一种基于医学主题词表增强表征的文本多标签分类方法
1.本发明涉及自然语言处理技术领域,具体涉及一种基于医学主题词表增强表征的文本多标签分类方法。
背景技术:
2.医学主题词表(medical subject headings,mesh)是由美国国家医学图书馆(national library of medicine,nlm)提出并逐年更新的词汇库,其作用是为了方便索引、编目和搜索生物医学信息。截止到2020年,nlm已经收录了29640个mesh词汇/短语。mesh最主要的作用是在巨大的生物医疗文献数据库medline中索引相关的文献,该文献库至今已经收录包括5200个期刊、约2600万篇文献;平均每篇medline中的文献标记有13个mesh,这些mesh可以用于生物医学文本挖掘、信息检索等方面。因此准确且高效的mesh标记意义重大。
3.medline数据库中收录的巨大数量文献,其医学主题词表一般是由nlm的专家手动标记。据统计,每篇文献的mesh标记需要花费$9.4,费时费力。为了应对高速的文献增长数量,nlm研发了一款名为medical text indexer(医学文本索引,mti)的软件,用来辅助专家进行自动或者半自动mesh标注。目前约有5%的文献是由mti自动标注,18%的文献由mti标注之后,再由人工审核,对标注进行修正。
4.从机器学习的角度来看,mesh标注是一个大规模多标签分类问题,其中mesh是标签,文献则是样本,目的是给每一篇文献标注合适的多个标签。直观来看,就是给定一篇文献,从固定的mesh词库中将近30,000个词汇/短语中选出合适的一定数量的mesh作为标签。许多机器学习领域的学者都针对这个问题提出了自己的解决方案,并且随着机器学习乃至深度学习技术的飞速发展,解决该问题的方法也在不断更新。但是,目前大多数工作都把注意力集中在(i)如何更好地表征输入文本以及(ii)增加输入文本的数量。对于(i),有各种文本表征模型,如卷积神经网络(convolutional neural networks,cnn)、循环神经网络(recurrent neural network,rnn)及其变体lstm(long short-term memory)、gru、bert(bidirectional encoder representations from transformers)等,研究人员不断探索更加合适的表征输入文本的方式,也在结果上不断有所突破;对于(ii),该工作的输入文本从最初文献的标题和摘要,增加了期刊名称、增加了图表说明,到目前增加了全文输入。
5.但是很少有工作关注标签本身所包含的信息问题。绝大多数工作只把标签作为一个短语,而没有发掘其更深层次的信息。对比人工标注的过程,专家一定是理解了mesh的含义,进而对文本进行标注。然而人工标注效率低下、成本过高,显然已经难以满足每年大量增长的医学文献的标注需求。但机器标注,由于机器不知道mesh所隐含的含义,因此难以进行准确的标注,其标注的表现一直不佳,进而影响文本分类的准确性和可靠性。
技术实现要素:
6.本发明针对现有技术所存在的问题,提出一种基于医学主题词表增强表征的文本
多标签分类方法,基于深度学习来对医学主题词表进行增强表征,以增加标签分类的准确性。
7.一种基于医学主题词表增强表征的文本多标签分类方法,包括对标签进行增强表征的步骤:s1、将文献中的医学主题词表作为标签,并建立标签的正样本集合;s2、从所述正样本集合中提取关于标签的关键词信息;s3、从所述关键词信息中提取语义特征,得到所述关键词信息的向量表示,记为第一向量;s4、将标签转化为向量,记为第二向量;s5、连接所述第一向量和所述第二向量以对标签进行增强表征。
8.进一步地,步骤s1具体包括:设给定数据集t,包含多篇文献,其中包含的标签数目为nm;针对每个标签mesh l(l=1,2,
…
,nm),从训练集中选出含标签mesh l的文献,构建对应的正样本集合t
l
。
9.进一步地,步骤s2中,利用tf-idf算法从所述正样本集合中提取标签的关键词信息。
10.进一步地,步骤s3中,利用预训练的模型biobert从所述关键词信息中提取所述语义特征。
11.进一步地,步骤s4中,利用门控循环单元模型将标签转化为向量。
12.进一步地,针对标签mesh l,其对应的所述第一向量和所述第二向量分别记为通过步骤s5连接所述第一向量和所述第二向量并进行平均池化,得到标签mesh l的增强表征其中,k为所述关键词信息的长度,d为特征维度,为实数域。
13.进一步地,还包括:s6、利用预训练模型,提取给定数据集t的语义特征并用向量表示,记为向量d;s7、基于向量d,对给定数据集t中的每篇文献t,选出最相似的k篇文献,再从k篇文献中选出出现频率最高的m个标签,将m个标签转化为向量表示记为s
t
;s8、将向量s
t
与文献t进行注意力机制相结合,输出结果向量h。
14.进一步地,步骤s6包括:对于给定数据集t中的每篇文献t,利用预训练的神经网络模型biobert提取其语义特征,得到对应的特征向量模型biobert提取其语义特征,得到对应的特征向量nw表示文献t的长度即单词数量,d表示特征维度;则给定数据集t的文献总体表征为d=[t1,t2,
…
,tn],n表示给定数据集t中文献的数量;步骤s7包括:根据向量d,利用无监督聚类方式k-means选出文献t的k篇最相似文献,再从k篇最相似文献所包含的标签中选出出现频率最高的m个标签并转化为向量,记为步骤s8包括:基于注意力机制,赋予文献t其k篇最相似文献中的m个标签所包含的信息,得结果向量h,为:t
t
表示特征向量t的转置。
[0015]
进一步地,还包括利用如下公式计算文献t和标签meshj之间的分数:其中,σ为sigmoid激活函数,mj和bj都是可学习的参数,j∈[1,m],αj通过对向量h进行归一化而得到,即:
[0016]
进一步地,还包括:将结果向量h输入线性分类器,判断所属标签。
[0017]
与现有技术相比,本发明的有益效果在于:通过从大量的文本中提取标签的关键词信息作为标签的解释,以增加标签的信息量,从而提高模型标注医学主题词表的准确率。
附图说明
[0018]
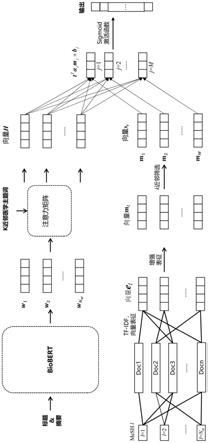
图1是本发明实施例基于医学主题词表增强表征的文本多标签分类方法的流程架构图。
[0019]
图2是本发明实施例的注意力机制示意图。
具体实施方式
[0020]
下面结合附图和具体的实施方式对本发明作进一步说明。
[0021]
本发明实施例提出一种基于医学主题词表增强表征的文本多标签分类方法,如图1所示为该方法的流程架构,包含:对医学主题词表进行增强表征,然后,基于增强表征的医学主题词表进行文本多标签分类。参考图1,包括如下步骤:
[0022]
s1、将文献中的医学主题词表作为标签,并建立标签的正样本集合。
[0023]
设给定数据集t包含n篇文献doc1、doc2、
……
、docn,总共包含标签数目为nm;针对每个标签mesh l(l=1,2,
…
,nm),从训练集中选出含标签mesh l的文献,构建对应的正样本集合t
l
。如图1中所示,与标签mesh l连线的文献即表示含有该标签的文献,这些文献构成该标签的正样本集合。
[0024]
s2、从所述正样本集合中提取关于标签的关键词信息。
[0025]
针对每个标签mesh l(l=1,2,
…
,nm),可以利用tf-idf(词频-逆文本频率指数)算法从各自的正样本集合中提取对应的关键词信息,每个标签的关键词信息的长度记为kl。在一个实施例中,选取kl=10。
[0026]
s3、从所述关键词信息中提取语义特征,得到所述关键词信息的向量表示,记为第一向量。
[0027]
针对标签mesh l,在利用tf-idf提取关键词信息之后,再将关键词信息采用向量表征,具体而言,是从关键词信息中提取语义特征,构成特征向量,即得到关键词信息的向量表示,记为第一向量其中k为所述关键词信息的长度,d为特征维度,为实数域。在一种实施例中,可以采用预训练的模型biobert来从关键词信息中提取语义特征。需要说明的是,biobert神经网络模型的网络结构是已知的,本领域技术人员可从文献《lee j,yoonw,kim s,et al.biobert:a pre-trained biomedical language representation model for biomedical text mining[j].bioinformatics,2020,36(4):1234-1240.》中获知该网络结构;可利用大量生物医学领域的文本,采用现有的神经网络训练方法,以关键词信息的数据集作为输入、以对应的语义特征作为输出对该神经网络进行预训练。
[0028]
s4、将标签转化为向量,记为第二向量。在一种实施例中,利用门控循环单元(gate recurrent unit,gru)模型将标签mesh l转化为向量,记为第二向量
[0029]
s5、连接所述第一向量和所述第二向量以对标签进行增强表征。针对标签mesh l,将其第一向量e
l
与第二向量m'
l
连接起来并进行平均池化,得到一个向量该向量m
l
即为标签mesh l的增强表征,也就是医学主题词表的增强表征。
[0030]
s6、利用预训练模型,提取给定数据集t的语义特征并用向量表示,记为向量d。对于给定数据集t中的每篇文献t,将其文本(比如标题和摘要)输入到预训练的biobert模型中,提取其语义特征,得到对应的特征向量中,提取其语义特征,得到对应的特征向量nw表示文献t的长度即单词数量,d表示特征维度;则给定数据集t的文献总体表征为d=[t1,t2,
…
,tn],n表示给定数据集t中文献的数量。可利用大量生物医学领域的文本,采用现有的神经网络训练方法,以大量文献的文本数据集作为输入、以对应的语义特征作为输出对biobert神经网络模型进行预训练。
[0031]
s7、基于向量d,对给定数据集t中的每篇文献t,选出最相似的k篇文献,再从k篇文献中选出出现频率最高的m个标签,将m个标签转化为向量表示记为s
t
。根据向量d,利用无监督聚类方式k-means筛选出文献t的k篇最相似文献,再从k篇最相似文献所包含的标签中选出出现频率最高的m个标签并转化为向量,记为
[0032]
s8、将向量s
t
与文献t进行注意力机制相结合,输出结果向量h。参考图1和图2,基于注意力机制,赋予文献t其k篇最相似文献中的m个标签所包含的信息,即:将文献t的k近邻医学主题词的向量与文献t的特征向量的转置进行点积,得结果向量h,为:t
t
表示特征向量t的转置。
[0033]
s9、利用如下公式计算文献t和标签meshj之间的分数:其中,σ为sigmoid激活函数,j=1,2,
…
,m;mj和bj都是可学习的参数,通过优化损失函数和反向传播,在每一个循环中优化这两个参数。αj通过对向量h进行归一化而得到,即:得到每个标签针对某一给定文献的分数,分数越高说明该标签为真的可能性越大。
[0034]
s10、将结果向量h输入线性分类器,判断所属标签,进而实现文本分类。
[0035]
下面通过一个具体的例子来对本发明前述实施例进行辅助说明。
[0036]
本实验采用的数据集t为pmc collection。该数据集包括257,590篇文献,22881个mesh。平均每篇文献包含有13.34个mesh标签,而平均每个mesh的正样本集合包含150篇文献。本实验使用的显卡型号为titan xp,显存12gb。批尺寸(batch size)设为4,学习率(learning rate)设为2
×
10-5
。具体实施步骤如下:
[0037]
首先,把文献的标题和摘要作为输入文本,通过biobert模型输出文献的特征向量其中nw表示文献长度,即单词数量,在本发明中特指文献标题和摘要的单词数量。
[0038]
根据给定的数据集t,针对每个mesh l(l=1,2,
…
,nm),选出含有该mesh的样本合集t
l
,即集合t
l
中每篇文献的标注中都含有mesh l。在集合t
l
中,利用tf-idf算法筛选出关
键词信息,然后利用biobert提取语义特征,用向量表示为之后对应的mesh l经过训练好的gru转化为向量过训练好的gru转化为向量最后连接两个向量e
l
和m'
l
,并经过平均池化,得到关于mesh l的最终表征
[0039]
同时,根据上述得到的文献t的向量表征针对每篇文献t,利用无监督聚类方式k-means,筛选出k=1000篇最为相似的文献。再从k篇文献所包含的标签中选出出现频率最高的m=1024个标签并转化为向量s
t
,表示为
[0040]
得到文献t的向量表征及文献t对应的k近邻医学主题词表后,我们利用注意力机制,将相似文献对应的医学主题词表信息赋予文献t的向量表征,即:之后再通过softmax函数,把得到的向量h归一化,即:
[0041]
为了对每篇文献t进行分类,通过以下公式得到针对文献t和meshj之间的分数:其中mj和bj都是可学习的参数。在训练过程中,本发明采用交叉熵损失函数。对于meshj,其交叉熵损失函数可以表示为:通过减小该函数的值不断优化模型。
[0042]
本发明采用的评估标准为precision@k(下述简写为p@k)以及ndcg@k。precision@k是指标precision的特例:即仅对评估样本的前k个分数最高的样本进行评估。以y∈{0,1}
nm
表示文献的实际标签集合,表示对同一篇文献模型预测的标签合集,则上述评估标准用公式表述为:标准用公式表述为:标准用公式表述为:其中是系统预测的正样本标签和实际标签中对应的标签的索引合集,||y||0表示实际标签集合中和预测标签中对应的数量。得到如下表1的结果:表1
[0043]
表1是本发明结果与其他论文模型结果的对比。其中multichannel textcnn方法
使用的是cnn模型,hgcnmesh方法使用的是图神经网络(graph neural network)模型捕捉标签之间的关系。可以看出在k=1、3、5的情况下,本发明p@k和ndcg@k指标都有所提升,说明本实验方案对于标签语义的补充起到了良好的效果。
[0044]
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1