一种基于多头自注意力和置换注意力的相机定位方法
1.本发明属于计算机视觉及人工智能技术领域,涉及一种基于多头自注意力和置换注意力的相机定位方法。
背景技术:
2.从图像中恢复相机的位姿是计算机视觉的基本问题之一。准确估计相机的位姿是增强现实、自主导航和机器人技术应用的关键,其中定位对其性能至关重要。近年来,基于深度学习的视觉定位研究不断增多,其中以卷积神经网络为代表的深度学习的方法在计算机视觉领域发挥了非常重要的作用,这些深度网络在提取图片特征,找出潜在规律等方面相比传统方法效果显著,所以我们考虑把深度学习应用的相机位姿估计领域,直接让深度网络学习图片之间的几何关系,实现端到端的位姿估计。这个过程完全摒弃了传统方法中的特征提取、特征匹配、图优化等步骤,根据输入的图片直接得到相机的姿态。基于深度学习的代表作是posenet,它把位姿预测视为回归问题,其变种的模型使用了不同的特征提取网络或者几何约束等,尽管这些技术总体上表现出良好的性能,但它们在面对动态对象或照明变化时缺乏鲁棒性,在场景高度可变的室外数据集中尤为明显。进一步的技术考虑了使用多张图像作为网络的输入,在连续帧之间引入相对姿势作为附加约束,生成更精确的定位结果并减少许多异常值。然而,较大的区域可能包含更多局部相似的外观,从而会降低定位系统的能力,因此需要一种仅使用单幅图像作为输入的能在多种场景下进行准确的端到端位姿估计方法。
技术实现要素:
3.本发明的目的是提供一种基于多头自注意力和置换注意力的相机定位回归方法,解决了在多种场景下的定位问题。
4.本发明所采用的技术方案是,一种基于多头自注意力和置换注意力的相机定位方法,具体按以下步骤实施:
5.步骤1,构建基于transformers bottleneck结构和置换注意力的相机定位网络;
6.步骤2,将经步骤1建立的神经网络进行训练;
7.步骤3,将经步骤2训练好的网络进行测试。
8.本发明的特点还在于:
9.其中步骤1的具体实施过程包括:视觉编码模块、置换注意力模块和位姿回归模块三部分,具体按以下步骤实施:
10.步骤1.1,图像输入网络后,首先通过视觉编码模块进行下采样提取特征;
11.步骤1.2,再经过置换注意力模块捕获特征图上的时空依赖关系,输出具有依赖关系的attention map;
12.步骤1.3,最后将计算得到的attention map输入位姿回归器用于回归相机位姿;
13.其中步骤1.1中视觉编码模块具体按以下步骤实施:
14.步骤1.1.1,输入图像,将图片大小设置为256*256,即输入网络的图片尺寸为256*256*3;
15.步骤1.1.2,对输入图像进行一次普通卷积操作,压缩1次h*w,将通道数调整为64通道,并进行bn与relu激活;
16.步骤1.1.3,将步骤1.1.2中所得特征图传入残差卷积块进行13次残差卷积,每个残差卷积后接se通道注意力模块,得到通道数为1024的特征图;
17.步骤1.1.4,将步骤1.1.3所得特征图输入基于transformers bottleneck的残差块进行全局特征提取,最后输出2048通道的特征图;
18.其中基于transformers bottleneck的残差块构造步骤为:
19.首先通过1*1卷积进行通道扩张,并进行bn与relu激活;然后将残差卷积块中的3*3卷积替换为多头自注意力模块并加入相对位置编码信息;然后再通过1*1卷积调整通道数,并进行bn与relu激活;最后再嵌入se模块进行通道层面的特征提取;
20.其中步骤1.2中置换注意力模块具体按以下步骤实施:
21.步骤1.2.1,将特征提取模块所得到的特征图传入置换注意力模块,同时构建通道注意力和空间注意力;
22.步骤1.2.2,该模块将输出特征图的通道进行分组,将分组后的每个子特征继续分为两份,分别提取通道注意力和空间注意力;
23.步骤1.2.3,完成前面两种注意力计算后,需要对其进行集成,首先通过简单的concat进行融合得到,最后,采用通道置换操作进行组间通信,输出具有2048通道的特征图;
24.其中步骤1.3中位姿回归模块具体按以下步骤实施:
25.步骤1.3.1,置换注意力模块融合特征后得到2048维特征图,构造mlp模块;
26.步骤1.3.2,将特征图输入全连接层,得到1*1*2048大小的特征图;
27.步骤1.3.3,将得到的特征图分别输入到两个全连接层,得到两个代表平移和旋转的三维特征向量;
28.步骤1.3.4,将得到的两个三维向量进行concat,最后得到一个六维的位姿向量;
29.其中步骤2中网络训练的数据集分为室内数据集和室外数据集,室内数据集为7scenes,室外数据集为oxford robotcar,具体按以下步骤实施:
30.步骤2.1,加载数据集,初始化权重参数;
31.步骤2.2,将数据集数据进行分割,将70%的图像用于训练,30%的图像用于估计;
32.步骤2.3,采用l1损失函数,每5个epoch之后输出训练损失值;
33.步骤2.4,初始学习率定为5e-5,训练采用学习率自动下降的方式;
34.步骤2.5,训练到600epoch后loss值不在下降,停止训练并保存模型;
35.其中步骤2.2中数据集分割的具体操作过程包括:
36.首先将训练集按照预先设定的batch输入网络,然后将数据集里的图片resize为256像素,再将图像归一化使像素强度在(-1,1)范围之内,在oxford robotcar数据集上,将亮度、对比度和饱和度设置为0.7,色调设置为0.5;
37.其中步骤3中网络测试的具体步骤如下:
38.步骤3.1,加载数据集中的测试图片,并设定相机位姿回归维数;
39.步骤3.2,加载训练后的模型参数并读取测试数据集;
40.步骤3.3,将数据集图像每一帧传入相机回归模型,对像素点进行回归预测;
41.步骤3.4,计算回归位姿的平移和旋转误差。
42.本发明的有益效果是:
43.本发明的一种基于多头自注意力和置换注意力的相机定位方法,该方法使用单目图像作为输入,学习拒绝动态对象和光照条件以获得更好的性能,在室内以及室外数据集都可以高效运行。通过显著性图的可视化,我们展示了网络如何学习拒绝动态对象,从而可以进行准确而鲁棒的相机位姿估计,该模型不需要额外的手工几何损失函数即可进行端到端的训练。
附图说明
44.图1是本发明的一种基于多头自注意力和置换注意力的相机定位方法中的位姿回归网络结构图;
45.图2是本发明的一种基于多头自注意力和置换注意力的相机定位方法的视觉编码器中的transformers bottleneck的残差块结构示意图;
46.图3是本发明的一种基于多头自注意力和置换注意力的相机定位方法中transformers bottleneck的残差块中的多头自注意力模块的结构示意图;
47.图4是本发明的一种基于多头自注意力和置换注意力的相机位定位方法中置换注意力模块的结构示意图。
具体实施方式
48.下面结合附图和具体实施方式对本发明进行详细说明。
49.本发明提供了一种基于多头自注意力和置换注意力的相机定位方法,具体按以下步骤实施:
50.步骤1,构建基于transformer结构和置换注意力的相机定位网络,然后通过视觉编码器提取图像特征,将提取到的图像特征传入置换注意力模块筛选具有鲁棒性的几何特征,再通过简单的concat模块完成特征融合,最后将融合后的特征输入位姿回归器中回归出平移和旋转向量,该网络具体结构如图1所示;
51.其网络结构共分为3个模块:1)视觉编码模块;2)置换注意力模块;3)位姿回归模块。具体按以下步骤实施;
52.步骤1.1,图像输入网络后,首先通过视觉编码模块进行下采样提取特征;
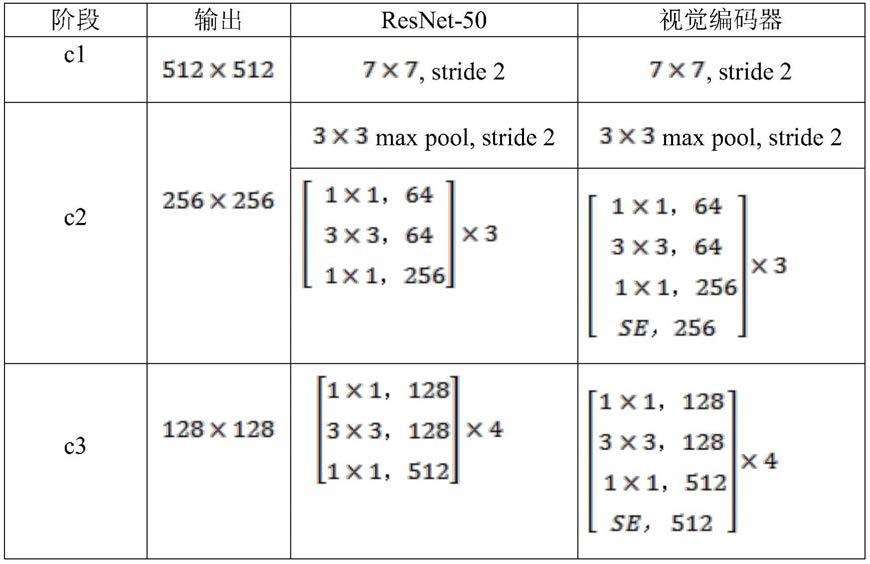
53.步骤1.2,再经过置换注意力模块捕获特征图上的时空依赖关系,输出具有依赖关系的attention map;
54.步骤1.3,最后将计算得到的attention map输入位姿回归器用于回归相机位姿;
55.1)视觉编码模块;对于端到端的位姿回归任务来说,最为重要的是特征提取模块,此模块用于提取图像从低维的线性特征到高维抽象特征,位姿回归网络的大部分参数以及计算量来自于这个模块,本发明为保证精度的同时提取了有利于位姿回归的鲁棒的特征,通过改进一种适用于分类、分割的网络resnet50作为本网络的主干,该网络能够提取到更加鲁棒的特征;
56.resnet有2个基本的块,一个是identity block,输入和输出的维度是一样的,所以可以串联多个;另外一个基本块是conv block,输入和输出的维度是不一样的,所以不能连续串联,它的作用本来就是为了改变特征向量的维度,因为cnn最后都是要把输入图像逐渐转换成尺寸很小但是深度很深的feature map,一般的套路是用统一的比较小的卷积核(比如vgg都是用3*3),但是随着网络深度的增加,输出的通道数也增大,网络学到的东西越来越复杂,所以必须在进入identity block之前,用conv block转换一下维度,这样网络就可以连续接identity block;resnet分为5个stage,其中stage0的结构比较简单,可以视其为对输入的预处理,后4个stage都由bottleneck组成,结构较为相似。stage 1包含3个bottleneck,剩下的3个stage分别包括4、6、3个bottleneck;
57.本发明的视觉编码模块基于resnet50进行改进,其中,将resnet的最后三个bottleneck中的3*3空间卷积替换为全局多头自注意力层,并且在1*1卷积后嵌入了se模块,使得该层在2d特征图上实现全局自我注意,其它残差块只在1*1卷积后嵌入se模块,残差块结构如图2所示;为了使注意力操作位置感知,基于transformer的架构通常使用位置编码,并且相对位置编码更加有利于视觉任务;基于相对位置编码的多头自注意力模块不仅考虑了内容信息,还考虑了不同位置特征之间的相对距离,因此能够有效地将跨对象的信息于位置感知联系起来;transformerbottleneck结构图如图3所示,本网络使用了四个头部,全局注意力模块在2d特征图上执行,其相对位置编码分别为高度和宽度编码,注意力为qk
t
+qr
t
,q、k、r分别代表查询向量、键向量和位置编码向量,视觉编码模块的详细结构如表1所示;
58.表1视觉编码器结构参数对比
59.[0060][0061]
其中步骤1.1中视觉编码模块具体按以下步骤实施:
[0062]
步骤1.1.1,输入图像,将图片大小设置为256*256,即输入网络的图片尺寸为256*256*3;
[0063]
步骤1.1.2,对输入图像进行一次普通卷积操作,压缩1次h*w,将通道数调整为64通道,并进行bn与relu激活;
[0064]
步骤1.1.3,将步骤1.1.2中所得特征图传入残差卷积块进行13次残差卷积,每个残差卷积后接se通道注意力模块,得到通道数为1024的特征图;
[0065]
步骤1.1.4,将步骤1.1.3所得特征图输入基于transformers bottleneck的残差块进行全局特征提取,最后输出2048通道的特征图;
[0066]
其中残差卷积块构造步骤为:
[0067]
首先通过1*1卷积进行通道扩张,并进行bn与relu激活;然后通过3*3卷积进行特征提取;然后通过1*1卷积调整通道,并进行bn与relu激活;每个残差块后接se通道注意力模块进行通道上的特征提取;
[0068]
其中基于transformers的残差块的构造步骤为:
[0069]
首先通过1*1卷积进行通道扩张,并进行bn与relu激活;然后将将残差卷积块中的3*3卷积替换为多头自注意力模块并加入相对位置编码信息;最后通过1*1卷积调整通道,并进行bn与relu激活;
[0070]
其中步骤1.2中置换注意力模块包括通道注意力模块和空间注意力模块两部分,具体按以下步骤实施:
[0071]
步骤1.2.1,将视觉编码模块提取到的特征传入置换注意力模块,同时构建通道注意力和空间注意力。
[0072]
步骤1.2.2,该模块将输出特征进行通道分组,将分组后的每个子特征继续分为两份,分别提取通道特征和空间特征:
[0073]
首先将传入置换注意力模块的特征沿着通道维度进行分组,然后再将分组后的特征沿着通道维度继续拆分成两个分支,一个分支用于学习通道注意力特征,一个分支用于学习空域注意力特征,最后还需要通过spatial与channel注意力模块生成不同的重要性系数;
[0074]
步骤1.2.3,完成前面两种注意力计算后,需要对其进行集成,首先通过简单的
concat进行融合得到。最后,采用通道置换操作进行组间通信,输出具有2048通道的特征图;
[0075]
其中步骤1.3中位姿估计模块的构造步骤为:
[0076]
步骤1.3.1,置换注意力模块融合特征后得到2048维特征图,构造多层感知机(mlp)模块;
[0077]
步骤1.3.2,将特征图输入全连接层,得到1*1*2048大小的特征图;
[0078]
步骤1.3.3,将得到的特征图分别输入到两个全连接层,得到两个代表平移和旋转的三维特征向量;
[0079]
步骤1.3.4,将得到的两个三维向量进行concat,最后得到一个六维的位姿向量;
[0080]
步骤2,网络训练:本发明使用pytorch框架搭建网络结构,使用l1函数作为损失函数,使用adam算法优化训练参数,并在训练过程中采用早停策略防止网络训练过拟合,以达到最优训练效果:
[0081]
对网络进行训练的数据集分为室内数据集和室外数据集,室内数据集为7scenes数据集,室外数据集为oxford robotcar数据集,具体按以下步骤实施:
[0082]
步骤2.1,加载数据集,初始化权重参数;
[0083]
步骤2.2,将数据集数据进行分割,将70%的图像用于训练,30%的图像用于估计:
[0084]
首先将训练集按照预先设定的batch输入网络,然后将数据集里的图片resize为256像素,再将图像归一化使像素强度在(-1,1)范围之内,在oxford robotcar数据集上,我们将亮度、对比度和饱和度设置为0.7,色调设置为0.5,这一增强步骤有利于改进模型在各种天气和气候条件下的泛化能力;
[0085]
步骤2.3,采用l1损失函数,每5个epoch之后输出训练损失值;
[0086]
步骤2.4,初始学习率定为5e-5,训练采用学习率自动下降的方式;
[0087]
步骤2.5,训练到600epoch后loss值不在下降,停止训练并保存模型;
[0088]
步骤3,网络测试:将测试图像输入网络,得到位姿估计结果,并计算平移和旋转的loss值,对网络性能进行评估:
[0089]
步骤3.1,加载数据集中的测试图片,并设定相机位姿回归维数;
[0090]
步骤3.2,加载训练后的模型参数并读取测试数据集;
[0091]
步骤3.3,将数据集图像每一帧传入相机回归模型,对像素点进行回归预测;
[0092]
步骤3.4,计算回归位姿的平移和旋转误差。
[0093]
以下表格说明本发明在测试集上的的效果:
[0094]
表2在7scenes数据集上的网络性能对比
[0095][0096]
表2总结了在7scenes数据集上所有方法的性能,显然,我们可以看到,我们的方法优于其他基于单目图像的方法,与基于单目图像的基线ir-baseline相比,位置精度提高了17%,旋转精度提高了25%,特别是在具有无纹理区域(如fire和pumpkin)和高度重复纹理(如chess)的场景中达到了最佳的性能。在pumpkin场景中将位置误差从0.26m减小到0.19m,在chess场景中将位置误差从0.18m减小到0.11m,这是对现有技术的重大改进,在其他常规场景中仍能达到比基线更高的精度。
[0097]
表3在oxford robotcar数据集上的网络性能对比
[0098][0099]
表3显示了posenet、mapnet、lsg和我们的方法的定量比较。由于训练和测试序列是在不同的时间、不同的条件下捕获的,因此posenet很难处理这些变化,并输出大量异常值的不准确估计。mapnet通过在连续帧之间引入相对姿势作为附加约束,生成更精确的结果并减少许多异常值。然而,较大的区域可能包含更多局部相似的外观,从而降低定位系统的能力。通过采用内容增强,虽然lsg在一定程度上改善了这个问题,但它降低了准确性。相比之下,考虑到内容和移动,我们的模型更有效地解决了这些挑战,与posenet+相比,位置精度提高了67%,旋转精度提高了64%。
[0100]
由于场景动态性和环境外观的高度可变性,摄像机定位在计算机视觉中是一项具有挑战性的任务;本发明提出了一种基于transformer结构和置换注意力的相机定位方法,其中在视觉编码模块中引入了transformers bottleneck结构可以鼓励框架学习几何稳健
的特征,减轻动态对象和照明变化的影响;在位姿回归过程中引入了置换注意力模块,该模块融合了空间和通道上的特征信息,融合后的特征将输入位姿回归器用来指导位姿的回归;经过实验分析,我们的模型在室外和室内数据集上的定位精度得到明显提升。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1