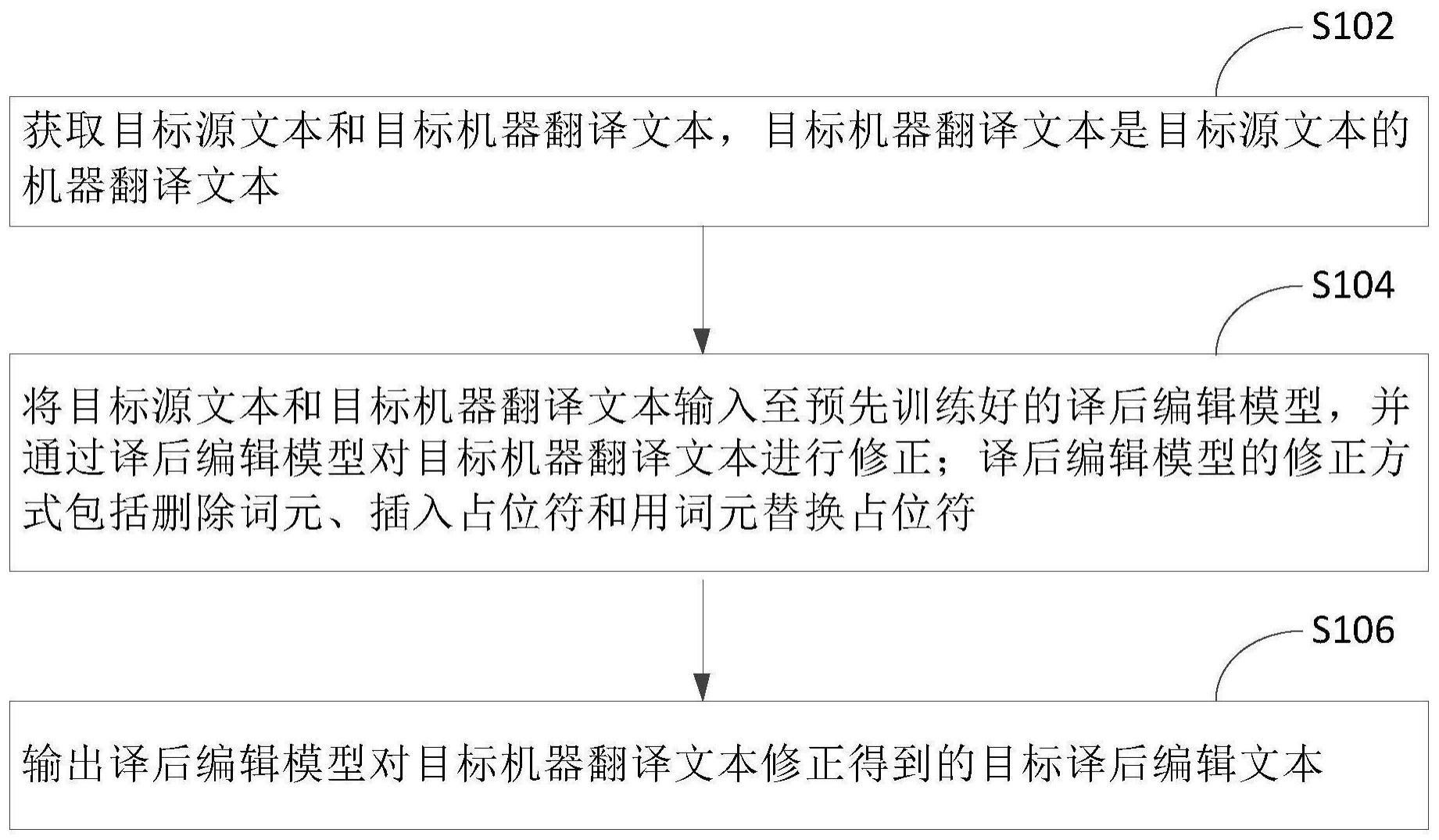
3、获取目标源文本和目标机器翻译文本,所述目标机器翻译文本是所述目标源文本的机器翻译文本;
4、将所述目标源文本和所述目标机器翻译文本输入至预先训练好的译后编辑模型,并通过所述译后编辑模型对所述目标机器翻译文本进行修正;所述译后编辑模型的修正方式包括删除词元、插入占位符和用词元替换占位符;
5、输出所述译后编辑模型对所述目标机器翻译文本修正得到的目标译后编辑文本。
6、可选地,所述译后编辑模型包括编码器网络和解码器网络;所述通过所述译后编辑模型对所述目标机器翻译文本进行修正,包括:
7、通过所述编码器网络,对所述目标源文本进行编码得到所述目标源文本的编码向量;
8、通过所述解码器网络,对所述目标机器翻译文本进行编码得到所述目标机器翻译文本的编码向量,并根据所述目标源文本的编码向量和所述目标机器翻译文本的编码向量对所述目标机器翻译文本进行修正。
9、可选地,所述解码器网络包括编码单元、解码单元、第一预测单元、第二预测单元以及第三预测单元;
10、所述通过所述解码器网络,对所述目标机器翻译文本进行编码得到所述目标机器翻译文本的编码向量,并根据所述目标源文本的编码向量和所述目标机器翻译文本的编码向量对所述目标机器翻译文本进行修正,包括:
11、通过所述编码单元,对所述目标机器翻译文本进行编码得到所述目标机器翻译文本的编码向量;
12、通过所述解码单元,对所述目标源文本的编码向量和所述目标机器翻译文本的编码向量进行矩阵运算,得到所述目标机器翻译文本基于所述目标源文本的注意力分布;
13、通过所述第一预测单元,根据所述目标机器翻译文本基于所述目标源文本的注意力分布预测是否要删除所述目标机器翻译文本中的词元;
14、通过所述第二预测单元,预测在所述目标机器翻译文本中的词元间需要插入的占位符的数量,所述数量为大于或等于零的整数;
15、通过所述第三预测单元,预测出替代所述占位符的词元。
16、可选地,在将所述目标源文本和所述目标机器翻译文本输入至预先训练好的译后编辑模型之前,所述方法还包括:
17、获取多个样本数据组合,每个所述样本数据组合包括样本源文本、第一样本翻译文本以及第二样本翻译文本,所述第一样本翻译文本是所述样本源文本的机器翻译文本,所述第二样本翻译文本是所述样本源文本的译后编辑文本;
18、使用所述多个样本数据组合对所述译后编辑模型进行训练。
19、可选地,在所述获取多个样本数据组合之前,所述方法还包括:
20、获取双语语料文本,所述双语语料文本包括对应相同内容的第一语种文本和第二语种文本;
21、将所述第一语种文本作为所述样本数据组合中的样本源文本;
22、将所述第二语种文本作为所述样本数据组合中的第二样本翻译文本;
23、对所述第二语种文本中的词元进行随机替换和/或随机删除,得到所述样本数据组合中的第一样本翻译文本。
24、可选地,在所述获取多个样本数据组合之前,所述方法还包括:
25、获取双语语料文本,所述双语语料文本包括对应相同内容的第一语种文本和第二语种文本;
26、将所述第一语种文本作为所述样本数据组合中的样本源文本;
27、将所述第二语种文本作为所述样本数据组合中的第二样本翻译文本;
28、调劣预先训练好的翻译模型的参数,将所述第一语种文本输入至所述翻译模型中,通过所述翻译模型对所述第一语种文本进行翻译得到翻译结果,将所述翻译结果作为所述样本数据组合中的第一样本翻译文本。
29、可选地,所述使用所述多个样本数据组合对所述译后编辑模型进行训练,包括:
30、将所述多个样本数据组合分为n个训练批次,确定每个训练批次的不可信概率;
31、在第i个训练批次的不可信概率大于或等于预设阈值的情况下,确定针对第i个训练批次中的每个所述样本数据组合采用第一模式进行训练;在第i个训练批次的不可信概率小于预设阈值的情况下,确定针对第i个训练批次中的每个所述样本数据组合采用第二模式进行训练;所述第i个训练批次是所述n个训练批次中的任一个训练批次;
32、在针对第i个训练批次中的每个所述样本数据组合采用所述第一模式进行训练的情况下,将所述样本数据组合中的第二样本翻译文本的第j-1个词元作为所述译后编辑模型的下一步输入以预测出第j个词元;在针对第i个训练批次中的每个所述样本数据组合采用所述第二模式进行训练的情况下,将所述译后编辑模型预测出的第j-1个词元作为所述译后编辑模型的下一步输入以预测出第j个词元;所述j为整数并且j≥2。
33、可选地,根据以下式子确定第i个训练批次的不可信概率:
34、∈i=max(∈min,k-c*i)
35、其中,∈i为第i个训练批次的不可信概率,max()为取最大值函数,k和c为正值常数,∈min为预设的不可信概率最小值,∈min≥0。
36、根据本公开的实施例的第二方面,提供了一种译后编辑装置,该译后编辑装置包括:
37、获取模块,用于获取目标源文本和目标机器翻译文本,所述目标机器翻译文本是所述目标源文本的机器翻译文本;
38、修正模块,用于将所述目标源文本和所述目标机器翻译文本输入至预先训练好的译后编辑模型,并通过所述译后编辑模型对所述目标机器翻译文本进行修正;所述译后编辑模型的修正方式包括删除词元、插入占位符和用词元替换占位符;
39、输出模块,用于输出所述译后编辑模型对所述目标机器翻译文本修正得到的目标译后编辑文本。
40、根据本公开的实施例的第三方面,提供了一种电子设备,包括处理器和存储器,所述存储器存储有计算机指令,所述计算机指令被所述处理器执行时实现本公开的第一方面的译后编辑方法。
41、根据本公开的实施例的第四方面,提供了一种计算机可读存储介质,其上存储有计算机指令,所述计算机指令被处理器执行时实现本公开的第一方面的译后编辑方法。
42、本公开实施例提供的译后编辑方法和装置、电子设备及存储介质,将目标源文本和目标源文本的机器翻译文本输入至预先训练好的译后编辑模型,通过该译后编辑模型对目标源文本的机器翻译文本进行修正,在修正过程中模仿人类的删除词元、插入词元的修改方式,从而提升了翻译结果的准确性。
43、通过以下参照附图对本公开的示例性实施例的详细描述,本公开的实施例的特征及其优点将会变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!