一种基于深度学习的水尺自动读数方法与流程
1.本发明涉及水位测量技术领域,尤其涉及一种基于深度学习的水尺自动读数方法。
背景技术:
2.随着深度学习和图像处理理论和技术的日趋成熟,人工智能技术在很多领域表现出前所未有的优势,例如医学影像、自动驾驶、人脸识别等,极大提升了人们生产效率。现有基于视频图像的水位测量方法主要采用图像处理技术及数学形态学变换识别水尺读数,这些方法在简单、特定的场景中能够表现出良好的性能,但是,一旦切换场景,这些方法就会失效,场景适应性不好且存在通用性不强的问题。
技术实现要素:
3.本发明的目的在于提供一种基于深度学习的水尺自动读数方法,从而解决现有技术中存在的前述问题。
4.为了实现上述目的,本发明采用的技术方案如下:
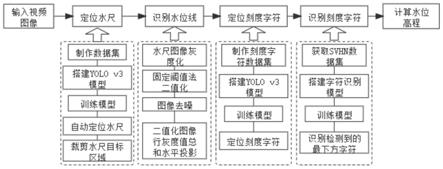
5.一种基于深度学习的水尺自动读数方法,包括如下步骤,
6.s1、利用图像标注软件对收集到的包含水尺的图像样本进行处理,生成水尺图像样本数据集,利用图像数据集训练基于深度学习的目标检测模型,并利用训练好的目标检测模型对输入的视频帧图像中的水尺目标进行定位,获取水尺目标的边界框预测参数,基于水尺目标的边界框预测参数,从视频帧图像中裁剪出水尺区域,得到水尺区域的rgb彩色图像,即水尺图像;
7.s2、对水尺图像进行倾斜校正;
8.s3、对校正后的水尺图像进行预处理,并识别预处理后的水尺图像中的水位线位置;
9.s4、根据提取出的水尺图像制作水尺刻度字符数据集,基于该数据集训练基于深度学习的目标检测模型,并利用训练好的目标检测模型定位水尺图像中的所有刻度字符;
10.s5、搭建并训练字符识别模型,并利用训练好的字符识别模型识别所有刻度字符中位于最下方的刻度字符所表示的实际数值;
11.s6、根据最下方刻度字符所表示的实际数值与水位线位置之间的像素距离,获取最终的水位高程。
12.优选的,步骤s1具体包括如下内容,
13.s11、通过互联网下载和实地拍摄两种方式采集包含水尺目标的图像样本;
14.s12、采用labelimg标注工具用最小外接矩形将图像样本中的每个水尺目标框住,生成相应的xml格式的标签文件,即水尺图像样本数据集;
15.s13、基于tensorflow深度学习框架搭建目标检测模型yolo v3,并利用水尺图像样本数据集训练目标检测模型yolo v3;
v3检测到的刻度字符,当找到第一个刻度字符时停止寻找,通过字符识别模型识别该字符表示的实际数值;
36.s63、根据该字符所表示的实际数值与水位线坐标值之间的像素距离,获取最终的水位高程。
37.本发明的有益效果是:1、通过目标检测模型yolo v3对水尺目标定位,有效排除了复杂背景的干扰,精确地提取出水尺目标区域,提升了方法的场景适应性。2、水位线附近的小型漂浮物(如树叶、藻类等)对水位线位置的识别存在较大影响,采用自上而下地连续阈值判定搜索策略有效消除了局部噪声的影响。3、通过最下方且位于水位线之上的刻度字符所表示的实际数值与水位线位置之间的计算获取最终水位高程的策略,提升了本发明方法的通用性。
附图说明
38.图1是本发明实施例中水尺自动读数方法的原理流程图;
39.图2是本发明实施例中目标检测模型yolo v3的结构示意图。
具体实施方式
40.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
41.如图1和图2所示,本实施例中,提供了一种基于深度学习的水尺自动读数方法,包括如下步骤,
42.s1、利用图像标注软件对收集到的包含水尺的图像样本进行处理,生成水尺图像样本数据集,利用图像数据集训练基于深度学习的目标检测模型,并利用训练好的目标检测模型对输入的视频帧图像中的水尺目标进行定位,获取水尺目标的边界框预测参数,基于水尺目标的边界框预测参数,从视频帧图像中裁剪出水尺区域,得到水尺区域的rgb彩色图像,即水尺图像;
43.s2、对水尺图像进行倾斜校正;
44.s3、对校正后的水尺图像进行预处理,并识别预处理后的水尺图像中的水位线位置;
45.s4、根据提取出的水尺图像制作水尺刻度字符数据集,基于该数据集训练基于深度学习的目标检测模型,并利用训练好的目标检测模型定位水尺图像中的所有刻度字符;
46.s5、搭建并训练字符识别模型,并利用训练好的字符识别模型识别所有刻度字符中位于最下方的刻度字符所表示的实际数值;
47.s6、根据最下方刻度字符所表示的实际数值与水位线位置之间的像素距离,获取最终的水位高程。
48.本实施例中,水尺自动读数方法的原理过程为:通过基于深度学习的目标检测模型yolov3对原始图像中的水尺目标进行定位,有效排除复杂背景的干扰,精确地提取出水尺目标区域;水位线附近的小型漂浮物(如树叶、藻类等)对水位线位置识别存在较大影响,通过自上而下地连续阈值判定的搜索策略有效消除局部噪声的影响;通过基于深度学习的
目标检测模型yolo v3定位水尺图像中所有刻度字符,并裁剪出最下方的刻度字符,输入到基于卷积神经网络的字符识别模型中,获取该刻度字符表示的实际数值,通过该刻度字符的实际数值与水位线位置之间的计算、转换,获取最终水位高程。
49.水尺自动读数方法包括六部分内容,分别为:水尺定位、水尺图像倾斜校正、水位线识别、刻度字符定位、刻度字符识别以及水位高程获取。下面分别针对这六部分内容进行详细的解释说明。
50.一、水尺定位
51.该部分内容对应步骤s1,步骤s1具体包括如下内容,
52.s11、通过互联网下载和实地拍摄两种方式采集包含水尺目标的图像样本;图像样本数量可以根据实际情况进行选择,以便更好的满足实际需求,一般选择为4000张。
53.s12、采用labelimg标注工具用最小外接矩形将图像样本中的每个水尺目标框住,生成相应的xml格式的标签文件,即水尺图像样本数据集;
54.s13、基于tensorflow深度学习框架搭建目标检测模型yolo v3,并利用水尺图像样本数据集训练目标检测模型yolo v3;
55.s14、训练过程中,设置batch size为16,采用adam优化器,超参均为默认值,初始学习率为0.001,每当验证集损失在10个epoch后仍不下降,此时将学习率降低至原来的十分之一,总迭代步数设置为200000步;
56.s15、采用精确度和漏检率作为评价指标,评价目标检测模型yolo v3的性能,当精确度和漏检率达到第一预设标准时,则表示目标检测模型yolo v3训练完成;
57.s16、利用训练好的yolo v3模型自动对视频帧图像中的水尺目标进行定位,获取水尺目标的边界框预测参数;
58.s17、基于水尺目标的边界框预测参数,从视频帧图像中裁剪出水尺区域,得到水尺区域的rgb彩色图像,即水尺图像。
59.本实施例中,互联网下载方式为通过爬虫技术从互联网上下载与水尺相关的图像,并人工筛选出图像质量较好(分辨率、场景等)的图像;实地拍摄方式为通过视频监控设备采集北京某水文检测站点真实业务需求的视频图像,采集到的为1920
×
1080像素的高清图像,每张视频图像中包含1个水尺目标。
60.为了让收集到的样本更具有一般性,并使得网络能够充分学习利用这些样本,采集的样本尽可能来自不同情景;例如,水尺有不同视角、不同光照、不同天气等问题。对于视角和光照等问题,在采集图像时多次调整摄像机角度以及在不同时间段对水尺拍摄,以此来丰富网络模型获取到表示特征。
61.在一台操作系统为windows server 2019 datacenter、编译环境为python 3.7.0、64gb内存、一块tesla t4显卡的计算服务器上对该目标检测模型yolo v3进行训练。
62.评价指标精确度precision和漏检率missed detection rate的计算公式如下:
[0063][0064]
[0065]
其中,tp为检测正确的目标个数;fp为检测为非的目标个数;fn为漏检的目标个数。
[0066]
视频帧图像的获取方式为:通过流媒体技术获取前端视频监控设备的视频流,从视频流中提取视频帧图像。
[0067]
二、水尺图像倾斜校正
[0068]
考虑到摄像机拍摄角度问题,得到的水尺图像中的水尺可能发生倾斜,影响水尺读数的正确性。因此,采用hough变换对提取出的水尺图像进行倾斜校正。
[0069]
三、水位线识别
[0070]
该部分对应步骤s3,步骤s3具体为,利用灰度化、二值化和图像去噪等图像处理技术对校正后的水尺图像进行预处理,并将得到的二值图像在水平方向投影,采用连续阈值的方法识别水位线位置。
[0071]
本实施例中,采用连续阈值的方法识别水位线位置的具体过程为:水位线附近的小型漂浮物(如树叶、藻类等)对水位线位置识别存在较大影响,由于二值化后的水尺图像中水尺和水面区域的水平投影曲线存在较大差异,因此,通过设定一个合适的预设阈值δ,自上而下对行灰度值总和进行遍历搜索,当某一位置连续10次灰度值总和小于预设阈值δ,那么将该位置作为水位线的行坐标。考虑到水面局部倒影、小型漂浮物等的干扰,经多次实验得到,当阈值为一行全白像素灰度值之和的10%时(δ=255
×
列数
×
0.1),水位线检测效果最好。
[0072]
四、刻度字符定位
[0073]
该部分内容对应步骤s4,步骤s4具体包括如下内容,
[0074]
s41、采用labelimg边界框标注软件标注水尺图像中的所有刻度字符,生成水尺刻度字符数据集;水尺图像的数量可以根据实际情况进行选择,一般为4000张,每张水尺图像中都包含多个刻度字符;
[0075]
s42、基于tensorflow深度学习框架搭建目标检测模型yolo v3,并利用水尺刻度字符数据集训练目标检测模型yolo v3;
[0076]
s43、训练时,首先利用公开数据集ms coco上预训练好的模型参数对目标检测模型yolo v3进行初始化;训练过程中,设置batch size为16,采用adam优化器,超参均为默认值,初始学习率为0.001,每当验证集损失在10个epoch后仍不下降,此时将学习率降低至原来的十分之一,总迭代步数设置为200000步;
[0077]
s44、采用精确度和漏检率作为评价指标,评价目标检测模型yolo v3的性能,当精确度和漏检率达到第二预设标准时,则表示目标检测模型yolo v3训练完成;
[0078]
s45、利用训练好的目标检测模型yolo v3定位水尺图像中的所有刻度字符。
[0079]
本实施例中,在一台操作系统为windows server 2019 datacenter、编译环境为python 3.7.0、64gb内存、一块tesla t4显卡的计算服务器上对该目标检测模型yolo v3进行训练。
[0080]
评价指标精确度precision和漏检率missed detection rate的计算公式如下:
[0081]
[0082][0083]
其中,tp为检测正确的目标个数;fp为检测为非的目标个数;fn为漏检的目标个数。
[0084]
五、刻度字符识别
[0085]
该部分内容对应步骤s5,步骤s5具体包括如下内容,
[0086]
s51、利用卷积神经网络快速搭建字符识别模型,基于svhn数据集训练字符识别模型;
[0087]
s52、字符识别模型训练的过程中,设置batch size为96,采用adadelta优化器优化,总迭代次数设置为2000次;
[0088]
s53、采用准确率和分类错误率作为评价指标,评价字符识别模型的性能,当准确率和分类错误率达到第三预设标准时,则表示字符识别模型训练完成;
[0089]
s54、利用训练好的字符识别模型,识别步骤s5的所有刻度字符中的最下方且位于水位线之上的刻度字符所表示的实际数值。
[0090]
评价指标准确率accuracy、分类错误率error的计算公式如下:
[0091]
accuracy=tp/num
[0092]
error=fp/num
[0093]
其中,tp为被正确分类的图像数量;num为测试图像总数;fp为被错误分类的图像数量。
[0094]
六、水位高程获取
[0095]
该部分内容对应步骤s6,步骤s6具体为,
[0096]
s61、以水尺图像的左上角为原点坐标(0,0),右上角方向为横轴(x轴)正方向,左下角方向为纵轴(y轴)正方向,得到水位线的纵轴坐标值;水位线与原点坐标的垂直距离记为y
wl
;
[0097]
s62、从水位线位置开始,沿着纵轴反方向依次向上寻找通过目标检测模型yolo v3检测到的刻度字符,当找到第一个刻度字符时停止寻找,并将其纵坐标记为y
num
,高度记为h
num
;通过字符识别模型识别该字符表示的实际数值,记为num;
[0098]
s63、根据该字符所表示的实际数值与水位线坐标值之间的像素距离,获取最终的水位高程。
[0099]
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
[0100]
本发明提供了一种基于深度学习的水尺自动读数方法,该方法通过目标检测模型yolo v3对水尺目标定位,有效排除了复杂背景的干扰,精确地提取出水尺目标区域,提升了方法的场景适应性。水位线附近的小型漂浮物(如树叶、藻类等)对水位线位置的识别存在较大影响,采用自上而下地连续阈值判定搜索策略有效消除了局部噪声的影响。该方法通过最下方且位于水位线之上的刻度字符所表示的实际数值与水位线位置之间的计算获取最终水位高程的策略,提升了本发明方法的通用性。
[0101]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1