一种基于深度学习的电气专业配电箱系统图中的配电箱子图识别方法与流程
1.本发明属于配电箱系统图时别技术领域,具体为一种基于深度学习的电气专业配电箱系统图中的配电箱子图识别方法。
背景技术:
2.cad施工图,是表示通过autocad软件将工程项目总体布局,建筑物的外部形状、内部布置、结构构造、内外装修、材料作法以及设备、施工等制作的图样,现有电气专业配电箱系统图纸中配电箱子图获取的技术中,首先需要将配电箱子图中基础图元(图元指的是组成图形的可见基础元素,所对应的就是绘图界面上看得见的实体,比如直线,圆弧,圆等,这些基础元素组成一个个有实际意义的构件,如门、窗)所在的图层推荐到正确的配电箱子图可能出现的构件图层,包括电线、断路器、一体式断路器、漏电断路器、电表、熔断器、热继电器,再通过cad图纸打印服务将所有构建的图元打印到png图片上(图片的宽为11890,高为8410),通过传统图像算法中的膨胀操作(核的大小为20
×
20),使得图片中的直线,多段线等图元的宽度增加,然后将配电箱系统图的尺寸放缩到608
×
608之后送到目标检测模型中进行配电箱子图的位置预测,结果返回配电箱子图的置信度和边框位置,通过置信度阈值调整的筛选处最终预测的配电箱子图的位置。
3.在电气专业配电箱子图时别过程中,由于通过业务逻辑合并时,配电箱子图中构建的识别容易发生错误,从而导致配电箱子图的数量获取和实际有偏差,其边框位置也不精确,从而影响后续配电箱子图各种属性的识别。
技术实现要素:
4.本发明的目的在于提供一种基于深度学习的电气专业配电箱系统图中的配电箱子图识别方法,以解决上述背景技术中提出的问题。
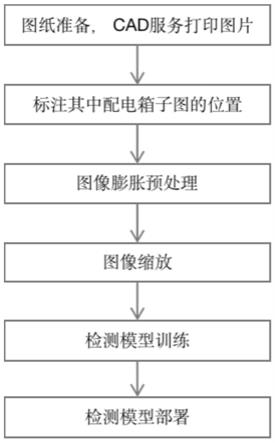
5.为了实现上述目的,本发明提供如下技术方案:一种基于深度学习的电气专业配电箱系统图中的配电箱子图识别方法,包括以下步骤:
6.①
模型训练:
7.1)数据准备:将30-40张图纸通过cad解析获取到图纸上所需的图元信息,并通过cad图纸打印服务生成300-400张配电箱系统图的png图片;
8.2)检查步骤1)中打印服务生成的配电箱系统图,并标注其配电箱子图的位置;
9.3)利用传统图像处理中的膨胀算法将配电箱子图中的基础图元的跨度增加,确保后续图片防缩之后图元不会消失;
10.4)将图片防缩到检测模型所需的指定尺寸,同时将配电箱子图的标注位置也同比例缩小;
11.5)将标记好的数据集送入检测模型进行训练,选取迭代过程中验证集平均准确率最高的一次的参数为后续部署模型的参数;
12.②
模型部署:
13.6)将训练好的模型部署到ai-service中,供ai识图引擎调用。
14.优选的,
①
模型训练里步骤1)所需要的解析图纸的最佳数量为30张,解析图纸的数量可最高可为40张,解析图纸通过cad解析并获取图纸上所需的图元信息,而获取图元信息的过程中需要数量来提供足够多的解析基础,从而使得图元信息获取得更加充分,以30张的数量为标准,如果图中的信息量很大,则需要提高解析图纸的数量,从而更好得获取图元信息。
15.优选的,
①
模型训练里步骤4)中的图片防缩到检测模型的指定尺寸为608
×
608,指定尺寸需要控制为608
×
608,一方面,由于图片在同步防缩过程中各个位置的标注信息也会同步缩小,从而造成图元信息的获取不够及时,而608
×
608的方形尺寸能更好得呈现图元信息,同时还能控制图的大小,同时608
×
608的尺寸有利形成全局的尺寸统一,使得标注更加高效、快捷。
16.优选的,
①
模型训练里步骤1)中的配电箱系统图的png格式具备独立于计算机软硬件环境、可使用压缩以及透明性等优点,png格式图片特点如下:
17.1、使用彩色查找表或者叫做调色板可支持256种颜色的彩色图像;
18.2、流式读/写性能:图像文件格式允许连续读出和写入图像数据,这个特性很适合于在通信过程中生成和显示图像;
19.3、逐次逼近显示:这种特性可使在通信链路上传输图像文件的同时就在终端上显示图像,把整个轮廓显示出来之后逐步显示图像的细节,也就是先用低分辨率显示图像,然后逐步提高它的分辨率;
20.4、透明性:这个性能可使图像中某些部分不显示出来,用来创建一些有特色的图像;
21.5、辅助信息:这个特性可用来在图像文件中存储一些文本注释信息;
22.6、独立于计算机软硬件环境;
23.7、使用无损压缩。
24.优选的,步骤5)中使用的检测模型为yolov4模型,所述检测模型可升级为yolov5模型,yolov4模型通过总结目标trick,通过大量实验找出最佳组合,在进行检测的时候,通过大量的组合以及随机排列,来保证数据获取的随机性,从而提高了训练过程中的精度,yolov4模型几乎总结了上以上三代的所有检测技巧,其检测效率和检测精度都是指数级别的飞跃,因此在对标记好的数据能够有效检测和训练。
25.优选的,步骤5)中检测模型的训练次数5-10次,5次对应数量为300张的图,10次对应数量为400张的图,yolov4模型的训练数量决定了训练出来的模型质量高低,通过增加训练的次数,从而在训练过程中不断的进行选取和迭代,从而可以不停的沿着平均准确率最高的一次参数,并指定该参数为后续部署模型的参数。
26.优选的,步骤1)中的数据准备用图应为随机排列方式上传,通过组合排列的方式形成统计学意义,对于解析图纸的上传需要保持随机的方式,只有这样,才能使得获取的图元信息有序且高效,在cad进行解析的过程中,图纸上传如果集中起来,会造成解析强度过大,加重中央处理器的实时渲染负担,不利于图元信息的获取,随机上传的优势在于可以选择性的等待渲染和图元信息的提取,保证图元信息的顺利展示。
27.优选的,步骤6)中可通过选择不同的训练模型进行ai识图引擎的调用,训练模型的数量控制在4-6个,选用的模型以彼此之间准确率相同为准,步骤5)中训练出来的模型可以部署到ai-service中,供ai识图引擎调用,随着训练模型数量的增加,ai识图引擎的调用速度会更快,从而加快识图效率,而训练模型的数量需要根据识图引擎的最大工作效率进行适配,从而使得数量优势转化为质量优势。
28.本发明的有益效果如下:
29.1、本发明通过使用目标检测的方法来对电气专业配电箱系统图中配电箱子图的识别,通过将指定数量的图纸经过cad解析获取到图纸上所需的元信息并打印出来,通过对图纸检查来进行配电箱子图的位置标志,然后利用膨胀算法增加配电箱子图的基础图元的跨度,从而避免图片在防缩后消失,随后将标记好的数据通过yolov4检测模型进行训练从而获得后续的部署模型参数,通过部署模型至ai-service中,以供ai时别引擎调用,从而有效的解决由于构件繁多,构件合并逻辑复杂且构件识别准确率有限导致配电箱子图数量和位置获取不准确的问题,能有效的提高配电箱子图的识别准确率。
附图说明
30.图1为本发明结构示意图;
31.图2为本发明cad解析图纸的示意图;
32.图3为本发明配电箱子图标注示意图;
33.图4为本发明图片膨胀示意图;
34.图5为本发明模型部署示意图。
具体实施方式
35.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.如图1至图5所示,本发明实施例中,一种基于深度学习的电气专业配电箱系统图中的配电箱子图识别方法,包括以下步骤:
37.①
模型训练:
38.1)数据准备:将30-40张图纸通过cad解析获取到图纸上所需的图元信息,并通过cad图纸打印服务生成300-400张配电箱系统图的png图片;
39.2)检查步骤1)中打印服务生成的配电箱系统图,并标注其配电箱子图的位置;
40.3)利用传统图像处理中的膨胀算法将配电箱子图中的基础图元的跨度增加,确保后续图片防缩之后图元不会消失;
41.4)将图片防缩到检测模型所需的指定尺寸,同时将配电箱子图的标注位置也同比例缩小;
42.5)将标记好的数据集送入检测模型进行训练,选取迭代过程中验证集平均准确率最高的一次的参数为后续部署模型的参数;
43.②
模型部署:
44.6)将训练好的模型部署到ai-service中,供ai识图引擎调用。
45.其中,
①
模型训练里步骤1)所需要的解析图纸的最佳数量为30张,解析图纸的数量可最高可为40张,解析图纸通过cad解析并获取图纸上所需的图元信息,而获取图元信息的过程中需要数量来提供足够多的解析基础,从而使得图元信息获取得更加充分,以30张的数量为标准,如果图中的信息量很大,则需要提高解析图纸的数量,从而更好得获取图元信息。
46.其中,
①
模型训练里步骤4)中的图片防缩到检测模型的指定尺寸为608
×
608,指定尺寸需要控制为608
×
608,一方面,由于图片在同步防缩过程中各个位置的标注信息也会同步缩小,从而造成图元信息的获取不够及时,而608
×
608的方形尺寸能更好得呈现图元信息,同时还能控制图的大小,同时608
×
608的尺寸有利形成全局的尺寸统一,使得标注更加高效、快捷。
47.其中,
①
模型训练里步骤1)中的配电箱系统图的png格式具备独立于计算机软硬件环境、可使用压缩以及透明性等优点,png格式图片特点如下:
48.1、使用彩色查找表或者叫做调色板可支持256种颜色的彩色图像;
49.2、流式读/写性能:图像文件格式允许连续读出和写入图像数据,这个特性很适合于在通信过程中生成和显示图像;
50.3、逐次逼近显示:这种特性可使在通信链路上传输图像文件的同时就在终端上显示图像,把整个轮廓显示出来之后逐步显示图像的细节,也就是先用低分辨率显示图像,然后逐步提高它的分辨率;
51.4、透明性:这个性能可使图像中某些部分不显示出来,用来创建一些有特色的图像;
52.5、辅助信息:这个特性可用来在图像文件中存储一些文本注释信息;
53.6、独立于计算机软硬件环境;
54.7、使用无损压缩。
55.其中,步骤5)中使用的检测模型为yolov4模型,检测模型可升级为yolov5模型,yolov4模型通过总结目标trick,通过大量实验找出最佳组合,在进行检测的时候,通过大量的组合以及随机排列,来保证数据获取的随机性,从而提高了训练过程中的精度,yolov4模型几乎总结了上以上三代的所有检测技巧,其检测效率和检测精度都是指数级别的飞跃,因此在对标记好的数据能够有效检测和训练。
56.其中,步骤5)中检测模型的训练次数5-10次,5次对应数量为300张的图,10次对应数量为400张的图,yolov4模型的训练数量决定了训练出来的模型质量高低,通过增加训练的次数,从而在训练过程中不断的进行选取和迭代,从而可以不停的沿着平均准确率最高的一次参数,并指定该参数为后续部署模型的参数。
57.其中,步骤1)中的数据准备用图应为随机排列方式上传,通过组合排列的方式形成统计学意义,对于解析图纸的上传需要保持随机的方式,只有这样,才能使得获取的图元信息有序且高效,在cad进行解析的过程中,图纸上传如果集中起来,会造成解析强度过大,加重中央处理器的实时渲染负担,不利于图元信息的获取,随机上传的优势在于可以选择性的等待渲染和图元信息的提取,保证图元信息的顺利展示。
58.其中,步骤6)中可通过选择不同的训练模型进行ai识图引擎的调用,训练模型的
数量控制在4-6个,选用的模型以彼此之间准确率相同为准,步骤5)中训练出来的模型可以部署到ai-service中,供ai识图引擎调用,随着训练模型数量的增加,ai识图引擎的调用速度会更快,从而加快识图效率,而训练模型的数量需要根据识图引擎的最大工作效率进行适配,从而使得数量优势转化为质量优势。
59.需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
60.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1