一种基于索引更改Hive数据的方法与流程
一种基于索引更改hive数据的方法
技术领域
1.本发明涉及大数据计算应用技术领域,特别涉及一种基于索引更改hive数据的方法。
背景技术:
2.新一代信息技术基础设施建设、发展数字经济、工业互联网是当前最受关注的概念,这些概念牵涉到方方面面都离不开大数据的支撑。比如5g网络、数据中心、人工智能等等都是以技术创新为驱动,以信息网络为基础,为社会数字转型,智能升级和基础服务提供支撑。这些技术都是以数据融合、大数据一体化为基础,基于人工智能、机器学习,为企业、政府以及教育等各行各业提供数据基础、算力支撑。数据如何采集、如何存储,保证后续数据融合、计算提供完整的数据是实现上述技术对重要技术手段。
3.hadoop是当前大数据最主流的生态框架,基于hadoop衍生了hive、hbase、spark 等大数据存储和计算的优秀框架。基于hadoop生态构建数据湖是目前主流的大数据技术趋势,分布式、容错性强、易扩展的优势让其在大数据领域一枝独秀。
4.但是,hadoop目前主流的数据存储和计算都是基于数据不变为前提,提供时间耗时较长的数据处理服务。比如基于hive的数据存储就不能可更改,或者按分区更改,这样就限制了其使用范围。比如,在大数据一体化建设中,所有的业务库都要汇集到大数据中心,打通数据之间的联通性,实现一份数据全网可用。打通行业壁垒,地域壁垒,甚至部门壁垒。但是,这个场景中有一个重要的问题:系统建设处理可以对历史数据一次性汇集,但是后续业务部门的增量数据如何汇集入湖,从而实现数据的精准入湖,保证数据的一致性。因为目前使用hdfs和hive作为数据湖的存储引擎面的主要是问题,就是业务部门修改的数据,在同步至hive时,无法实现精准逐条更新。
5.为了解决用户从传统数据库同步数据至数据湖时,hive无法支持数据更改,导致数据变动无法同步体现到数据库中的困境,本发明提出了一种基于索引更改hive数据的方法。
技术实现要素:
6.本发明为了弥补现有技术的缺陷,提供了一种简单高效的基于索引更改hive数据的方法。
7.本发明是通过如下技术方案实现的:
8.一种基于索引更改hive数据的方法,其特征在于:包括以下步骤:
9.第一步、通过spark(计算引擎)获取存量数据hdata主键keys和增量数据sdata 主键keys;
10.第二步、spark按照增量数据sdata主键keys从hbase数据库索引表中获取对应历史存量数据hdata的文件路径;然后,spark根据主键keys以及标志位合并增量数据sdata 与对应历史存量数据hdata,形成新的文件;
11.第四步,spark根据主键keys以及文件路径,标记文件是否有效,若无效便标记作废。
12.所述第一步中,指定存量数据hdata表的唯一主键或者联合主键,spark在写入数据时获取主键或者联合主键列的值,将联合主键列的值作为主键keys写入hbbase数据库中,同时保存该行数据所在文件在hdfs(hadoop分布式文件系统)数据库中的真实路径。
13.所述第一步中,通过spark获取数据源的中的历史存量数据hdata,根据主键或者联合主键信息,获取主键数据集主键keys;将历史存量数据hdata数据写入hive的同时,记录下每行数据所存在的文件路径locals,将主键数据集主键keys和文件路径locals写入到hbase数据库中;并将所有有效文件记录在单独的logs文件夹下的log文件中。
14.所述第二步中,当新的增量数据sdata需要通过spark更新数据时,先根据主键keys 去hbase数据库查询对应历史存量数据hdata在hdfs数据库的文件路径,然后将该文件中的数据和增量数据sdata进行合并,形成新的文件保存到hdfs数据库中。
15.所述第二步中,spark获取增量数据sdata后,首先提取主键keys,然后根据主键值去hbase数据库索引表中查询已保存当前行的文件files,并将增量数据sdata合并到文件files中;spark读取文件files中的所有数据mdata,并将文件files中的所有数据mdata 与增量数据sdata进行合并,增量数据sdata包括删除的数据、修改的数据以及新插入的数据。
16.所述第三步中,将废旧的文件在log(日志)目录中的log文件中做废弃标识,将新文件的绝对路径保存更新到对应的hbase数据库中,即可完成对hive数据的增量更新。
17.所述第二步中,将合并后的数据写入到文件newfiles中,同时更新hbase数据库中对应的主键keys的文件名称以及绝对路径;在log文件中把文件files标记为废弃,同时将文件newfiles标记为新的文件。
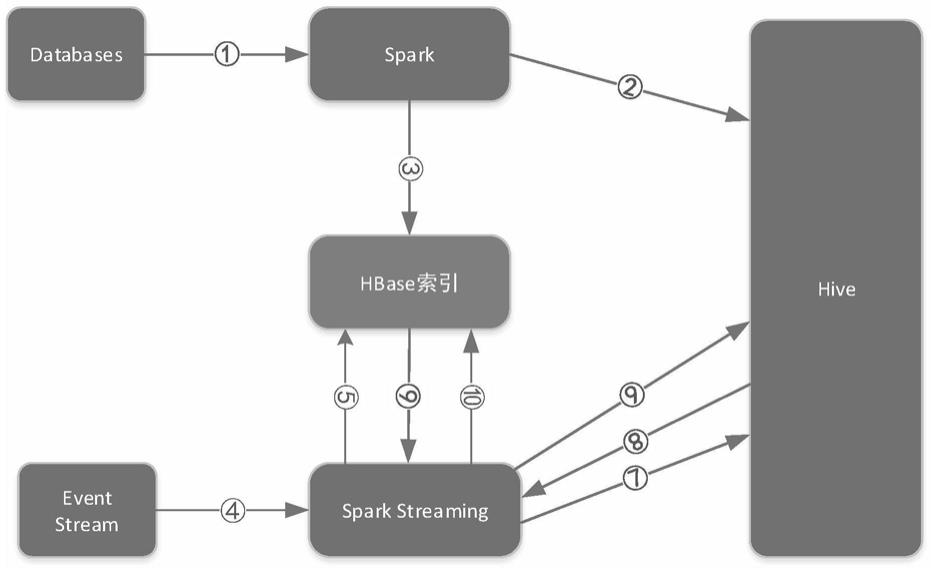
18.该基于索引更改hive数据的方法,具体实现流程如下:
19.(1)spark从数据库中获取历史存量数据hdata,根据主键信息获取主键的值;
20.(2)spark把历史存量数据hdata写入到hive中,并记录每行数据写入到了哪个文件中,形成(key,filelocals)的键值对;并将文件路径filelocals记录到log目录中,将日志文件中设置该文件路径filelocals为有效文件;
21.(3)spark将(key,fileslocal)键值对作为数据索引保存至hbase数据库表中;
22.(4)spark streaming(批处理的流式(实时)计算框架)从消息框架中获取增量数据streamrdd(队列流),并取到主键keys集合;
23.(5)spark streaming根据主键keys集合从hbase数据库中取出需要修改的数据之前已经存在的文件路径filelocals集合;
24.(6)hbase数据库返回文件路径filelocals集合;
25.(7)spark streaming根据文件路径filelocals集合,从hive中取出需要修改的文件;
26.(8)返回需要修改的数据文件集合rdd,spark streaming将增量数据streamrdd 和数据文件集合rdd进行合并,删除数据、更新数据和/或插入数据,最后合并成一个新的数据文件集合new rdd;
27.(9)spark streaming将数据文件集合newrdd写入的hive表中,并将数据文件集合newrdd写的新文件集合更新到log表,标记为有效,将第(7)步中的文件路径filelocals 集
合标记为作废;
28.(10)将更新的数据的主键keys和文件路径filelocals更新为新的(keys,filelocals) 键值对保存至hbase数据库索引表中。
29.本发明的有益效果是:该基于索引更改hive数据的方法,利用hbase索引表记录文件位置以及spark快速合并文件的特点,快读定位到涉及修改的文件,实现了新增数据和历史存量数据的合并,从而实现了对hive数据的增量更新。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.附图1为本发明基于索引更改hive数据的方法示意图。
具体实施方式
32.为了使本技术领域的人员更好的理解本发明中的技术方案,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚,完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
33.该基于索引更改hive数据的方法,包括以下步骤:
34.第一步、通过spark(计算引擎)获取存量数据hdata主键keys和增量数据sdata 主键keys;
35.第二步、spark按照增量数据sdata主键keys从hbase数据库索引表中获取对应历史存量数据hdata的文件路径;然后,spark根据主键keys以及标志位合并增量数据sdata 与对应历史存量数据hdata,形成新的文件;
36.第四步,spark根据主键keys以及文件路径,标记文件是否有效,若无效便标记作废。
37.所述第一步中,指定存量数据hdata表的唯一主键或者联合主键,spark在写入数据时获取主键或者联合主键列的值,将联合主键列的值作为主键keys写入hbbase数据库中,同时保存该行数据所在文件在hdfs(hadoop分布式文件系统)数据库中的真实路径。
38.所述第一步中,通过spark获取数据源的中的历史存量数据hdata,根据主键或者联合主键信息,获取主键数据集主键keys;将历史存量数据hdata数据写入hive的同时,记录下每行数据所存在的文件路径locals,将主键数据集主键keys和文件路径locals写入到hbase数据库中;并将所有有效文件记录在单独的logs文件夹下的log文件中。
39.所述第二步中,当新的增量数据sdata需要通过spark更新数据时,先根据主键keys 去hbase数据库查询对应历史存量数据hdata在hdfs数据库的文件路径,然后将该文件中的数据和增量数据sdata进行合并,形成新的文件保存到hdfs数据库中。
40.所述第二步中,spark获取增量数据sdata后,首先提取主键keys,然后根据主键值去hbase数据库索引表中查询已保存当前行的文件files,并将增量数据sdata合并到文件
files中;spark读取文件files中的所有数据mdata,并将文件files中的所有数据mdata 与增量数据sdata进行合并,增量数据sdata包括删除的数据、修改的数据以及新插入的数据。
41.所述第三步中,将废旧的文件在log(日志)目录中的log文件中做废弃标识,将新文件的绝对路径保存更新到对应的hbase数据库中,即可完成对hive数据的增量更新。
42.所述第二步中,将合并后的数据写入到文件newfiles中,同时更新hbase数据库中对应的主键keys的文件名称以及绝对路径;在log文件中把文件files标记为废弃,同时将文件newfiles标记为新的文件。
43.该基于索引更改hive数据的方法,具体实现流程如下:
44.(1)spark从数据库中获取历史存量数据hdata,根据主键信息获取主键的值;
45.(2)spark把历史存量数据hdata写入到hive中,并记录每行数据写入到了哪个文件中,形成(key,filelocals)的键值对;并将文件路径filelocals记录到log目录中,将日志文件中设置该文件路径filelocals为有效文件;
46.(3)spark将(key,fileslocal)键值对作为数据索引保存至hbase数据库表中;
47.(4)spark streaming(批处理的流式(实时)计算框架)从消息框架中获取增量数据streamrdd(队列流),并取到主键keys集合;
48.(5)spark streaming根据主键keys集合从hbase数据库中取出需要修改的数据之前已经存在的文件路径filelocals集合;
49.(6)hbase数据库返回文件路径filelocals集合;
50.(7)spark streaming根据文件路径filelocals集合,从hive中取出需要修改的文件;
51.(8)返回需要修改的数据文件集合rdd,spark streaming将增量数据streamrdd 和数据文件集合rdd进行合并,删除数据、更新数据和/或插入数据,最后合并成一个新的数据文件集合new rdd;
52.(9)spark streaming将数据文件集合newrdd写入的hive表中,并将数据文件集合newrdd写的新文件集合更新到log表,标记为有效,将第(7)步中的文件路径filelocals 集合标记为作废;
53.(10)将更新的数据的主键keys和文件路径filelocals更新为新的(keys,filelocals) 键值对保存至hbase数据库索引表中。
54.以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1