一种处理混合废旧产品的多人共站不完全拆卸线平衡设计方法
1.本发明涉及拆卸系统平衡设计技术领域,具体是一种处理混合废旧产品的多人共站不完全拆卸线平衡设计方法。
背景技术:
2.随着智能产品的更新速度日益加快和人民消费习惯的逐步改变,大量废旧机电产品不断产生。通常废旧机电产品中包含有子功能健全的零部组件和可再回收利用的原材料,同时也包含污染环境的有害物质。比如电动汽车中,轮毂,白车身,转向系统等属于可回收的有利用价值的零部组件,而动力电池包、聚酯材料、聚甲醛材料等属于对环境有害的物质。不合理处理这些废旧机电产品不仅会导致大量可回收资源的浪费,还会造成严重的环境污染。然而,资源短缺和环境污染已经成为制约当前社会可持续发展的关键因素。因此,如何及时并有效处理废旧机电产品已成为亟待解决的问题。
3.拆卸生产线是实现大量废旧机电产品循环利用和再制造的重要解决方案。拆卸生产线是将产品的零部件按照其相互连接的约束关系逐一分配到沿传送带分布的不同工作站当中,再由其中的操作工人完成相应任务的拆卸工作,拆卸下来的可再利用的零部件通过修复后可重返销售市场,而不具备功能可修复的零部件则通过物理粉碎、高温溶解和化学处理等手段进行原材料的提取,然后使原材料进入重新制造过程。
4.拆卸线平衡设计的目的是将规划好的拆卸任务分配到顺序排布的工作站中,并在保证产线流畅运行的情况下尽可能地均衡多个需要考虑的优化目标,比如经济指标(成本、利润、产量和需求指标等),环保指标(能耗、碳排放量和有害物质指标等),产线指标(线效率、节拍时间、工作站数量和刀具更换次数等)。在现实中,对这些目标进行均衡优化得到最合适的拆卸方案对于拆卸企业来说尤为重要。
5.传统的拆卸线平衡设计中,工作站均采用单人站点拆卸方式,即每个工作站内均只有一个工人完成该工作站内的所有拆卸任务。当拆卸零件数量多且结构复杂的产品时,工作站内包含大量的拆卸任务,单人站点拆卸效率极为低下。为了提高拆卸效率,本专利将工作站设计为多工位站点,即一个工作站内安排多个工人完成站内拆卸任务。当前,拆卸线平衡设计仅满足单一产品的完全拆卸,即整条拆卸线完成某一特定产品的所有零部件的移除。对于回收多种品类废旧产品的企业来说,单一产品拆卸线不利于适应客户需求波动较大的产品拆卸,即当某种产品的需求量不大甚至无需求时,它的拆卸线只有停产以避免增加生产成本。另外,与完全拆卸不同,仅将有价值、危害和必拆的零件拆除,剩余零件则不拆除的模式被称为不完全拆卸。不完全拆卸非常有利于避免产线的无效作业和劳动力浪费。因此,很有必要设计能同时拆卸多种类产品的多人站点不完全拆卸线以柔性地应对变化的客户需求和降低拆卸成本。
技术实现要素:
6.为解决上述问题,本发明的主要目的在于提供了一种处理混合废旧产品的多人共站不完全拆卸线平衡设计方法,本发明拆卸线平衡设计模型适用于混合产品拆卸方案优选,将传统的单一产品完全拆卸拓展到混合多产品不完全拆卸,提高了拆卸效率。
7.本发明的技术方案是:
8.一种处理混合废旧产品的多人共站不完全拆卸线平衡设计方法,包括以下步骤:
9.s1、以工作站节拍时间、拆卸成本、需求指标、危害指标最低为目标,建立数学模型,该数学模型的目标函数如下:
10.min ct
ꢀꢀꢀ
(1)
[0011][0012][0013][0014]
其中,u为所有产品的总任务集合,i,j为任务编号,i,j∈u;s为工作站编号s∈s;w为工人编号,w∈w;为拆卸任务i的开始时间,如果i是工作站s中工人手上的第一个任务时,则t
iw
为在考虑了产品零部件的回收状态和工人技能差异后,工人w执行任务i的拆卸处理时间;dci为执行任务i的单位时间拆卸成本;ocs为工作站s的单位时间运行成本;hpw为工人w的时薪;hci为任务i的无害化处理成本;ct为工作站的节拍时间;tc为拆卸线运行总成本;di为需求指标;hi为危害指标;y
isw
为任务i的分配变量,如果任务i被分配到工作站s的工人w手中,y
isw
=1,否则y
isw
=0;ks为工作站开启状态变量,如果工作站s开启,ks=1,否则ks=0;
[0015]
s2、收集拆卸线数据并提出目标函数的约束条件,形成拆卸平衡设计模型;所述约束条件包括拆卸决策变量约束、任务间关系约束、节拍时间约束、分配约束、工作站配置约束、工人配置约束、变量约束:
[0016]
s3、求解所述拆卸平衡设计模型,对解集的各个目标进行比例加权求和获得单个具有偏向性的最优拆卸方案。
[0017]
目前大多数现有的拆卸线平衡模型为概念的,既不能正确且完整地描述问题的所有约束,也不能用数学求解器获得目标的全局最优解。针对上述问题,对本发明的拆卸平衡设计模型建立了完善描述拆卸平衡限定的多目标和约束条件,使得拆卸平衡设计模型成为可以采用学求解器求解的混合整数规划(mixed-integer programming,mip)模型。此外,约束条件中还考虑了废旧机电产品的结构回收状态和工人技能差异对拆卸线的综合影响,使得优选出的拆卸方案更具代表性。
[0018]
另外,小规模零件的产品可采用精确求解器求解最佳拆卸方案,但随着产品的零件数量和结构复杂度的增加,大规模零件的产品去求解难度呈指数级增加。鉴于上述问题,本发明结合nsga-ii的算法结构和所提模型的特征提出包含激励策略的改进nsga-ii(improvednsga-ii,insga-ii)以实现拆卸平衡设计模型的有效求解。所提insga-ii算法属于元启发式算法类别,具有搜索速度快和获取全局最优解能力强的特点。具体而言,该算
法采用pareto 占优方法筛选算法迭代过程中的非劣解,采用超体积(hv,hyper volume)指标评价当前非劣解集分散性和收敛性,即评价每一代获得解的优劣。
[0019]
本发明的技术效果是:
[0020]
(1)本发明的多人站点拆卸线平衡设计从传统的单一产品完全拆卸拓展到混合多产品不完全拆卸。
[0021]
(2)本发明完善描述拆卸平衡限定的多目标和约束条件,建立了可以采用数学求解器求解的混合整数规划模型,且此模型考虑了废旧机电产品的结构回收状态和工人技能差异对拆卸线的综合影响。
[0022]
(3)本发明提出了改进的算法(insga-ii),本算法基于pareto解集加权的方法以获取具有目标偏向的最佳拆卸方案,为决策者快速调整排产提供高效的方法。
附图说明
[0023]
为了更清楚地说明本发明实施方式的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍。
[0024]
图1为本发明实施例insga-ii的算法流程图;
[0025]
图2为本发明实施例电视机的优先关系图;
[0026]
图3为本发明实施例电脑的优先关系图;
[0027]
图4为本发明实施例打印机的优先关系图;
[0028]
图5为本发明实施例insga
‑ⅱ
的hv迭代曲线流程图;
[0029]
图6为本发明实施例hv指标箱型图;
[0030]
图7为本发明实施例带有成本偏向的最优方案排产甘特图。
具体实施方式
[0031]
下面结合实施例及附图,对本发明作进一步地的详细说明。
[0032]
为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
[0033]
实施例
[0034]
一种处理混合废旧产品的多人共站不完全拆卸线平衡设计方法,包括以下步骤:
[0035]
s1、以工作站节拍时间、拆卸成本、需求指标、危害指标最低为目标,建立数学模型,该数学模型的目标函数如下:
[0036]
min ct
ꢀꢀꢀ
(1)
[0037][0038][0039]
[0040]
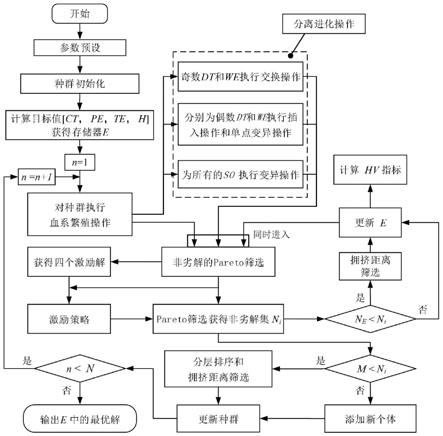
其中,u为所有产品的总任务集合,i,j为任务编号,i,j∈u;s为工作站编号s∈s;w为工人编号,w∈w;为拆卸任务i的开始时间,如果i是工作站s中工人手上的第一个任务时,则t
iw
为在考虑了产品零部件的回收状态和工人技能差异后,工人w执行任务i的拆卸处理时间;dci为执行任务i的单位时间拆卸成本;ocs为工作站s的单位时间运行成本;hpw为工人w的时薪;hci为任务i的无害化处理成本;ct为工作站的节拍时间;tc为拆卸线运行总成本;di为需求指标;hi为危害指标;y
isw
为任务i的分配变量,如果任务i被分配到工作站s的工人w手中,y
isw
=1,否则y
isw
=0;ks为工作站开启状态变量,如果工作站s开启,ks=1,否则ks=0;
[0041]
s2、在所述数学模型的基础上,收集拆卸线数据并提出目标函数的约束条件,形成拆卸平衡设计模型;所述约束条件包括拆卸决策变量约束、任务间关系约束、节拍时间约束、分配约束、工作站配置约束、工人配置约束、变量约束:
[0042]
所属约束条件如下:
[0043]
拆卸决策变量约束:
[0044][0045][0046][0047][0048]
任务间关系约束:
[0049][0050][0051][0052][0053][0054]
节拍时间约束:
[0055][0056][0057][0058]
分配约束:
[0059][0060][0061]
工作站配置约束:
[0062][0063][0064][0065]
工人配置约束:
[0066][0067][0068][0069]
变量约束:
[0070][0071]
式中,a为产品类型编号a∈a;ua为产品a的任务集合;c
max
为每个工作站的最大工人容量;pq为产品a的第q种回收状态的概率,q∈qa,qa为产品a的总回收状态集合,如果废旧产品零件的回收状态和新产品的一样,则pq=1;t
iq
为第q种回收状态下,任务i的拆卸处理时间;sd
iw
为工人w执行任务i的技能差异程度,如果工人w执行任务i的技能熟练程度为1,则sd
iw
=1,技能偏离正常水平的程度记为α,sd
iw
∈[1-α,1+α];ψ为一个很大的正数;pa(i)为产品a中任务i的紧前任务集合;xi为任务i的执行状态变量,如果任务i被执行拆卸, xi=1,否则xi=0;z
sw
为工人分配变量,如果工人w被分配到工作站s中,z
sw
=1,否则z
sw
=0; r
ijsw
为任务排列约束,如果任务i和任务j都被安排到工作站s的工人w手中,且任务i先于任务j拆卸,r
ijsw
=1,否则r
ijsw
=0;di为需求变量,如果任务i是需求的,di=1,否则di=0; hi为危害变量,如果任务i是危害的,hi=1,否则hi=0;|.|表示集合的基数运算;
[0072]
式5~8表示在不完全拆卸线中需求和危害任务必须拆除;式9为考虑了回收产品的回收状态和工人技能差异后工人w执行任务i的拆卸时间计算式;式10表示一个工人一次只能执行一个任务;式11~12表示当紧后任务j拆卸时,其紧前任务必须且晚于任务i拆卸;式 13约束不拆卸的任务没有开启时间。式14表示工人w只有完成分配给他的任务i之前的任务才能开始执行任务i;式15表示工人完成分配给他的任务的结束时间不超过他所在工作站的结束时间;式16表示每个工作站中分配给每个工人的任务处理时间之和不能超过一个节拍;式17、18表示当工人拆卸任务i,j时,任务i,j就不能再分配给其他人;式19约束了可开启的最大和最小工作站数量。式20表示当工作站中分配的有任务时,则该工作站开启,反之则关闭;式21约束工作站按顺序依次开启。式22规定了每个工作站的工人数量最大容量;式23表示当任务i要分配给工作站s中的工人w手中时,那么该工人应该位于该工作站中;式24表示有的工人可能不被雇佣;式25为变量约束。
[0073]
s3、求解所述拆卸平衡设计模型,对解集的各个目标进行比例加权求和获得单个具有偏向性的最优拆卸方案。各个目标的加权比例可以根据偏好自由选择。
[0074]
本次求解采用insga-ii算法进行,该算法采用pareto占优方法筛选算法迭代过程中的非劣解,采用超体积(hv,hyper volume)指标评价当前非劣解集分散性和收敛性,即评价每一代获得解的优劣。
[0075]
所述超体积指标计算式如下:
[0076][0077]
其中,e表示获得的非劣解集,e是e中的一个解,f
le
表示解e对应的第l个目标值,r
*
=(r
1*
,r
2*
,r
3*
,r
4*
)表示问题的参考点,表示解e和参考点r
*
之间构成的超体积。
[0078]
请参考图1,该算法包括如下步骤:
[0079]
s31:参数预设;预设的参数包括种群规模m,迭代次数n,储存器大小ne;
[0080]
s32:种群初始化:采用编码方式产生初始种群并计算该种群个体对应的目标值[ct,tc, di,hi],然后采用pareto占优方法更新储存器e;
[0081]
s33:进入迭代程序,令n=1;
[0082]
s34:对种群执行血系繁殖操作,得到新的种群;
[0083]
s35:对s34获得的新种群执行分离进化操作,得到另一个新的种群;
[0084]
s36:对s34和s35获得的新种群以及储存器e执行pareto占优筛选,得到当前迭代次数中的非劣解集;
[0085]
s37:将非劣解集中的四个单目标最小的解作为四个激励解,将该四个激励解和非劣解集作为父母然后执行血系繁殖操作,从而获得更好的新解;
[0086]
s38:对s36获得的非劣解集和s37获得更好新解执行pareto占优筛选从而获得了新的非劣解集,并记为ni;
[0087]
s39:更新储存器e;如果ne《ni,则采用拥挤距离cd对ni进行筛选,否则就直接将ni作为储存器e,并计算储存器e的hv指标;
[0088]
s40:更新种群;如果m《ni,从ni中通过拥挤距离cd筛选m个个体形成新的种群;否则,不够的个体采用编码方式产生新解来补充;
[0089]
s41:判断是否进入下一次迭代:如果n《n,令n=n+1,转到步骤s34进入下一次迭代,否则终止迭代,将储存器e中的解作为所述拆卸平衡设计模型的最优解,并输出这些非劣解对应的非劣方案。
[0090]
对于上述解法,步骤s32和步骤s40均涉及采用编码方式生成新解,具体而言,所述编码方式为三层编码方式,三层编码分别是:拆卸任务序列(disassembly task sequence,简称序列dt)、工作站开启状态序列(station open state sequence,简称序列so)、工人雇佣状态序列(worker employment state sequence,简称序列we),其具体编码策略如下:
[0091]
(6)将待拆卸产品a中任务的优先关系数据化为二进制优先关系矩阵pma=[
…
,p
ij
,
…
],第i行第j列元素p
ij
为决策变量,p
ij
=1表示任务i是任务j的紧前任务,p
ij
=0表示任务i 和任务j没有优先约束关系。
[0092][0093]
(7)将所有产品的优先关系矩阵组合形成合成的优先关系矩阵ipm,各产品的优先关系矩阵pma沿ipm主对角线放置,ipm中的其他元素为0。
[0094][0095]
(8)序列dt的产生过程如下:首先,在ipm矩阵中找到无紧前关系的待拆任务集v
t
(即拆卸任务对应的列向量元素全部为0),判断其中是否有需求零件或者危害零件,如果有危害零件则将危害零件优先选择出来作为整条序列的第一个任务,如果没有危害零件而有需求零件则将需求零件优先选择出来作为整条序列的第一个任务,如果既没有需求零件和者危害零件,则随机从v
t
中选取一个任务作为整条序列的第一个任务,然后将该任务在ipm矩阵中对应的列置为1从而避免该已排列任务在下次寻找v
t
时被再次找到,将该任务在ipm矩阵中对应的行置为0从而消除对其紧后任务的约束;接着,重复第一步依次将任务安排到第二个位置,第三个位置,直至所有任务排列完毕;
[0096]
(9)序列so的序列长度和拆卸任务序列dt一致,设so序列中的元素集合vs={1,2,
…
, |s|},|.|为集合的基数运算;序列so产生过程如下:针对so序列每一个位置从vs中随机选择一个工作站编号进行分配直至序列占满;对上述分配有工作站编号的序列中的所有元素进行升序排列,即得到工作站开启状态序列so。
[0097]
(10)序列we的长度为给定的工人总数量|w|,工人w是否分配到工作站s中采用0或者s来表示,0表示不采用工人w进行拆卸作业,s则表示将工人w分配到工作站s中进行拆卸作业。因此序列we的元素集合v
ws
={0,1,
…
,s,
…
,|w|}.另外由于每个工作站中分配的工人数量最大不超过c
max
,故we的产生过程为:针对we序列每一个元素的位置,从v
ws
中随机选择一个元素,如果该元素为非零元素,则判断该元素的数量,如果数量小于等于c
max
则该元素进行分配且该元素的累计数量加1,如果数量大于c
max
则将该元素不分配且从v
ws
中剔除,然后继续随机选择元素进行上述过程分配直序列占满,这样产生的we是满足要求的序列。
[0098]
在计算目标值时需要用到解码方式,所述解码方式分为两个阶段:一是将拆卸任务和工人分配到工作站中;二是将每个工作站中的任务分配到对应的工人手中。
[0099]
第一阶段解码:首先,找到序列dt中最后一个需求任务和危害任务,两个任务中靠序列后端的任务被选作拆卸终点,该任务及前面的任务为必拆任务序列,而该任务后面的任务不必拆卸,标记拆卸终点任务的位置索引为p
end
;判断序列so中对应位置索引p
end
和p
end
+1的工作站编号,如果两个工作站编号相同,则该工作站需要开启,而该工作站后面的所有
站点不开启,如果两个工作站编号不同,则p
end
+1对应的工作站及后面的所有工作站不开启;根据必拆任务序列和对应索引的序列so的一一对应关系,将必拆任务分配到开启的工作站中去;其次,查找序列we中的元素为开启工作站编号的位置索引,得到的位置索引即为对应每一个开启的工作站所雇佣的工人编号,把雇佣的工人分配到开启的工作站中;
[0100]
第二阶段解码:根据第一阶段解码的结果,将开启的工作站中的任务分配给其中的工人进行拆卸作业,具体过程为:获得当前工作站s的已分配的任务集合v
ts
和工人集合v
ws
,p为任务集合v
ts
中的任务位置编号,将工人集合v
ws
中的所有工人开始作业时间wb置为0,首先分配任务集合v
ts
中的第一个任务i(1),任务i(1)的紧前任务集接着获取拆卸完该任务的最短时间的工人集合r,当r中只有一个工人w时则直接采用该工人拆卸任务i(1),当 r中有多个工人时,应该选取其时薪最小的工人w来拆卸该任务,同时需要更新该任务i(1)和工人w的开始时间tb
i(1)
和wb;接下来,按照上述步骤分配任务集合v
ts
中的其他任务i(p);当任务i(p)存在的紧前任务集时,任务i(p)必须等v
p
中所有任务都拆卸完毕时,它才能开始拆卸;当工作站s中的所有任务都分配完毕时,接着就能够分配下一个工作站中的任务;当所有工作站中的任务全部分配完毕时,即可输出一条三层编码所对应的可行的拆卸方案。
[0101]
步骤s34中所述血系繁殖操作包括如下步骤:
[0102]
随机在母序列dt上截取一段任务编号,将该段任务编号按照在公序列dt上的顺序进行重排并替换到母序列上,这样母序列就产生了新子代dt序列;
[0103]
随机在母序列so上截取一段工作站编号,并将公序列so对应位置的等长的工作站编号替换给母序列,对替换后的母序列进行升序重排产生新子代so序列;
[0104]
随机在母序列we上截取一段包括工作站编号和0的片段,将公序列we对应位置的等长的片段替换给母序列,判断替换后的母序列中工作站编号的数量,如果有工作站编号数量大于c
max
的,则将该工作站编号随机替换成小于c
max
的工作站编号或者0,这样就产生新子代we 序列。
[0105]
步骤s35中所述分离进化操作包括如下步骤:
[0106]
s351、对奇数群中的dt和we序列进行单点交换操作,具体过程为:
[0107]
s3511、从dt序列中随机选择一个任务编号,根据任务的优先关系约束,确定该任务的可交换任务集合,并将该任务和集合中的任意一个任务进行位置互换,从而产生新的dt序列;
[0108]
s3512、随机选择we序列中的两个元素互换位置产生新的we序列。
[0109]
s352、对偶数群中的dt序列进行单点插入操作和we序列进行单点变异操作,具体过程为:
[0110]
从dt序列中随机选择一个任务编号,根据任务的优先关系约束,确定该任务的可插入位置集合,并将该任务插入到位置集合的任意一个位置,即产生新的dt序列;
[0111]
从we序列中随机选择一个元素,如果该元素为0,则将该元素随机替换成小于c
max
的工作站编号,如果该元素为工作站编号,则将该元素随机替换成小于c
max
的工作站编号或者0。
[0112]
s353、针对整个种群中的主要9种so情况设计一种单点变异方式,具体过程为:
[0113]
随机从集合{1,2,,
…
,|s|}中选择一个工作站编号为so序列的变异点,根据该变
异点在so序列中的数量分为大于1、等于1和等于0这三种类型;每一种类型根据变异点编号又可分为三种情况,即变异点为第一个工作站编号1,中间工作站编号和最大工作站编号|s|;
[0114]
针对变异点数量大于1的类型,如果变异点为1,则将序列中的最后一个1变成2即可;如果变异点为中间工作站编号,则将该编号随机加1或减1,并将变异后的序列进行升序重排;如果变异点为|s|,则将序列中的第一个|s|减1即可;
[0115]
针对变异点数量等于1的类型,如果变异点为1,则将so序列中的第二个元素变成1即可;如果变异点为中间工作站编号,则将紧临变异点两侧的任意一个元素变为变异点编号即可;如果变异点为|s|,则将so序列中倒数第二个元素变成|s|即可;
[0116]
针对变异点数量等于0的类型,如果变异点为1,则将so序列中的第一个元素变成1即可;如果变异点为中间工作站编号,则将so序列中任意一个元素变成变异点编号,并将变异后的序列进行升序重排;如果变异点为|s|,则将最后一个元素变为|s|即可。满足上述9种情况的so序列则进行变异,如果不满足则不进行变异;
[0117]
步骤s39和s40涉及拥挤距离cd,所述拥挤距离cd的计算式如下:
[0118][0119]
式中,i为第i个解;j为第j个目标,优化目标总个数为m;f
i,j
表示第i个解对应的第j个目标值;fj表示第j个目标上所有解的目标值集合;di为原始nsga-ii的拥挤距离代号和计算公式,其中d
ij
表示第i个解对应的第j个目标的拥挤距离;li表示第i个解的拥挤距离方差;cdi为第i个解的改进的拥挤距离计算表达式。
[0120]
上面已经记载了整个模型的建立和求解过程,下面我们采用上述模型和算法对所调研的电视机、电脑和打印机进行混合拆卸,并给出具有成本偏向的最佳拆卸排产方案。insga-ii 采用matlab2021b进行编程,计算机运行环境为windows 10系统,cpu i9500,内存8g。
[0121]
三种产品的拆卸任务优先关系如图2-4所示。
[0122]
通过现场监测和统计得到三种产品的回收状态和工人技能差异数据。其中,产品数量 |a|=3,任务总数量|u|=129,工人总数量|w|=30。另外,设定工作站最大开启数量|s|=6,每个工作最大容纳人数c
max
=5,每个工作站的平均能耗成本ocs=0.7。
[0123]
通常情况下,算法的参数设置应该进行正交实验等方法进行获取,但是针对本案例具有大规模任务数量的拆卸,正交实验耗时太长,因此经过调试后将种群规模和解储存器大小设定为1500和40。为了说明激励策略的加强效果和insga
‑ⅱ
的优越性,采用变邻域搜索算法(variable neighbourhood search,vns)、nsga-ii、nsga-iii、模拟退火算法(simulatedannealing,sa)与本发明所提算法(insga-ii)进行对比。为了对几种启发式算
法的结果进行公平对比,计算终止条件设为同一时间。为了确定计算时间,vns、nsga-ii、nsga-iii和 sa以及其带激励策略的改进算法(ivns、insga-ii、insga-iii和isa)分别单次计算15000s 的hv曲线如图5所示。可以看出,计算时间为13000s时,8种算法的hv均基本达到平稳,因此,将计算时间定为t=13000s(≈3.61h)。除8种算法的种群规模m和解储存器大小ne都为1500和40外,vns的参数设置为:初始邻域深度nd0=65,终止邻域深度nde=2,变邻域间隔为gap=ceil(n/(nd
0-nde)),每隔gap代邻域深度降低1,n=1000000以保证运行时间能达到3.61h;sa的参数设置为降温速率k=0.985,马尔科夫链长l=10,终止温度t
end
=25。此外,参考点r
*
设置为[1762,2890,227828,227828],每一个数值表示对应工况下的最坏情况。由图5中几种算法的对比可以看出,所提出的激励策略对于提高解的质量和加快算法的收敛速度有显著作用。每一种算法运算十次,hv的箱型图如图6所示。说明所提激励策略对四种经典算法寻求最优解的能力均有提高,且所提的insga-ii的求解能力优于其他7种算法。
[0124]
对8种算法各10次计算得到的共672个近优解进行pareto筛选可得到90个最优解(近 pareto前沿的解),各算法最优解占比如下表所示。可以看出insga-ii获取最优解的能力明显高于其他7种算法。
[0125]
表1不同算法最优解占比
[0126]
名称insga-iinsga-iiisasainsga-iiinsga-iiiivnsvns比例/%66.676.670026.66000
[0127]
通常情况下,厂商仅需要一个最优的解决方案即可。因为pareto筛选总能保留单目标最小的解,该解为某个目标权重为1,其他目标权重为0的解,而其他非支配解的各目标权重属于[0,1]。基于该原理,对pareto解集的各个目标进行加权就可以获得单个具有偏向性的最优解,加权公式如下所示:
[0128][0129]
其中,为归一化目标的加权和;f
l
为第l个目标值;w
l
为第l个目标的权重。
[0130]
令w1=0.1,w2=0.8,w3=0.025,w4=0.075,90个近pareto解中由insga-ii获得的解 [94.7903,1104.6876,2843.4217,3442.5330]的加权目标值最小,对应的拆卸方案为带有成本偏向的最优排产方案,如图7所示,其中最深灰度色的框表示危害任务、中等灰度色的框为需求任务、最浅灰度色的框为该任务既有危害属性又有需求属性、白色的框表示普通任务。这种方法的优点是,一次性获得最优解集,当权重变化时,简单加权计算就可得到最优方案。而以往对带有目标偏向的最佳方案进行获取时,先把多个目标采用加权转换成单目标进行优化,当各目标值权重变化时,需要重新运行程序,浪费时间也不利于实际排产。
[0131]
从图7可以看出,优化的产线节拍时间为94.7903s,给定的6个工作站中只有4个开启,除1、7、16、18、19、22、23、24、26、28号工人外(w为工人),其他共20名工人被雇佣来执行拆卸任务,四个工作站均达到最大工位容量。
[0132]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明实施例揭露的技术范围内,可轻易想到的变化或
替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1