违法广告识别方法、装置和电子设备与流程
1.本技术涉及互联网广告监测领域,且更为具体地,涉及一种违法广告识别方法、装置和电子设备。
背景技术:
2.近年来,随着互联网技术的发展,各类广告联盟和电商平台兴起,与之相伴随的是互联网广告问题的凸显。相较于传统广告,互联网广告发布便捷、形式多样、精准投放,违法广告藏身其中,隐蔽性强,传统手段难以发现、追踪和查处。因此,对互联网广告进行监管是非常有必要的。
3.对互联网广告中可能存在的违规词汇进行识别是互联网广告监管的重要内容。但是,互联网网络广告数量巨大、存在形式多样(有些广告词并非以文本数据格式出现,例如,以文本图像的形式出现),难以采用人工方式逐条监管和审查。
4.因此,期待一种用于互联网广告的违法广告自动识别方案。
技术实现要素:
5.为了解决上述技术问题,提出了本技术。本技术的实施例提供了一种违法广告识别方法、装置和电子设备,其从互联网网站抓取网页广告数据并通过文本识别技术提取出所述网页广告数据中的广告词,并以语义理解模型对所述广告词进行智能处理以判断广告词是否为违法广告。
6.根据本技术的一个方面,提供了一种违法广告识别方法,其包括:
7.从互联网网站抓取网页广告数据;
8.对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词;
9.对所述广告词进行分词处理并将分词后的每个词输入词嵌入模型以获得词向量序列;以及
10.将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果。
11.在上述违法广告识别方法中,从初始值开始按照预设的更新方式对用于滚动所述目标窗口的滚动条的值进行多次更新,包括:响应于检测到允许通过所述终端的操作系统提供的系统层调用接口对所述滚动条的值进行修改,通过所述系统层调用接口从初始值开始按照预设的更新方式对所述滚动条的值进行多次更新。
12.在上述违法广告识别方法中,从互联网网站抓取网页广告数据,包括:使用爬虫工具抓取不同地域的电脑端和移动端上的所述互联网网站上的网页广告数据,其中,所述互联网网站包括注册地为辖区的门户网站、电商网站、视频网站、搜索引擎网站、自有网站、广告联盟、移动互联网站、手机应用和微信公众号。
13.对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词,包括:定位所述网页广告数据中的文本区域;对所述文本区域进行图像校正;以及,对经图像校正后的所述文本区域进行行列分割并识别每一行中的广告词以获得所述网页广告数据
中的广告词。
14.在上述违法广告识别方法中,定位所述网页广告数据中的文本区域,包括:基于文字颜色和/或亮度和/或边缘信息进行聚类以将所述网页广告数据划分为文本区域和非文本区域;其中,对所述文本区域进行图像校正,包括:对所述文本区域进行旋转变换和仿射变换;其中,对经图像校正后的所述文本区域进行行列分割并识别每一行中的广告词以获得所述网页广告数据中的广告词,包括:对所述文本区域进行二值化处理;对二值化处理后的所述文本区域进行投影以确定行列分割点;以及,识别每一行中的广告词以获得所述网页广告数据的广告词。
15.在上述违法广告识别方法中,将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果,包括:
16.训练阶段,包括:
17.获取训练文本,所述训练文本为广告词;
18.在将所述广告词转化为词向量序列后通过双向长短时记忆神经网络模型以获得特征向量序列,其中,所述特征向量序列中的每一特征向量对应于所述广告词中的每一个词;
19.将与所述训练文本对应的真实违规词作为参考词通过所述词嵌入模型和所述双向长短时记忆神经网络模型以获得参考特征向量;
20.计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度以获得与所述广告词的每个词对应的(特征向量,相似度)的键值对和与所述广告词对应的相似度向量;
21.将所述特征向量序列中的每个特征向量分别通过分类器,以从所述分类器的最后一层全连接层得到每个所述特征向量对应的解码向量;
22.计算所述解码向量和与其对应的所述特征向量之间的第一交叉熵值和所述解码向量和与其对应的相似度之间的第二交叉熵值,并计算所述第一交叉熵函数值和所述第二交叉熵值之间的加权和作为所述特征向量的加权交叉熵值,以获得由每个所述特征向量对应的加权交叉熵值组成的交叉熵向量;以及
23.计算所述相似度向量与所述交叉熵向量之间的距离作为损失函数值来训练所述分类器和所述双向长短时记忆模型;以及
24.推断阶段,包括:
25.将所述词向量序列通过经训练阶段训练完成的所述双向长短时记忆模型以获得特征向量序列;以及
26.将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果。
27.在上述违法广告识别方法中,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度,包括:
28.计算所述参考特征向量与所述特征向量序列中每个特征向量之间的l1 距离或l2距离或余弦距离作为所述相似度。
29.在上述违法广告识别方法中,将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果,包括:使用所述分类器的多个全连接层对所述特
征向量序列中的每个特征向量进行全连接编码以获得解码向量;以及,将所述解码向量输入所述分类器的softmax分类函数以获得所述解码向量对应的词属于违规词的概率。
30.根据本技术的另一方面,提供了一种违法广告识别装置,其包括:
31.抓取模块,用于从互联网网站抓取网页广告数据;
32.文本识别模块,用于对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词;
33.词嵌入模块,用于对所述广告词进行分词处理并将分词后的每个词输入词嵌入模型以获得词向量序列;以及
34.识别模块,用于将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果。
35.根据本技术的再一方面,提供了一种电子设备,包括:处理器;以及,存储器,在所述存储器中存储有计算机程序指令,所述计算机程序指令在被所述处理器运行时使得所述处理器执行如上所述的违法广告识别方法。
36.根据本技术的又一方面,提供了一种计算机可读介质,其上存储有计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行如上所述的违法广告识别方法。
37.与现有技术相比,本技术提供的违法广告识别方法、装置和电子设备,其从互联网网站抓取网页广告数据并通过文本识别技术提取出所述网页广告数据中的广告词,并以语义理解模型对所述广告词进行智能处理以判断广告词是否为违法广告。
附图说明
38.通过结合附图对本技术实施例进行更详细的描述,本技术的上述以及其他目的、特征和优势将变得更加明显。附图用来提供对本技术实施例的进一步理解,并且构成说明书的一部分,与本技术实施例一起用于解释本技术,并不构成对本技术的限制。在附图中,相同的参考标号通常代表相同部件或步骤。
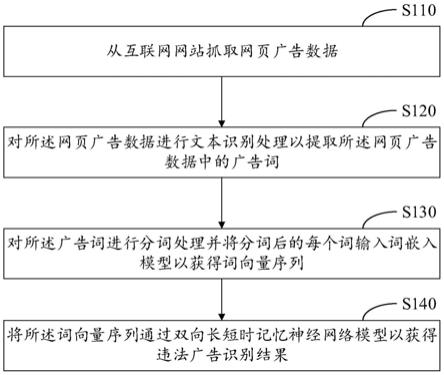
39.图1图示了根据本技术实施例的违法广告识别方法的流程图。
40.图2图示了根据本技术实施例的所述违法广告识别方法中对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词的流程图。
41.图3图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的流程图之一。
42.图4图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的训练阶段的架构示意图。
43.图5图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的流程图之二。
44.图6图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的推断阶段的架构示意图。
45.图7图示了根据本技术实施例的所述违法广告识别方法中将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果的流程图。
46.图8图示了根据本技术实施例的违法广告识别装置的框图。
47.图9图示了根据本技术实施例的所述违法广告识别装置的文本识别模块的框图。
48.图10图示了根据本技术实施例的所述违法广告识别装置的识别模块的框图。
49.图11图示了根据本技术实施例的电子设备的框图。
具体实施方式
50.下面,将参考附图详细地描述根据本技术的示例实施例。显然,所描述的实施例仅仅是本技术的一部分实施例,而不是本技术的全部实施例,应理解,本技术不受这里描述的示例实施例的限制。
51.申请概述
52.如上所述,近年来,随着互联网技术的发展,各类广告联盟和电商平台兴起,与之相伴随的是互联网广告问题的凸显。相较于传统广告,互联网广告发布便捷、形式多样、精准投放,违法广告藏身其中,隐蔽性强,传统手段难以发现、追踪和查处。因此,对互联网广告进行监管是非常有必要的。
53.对互联网广告中可能存在的违规词汇进行识别是互联网广告监管的重要内容。但是,互联网网络广告数量巨大、存在形式多样(有些广告词并非以文本数据格式出现,例如,以文本图像的形式出现),难以采用人工方式逐条监管和审查。
54.因此,期待一种用于互联网广告的违法广告自动识别方案。
55.在本技术的技术方案中,首先通过爬虫技术从互联网网站抓取网页广告数据。因一些广告词并非以文本的形式出现而是以文本图像的形式出现,因此,在本技术的一些示例中,对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词。然后,以语义理解模型对所述广告词进行智能处理以判断广告词是否为违法广告。
56.在本技术的技术方案中,依据新修订的《广告法》《互联网广告管理暂行办法》《医疗广告管理办法》等100余部法律法规中提取违规种子词汇,如:保证治愈、成功率100%等等,再利用同义词扩充种子词汇和语义相似度过滤扩充词汇,得到网络广告违规词库。
57.例如,《广告法》第九条第三项——发布广告使用“国家级”、“最高级”、“最佳”等用语属于违法广告,此外在广告此中出现最强大的专业面试辅导阵容、这套方法最适合自学人员、最新最前沿的高考资讯、全网最系统影视后期教程、教授最具市场潜力的课程内容、最专业的国际学校备考机构、全球最优秀的幼儿资源、史上最全题库、教你最正宗的营销理论与最新营销玩法、最好的网创项目、最有效的方式去做、最好的美国mba教育资源、顶级师资、最具影响力远程教育品牌、全国最完善的财务总监课后学习体系、业界最全教学体系、0基础2月时间现日收益、中国顶级养生培训实训基、战胜最老道的会计、考试一天,当天拿证、签约一次过、最优的学历提升方案、第一家提供最全面的学历提升的服务中心、挣最高的工资、全球最强师资、中国i t教育第一品牌、史上最完整、最专业的工程造价、最靠谱的电商培训、顶级师资配备、做中国最有良心的高端教育机构、金融理财培训服务第一品牌、中国记忆力教育第一品牌、职业培训第一品牌、挖掘机维修培训第 1品牌、最新最实用微创美容课程、最全的地理五诀讲座、传授最实用、最有影响力的名师名名家讲、家长满意度最高、通过率持续第1之类的都是不合适的。
58.在构建好网络广告违规词库后,基于自然语言的规则,在字符串匹配的基础上,结合上下文语义信息识别网络广告中的违规词。
59.在违法广告的识别上,针对包含禁用词类型的广告,对传统的关键词匹配技术进行改进,提出基于上下文的逻辑关键词匹配技术。针对包含违法描述句子型的广告,结合广告文本较短以及语义缺失等特点,提出基于潜在概率语义分析的违法广告识别模型。对网络广告中可能存在的违规描述语句进行识别,针对网络广告文本较短以及语义缺失等问题,提出利深度学习工具词嵌入模型,(例如,word2vec)和长短时记忆神经网络模型(例如,双向长短时记忆神经网络模型,双向lstm)的识别方法。
60.首先考虑到传统文本表示方法易造成数据表示稀疏及维度灾难问题,采用词嵌入模型对网络广告进行包含语义的词向量、句向量表示。然后对于向量化后的文本,采用专门处理序列化数据的双向长短时记忆神经网络模型进行网络广告违规语句判定。本方法能够有效识别网络广告违规语句,特别是对违规广告语句中字形相似、词语语义相似的违规类型识别准确率高。
61.基于此,本技术提出了一种违法广告识别方法,其包括:从互联网网站抓取网页广告数据;对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词;对所述广告词进行分词处理并将分词后的每个词输入词嵌入模型以获得词向量序列;以及,将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果。
62.在介绍了本技术的基本原理之后,下面将参考附图来具体介绍本技术的各种非限制性实施例。
63.示例性方法
64.图1图示了根据本技术实施例的违法广告识别方法的流程图。如图1所示,根据本技术实施例的违法广告识别方法,包括:s110,从互联网网站抓取网页广告数据;s120,对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词;s130,对所述广告词进行分词处理并将分词后的每个词输入词嵌入模型以获得词向量序列;以及,s140,将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果。
65.在步骤s110中,从互联网网站抓取网页广告数据。相应地,在本技术实施例中,使用爬虫工具抓取不同地域的电脑端和移动端上的所述互联网网站上的网页广告数据,其中,所述互联网网站包括注册地为辖区的门户网站、电商网站、视频网站、搜索引擎网站、自有网站、广告联盟、移动互联网站、手机应用和微信公众号。并且,所述网页广告数据包括图片、文字、图片+ 文字等。
66.在步骤s120中,对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词。由于广告词以图片形式存在,因此,需对所述网页广告数据进行文本识别处理以提取出所述网页广告数据中的广告词。在本技术一个具体的示例中,采用ocr技术(optical character recognition,光学字符识别)对图片的内容和文本在时间上实现毫秒级识别,从而对于没问题的广告数据可以定期丢弃以节省资源,而对于初步判断有问题的广告数据,则保存证据。
67.通常ocr技术可以分为版面分析
→
预处理
→
行列分割
→
字符识别
→
后处理识别校正。
68.以输入的网页广告数据为图像且图像是一页文本为例,那么识别时的第一件事情是判断页面上的文本朝向,因为得到的这页文档往往都不是很完美的,很可能带有倾斜或者污渍,那么要做的第一件事就是进行图像预处理,做角度矫正和去噪。然后要对文档版面
进行分析,进每一行进行行分割,把每一行的文字切割下来,最后再对每一行文本进行列分割,切割出每个字符,将该字符送入训练好的ocr识别模型进行字符识别,得到结果。但是模型识别结果往往是不太准确的,需要对其进行识别结果的矫正和优化,比如可以设计一个语法检测器,去检测字符的组合逻辑是否合理。比如,考虑单词 because,设计的识别模型把它识别为8ecause,那么就可以用语法检测器去纠正这种拼写错误,并用b代替8并完成识别矫正。这样子,整个ocr流程就走完了。
69.整个过程中,关键在于预处理阶段,预处理阶段的质量直接决定了最终的识别效果,因此这里详细介绍下预处理阶段,其中,预处理阶段中包含了三步:
70.(1)定位图片中的文字区域,而文字检测主要基于连通域分析的方法,主要思想是利用文字颜色、亮度、边缘信息进行聚类的方式来快速分离文字区域与非文字区域,较为流行的两个算法分别是:最大极值稳定区域(mser) 算法及笔画宽度变换(swt)算法,而在自然场景中因受到光照强度、图片拍摄质量和类文字背景的干扰,使得检测结果中包含非常多的非文字区域,而目前从候选区域区分出真正文字区域主要两种方法,用规则判断或轻量级的神经网络模型进行区分;
71.(2)文本区域图像矫正,主要基于旋转变换和仿射变换;
72.(3)行列分割提取出单字,这一步利用文字在行列间存在间隙的特征,通过二值化并在投影后找出行列分割点,当在文字与背景的区分度较好时,效果很好,而拍摄的图片中光照、摄像质量的影响,并且文字背景难以区分时,常造成错误分割的情况。
73.也就是,在本技术实施例中,如图2所示,对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词,包括:s210,定位所述网页广告数据中的文本区域;s220,对所述文本区域进行图像校正;以及,s230,对经图像校正后的所述文本区域进行行列分割并识别每一行中的广告词以获得所述网页广告数据中的广告词。
74.值得一提的是,传统的ocr冗长的处理流程以及大量人工规则的存在,使得每步的错误会不断累积,而使得最终识别结果虽然能满足要求,但可以对传统的ocr技术进行改进。进一步地,本技术还提出了一种基于深度学习的ocr技术。
75.从技术流程上来说,主要分为两步,首先是检测出图像中的文本行,接着进行序列识别。可见,基于深度学习的ocr识别框架相比于传统ocr识别框架,减少了三个步骤,降低了因误差累积对最终识别结果的影响。
76.值得一提的是,如果所述网页广告数据为视频,则应可以理解,在视屏广告、互动广告、富媒体广告的识别是逐帧分解成图片来进行识别。
77.在步骤s130中,对所述广告词进行分词处理并将分词后的每个词输入词嵌入模型以获得词向量序列。这里,考虑到传统文本表示造成数据表示稀疏及维度灾难问题,采用词嵌入模型对所述网页广告数据的广告词进行包含词向量和句向量表示。
78.具体地,在本技术一个具体的示例中,采用word2vec词嵌入模型对所述网页广告数据的广告词进行包含语义的词向量、句向量表示,其过程包括首先对所述广告词进行分词处理,然后,将分词后的每个词通过所述 word2vec词嵌入模型以获得词向量序列,其中,所述词向量序列中各个词向量对应于所述广告词中的各个词。
79.在步骤s140中,将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果。
80.在一个具体示例中,可以将通过双向lstm模型获得的特征向量的序列直接级联后进行分类,以确定文本是否违规。而在另一具体示例中,还可以进一步对于通过双向lstm模型获得的特征向量的序列中的每个特征向量进行标签标记,以标注与该特征向量对应的词的违规概率,并进而基于每个词的违规概率确定文本是否违规,这样,可以通过细粒度的分类来提高识别准确性。
81.在后一方法中,由于是针对与每个词对应的特征向量进行标签标记,也就是,如果将双向lstm模型+分类器模型考虑为编码器+解码器结构,则编码器是进行全局编码,而解码器则是进行局部解码,因此,为了增强编码器和解码器之间的全局-局部一致性,在该方法中进一步引入编码器注意力机制。
82.具体地,由于在本技术的上述方案中已经建立了违规词的词库,因此可以在双向lstm模型+分类器模型的训练过程当中,将与训练文本对应的真实违规词作为参考词,并同样通过双向lstm模型得到参考特征向量。然后,基于编码器注意力机制,计算参考特征向量与双向lstm模型得到的训练文本的每个词对应的特征向量之间的相似度,这样,一方面可以得到与每个词对应的(特征向量,相似度)的键值对,另一方面可以得到与训练文本对应的相似度向量。
83.并且,在将每个特征向量输入分类器时,可以从分类器的最后一层全连接层得到解码向量,接下来,计算该解码向量分别与特征向量的第一交叉熵值和与相似度的第二交叉熵值的加权和,并将每个特征向量的加权交叉熵值组成为交叉熵向量,用于表示解码器的隐状态的局部一致性。进一步地,通过计算相似度向量和交叉熵向量之间的距离并作为损失函数值来训练分类器,实质上是以参考向量与编码器的输出向量序列的相似性来突出输出向量序列中的上下文相关部分,并以所有编码器状态(表现为上述键值对)和解码器的隐状态(表现为交叉熵向量)来更新解码器的参数,从而改善编码器和解码器之间的全局-局部一致性。
84.具体地,根据本技术实施例的所述违法广告识别方法的识别过程包括训练阶段和使用阶段,如图3和图5所示。
85.图3图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的流程图之一。
86.如图3所示,在本技术实施例中,所述识别过程的训练阶段,包括步骤; s310,获取训练文本,所述训练文本为广告词;s320,在将所述广告词转化为词向量序列后通过双向长短时记忆神经网络模型以获得特征向量序列,其中,所述特征向量序列中的每一特征向量对应于所述广告词中的每一个词; s330,将与所述训练文本对应的真实违规词作为参考词通过所述词嵌入模型和所述双向长短时记忆神经网络模型以获得参考特征向量;s340,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度以获得与所述广告词的每个词对应的(特征向量,相似度)的键值对和与所述广告词对应的相似度向量;s350,将所述特征向量序列中的每个特征向量分别通过分类器,以从所述分类器的最后一层全连接层得到每个所述特征向量对应的解码向量;s360,计算所述解码向量和与其对应的所述特征向量之间的第一交叉熵值和所述解码向量和与其对应的相似度之间的第二交叉熵值,并计算所述第一交叉熵函数值和所述第二交叉熵值之间的加权和作为所述特征向量的加权交叉熵值,以获得由每个所述特征向量对应的加权交叉熵值组成的交叉熵向量;
s370,计算所述相似度向量与所述交叉熵向量之间的距离作为损失函数值来训练所述分类器和所述双向长短时记忆模型。
87.图4图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的训练阶段的架构示意图。如图4所示,在根据本技术实施例的所述识别过程的训练阶段的架构中,首先在将所述广告词(例如,如图4中所示意的t)通过词嵌入模型(例如,如图4中所示意的we)转化为词向量序列(例如,如图 4中所示意的vs)后通过双向长短时记忆神经网络模型(例如,如图4中所示意的dlstm)以获得特征向量序列(例如,如图4中所示意的fs),其中,所述特征向量序列中的每一特征向量对应于所述广告词中的每一个词。然后,将与所述训练文本对应的真实违规词作为参考词(例如,如图4中所示意的 r)通过所述词嵌入模型和所述双向长短时记忆神经网络模型以获得参考特征向量(例如,如图4中所示意的rv)。接着,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度以获得与所述广告词的每个词对应的(特征向量,相似度)的键值对和与所述广告词对应的相似度向量 (例如,如图4中所示意的vs)。然后,将所述特征向量序列中的每个特征向量分别通过分类器,以从所述分类器的最后一层全连接层得到每个所述特征向量对应的解码向量(例如,如图4中所示意的ve)。接着,计算所述解码向量和与其对应的所述特征向量之间的第一交叉熵值和所述解码向量和与其对应的相似度之间的第二交叉熵值,并计算所述第一交叉熵函数值和所述第二交叉熵值之间的加权和作为所述特征向量的加权交叉熵值,以获得由每个所述特征向量对应的加权交叉熵值组成的交叉熵向量(例如,如图4中所示意的vc)。最终,计算所述相似度向量与所述交叉熵向量之间的距离作为损失函数值来训练所述分类器和所述双向长短时记忆模型。
88.图5图示了根据本技术实施例的所述违法广告识别方法中将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的流程图之二。如图5所示,在本技术实施例中,所述识别过程的推断阶段,包括步骤:s410,将所述词向量序列通过经训练阶段训练完成的所述双向长短时记忆模型以获得特征向量序列;s420,将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果。
89.图6图示了图示了根据本技术实施例的所述违法广告识别方法中所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果的推断阶段的架构示意图。如图6所示,在根据本技术实施例的所述识别过程的推断阶段的架构中,首先将由词嵌入模型生成的词向量序列(例如,如图6 中所示意的vs)通过经训练阶段训练完成的所述双向长短时记忆模型(例如,如图6中所示意的dlstm)以获得特征向量序列(例如,如图6中所示意的fs);然后,将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果。
90.更具体地,在所述训练阶段的步骤s310中,获取训练文本,所述训练文本为广告词。
91.更具体地,在所述训练阶段的步骤s320中,在将所述广告词转化为词向量序列后通过双向长短时记忆神经网络模型以获得特征向量序列,其中,所述特征向量序列中的每一特征向量对应于所述广告词中的每一个词。也就是,将所述训练文本通过词嵌入模块和所述双向长短时记忆神经网络后获得训练特征向量序列。
92.更具体地,在所述训练阶段的步骤s330中,将与所述训练文本对应的真实违规词作为参考词通过所述词嵌入模型和所述双向长短时记忆神经网络模型以获得参考特征向量。应可以理解,由于已经构建了违规词的词库,因此,可以在所述双向长短时记忆模型和所述分类器模型的训练过程当中,将与所述训练文本对应的真实违规词作为参考词,并同样通过所述词嵌入模型和所述双向长短时记忆神经网络模型以获得所述参考特征向量。
93.更具体地,在所述训练阶段的步骤s340中,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度以获得与所述广告词的每个词对应的(特征向量,相似度)的键值对和与所述广告词对应的相似度向量。也就是,基于编码器注意力机制,计算参考特征向量与双向lstm模型得到的训练文本的每个词对应的特征向量之间的相似度,这样,一方面可以得到与每个词对应的(特征向量,相似度)的键值对,另一方面可以得到与训练文本对应的相似度向量。
94.在本技术一个具体的示例中,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度,包括:计算所述参考特征向量与所述特征向量序列中每个特征向量之间的l1距离作为所述相似度。这里,l1距离表示所述参考特征向量和所述特征向量序列中每个特征向量之间的曼哈顿距离,可以从数值维度上反映出所述参考特征向量与所述特征向量序列中每个特征向量之间的特征差异。
95.在本技术一个具体的示例中,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度,包括:计算所述参考特征向量与所述特征向量序列中每个特征向量之间的l2距离作为所述相似度。这里,l2距离表示所述参考特征向量和所述特征向量序列中每个特征向量之间的欧式距离,可以从空间距离维度上反映出所述参考特征向量与所述特征向量序列中每个特征向量之间的特征差异。
96.在本技术一个具体的示例中,计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度,包括:计算所述参考特征向量与所述特征向量序列中每个特征向量之间的余弦距离作为所述相似度。这里,余弦距离表示所述参考特征向量和所述特征向量序列中每个特征向量之间的欧式距离,可以从角度维度上反映出所述参考特征向量与所述特征向量序列中每个特征向量之间的特征差异。
97.值得一提的是,在本技术实施例中,采用l1距离、l2距离或者余弦距离可基于实际情况作出调整,优选地,所述相似度以余弦距离进行表示。
98.更具体地,在所述训练阶段的步骤s350中,将所述特征向量序列中的每个特征向量分别通过分类器,以从所述分类器的最后一层全连接层得到每个所述特征向量对应的解码向量。在本技术实施例中,所述分类器包括多个全连接层,所述多个全连接层用于对每个特征向量进行解码以获得解码向量。
99.更具体地,在所述的训练阶段的步骤s360中,计算所述解码向量和与其对应的所述特征向量之间的第一交叉熵值和所述解码向量和与其对应的相似度之间的第二交叉熵值,并计算所述第一交叉熵函数值和所述第二交叉熵值之间的加权和作为所述特征向量的加权交叉熵值,以获得由每个所述特征向量对应的加权交叉熵值组成的交叉熵向量。也就是,在将每个特征向量输入分类器时,可以从分类器的最后一层全连接层得到解码向量,接下来,计算该解码向量分别与特征向量的第一交叉熵值和与相似度的第二交叉熵值的加权和,并将每个特征向量的加权交叉熵值组成为交叉熵向量,用于表示解码器的隐状态的局
部一致性。
100.更具体地,在所述训练阶段的步骤s370中,计算所述相似度向量与所述交叉熵向量之间的距离作为损失函数值来训练所述分类器和所述双向长短时记忆模型。也就是,进一步地,通过计算相似度向量和交叉熵向量之间的距离并作为损失函数值来训练分类器,实质上是以参考向量与编码器的输出向量序列的相似性来突出输出向量序列中的上下文相关部分,并以所有编码器状态(表现为上述键值对)和解码器的隐状态(表现为交叉熵向量)来更新解码器的参数,从而改善编码器和解码器之间的全局-局部一致性。
101.更具体地,在所述推断阶段的步骤s410中,将所述词向量序列通过经训练阶段训练完成的所述双向长短时记忆模型以获得特征向量序列。也就是,将由所述待监测的广告词通过词嵌入模型所生成的所述词向量序列通过经训练阶段训练完成的所述双向长短时记忆模型,以通过所述双向长短时记忆模型对所述特征向量序列进行基于上下文的全局编码以获得所述特征向量序列。
102.更具体地,在所述推断阶段的步骤s420中,将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果。具体地,将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果的过程,包括首先使用所述分类器的多个全连接层对所述特征向量序列中的每个特征向量进行全连接编码以获得解码向量。然后,将所述解码向量输入所述分类器的softmax分类函数以获得所述解码向量对应的词属于违规词的概率。最终基于所述概率与预设阈值之间的比较,生成所述违法广告识别结果,例如,当所述概率大于预设阈值时,所述违法广告识别结果为所述网页广告数据为违法广告,存在违法广告词。
103.图7图示了根据本技术实施例的所述违法广告识别方法中将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果的流程图。如图7所示,在本技术实施例中,将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果,包括:s510,使用所述分类器的多个全连接层对所述特征向量序列中的每个特征向量进行全连接编码以获得解码向量;以及,s520,将所述解码向量输入所述分类器的softmax分类函数以获得所述解码向量对应的词属于违规词的概率。
104.综上,基于本技术实施例的违法广告识别方法被阐明,其从互联网网站抓取网页广告数据并通过文本识别技术提取出所述网页广告数据中的广告词,并以语义理解模型对所述广告词进行智能处理以判断广告词是否为违法广告。
105.示例性装置
106.图8图示了根据本技术实施例的违法广告识别装置的框图。
107.如图8所示,根据本技术实施例的违法广告识别装置800,包括:抓取模块810,用于从互联网网站抓取网页广告数据;文本识别模块820,用于对所述网页广告数据进行文本识别处理以提取所述网页广告数据中的广告词;词嵌入模块830,用于对所述广告词进行分词处理并将分词后的每个词输入词嵌入模型以获得词向量序列;以及,识别模块840,用于将所述词向量序列通过双向长短时记忆神经网络模型以获得违法广告识别结果。
108.在一个示例中,在上述违法广告识别装置800中,所述抓取模块810,进一步用于使用爬虫工具抓取不同地域的电脑端和移动端上的所述互联网网站上的网页广告数据,其中,所述互联网网站包括注册地为辖区的门户网站、电商网站、视频网站、搜索引擎网站、自
有网站、广告联盟、移动互联网站、手机应用和微信公众号。
109.在一个示例中,在上述违法广告识别装置800中,如图9所示,所述文本识别模块820,包括:文本区域定位单元821,用于定位所述网页广告数据中的文本区域;文本区域校正单元822,用于对所述文本区域进行图像校正;以及,文本识别单元823,用于对经图像校正后的所述文本区域进行行列分割并识别每一行中的广告词以获得所述网页广告数据中的广告词。
110.在一个示例中,在上述违法广告识别装置800中,所述文本区域定位单元821,进一步用于基于文字颜色和/或亮度和/或边缘信息进行聚类以将所述网页广告数据划分为文本区域和非文本区域;所述文本区域校正单元822,进一步用于对所述文本区域进行旋转变换和仿射变换;以及,所述文本识别单元823,进一步用于对所述文本区域进行二值化处理;对二值化处理后的所述文本区域进行投影以确定行列分割点;以及,识别每一行中的广告词以获得所述网页广告数据的广告词。
111.在一个示例中,在上述违法广告识别装置800中,如图10所示,所述识别模块840,包括训练单元850和推断单元870。
112.如图10所示,所述训练单元850,包括:训练文本获取子单元851,用于获取训练文本,所述训练文本为广告词;训练特征向量序列生成子单元852,用于在将所述广告词转化为词向量序列后通过双向长短时记忆神经网络模型以获得特征向量序列,其中,所述特征向量序列中的每一特征向量对应于所述广告词中的每一个词;参考特征向量生成子单元853,用于将与所述训练文本对应的真实违规词作为参考词通过所述词嵌入模型和所述双向长短时记忆神经网络模型以获得参考特征向量;注意力子单元854,用于计算所述参考特征向量与所述特征向量序列中每个特征向量之间的相似度以获得与所述广告词的每个词对应的(特征向量,相似度)的键值对和与所述广告词对应的相似度向量;解码子单元855,用于将所述特征向量序列中的每个特征向量分别通过分类器,以从所述分类器的最后一层全连接层得到每个所述特征向量对应的解码向量;交叉熵子单元856,用于计算所述解码向量和与其对应的所述特征向量之间的第一交叉熵值和所述解码向量和与其对应的相似度之间的第二交叉熵值,并计算所述第一交叉熵函数值和所述第二交叉熵值之间的加权和作为所述特征向量的加权交叉熵值,以获得由每个所述特征向量对应的加权交叉熵值组成的交叉熵向量;以及,更新子单元857,用于计算所述相似度向量与所述交叉熵向量之间的距离作为损失函数值来训练所述分类器和所述双向长短时记忆模型
113.如图10所示,所述推断单元870,包括:检测特征向量序列生成单元 871,用于将所述词向量序列通过经训练阶段训练完成的所述双向长短时记忆模型以获得特征向量序列;以及,违法广告识别结果生成子单元872,用于将所述特征向量序列通过经训练阶段训练完成的所述分类器以获得所述违法广告识别结果。
114.在一个示例中,在上述违法广告识别装置800中,所述注意力子单元854,进一步用于计算所述参考特征向量与所述特征向量序列中每个特征向量之间的l1距离或l2距离或余弦距离作为所述相似度。
115.在一个示例中,在上述违法广告识别装置800中,所述违法广告识别结果生成子单元872,进一步用于使用所述分类器的多个全连接层对所述特征向量序列中的每个特征向量进行全连接编码以获得解码向量;以及,将所述解码向量输入所述分类器的softmax分类
函数以获得所述解码向量对应的词属于违规词的概率
116.这里,本领域技术人员可以理解,上述违法广告识别装置800中的各个单元和模块的具体功能和操作已经在上面参考图1到图7的违法广告识别方法描述中得到了详细介绍,并因此,将省略其重复描述。
117.如上所述,根据本技术实施例的违法广告识别装置800可以实现在各种终端设备中,例如互联网广告监测的服务器等。在一个示例中,根据本技术实施例的违法广告识别装置800可以作为一个软件模块和/或硬件模块而集成到终端设备中。例如,该违法广告识别装置800可以是该终端设备的操作装置中的一个软件模块,或者可以是针对于该终端设备所开发的一个应用程序;当然,该违法广告识别装置800同样可以是该终端设备的众多硬件模块之一。
118.替换地,在另一示例中,该违法广告识别装置800与该终端设备也可以是分立的设备,并且该违法广告识别装置800可以通过有线和/或无线网络连接到该终端设备,并且按照约定的数据格式来传输交互信息。
119.示例性电子设备
120.下面,参考图11来描述根据本技术实施例的电子设备。
121.图11图示了根据本技术实施例的电子设备的框图。
122.如图11所示,电子设备10包括一个或多个处理器11和存储器12。
123.处理器11可以是中央处理单元(cpu)或者具有数据处理能力和/或指令执行能力的其他形式的处理单元,并且可以控制电子设备10中的其他组件以执行期望的功能。
124.存储器12可以包括一个或多个计算机程序产品,所述计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。所述易失性存储器例如可以包括随机存取存储器(ram)和/或高速缓冲存储器(cache)等。所述非易失性存储器例如可以包括只读存储器 (rom)、硬盘、闪存等。在所述计算机可读存储介质上可以存储一个或多个计算机程序指令,处理器11可以运行所述程序指令,以实现上文所述的本技术的各个实施例的违法广告识别方法中的功能以及/或者其他期望的功能。在所述计算机可读存储介质中还可以存储诸如训练文本、违法广告识别结果等各种内容。
125.在一个示例中,电子设备10还可以包括:输入装置13和输出装置14,这些组件通过总线装置和/或其他形式的连接机构(未示出)互连。
126.该输入装置13可以包括例如键盘、鼠标等等。
127.该输出装置14可以向外部输出各种信息,包括违法广告识别结果等。该输出装置14可以包括例如显示器、扬声器、打印机、以及通信网络及其所连接的远程输出设备等等。
128.当然,为了简化,图11中仅示出了该电子设备10中与本技术有关的组件中的一些,省略了诸如总线、输入/输出接口等等的组件。除此之外,根据具体应用情况,电子设备10还可以包括任何其他适当的组件。
129.示例性计算机程序产品和计算机可读存储介质
130.除了上述方法和设备以外,本技术的实施例还可以是计算机程序产品,其包括计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本技术各种实施例的违法广告识别方法中的功能中的步骤。
131.所述计算机程序产品可以以一种或多种程序设计语言的任意组合来编写用于执行本技术实施例操作的程序代码,所述程序设计语言包括面向对象的程序设计语言,诸如java、c++等,还包括常规的过程式程序设计语言,诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。
132.此外,本技术的实施例还可以是计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器执行本说明书上述“示例性方法”部分中描述的根据本技术各种实施例的违法广告识别方法中的功能中的步骤。
133.所述计算机可读存储介质可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以包括但不限于电、磁、光、电磁、红外线、或半导体的装置、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1