一种仓储环境手术器械目标检测模型训练及优化方法与流程
1.本发明涉及深度学习目标检测技术领域,尤其涉及一种仓储环境手术器械目标检测模型训练及优化方法。
背景技术:
2.手术器械在从仓储环境中打包时需要对每一类器械进行准确的计数以核实清单并完成打包,该清点任务目前主要由人工进行作业。人工负责清点工作的缺点在于劳动成本高、不能进行长时间工作、清点的效率较低。从而引入深度学习目标检测技术替换人工清点具有高效、准确、降低成本等优点,具有广阔的应用前景。
3.目标检测技术属于计算机视觉技术的一个子分支。近年在目标检测领域以深度学习方法为主流,尤其是以yolo系列为代表的一阶段算法具有快速准确的特点,已经在工程领域的众多方面有所应用。但是根据查阅的文献资料所得,yolo系列的sota级模型yolo v5的网络结构是面对公共数据集进行测验的,在面对实际仓储环境手术器械目标检测时,其表现存在许多的不足,如漏检、多检等,并不能够实际应用于手术器械清点任务,需要进行特定的网络结构优化,以满足实际作业要求。
4.深度学习目标检测模型训练的效果好坏很大一部分是来自于数据集质量的好坏,yolo v5模型也是一种由大量数据集才能够进行周期训练从而对训练参数进行学习的一种目标检测模型。根据查阅工程应用类文献资料,暂时并未存在针对于仓储环境手术器械目标检测任务的数据集构建方法。
技术实现要素:
5.本发明的目的是保证手术器械目标检测数据集的质量,对模型的结构进行优化,从以上内容实现对仓储环境手术器械目标检测模型训练及优化。
6.为了实现上述目的,本发明采用了如下技术方案:
7.一种仓储环境手术器械目标检测模型训练及优化方法,以yolo v5网络结构为基础,对网络结构进行优化,具体包括以下步骤:
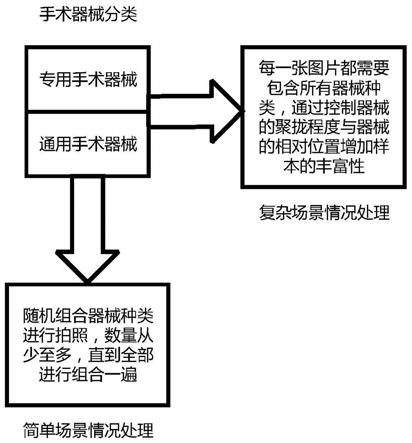
8.s1、配置实验环境,对拍摄环境进行处理,在处理后的环境下,将手术器械按照通用手术器械和专用手术器械两类进行分类;
9.s2、根据手术器械的数量、摆放位置以及排列组合关系分为简单场景和复杂场景两类数据集,结合s1中所得手术器械按照通用手术器械和专用手术器械两类数据集,分别在简单场景和复杂场景下进行手术器械源图片的获取,形成手术器械图片数据集;
10.s3、针对yolo v5网络结构器械清点能力不足的情况,对目标监测模型yolo v5的结构进行优化,从目标监测模型yolo v5中引出一条新的技术分支,加以重新训练从而得到技术更为准确的新结构模型;
11.s4、针对经典yolo v5网络结构并无损失函数能够反应训练图片中器械的正确数量与预测数量之间偏移距离的问题,对损失函数进行优化,在目标监测模型yolo v5中引入
新的损失函数,拉紧预测值与真值之间的距离。
12.优选地,所述s1中提到的对拍摄环境进行处理,具体包括有:
13.a1、控制拍摄位置周围的环境光与工作环境保持一致;
14.a2、拍摄用摄像机的相机平面与拍摄平面保持平行;
15.a3、拍摄背景与工作环境保持一致性;
16.a4、保证相机的高度可根据需要进行调节。
17.优选地,所述s2中提到的手术器械源图片的获取,拍摄过程中需注意:
18.b1、简单场景下进行拍摄时,将手术器械从少到多进行排列组合,直至所有种类器械都能得到组合并保证各种类的数据保持平衡;
19.b2、复杂场景下进行拍摄时,每一张图片都需要包含所有手术器械,且保证不存在严重重叠的现象;
20.b3、收集图像时,根据实际需要改变器械的相对位置和聚拢程度,确保场景的丰富程度。
21.优选地,所述s3中提到的目标监测模型yolo v5的优化,具体包括以下步骤:
22.c1、得到目标监测模型yolo v5的版本源码,复制源码中的yolo v5s.yaml文件;
23.c2、在c1中复制所得的原yaml文件的backbone和head后新加一个count结构,其来源是来自于原网络第20层的输出,按照预定的格式在count中添加[20,1,conv,[256,1,1]]代表引出第20层的输出,该层的重复次数为1,使用的网络基础结构为卷积层,输出通道数量256层,卷积核大小为1,步长为1;
[0024]
c3、完成c2中所述操作后,对得到的特征图进行由特征图转换到密度图的操作;
[0025]
c4、完成c3所述操作后,再加上一层卷积层进行提取特征,之后再经过一层卷积核大小为1的卷积层输出至预测头,得到密度预测图,从密度预测图中得到的图片中器械的数量根据为密度图中的像素值;
[0026]
c5、在yaml文件中完成模型结构的更改操作之后,进一步在yolo.py中更改模型的输出;
[0027]
c6、更改前向传播函数,保证模型的前向传播函数能够同时输出计数预测头的输出。
[0028]
优选地,所述s4中提到的对损失函数进行优化,具体包括以下步骤:
[0029]
d1、将经过优化的目标监测模型yolo v5中的第24层的输出重新接入原计算函数中,得到损害计算函数,保证原损失计算的顺利进行;
[0030]
d2、在损失计算函数中引入新的lcnt损失,利用新得到的损失函数根据实验性经验得出结论,选用均方差损失函数,利用均方差损失函数判断总预测数量与真值之间的距离,并且拉近两者之间的距离;
[0031]
d3、得到计数损失之后将计数损失与种类损失、置信度损失、回归框损失进行相加,再把总损失在反向传播函数中进行参数的更新;
[0032]
d4、重复d1~d3所述操作进行迭代训练,加强模型对器械数量的清点能力。
[0033]
与现有技术相比,本发明提供了一种仓储环境手术器械目标检测模型训练及优化方法,具备以下有益效果:
[0034]
本发明提出了一种仓储环境下手术器械实例分割模型的训练及优化方法,能够有
效的对目标检测模型yolo v5的结构和损失函数进行优化,有效提高了目标检测模型对手术器械数量的识别和清点功能。
附图说明
[0035]
图1为本发明提出的一种仓储环境手术器械目标检测模型训练及优化方法数据集构建示意图;
[0036]
图2为本发明提出的一种仓储环境手术器械目标检测模型训练及优化方法改进后的网络结构示意图。
具体实施方式
[0037]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0038]
实施例1:
[0039]
请参阅图1-2;
[0040]
1.一种仓储环境手术器械目标检测模型训练及优化方法,其特征在于,以yolo v5网络结构为基础,对网络结构进行优化,具体包括以下步骤:
[0041]
s1、配置实验环境,对拍摄环境进行处理,在处理后的环境下,将手术器械按照通用手术器械和专用手术器械两类进行分类;
[0042]
所述s1中提到的对拍摄环境进行处理,具体包括有:
[0043]
a1、控制拍摄位置周围的环境光与工作环境保持一致;
[0044]
a2、拍摄用摄像机的相机平面与拍摄平面保持平行;
[0045]
a3、拍摄背景与工作环境保持一致性;
[0046]
a4、保证相机的高度可根据需要进行调节;
[0047]
s2、根据手术器械的数量、摆放位置以及排列组合关系分为简单场景和复杂场景两类数据集,结合s1中所得手术器械按照通用手术器械和专用手术器械两类数据集,分别在简单场景和复杂场景下进行手术器械源图片的获取,形成手术器械图片数据集;
[0048]
所述s2中提到的手术器械源图片的获取,拍摄过程中需注意:
[0049]
b1、简单场景下进行拍摄时,将手术器械从少到多进行排列组合,直至所有种类器械都能得到组合并保证各种类的数据保持平衡;
[0050]
b2、复杂场景下进行拍摄时,每一张图片都需要包含所有手术器械,且保证不存在严重重叠的现象;
[0051]
b3、收集图像时,根据实际需要改变器械的相对位置和聚拢程度,确保场景的丰富程度;
[0052]
s3、针对yolo v5网络结构器械清点能力不足的情况,对目标监测模型yolo v5的结构进行优化,从目标监测模型yolo v5中引出一条新的技术分支,加以重新训练从而得到技术更为准确的新结构模型;
[0053]
所述s3中提到的目标监测模型yolo v5的优化,具体包括以下步骤:
[0054]
c1、得到目标监测模型yolo v5的版本源码,复制源码中的yolo v5s.yaml文件;
[0055]
c2、在c1中复制所得的原yaml文件的backbone和head后新加一个count结构,其来
源是来自于原网络第20层的输出,按照预定的格式在count中添加[20,1,conv,[256,1,1]]代表引出第20层的输出,该层的重复次数为1,使用的网络基础结构为卷积层,输出通道数量256层,卷积核大小为1,步长为1;
[0056]
c3、完成c2中所述操作后,对得到的特征图进行由特征图转换到密度图的操作;
[0057]
c4、完成c3所述操作后,再加上一层卷积层进行提取特征,之后再经过一层卷积核大小为1的卷积层输出至预测头,得到密度预测图,从密度预测图中得到的图片中器械的数量根据为密度图中的像素值;
[0058]
c5、在yaml文件中完成模型结构的更改操作之后,进一步在yolo.py中更改模型的输出;
[0059]
c6、更改前向传播函数,保证模型的前向传播函数能够同时输出计数预测头的输出;
[0060]
s4、针对经典yolo v5网络结构并无损失函数能够反应训练图片中器械的正确数量与预测数量之间偏移距离的问题,对损失函数进行优化,在目标监测模型yolo v5中引入新的损失函数,拉紧预测值与真值之间的距离;
[0061]
所述s4中提到的对损失函数进行优化,具体包括以下步骤:
[0062]
d1、将经过优化的目标监测模型yolo v5中的第24层的输出重新接入原计算函数中,得到损害计算函数,保证原损失计算的顺利进行;
[0063]
d2、在损失计算函数中引入新的lcnt损失,利用新得到的损失函数根据实验性经验得出结论,选用均方差损失函数,利用均方差损失函数判断总预测数量与真值之间的距离,并且拉近两者之间的距离;
[0064]
d3、得到计数损失之后将计数损失与种类损失、置信度损失、回归框损失进行相加,再把总损失在反向传播函数中进行参数的更新;
[0065]
d4、重复d1~d3所述操作进行迭代训练,加强模型对器械数量的清点能力。
[0066]
本发明提出了一种仓储环境下手术器械实例分割模型的训练及优化方法,能够有效的对目标检测模型yolo v5的结构和损失函数进行优化,有效提高了目标检测模型对手术器械数量的识别和清点功能。
[0067]
实施例2:
[0068]
请参阅图1-2,基于实施例1但有所不同之处在于,
[0069]
本实施案例中涉及一种仓储环境手术器械目标检测模型训练及优化方法,包括:手术器械数据集的构建方法、目标检测模型yolo v5网络结构的改进、引入新的计数损失函数。
[0070]
对于手术器械数据集的构建,在到手术器械样本后需要对其进行分类成通用手术器械与专用手术器械两类器械。分别在简单场景与复杂场景下进行源图片的获取。
[0071]
在开始拍摄之前需要将拍摄环境进行处理,需要达到以下的要求:
[0072]
1.周围的环境光需要与工作环境保持一致性;
[0073]
2.摄像头的相机平面需要与拍摄平面保持平行;
[0074]
3.拍摄背景需要与工作环境保持一致性;
[0075]
4.可以保证相机的高度是可调节的;
[0076]
因此具体的步骤中采用了无影灯源作为拍摄中的光源,纯绿背景布平摊在工作桌
上作为拍摄背景,使用d435深度学习摄像头作为相机拍摄图片,使用高度可调节支架作为相机支架进行固定,拍摄过程注意相机是否倾斜。
[0077]
实验环境配置完成之后首先进行简单场景下的数据集制作。简单场景数集需要根据器械种类的数量进行排列组合直至所有种类的器械都能互相搭配到,每一种情况拍摄2~3张即可,每张需要保证图片中的器械相对位置发生变化。即位置变换不能以挪动器械在相机平面中的位置的形式出现,如左上角的器械挪动到右下角,其角度姿势并未发生改变。
[0078]
复杂场景下的数据集中每张图片都需要保证含有所有种类的器械,不可包含有严重重叠情况,可有轻微重叠的情况出现。通过控制器械之间相对位置以及聚拢程度控制数据集的丰富程度。以16个器械种类为例,需要组合出2000张复杂场景下的数据集。
[0079]
同时不管是简单场景下的数据集还是复杂场景下的数据集都需要注意的是其数据集的图片不能存在模糊的情况、只含有部分的情况出现,在得到所有的数据集之后对其进行检查,查看是否出现该类情况,如果有,则将其剔除,以保证质量。
[0080]
对于yolo v5模型结构的更改,具体步骤如下:
[0081]
首先是得到yolo v5(v2.0)版本源码,复制其yolo v5s.yaml文件。yolo v5网络结构的模型根据该yaml文件进行模型的建立,所以改动其网络结构首先需要对该结构继续改动。在原yaml文件的backbone和head后新加一个count结构,其来源是来自于原网络第20层的输出,按照预定的格式[from,number,module,args]在count中添加[20,1,conv,[256,1,1]]代表引出第20层的输出,该层的重复次数为1,使用的网络基础结构为卷积层,输出通道数量256层,卷积核大小为1,步长为1。应该注意,这里的卷积后面默认跟有leakrelu激活层与bn层操作,以下同理。
[0082]
引出输出后需要对得到的特征图进行由特征图转换到密度图的操作,在这一步使用了3*3大小的卷积核进行卷积操作,在yaml文件应该添加如下数据[-1,3,conv,[256,3,1]],-1表示该层的输入来自于上一层,其他参数的含义同上。
[0083]
一层卷积层经过实验发现对特征图的提取效果并不够明显,所以后续需要再加上一层卷积层进行提取特征,之后再经过一层卷积核大小为1的卷积层输出至预测头,为了完成这一步操作需要在yaml文件中的count层添加如下的操作:
[0084]
[-1,3,conv,[256,3,1]],[-1,1,conv,[1,1,1]]。之后得到密度预测图,大小为40*40,从密度图中得到图片中器械的数量根据为密度图中的像素值。
[0085]
yaml文件中完成模型结构的更改之后需要在yolo.py中更改模型的输出,因为原yolo.py文件其输出是与原yolo结构耦合的。新的结构更改之后其输出格式与原输出格式并不相同,会导致网络不能完成训练。具体的操作如下说明:
[0086]
在parse_model()函数中对save操作,如果网络的深度已经大于24层,则将第28层网络的输出作为计数预测头的输出,并进行保存。同时考虑到yolo结构的根据不同大小会扩张网络的宽度与深度,所以需要在该函数中保证第28层的输出通道为1,即深度大于24层时,网络的深度与宽度将不再进行扩张。
[0087]
为了保证模型的前向传播函数能够同时输出计数预测头的输出,需要在前向传播函数中进行更改,即将新结构的网络第24层的输出与第28层的输出同时输出。第24层的输出为原网络结构的输出,用以进行对目标进行种类以及位置预测,第28层的输出为输入图片中器械的数量密度图,用以回归总数量。
[0088]
解决完前向传播函数的输出问题后,需要utils包中的general.py中的损失计算函数进行更改,因为原网络结构最后一层输出形式为list[tensor1,tensor2,tensor3]的形状,新结构的最后一层输出格式为b*1*40*40,需要将改进后的网络结构第24层的输出重新接入原计算函数中从而保证原损失计算。同时需要引入新的lcnt(counting loss)损失,该损失函数根据实验性经验得出结论,选用均方差损失函数效果较好。可以判断总预测数量与真值之间的距离,并且拉近两者之间的距离。总预测数量的得到方法为将密度图中的像素值根据阈值进行选拔,将大于阈值的像素点进行计数,再与gt进行均方差计算。
[0089]
得到计数损失之后将计数损失与种类损失、置信度损失、回归框损失进行相加,再把总损失在反向传播函数中进行参数的更新。
[0090]
以此进行迭代训练,加强模型对器械数量的清点能力。
[0091]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1