一种自动筛选上游风险源的水污染快速溯源方法与流程
1.本发明涉及环境污染治理和环境监测领域,尤其涉及一种自动筛选上游风险源的水污染快速溯源方法,用于快速排查、确定水污染事件中的涉嫌风险源,并计算可疑风险源的排污贡献率。
背景技术:
2.水环境安全是影响人们生活生产、区域经济发展的重要问题。水环境管制对整个水环境保护、水污染控制以及维护水环境健康等起着至关重要的作用。通过对水环境污染源头的追溯,可以有效防范污染物的扩散、查找到污染源,辅助水环境的监督管制,进而保证水环境的安全。
3.现有的水污染溯源方法,主要涉及四类:一是在污染发生后利用被污染的下游水样和上游涉事企业排污口的水样进行检测,并对结果进行比对分析,实现对污染源的排查、溯源、贡献率的计算,对涉嫌违规的企业进行追责;二是利用监测点的监测数据,基于数学模型或水文模型反推污染源的位置或范围;三是利用事先建立的风险源的化学指纹库或排污特征库,与监测站的监测结果进行比对以确定涉嫌违规的企业;四是从污染水体的波谱特征入手,利用遥感影像数据实现水污染溯源。由于第一类方法需要在每个排污口都安装检测设备,成本投入大、后期维护工作量大,且耗时、操作复杂,因此无法及时进行涉事企业的追责;第二类方法在进行水污染事件溯源时往往需要大量的计算分析资源,模型计算速度较慢,难以满足工程上或普通用户的快速溯源的问题;第三类利用遥感数据进行水污染溯源方法依赖于高分辨率、高光谱的遥感影像,费用高且受遥感解译方法准确性影响很大,现有的遥感解译手段难以满足工程上水污染事件快速溯源的需求;而第四类方法通过与事先建立风险源特征库进行比对,可以大量减少水污染溯源的工作量,提高水污染溯源的效率。然而,现有的第四类方法仍存在不足。现有的技术在进行上下游判断时,常通过目视解译的方式确定位于监测点或被污染点上游的风险源,这导致水污染事件溯源过程自动化程度低,人工依赖度强。
技术实现要素:
4.根据上述提出的技术问题,而提供一种自动筛选上游风险源的水污染快速溯源方法。本发明主要利用空间查询技术构建水文空间情景库,并对排污风险源的排污特征进行分析,构建风险源排污特征库,在水污染事件发生时,结合空间查询技术自动筛选出上游风险源(涉嫌风险源),将监测站监测结果与涉嫌风险源排污特征进行比对,并计算涉嫌风险源的排污贡献率,从而辅助快速排查可疑的违规排污风险源。本发明采用的技术手段如下:
5.一种自动筛选上游风险源的水污染快速溯源方法,包括如下步骤:
6.步骤1、获取水系数据、监测点数据、风险源数据之间的空间关系,获取空间查询监测点、风险源点相应的最邻近径流及最邻近点坐标,基于此构建水文空间情景库;
7.步骤2、获取所采集的目标区域各风险源污水的污染物数据,建立风险源排污特征
库,所述风险源排污特征库实时更新;
8.步骤3、使用空间查询技术自动化确定监测点位和风险源的上下游关系,初步筛选出位于监测站上游的可能影响监测点位水质的风险源;
9.步骤4、对于超出水质标准的监测项目或重点观察的监测项目,根据监测点的检测项目和风险源排污特征映射关系,从风险源排污特征库中提取涉嫌风险源相关信息,计算涉嫌风险源影响监测点位水质的排污贡献率,最后根据输出的综合排污贡献率的大小判断涉嫌风险源污染监测点位水质的贡献程度。
10.进一步地,所述步骤1具体包括如下步骤:
11.步骤1.1、空间查询径流所在流域:利用空间查询技术确定区域内各径流段所在流域;
12.步骤1.2、空间查询各监测点最邻近径流段及对应的最邻近点:利用空间查询技术确定各监测点最邻近径流段及对应的最邻近点坐标;
13.步骤1.3、空间查询各风险源最邻近径流段及对应的最邻近点:利用空间查询技术确定各风险源最邻近径流段及对应的最邻近点坐标。
14.进一步地,所述步骤2中,污染物数据包括污染物种类、含量数据,所述风险源排污特征库实时更新的数据包括企业定期申报数据或不定期现场检查数据。
15.进一步地,所述步骤3包括如下步骤:
16.步骤3.1、将监测点的上游风险源按流域分为两个部分,包括与监测点同一流域的上游风险源和上游k阶流域风险源,空间查询同一流域的上游风险源,具体地,通过对比监测点在最邻近径流段的最邻近点位及其同一流域内风险源最邻近径流段的最邻近点位到监测点最临近径流段上游截断点的距离,判断风险源是否位于监测点上游,若监测点到该截断点的距离大于风险源到该截断点的距离,则该风险源属于监测点的上游风险源,该风险源为涉嫌风险源;否则,该风险源被判断为不影响该监测点位水质,不作为涉嫌风险源;
17.步骤3.2、空间查询上游k阶流域内风险源:通过查找监测点所在径流上游第1阶径流段所在的流域,并向上不断查找上游第2,
…
,k阶邻接流域,最后将位于上游k阶流域内所有的风险源同样列入涉嫌风险源集合中。
18.进一步地,利用postgresql数据库的空间查询技术将步骤3的流程自动化。
19.进一步地,流程自动化具体包括查询同一流域的上游风险源流程和查询上游k阶流域内风险源流程:
20.其中,查询同一流域的上游风险源流程包括:
21.步骤3a、利用postgresql数据库的st_dumppoints和st_makeline函数将监测点的最邻近径流段按折点进行拆分,分为多个按上下游顺序连接的子径流段;
22.步骤3b、按所拆分的上下游顺序,利用st_distance函数查找与监测点最邻近点距离为0的子径流段,计算该子径流段的上游截断点和监测点最邻近点之间的距离,并与该子径流段上游的所有子径流段长度累加,得到监测点最邻近点位到径流段上游截断点的距离;
23.步骤3c、同样的方式可以获得同一流域各风险源最邻近点到径流段上游截断点的距离,若此距离小于或等于监测点最邻近点到径流段上游截断点的距离,则该风险源为监测点同一流域的上游风险源;
24.步骤3d、生成该监测点同一流域上游风险源集合;
25.查询上游k阶流域内风险源流程包括:
26.步骤3e、利用水文空间情景库中径流表的上游截断点id字段和下游截断点id字段内连接获取径流上游1阶相邻流域,生成径流段上游1阶邻接径流段所在流域表;
27.步骤3f、利用该表循环查找监测点所属径流段的上游k阶流域,将位于这些上游k阶流域内的风险源同样列为涉嫌风险源;
28.步骤3g、生成该监测点上游k阶流域风险源集合;
29.与步骤3d、中查询的监测点同一流域上游风险源集合合并,生成该监测点上游涉嫌风险源集合。
30.进一步地,所述步骤4具体包括如下步骤:
31.步骤4.1、确定进行比对的监测项目集合:进行比对的监测项目与所构建的监测项目与风险源排污特征的映射关系相结合,用于从风险源排污特征库中筛选排污特征进行贡献率的计算;
32.步骤4.2、提取初步筛选风险源及相关排污特征:利用监测项目与风险源排污特征映射关系,根据步骤4.1确定的进行比对的监测项目,获取进行比对的风险源排污特征集合;根据进行比对的风险源排污特征集合以及步骤3获取的筛选后上游风险源集合,从风险源排污特征库中查找初步筛选后的涉嫌风险源的排污特征和相关信息;
33.步骤4.3、计算涉嫌风险源单项排污贡献率:根据步骤4.2中提取的涉嫌风险源数据和监测数据,可计算风险源a排出的污水对该点位水质中污染物i的单项排污贡献率p
′
a
(i):
[0034][0035][0036]
其中风险源a对应污染物i的排污特征浓度为c
a
(i),风险源点位到监测点位的欧氏距离为d
a
;监测点记录的污染物i的浓度c(i);
[0037]
步骤4.4、计算涉嫌风险源综合排污贡献率:
[0038]
根据步骤4.3的计算结果,进一步计算风险源a综合影响该监测点位水质的综合排污贡献率prob
a
:
[0039][0040]
本发明在水污染溯源过程中引入空间查询技术及gis空间分析方法,使得进行可疑风险源的快速排查和排污贡献率的计算更加简单。本发明提出了一种自动化筛选被污染点上游风险源并计算涉嫌风险源排污贡献率的方法,利用空间查询技术对上游风险源进行自动筛选,并利用风险源排污特征库与监测项目比对从而计算风险源排污贡献率。本发明提高了水污染事件快速溯源的效率,能为排查风险源提供决策信息。
[0041]
本发明与现有技术相比,具有以下的有益效果:本发明可以利用基础的dem数据及已掌握的风险源信息进行水污染事件快速溯源和排污贡献率计算,大大降低了人力物力的需求;同时,通过自动化判断上游风险源进行初步筛选的算法,减小了人工依赖度,提高了自动化率。这种将空间查询技术与水污染溯源有机结合的方式,减少了水污染溯源的工作量,降低了溯源成本,快速高效地实现溯源,为普通研究人员、用户以及政府相关部门开展水污染溯源工作提供了便利。
附图说明
[0042]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0043]
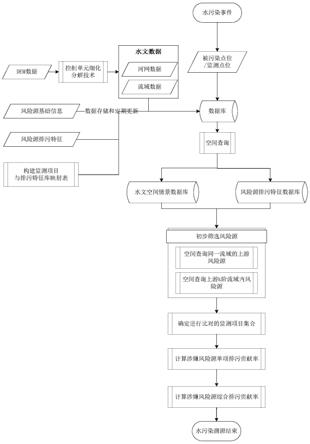
图1为本发明实施方式的整体流程图。
[0044]
图2是本发明实施方式步骤1中“监测点、风险源点相应的最邻近径流及最邻近点”示意图;
[0045]
图3是本发明实施方式步骤3子步骤3.1中监测点、监测点同一流域内风险源相应的最邻近点到监测点最邻近径流上游截断点的径流段示意图;
[0046]
图4是本发明实施方式步骤3子步骤3.1空间查询同一流域的上游风险源的算法流程图;
[0047]
图5是本发明实施方式步骤3子步骤3.2的中监测点上游k阶流域示意图;
[0048]
图6是本发明实施方式步骤3子步骤3.2空间查询上游k阶流域内风险源的算法流程图。
具体实施方式
[0049]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
本实施例公开了一种自动筛选上游风险源的水污染快速溯源方法,在发生污染事故后或分析人员需要对污染物进行溯源时,利用事先建立的水文空间情景库和风险源排污特征库,结合监测点的检测结果,对造成监测点位置水质污染的风险源进行自动化筛选和排污贡献率计算。该方法可用于快速缩小风险源排查范围,提高排查效率。如图1所示,包括如下步骤:在水污染事件追踪前,利用空间查询技术构建水文空间情景库,和建立风险源排污特征数据库;在水污染事件风险源排查时,利用空间查询技术自动化查询出位于监测点位上游的涉嫌风险源;再利用风险源排污特征与监测项目的映射关系进行比对,计算涉嫌风险源对监测点位水质污染的单项排污贡献率和综合排污贡献率,最后确定水污染事件下污染监测点所在水位的涉嫌风险源及相应的排污贡献率。
[0051]
具体地:步骤1、利用空间查询技术,确定基于dem数据获取的水系数据、监测点数据、风险源数据之间的空间关系,包括空间查询径流所在流域;获取空间查询监测点、风险
源点相应的最邻近径流及最邻近点坐标,基于此构建水文空间情景库,本实施例中,利用postgresql数据库对数据进行管理,从而构建水文空间情景库;
[0052]
步骤2、获取所采集的目标区域各风险源污水的污染物数据,将风险源的基础信息及排污特征以数据库的形式管理建立风险源排污特征库,所述风险源排污特征库实时更新;污染物数据包括污染物种类、含量数据,作为风险源的排污特征,所述风险源排污特征库实时更新的数据包括企业定期申报数据或不定期现场检查数据,以此为更新手段,更新区域内风险源排污特征数据库。
[0053]
步骤3、使用空间查询技术自动化确定监测点位和风险源的上下游关系,初步筛选出位于监测站上游的可能影响监测点位水质的风险源(涉嫌风险源);
[0054]
步骤4、针对步骤3.初步筛选出的涉嫌风险源,对于超出水质标准的监测项目或重点观察的监测项目,根据监测点的检测项目和风险源排污特征映射关系,从风险源排污特征库中提取涉嫌风险源相关信息,计算涉嫌风险源影响监测点位水质的排污贡献率,最后根据输出的综合排污贡献率的大小判断涉嫌风险源污染监测点位水质的贡献程度。涉嫌风险源综合排污贡献率越大,监测点位水质污染可能受该风险源的影响越大。
[0055]
具体地,所述步骤1具体包括如下步骤:
[0056]
步骤1.1、空间查询径流所在流域:利用空间查询技术确定区域内各径流段所在流域;
[0057]
步骤1.2、空间查询各监测点最邻近径流段及对应的最邻近点:利用空间查询技术确定各监测点最邻近径流段及对应的最邻近点坐标;
[0058]
步骤1.3、空间查询各风险源最邻近径流段及对应的最邻近点:利用空间查询技术确定各风险源最邻近径流段及对应的最邻近点坐标,本实施例中,监测点、风险源点相应的最邻近径流及最邻近点的关系如图2所示。
[0059]
具体地,所述步骤3中,监测点所在同一流域上游风险源、监测点最邻近径流上游流域内风险源的排污都有可能对该监测点位水质产生影响。因此,本方法中将监测点的上游风险源按流域分为两个部分,包括与监测点同一流域的上游风险源和上游k阶流域风险源(k≥1),此处k代表与监测点最邻近径流邻接的流域的阶数。通常将k设置为可追溯的最高阶流域,从而将监测点上游所有风险源纳入溯源范围,可以通过调整k值从而调整上游风险源搜索范围。
[0060]
步骤3包括如下步骤:步骤3.1、空间查询同一流域的上游风险源,具体地,如图3所示,通过对比监测点在最邻近径流段的最邻近点位(以下简称监测点最邻近点)及其同一流域内风险源最邻近径流段的最邻近点位(以下简称风险源最邻近点)到监测点最临近径流段上游截断点的距离,判断风险源是否位于监测点上游,若监测点到该截断点的距离大于风险源到该截断点的距离,则该风险源属于监测点的上游风险源,该风险源为涉嫌风险源;否则,该风险源被判断为不影响该监测点位水质,不作为涉嫌风险源;
[0061]
步骤3.2、如图5所示,空间查询上游k阶流域内风险源:通过查找监测点所在径流上游第1阶径流段所在的流域,并向上不断查找上游第2,
…
,k阶邻接流域,最后将位于上游k阶流域内所有的风险源同样列入涉嫌风险源集合中。
[0062]
为了自动化的管理,利用postgresql数据库的空间查询技术将步骤3的流程自动化。
[0063]
具体地,流程自动化具体包括查询同一流域的上游风险源流程和查询上游k阶流域内风险源流程:
[0064]
其中,如图4所示,查询同一流域的上游风险源流程包括:
[0065]
步骤3a、利用postgresql数据库的st_dumppoints和st_makeline函数将监测点的最邻近径流段按折点进行拆分,分为多个按上下游顺序连接的子径流段;
[0066]
步骤3b、按所拆分的上下游顺序,利用st_distance函数查找与监测点最邻近点距离为0的子径流段,计算该子径流段的上游截断点和监测点最邻近点之间的距离,并与该子径流段上游的所有子径流段长度累加,得到监测点最邻近点位到径流段上游截断点的距离;
[0067]
步骤3c、同样的方式可以获得同一流域各风险源最邻近点到径流段上游截断点的距离,若此距离小于或等于监测点最邻近点到径流段上游截断点的距离,则该风险源为监测点同一流域的上游风险源;
[0068]
步骤3d、生成该监测点同一流域上游风险源集合;
[0069]
如图6所示,查询上游k阶流域内风险源流程包括:
[0070]
步骤3e、利用水文空间情景库中径流表的上游截断点id字段和下游截断点id字段内连接获取径流上游1阶相邻流域,生成径流段上游1阶邻接径流段所在流域表;
[0071]
步骤3f、利用该表循环查找监测点所属径流段的上游k阶流域,将位于这些上游k阶流域内的风险源同样列为涉嫌风险源;
[0072]
步骤3g、生成该监测点上游k阶流域风险源集合;
[0073]
与步骤3d、中查询的监测点同一流域上游风险源集合合并,生成该监测点上游涉嫌风险源集合。
[0074]
进一步地,所述步骤4具体包括如下步骤:
[0075]
步骤4.1、确定进行比对的监测项目集合:进行比对的监测项目与所构建的监测项目与风险源排污特征的映射关系相结合,用于从风险源排污特征库中筛选排污特征进行贡献率的计算;其中,所述集合可以是分析人员重点观察的监测项目集合,也可以使用超出某个水质标准(如生活饮用水标准gb5749
‑
2006)的监测项目集合,
[0076]
步骤4.2、提取初步筛选风险源及相关排污特征:利用监测项目与风险源排污特征映射关系,根据步骤4.1确定的进行比对的监测项目,获取进行比对的风险源排污特征集合;根据进行比对的风险源排污特征集合以及步骤3获取的筛选后上游风险源集合,从风险源排污特征库中查找初步筛选后的涉嫌风险源的排污特征和相关信息;
[0077]
步骤4.3、计算涉嫌风险源单项排污贡献率:根据步骤4.2中提取的涉嫌风险源数据和监测数据,可计算风险源a排出的污水对该点位水质中污染物i的单项排污贡献率p
′
a
(i):
[0078]
[0079][0080]
其中风险源a对应污染物i的排污特征浓度为c
a
(i),风险源点位到监测点位的欧氏距离为d
a
;监测点记录的污染物i的浓度c(i);
[0081]
步骤4.4、计算涉嫌风险源综合排污贡献率:
[0082]
根据步骤4.3的计算结果,进一步计算风险源a综合影响该监测点位水质的综合排污贡献率prob
a
:
[0083][0084]
实施例1
[0085]
本实施例以辽宁省大连市某区域水污染事件为例对本方法的流程进行具体的阐述。
[0086]
步骤1.建立水文空间情景库
[0087]
选定辽宁省大连市某区域附近流域作为目标区域,获取目标区域的dem数据和行政区划数据,根据《水体达标方案编制技术指南》(试行)中的控制单元细化分解技术,利用arcgis软件中的hydrology modeling模块提取河网数据及集水区域数据。并获取监测点及风险源基础信息,如监测点唯一编号、坐标(经纬度),以及监测记录信息,包括监测时间、监测项目及对应的监测值;风险源唯一编号、对应企业名称、坐标(经纬度)。
[0088]
利用空间查询技术,空间查询目标区域径流所在流域;空间查询监测点、风险源点相应的最邻近径流及最邻近点坐标;利用postgresql数据库对数据进行管理,从而构建水文空间情景库。
[0089]
步骤1.1.空间查询径流所在流域
[0090]
利用空间查询技术确定区域内各径流段所在流域。
[0091]
步骤1.2.空间查询各监测点最邻近径流段及对应的最邻近点
[0092]
利用空间查询技术确定各监测点最邻近径流段及对应的最邻近点坐标。
[0093]
步骤1.3空间查询各风险源最邻近径流段及对应的最邻近点
[0094]
利用空间查询技术确定各风险源最邻近径流段及对应的最邻近点坐标。
[0095]
步骤2.建立风险源排污特征库
[0096]
利用所采集的目标区域各风险源污水的污染物数据,包括污染物种类、含量等信息作为风险源的排污特征,建立目标区域风险源排污特征库。
[0097]
步骤3.初步筛选风险源
[0098]
步骤3.1.空间查询同一流域的上游风险源
[0099]
利用postgresql数据库的空间查询技术编写步骤3.1.空间查询同一流域的上游风险源查询函数,自动化查询同一流域的上游风险源结合,查询结果如
[0100]
表1:
[0101]
表1监测点同一流域上游风险源
[0102]
序号风险源id1d4ce86c***
28cf416cf***3025b3e4***
[0103]
步骤3.2.空间查询上游k阶流域内风险源
[0104]
利用postgresql数据库的空间查询技术编写步骤3.2.空间查询上游k阶流域内风险源查询函数,自动化查询上游k阶流域内风险源,本实例中设置k=1,查询结果示例如表3:
[0105]
表3监测点上游k阶流域内风险源
[0106][0107][0108]
步骤4.计算涉嫌风险源综合排污贡献率
[0109]
步骤4.1.确定进行比对的监测项目集合
[0110]
本实例根据超出生活饮用水标准(gb5749
‑
2006)监测项目作为进行比对的监测项目集合。
[0111]
步骤4.2.提取初步筛选风险源及相关排污特征
[0112]
根据监测站监测项目与风险源排污特征之间的内在联系设计监测项目和排污特征字段映射表,本实例中构建映射表示意如表1。利用监测点的检测项目和风险源排污特征映射关系,根据步骤4.1确定的超出生活饮用水标准(gb5749
‑
2006)监测项目,获取进行比对的风险源排污特征集合以及步骤3获取的筛选后上游风险源集合,从风险源排污特征库中查找初步筛选后的涉嫌风险源的排污特征和相关信息。
[0113]
表1监测项目和排污特征字段映射表示例
[0114]
id监测项目风险源排污特征1铅总铅出口浓度指标值_毫克每升2镉总镉出口浓度指标值_毫克每升3汞总汞出口浓度指标值_毫克每升4六价铬六价铬出口浓度指标值_毫克每升
………………
[0115]
步骤4.3.计算涉嫌风险源单项排污贡献率
[0116]
根据步骤4.2中提取的涉嫌风险源数据和监测数据,可计算风险源排出污水对该监测点位水质中污染物的单项排污贡献率。
[0117]
步骤4.4.计算涉嫌风险源综合排污贡献率
[0118]
根据步骤4.3的计算结果,进一步计算风险源综合影响该监测点位水质的综合排污贡献率。本案例下该水污染事件下涉嫌风险源的综合排污贡献率结果如表4所示:
[0119]
表4涉嫌风险源的综合排污贡献率
[0120]
序号风险源id风险源综合排污贡献率10756649b***0.76525a432cf7***0.1243ffc51c3b***0.1114d4ce86c***0.00058cf416cf***0.0006025b3e4***0.00072800e0ed***0.00088b71d9e1***0.000
[0121]
上述计算完成后,根据输出综合排污贡献率的大小可判断涉嫌风险源污染监测点位水质的贡献程度,涉嫌风险源综合排污贡献率越大,监测点位水质污染可能受该风险源的影响越大。
[0122]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1