新型大数据算法平台实现方法与流程
1.本发明涉及大数据处理技术领域,具体是一种新型大数据算法平台实现方法。
背景技术:
2.随着大数据的兴起,伴随着大数据的相关业务也越来越多,机器学习和深度学习算法的应用越来越多,训练的数据集也越来越大,单机的模型训练方式很难满足实际的需要,基于此,大数据算法平台应运而生,其以算子流程的方式实现算法可视化操作,以及便捷快速的部署监控等,与云平台智能化部署融合不仅能够支持非算法人员进行操作,而且能够满足不同的业务需求,多人协作,大大增加了算法可塑性,但同时由于是新兴产品,存在诸多问题:1.算法算子实现流程过长,完成一个算法开发需要大量的算子才能够完成,不仅浪费资源,也增加了操作的难度;2.算子种类不全,有的平台只支持深度学习算法,有的只支持机器学习算法,只满足简单需求,无法运用到复杂业务场景;3.不支持自定义算子,一般算子都是不对外开放的,因此会有部分受限,不利于平台扩展;4.性能效率低,由于部分资源受限,一个完整的算法流程耗费时间较多,不仅占用资源而且浪费时间。
技术实现要素:
3.为了实现业务与算子的适配,提高算法性能,本发明提供了一种新型大数据算法平台实现方法。
4.本发明解决上述问题所采用的技术方案是:
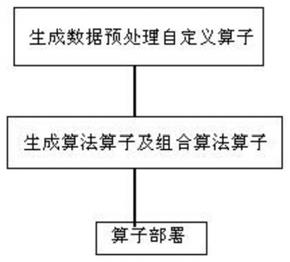
5.新型大数据算法平台实现方法,包括:
6.步骤1、生成数据预处理自定义算子;
7.步骤2、生成算法算子及组合算法算子;
8.步骤3、算子部署。
9.进一步地,所述步骤1包括:
10.步骤11、算子数据源参数配置;
11.步骤12、特征工程参数配置;
12.步骤13、根据各参数配置情况生成数据预处理自定义算子。
13.进一步地,所述步骤11与步骤12之间还包括步骤s12、算子数据处理参数配置。
14.进一步地,所述步骤s12包括:
15.步骤s121、类型转换参数配置;
16.步骤s122、缺失值填充参数配置;
17.步骤s123、数据过滤参数配置;
18.步骤s124、归一化和标准化参数配置;
19.步骤s125、拆分与采样参数配置;
20.步骤s126、链接参数配置。
21.进一步地,所述步骤12包括:
22.步骤121、主成分分析参数配置;
23.步骤122、one
‑
hot编码参数配置;
24.步骤123、特征异常平滑参数配置;
25.步骤124、特征离散参数配置。
26.进一步地,所述步骤2生成算法算子的步骤包括:
27.步骤211、算法模型确定;
28.步骤212、配置超参数;
29.步骤213、修改超参数;
30.步骤214、增加人为超参数;
31.步骤215、根据各参数配置情况生成算法算子。
32.进一步地,所述算法模型包括时间序列分析模型、机器学习模型及深度学习模型。
33.进一步地,所述步骤2生成组合算法算子的步骤包括:
34.步骤221、确定组合算法模型;
35.步骤222、算法模型组合适配;
36.步骤223、根据算法模型及适配情况生成组合算法算子。
37.进一步地,还包括步骤4算子修改。
38.本发明相比于现有技术具有的有益效果是:1.支持自定义算子,可以根据需求进行适配,这样不仅增加了大数据算法平台的可扩展性,而且能够满足不同业务需求,增加了操作的便捷性;2.减少算子流程,针对算法实现流程进行优化,将部分算法进行合并,并增加算子参数,提高了算法性能;3.对算法算子进行丰富,不仅仅是针对本身算法参数,还要融合其他因素,这样便于不同数据源运用不同算法算子。基于上述方式不仅能够解决大数据算法平台算法算子实现流程过长的问题,而且增加了大数据算法平台的可操作性,能够更好的满足不同业务需求,真正发挥出大数据算法平台的优势,对不同类型的人员,不同类型的业务进行适配。
附图说明
39.图1为新型大数据算法平台实现方法整体流程图;
40.图2为数据预处理自定义算子生成流程图;
41.图3为算法算子及组合算法算子生成流程图。
具体实施方式
42.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
43.如图1所示,新型大数据算法平台实现方法,包括:
44.步骤1、生成数据预处理自定义算子;
45.步骤2、生成算法算子及组合算法算子;
46.步骤3、算子部署。
47.本技术通过自定义数据预处理算子实现不同数据处理需求的适配,不仅增加了大
数据算法平台的可扩展性,而且能够满足不同业务需求,增加了操作的便捷性。通过组合算法算子实现算法合并,从而减少算子流程,提高了算法性能。
48.具体的,所述步骤1包括:
49.步骤11、算子数据源参数配置;例如:字段名称为data,0代表文本文件,格式为csv格式,1代表mysql数据库,2代表hive数据库。
50.当本地数据来源为文本文件csv格式时,默认逗号为分隔符,若有其他分隔符,按照字段名称character来进行对应选择。这里额外需要处理的是,csv文件首行是否作为字段名的问题,在本实施例中采取直接过滤首行:如果有字段名则去掉,如果没有则直接进行处理,生成算子之后会自动生成对应的字段名。做好处理之后,将所述处理保存在算子中,并进行算子参数配置。
51.当数据源为mysql时,用户需要提前根据要求配置mysql数据库,并进行验证,测试成功后将信息反馈给算子,并进行编码操作,针对数据表进行处理,做好处理之后,将所述处理保存在算子中,并进行算子参数配置。
52.当数据源为hive时,用户需要提前根据要求配置hive数据库,并进行验证,测试成功后将信息反馈给算子,并进行编码操作,针对数据表进行处理,做好处理之后,将所述处理保存在算子中,并进行算子参数配置。
53.将所述算子的参数信息保存到算子参数表中。
54.步骤12、特征工程参数配置:进行该步操作的前提是数据类型为double类型,包括:
55.主成分分析参数配置:按照0:主成分数量,1:信息百分比1.1百分比值,8:不主成分分析,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如pca_代表主成分分析之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
56.one
‑
hot编码参数配置:按照0:keep策略,1:error策略,8:不one
‑
hot编码,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如one_代表one
‑
hot编码之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
57.特征异常平滑参数配置:按照0:zscore0.1:置信水平值平滑,1:阙值平滑,2:百分位平滑,8:不处理,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如abms_代表特征异常平滑之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
58.特征离散参数配置:按照0:等距离散,1:等频离散,2:离散区间数,8:不处理,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如dis_代表特征离散之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
59.在实际进行数据运用时并不是所有数据都满足要求,因此需要对数据进行处理。可在步骤11与步骤12间增加步骤s12、算子数据处理参数配置;通过该步骤可以实现不同的数据处理需求,例如类型转换,缺失值填充,数据过滤等。
60.类型转换参数配置:经过步骤11源数据获取成功后,自动生成的数据集字段名称
类型均为string,但部分处理或者部分算法候选集需要不同类型,因此需要进行类型转换,如:分别按照1,string
‑
string;2,string
‑
double;3,string
‑
bigint进行转换,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如cvrt_代表类型转换好的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
61.缺失值填充参数配置:在对空值进行填充时,针对数字型数据:可以按照填充值0:最大值,1:最小值,2:平均值,3:中位数,4:重数,5:自定义值等进行填充,这里自定义值也需要填充数字型数据。针对字符型数据直接自定义填充,这里自定义值也需要填充字符型数据。以上处理自动生成转换好的字段名称,以便和源数据区分,形如imputed_代表缺失值填充后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。空值指数据为空,形如null,null,
“”
等标识均为空数据。
62.数据过滤参数配置:过滤规则形如xxx>5,xxx<=3,xxx=
‘
你好’等具体规则,这里的规则需要用户按照需求进行填写,对于数字型数据,支持支持大于,小于等常规过滤条件,还包含mean等常规函数;对于字符型数据,按照等于,不等于等常规过滤条件进行过滤。
63.归一化和标准化参数配置:进行该步骤的前提是类型必须为double或者int类型。例如,归一化参数配置:按照0:离差标准化,1:标准差标准化,2:非线性归一化,8:不归一化,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如norm_代表归一化之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。标准化参数配置:按照0:正态化,1:0,1之间,2:
‑
1,1之间,8:不标准化进行处理,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如std_代表标准化之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
64.拆分与采样参数配置:
65.拆分:可按照0:按比例拆分0.1比例值,1:按照阙值拆分1.1阙值列,8:不拆分,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如spi_代表拆分之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
66.采样:包括随机采样,分层采样及加权采样,可按照0:采样比例0.1比例值,1:采样个数1.1个数值,8:不采样进行处理,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如ran_代表随机采样,分层采样或加权采样之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
67.链接参数配置:进行join操作的前提是需要两个表,即左表和右表,且左右表之间有可匹配字段,左表和右表链接规则一致。
68.左表,按照0:左链接,1:右链接,2:内链接,3:全链接,8:不链接,并进行记忆,自动生成转换好的字段名称,以便和源数据区分,形如joinl_代表左表之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
69.右表,按照0:左链接,1:右链接,2:内链接,3:全链接,8:不链接,并进行记忆,自动
生成转换好的字段名称,以便和源数据区分,形如joinr_代表右表之后的字段,做好处理之后,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
70.根据不同的数据处理需求,各处理方式可单独使用也可组合使用。
71.步骤13、根据各参数配置情况生成数据预处理自定义算子,具体为根据算子参数表进行配置封装,形成算子组件。
72.所述步骤2生成算法算子的步骤包括:
73.步骤211、算法模型确定:在本实施例中,算法模型包括时间序列分析模型、机器学习模型及深度学习模型;
74.步骤212、配置超参数;
75.步骤213、修改超参数;
76.步骤214、增加人为超参数;
77.步骤215、根据各参数配置情况生成算法算子。
78.算法模型确定:例如时间序列分析模型:按照0:arima1:arma2:es3:garch4:holt5:holt_winners6:prophet7:sarima8:stl9:x11,并进行记忆。
79.配置超参数:按照0:arima1:arma2:es3:garch4:holt5:holt_winners6:prophet7:sarima8:stl9:x11,并进行记忆。
80.形如:
[0081][0082][0083]
修改超参数:按照0:arima1:arma2:es3:garch4:holt5:holt_winners6:prophet7:sarima8:stl9:x11,并进行记忆。
[0084]
形如:
[0085][0086]
增加人为超参数:按照0:arima1:arma2:es3:garch4:holt5:holt_winners6:prophet7:sarima8:stl9:x11,并进行记忆。
[0087]
形如:
[0088][0089]
根据各参数配置情况生成算法算子:将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
[0090]
机器学习模型:按照0:cart1:catboost2:gbdt3:gbm4:knn5:lr6:rf7:svr8:xgboost,并进行记忆。
[0091]
配置超参数:按照0:cart1:catboost2:gbdt3:gbm4:knn5:lr6:rf7:svr8:xgboost,并进行记忆。
[0092]
形如:
[0093][0094]
修改超参数:按照0:cart1:catboost2:gbdt3:gbm4:knn5:lr6:rf7:svr8:xgboost,并进行记忆。
[0095]
形如:
[0096][0097]
增加人为超参数:按照0:cart1:catboost2:gbdt3:gbm4:knn5:lr6:rf7:svr8:xgboost,并进行记忆。
[0098]
形如:
[0099]
[0100][0101]
将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
[0102]
深度学习模型:按照0:cnn1:lstm2:mlp3:tcn4:seq2seq,并进行记忆。
[0103]
配置超参数:按照0:cnn1:lstm2:mlp3:tcn4:seq2seq,并进行记忆。
[0104]
形如:
[0105][0106]
修改超参数:按照0:cnn1:lstm2:mlp3:tcn4:seq2seq,并进行记忆。
[0107]
形如:
[0108][0109]
增加人为超参数:按照0:cnn1:lstm2:mlp3:tcn4:seq2seq,并进行记忆。
[0110]
形如:
[0111]
[0112][0113]
将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中。
[0114]
所述步骤2生成组合算法算子的步骤包括:
[0115]
步骤221、确定组合算法模型;
[0116]
步骤222、算法模型组合适配;
[0117]
步骤223、根据算法模型及适配情况生成组合算法算子。
[0118]
按照0:时间序列模型:l机器学习模型2:深度学习模型3:适配状态:{成功,失败},并进行记忆,将所述处理保存在算子中,并进行算子参数配置,将所述算子的参数信息保存到算子参数表中,获取算子参数表并进行配置封装,形成算子组件。
[0119]
步骤3、算子部署:包括
[0120]
(1)运行环境配置:算子部署环境,需要支持算子包含的开发语言环境;
[0121]
(2)平台环境配置:大数据组件,大数据部署环境,云环境,微服务等;
[0122]
(3)算子所属组编号,命名之后进行分组管理;
[0123]
(4)创建时间:系统生成时间即为创建时间;
[0124]
(5)共享:是否共享,按照0:共享,1:不共享配置,以实现多项目协同作业。
[0125]
进一步地,还包括步骤4算子修改,对于部署好的算子还支持算子修改,对应地,在部署时还包括最后修改时间:算子最后修改时间;以修改为例,获取当前修改时间。
[0126]
数据预处理自定义算子参数配置表如下所示:
[0127]
[0128][0129]
算法算子及组合算法算子参数配置表如下所示:
[0130]
[0131][0132]
实施例
[0133]
step1数据源获取
[0134]
选取本地csv数据,具体格式如下:
[0135][0136]
则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0}
[0137]
step2类型转换
[0138]
根据需要,将_c0至_c3的字段类型从string转为double类型,转换结果如下:
[0139][0140]
则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0;type_conversion:1}
[0141]
step3缺失值填充
[0142]
根据需要,需要对空值数据进行填充,填充结果如下:
[0143][0144]
则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0;type_conversion:1;missing_fill_original:0;missing_fill_value:2}
[0145]
step4归一化
[0146]
根据需要,需要对数据进行归一化处理,处理结果如下:
[0147][0148]
则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0;type_conversion:1;missing_fill_original:0;missing_fill_value:2;normalization:1}
[0149]
step5拆分
[0150]
根据需要,需要对数据进行拆分处理,处理结果如下:
[0151][0152][0153]
则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0;type_conversion:1;missing_fill_original:0;missing_fill_value:2;normalization:1;split_up:{0,0.8}}
[0154]
step6特征异常平滑
[0155]
根据需要,需要对数据进行特征异常平滑处理,处理结果如下:
[0156][0157]
则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0;type_conversion:1;missing_fill_original:0;missing_fill_value:2;normalization:1;split_up:{0,0.8};unusually_smooth:1}
[0158]
step7生成数据预处理自定义算子
[0159]
完成自定义数据预处理算子参数配置,接下来配置生成数据预处理自定义算子,则算子参数为{id:1;name:自定义数据预处理;description:包含数据导入,数据预处理,特征工程等,集成自定义数据预处理算子;data:0;character:0;type_conversion:1;missing_fill_original:0;missing_fill_value:2;normalization:1;split_up:{0,0.8};unusually_smooth:1;run:linixx86sys_config:{1g,1g,512g};group:1;create_time:2021
‑
01
‑
22;update_time:2021
‑
01
‑
22;public:1}
[0160]
根据算子配置参数,进行封装,产出api接口,并进行部署,部署成功后数据预处理自定义算子配置成功,既可以进行访问也可进行参数更改。
[0161]
step8生成算法组合算子
[0162]
在step7步骤基础之上,已经生成算法所需的源数据,接下来就是运用算法组合算子进行处理,则算子参数为{id:1;name:算法组合;description:时间序列分析模型,机器学习模型,深度学习模型等;time_series:0;machine_learning:7;deep_learning:1;time_series_handcraft:1;machine_learning_handcraft:{00.3};adaption:1;combination:1;run:linixx86sys_config:{1g,1g,512g};group:2;create_time:2021
‑
01
‑
22;update_time:2021
‑
01
‑
22;public:1}
[0163]
根据算子配置参数,进行封装,产出api接口,并进行部署,部署成功后算法组合算子配置成功,既可以进行访问也可进行参数更改。
[0164]
经过实验表明,经过数据预处理自定义算子以及算法组合算子,能够满足大多数业务场景,且仅仅只需要两个算子就可以完成负责的算法实现过程,经过性能测试发现,经过优化的算法流程会优于常规构建流程。
[0165]
下表对比了目前市场上几家成熟的算法平台(其中新型为本技术所采用的算法平台),以算法算子实现流程步骤以及运行整个流程所耗费时间进行对比,发现无论从步骤还是性能方面均优于其他平台,主要表现在缩短算子流程,融合算子之间优点,减少冗余操作,增加算法算子可塑性以及可扩展性,充分发挥了大数据算法平台的优点。
[0166]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1