行人图像识别方法及装置与流程
1.本发明涉及人工智能技术领域,尤其涉及一种行人图像识别方法及装置。
背景技术:
2.随着养老社区的全国布局,养老社区越来越多,社区内活动也是丰富多彩,老人需要各种各样的定制服务和生活,随着社区摄像头逐渐增加,随之产生的拍摄视频也越来越多,如何在未来能更高效将这些拍摄的照片或者视频更好的服务于社区中居住的高净值客户,是一个越来越需要迫切解决的问题。因此,从这些拍摄的图片或视频中识别出行人,是一个亟需解决的问题。
3.现有技术中,常采用reid算法进行行人识别,但是reid算法在实际应用场景下的数据非常复杂,由于不同摄像设备之间的差异,同时行人兼具刚性和柔性的特性,外观易受穿着、尺度、遮挡、姿态和视角等影响,所以对reid算法需要很高要求。因为算法落地场景时,由于往往存在更复杂的场景,易出现遮挡问题,从而导致reid算法的行人图像识别鲁棒性不强。
技术实现要素:
4.本发明实施例提出一种行人图像识别方法,用以准确地从大量行人图像中识别出目标行人,鲁棒性强,该方法包括:
5.获取多张行人图像;
6.提取每张行人图像的二维特征矩阵f;
7.根据每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征向量f1;
8.获取预先设定的类别数和基于该类别数预先训练的行人局部类别矩阵p;
9.根据行人局部类别矩阵和每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征矩阵;
10.根据每张行人图像的最像素级别注意力特征向量f1和最像素级别注意力特征矩阵,获得第三特征向量f4;
11.基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。
12.本发明实施例提出一种行人图像识别装置,用以准确地从大量行人图像中识别出目标行人,鲁棒性强,该装置包括:
13.行人图像获取模块,用于获取多张行人图像;
14.二维特征提取模块,用于提取每张行人图像的二维特征矩阵f;
15.最像素级别注意力特征向量提取模块,用于根据每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征向量f1;
16.行人局部类别矩阵获得模块,用于获取预先设定的类别数和基于该类别数预先训
练的行人局部类别矩阵p;
17.最像素级别注意力特征矩阵获得模块,用于根据行人局部类别矩阵和每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征矩阵;
18.第三特征向量获得模块,用于根据每张行人图像的最像素级别注意力特征向量f1和最像素级别注意力特征矩阵,获得第三特征向量f4;
19.检索模块,用于基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。
20.本发明实施例还提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述行人图像识别方法。
21.本发明实施例还提出了一种计算机可读存储介质,所述计算机可读存储介质存储有执行上述行人图像识别方法的计算机程序。
22.在本发明实施例中,获取多张行人图像;提取每张行人图像的二维特征矩阵;根据每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征向量;获取预先设定的类别数和基于该类别数预先训练的行人局部类别矩阵;根据行人局部类别矩阵和每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征矩阵;根据每张行人图像的最像素级别注意力特征向量和最像素级别注意力特征矩阵,获得第三特征向量;基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。在上述过程中,可以获取每张行人图像的最像素级别注意力特征向量,以及最像素级别注意力特征矩阵,其原理是将相同属性的像素聚合,而预先训练的行人局部类别矩阵,使得可以实现以弱监督的方式找到人体不同部位的特征,从而提高复杂的场景下的鲁棒性,提高行人识别准确度。
附图说明
23.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
24.图1为本发明实施例中行人图像识别方法的流程图;
25.图2为本发明实施例中获取行人图像的流程图;
26.图3为本发明实施例中提取二维特征矩阵的流程图;
27.图4为本发明实施例中获得最像素级别注意力特征向量的流程图;
28.图5为本发明实施例中获得最像素级别注意力特征矩阵的流程图;
29.图6为本发明实施例中获得第三特征向量的流程图;
30.图7为本发明实施例中图像检索的流程图;
31.图8为本发明实施例中行人图像识别装置的示意图;
32.图9为本发明实施例中计算机设备的示意图。
具体实施方式
33.为使本发明实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本发明实施例做进一步详细说明。在此,本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
34.在本说明书的描述中,所使用的“包含”、“包括”、“具有”、“含有”等,均为开放性的用语,即意指包含但不限于。参考术语“一个实施例”、“一个具体实施例”、“一些实施例”、“例如”等的描述意指结合该实施例或示例描述的具体特征、结构或者特点包含于本技术的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。各实施例中涉及的步骤顺序用于示意性说明本技术的实施,其中的步骤顺序不作限定,可根据需要作适当调整。
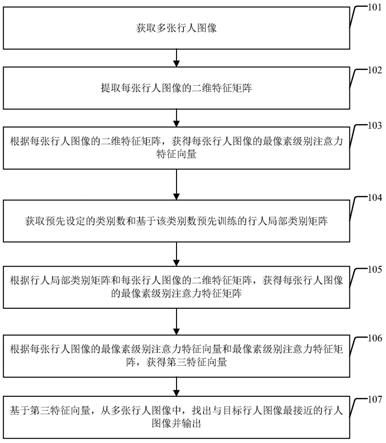
35.图1为本发明实施例中行人图像识别方法的流程图,如图1所示,该方法包括:
36.步骤101,获取多张行人图像;
37.步骤102,提取每张行人图像的二维特征矩阵f;
38.步骤103,根据每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征向量f1;
39.步骤104,获取预先设定的类别数和基于该类别数预先训练的行人局部类别矩阵p;
40.步骤105,根据行人局部类别矩阵和每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征矩阵;
41.步骤106,根据每张行人图像的最像素级别注意力特征向量f1和最像素级别注意力特征矩阵,获得第三特征向量f4;
42.步骤107,基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。
43.在本发明实施例中,可以获取每张行人图像的最像素级别注意力特征向量,以及最像素级别注意力特征矩阵,其原理是将相同属性的像素聚合,而预先训练的行人局部类别矩阵,使得可以实现以弱监督的方式找到人体不同部位的特征,从而提高复杂的场景下的鲁棒性,提高行人识别准确度。
44.具体实施时,在步骤102
‑
步骤106中,基于行人像素和局部注意力模型ppam(pixel
‑
aware and part
‑
aware atention model)来实现,是对reid算法的优化,ppam模型可基于行人图片的注意力模型提取方法,获得最像素级别注意力特征向量f1,同时进一步的利用像素级别特征,预先训练一个行人局部类别矩阵,从而获得最像素级别注意力特征矩阵,最终可得到一个第三特征向量,用于检索,即找出与目标行人图像最接近的行人图像并输出。
45.图2为本发明实施例中获取行人图像的流程图,在一实施例中,获取多张行人图像,包括:
46.步骤201,获取设定时长内的视频数据;
47.步骤202,对所述视频数据进行抽帧,获得多张初始图像;
48.步骤203,从多张初始图像中,获得多个行人的目标框;
49.步骤204,将每个行人的目标框裁剪成行人图片后,变换为预设大小的行人图像。
50.在上述实施例中,当获得设定时长的摄像头的视频数据后,对视频数据进行抽帧,获得多张初始图像。之后,需使用目标检测算法获得行人的目标框,该目标检测算法可以有多种,例如,yolov5算法,在获得行人的目标框后,将行人根据目标框裁剪成行人图片后,统一将图片变换成(256,128,3)图像,及预设大小的行人图像。
51.图3为本发明实施例中提取二维特征矩阵的流程图,在一实施例中,提取每张行人图像的二维特征矩阵,包括:
52.步骤301,提取每张行人图像的特征矩阵;
53.步骤302,将每张行人图像的特征矩阵打扁为对应的二维特征矩阵。
54.在上述实施例中,提取每张行人图像的特征矩阵时,使用的模型不唯一,例如,可以使用resnet50,去掉resnet50最后的池化层和全连接层,获得特征矩阵,例如,特征长、宽和通道数为(16,8,2048)的特征矩阵。
55.行人图像背景区域具有不同的特征,增加了获取目标行人人鲁棒特征的难度。因此,本发明实施例采用ppam模型中的自我注意机制来捕捉完整的图像上下文信息,可以得到像素级上下文感知的特征矩阵。其中,使用一个(1,1)的卷积,使特征矩阵矩阵转化为更小的维度(16,8,512),然后将特征矩阵转长宽打扁化为二维特征矩阵f,大小为(128,512),128代表长宽相乘,512代表通道数。
56.图4为本发明实施例中获得最像素级别注意力特征向量的流程图,在一实施例中,根据每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征向量,包括:
57.步骤401,计算每个二维特征矩阵中每个之间像素的注意力权重;
58.步骤402,对每张行人图像,基于该行人图像对应的二维特征矩阵中每个像素之间的注意力权重,计算聚合了该二维特征矩阵所有位置的像素上下文信息的像素特征向量;
59.步骤403,将每张行人图像对应的二维特征矩阵中所有像素特征向量拼接在一起,并使用两层全连接层得到每张行人图像的最像素级别注意力特征向量。
60.在上述实施例中,首先根据如下公式计算二维特征矩阵f中每个像素之间的注意力权重:
[0061][0062][0063]
其中,s
i,j
为像素i之间的注意力权重,i,j∈1,2,3.....128;f
i
为二维特征矩阵f中像素i的特征向量;w
q
,w
k
为两个投影矩阵,大小都为(512,512)。
[0064]
接着采用如下公式,计算聚合了该二维特征矩阵所有位置的像素上下文信息的像素特征向量:
[0065][0066]
其中,为像素特征向量,大小为(1,512);w
v
是投影矩阵,大小为(512,512)。
[0067]
最后得到的每张行人图像的最像素级别注意力特征向量f1,大小为(128,512)。
[0068]
在步骤104中,获取预先设定的类别数和基于该类别数预先训练的行人局部类别矩阵。行人局部类别矩阵是为了进行局部类别提取,在本发明实施例中,用注意力机制将行人图像分为多个类别,类别数与场景复杂度有关,例如可以分为8个部分,也就是类别数为8,因此,训练出的行人局部类别矩阵p的大小为(8,512)。
[0069]
图5为本发明实施例中获得最像素级别注意力特征矩阵的流程图,在一实施例中,根据行人局部类别矩阵和每张行人图像的二维特征矩阵f,获得每张行人图像的最像素级别注意力特征矩阵,包括:
[0070]
步骤501,对于每张行人图像,根据所述行人局部类别矩阵p和该行人图像对应的二维特征矩阵f,计算每个类别的权重参数p
i,j
;
[0071]
步骤502,根据每个类别的权重参数p
i,j
,计算每张行人图像对应的聚合了所有类别信息的像素特征向量
[0072]
步骤503,将每张行人图像对应的所有类别特征向量并接在一起,并使用两层全连接层得到最像素级别注意力特征矩阵。
[0073]
在上述实施例中,采用如下公式,计算每个类别的权重参数p
i,j
:
[0074][0075][0076]
其中,p
i,j
为每个类别的权重参数,i∈1,2,3.....8;j∈1,2,3.....128;p为每个类别的特征矩阵;f为二维特征矩阵f中每个像素的特征向量;w
,w
kk
为两个投影矩阵,大小都为(512,512)。
[0077]
采用如下公式,根据每个类别的权重参数p
i,j
,计算每张行人图像对应的聚合了所有类别信息的像素特征向量
[0078][0079]
其中,的大小为(1,512);w
vv
为投影矩阵,大小为(512,512)。
[0080]
图6为本发明实施例中获得第三特征向量的流程图,在一实施例中,根据每张行人图像的最像素级别注意力特征向量f1和最像素级别注意力特征矩阵,获得第三特征向量f4,包括:
[0081]
步骤601,将每张行人图像对应的最像素级别注意力特征矩阵进行全局平均池化,得到类别信息向量p1;
[0082]
步骤602,将每张行人图像的最像素级别注意力特征向量f1进行全局平均池化,获得第一特征向量f2;
[0083]
步骤603,将每张行人图像的类别信息向量p1使用sigmoid函数激活点乘第一特征向量f2,获得第二特征向量f3;
[0084]
步骤604,将每张行人图像的第二特征向量f3和第一特征向量f2拼接在一起,得到第三特征向量f4。
[0085]
在上述实施例中,f2的大小为(1,512),f4的大小为(1,1024)。
[0086]
图7为本发明实施例中图像检索的流程图,在一实施例中,基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像,包括:
[0087]
步骤701,分别计算每张行人图像的第三特征向量f4与目标行人图像的欧式距离;
[0088]
步骤702,确定欧式距离最小的行人图像为与目标行人图像最接近的行人图像。
[0089]
在上述实施例中,步骤701和步骤702可以使用任意高效快速的特征向量搜索工具,例如milvus。
[0090]
本发明实施例提出的行人图像识别方法可以应用到以下两种场景中。
[0091]
场景一:当老人走丢时,找到老人近期照片,提取老人编码特征,作为目标行人图像,调取社区和附近摄像头的视频数据,通过与目标行人图像对比,可识别出所有的该老人的行人图像,从而找到老人所有运动轨迹和最后经过场景,为找到老人或者为找寻老人提供有力线索。
[0092]
场景二:目前有很多医学模型,如防跌倒模型,该模型可以通过各种指标提供描述老人可能跌倒的风险,该模型的完善和准确性提高需要更多维度的数据,例如,老人的图形,因此可以用本发明方法快速标注分析老人行动轨迹,提炼如运动次数、外出次数、外出时间等等更多的老人行动特征,为防跌倒模型的算法人员提供更多数据,从而为养老社区提供更好的的医学预见性能力。
[0093]
在本发明实施例提出的方法中,获取多张行人图像;提取每张行人图像的二维特征矩阵;根据每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征向量;获取预先设定的类别数和基于该类别数预先训练的行人局部类别矩阵;根据行人局部类别矩阵和每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征矩阵;根据每张行人图像的最像素级别注意力特征向量和最像素级别注意力特征矩阵,获得第三特征向量;基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。在上述过程中,可以获取每张行人图像的最像素级别注意力特征向量,以及最像素级别注意力特征矩阵,其原理是将相同属性的像素聚合,而预先训练的行人局部类别矩阵,使得可以实现以弱监督的方式找到人体不同部位的特征,从而提高复杂的场景下的鲁棒性,提高行人识别准确度。
[0094]
本发明实施例还提出一种行人图像识别装置,其原理与行人图像识别方法类似,这里不再赘述。
[0095]
图8为本发明实施例中行人图像识别装置的示意图,如图8所示,该装置包括:
[0096]
行人图像获取模块801,用于获取多张行人图像;
[0097]
二维特征提取模块802,用于提取每张行人图像的二维特征矩阵;
[0098]
最像素级别注意力特征向量提取模块803,用于根据每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征向量;
[0099]
行人局部类别矩阵获得模块804,用于获取预先设定的类别数和基于该类别数预先训练的行人局部类别矩阵;
[0100]
最像素级别注意力特征矩阵获得模块805,用于根据行人局部类别矩阵和每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征矩阵;
[0101]
第三特征向量获得模块806,用于根据每张行人图像的最像素级别注意力特征向量和最像素级别注意力特征矩阵,获得第三特征向量;
[0102]
检索模块807,用于基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。
[0103]
在一实施例中,行人图像获取模块具体用于:
[0104]
获取设定时长内的视频数据;
[0105]
对所述视频数据进行抽帧,获得多张初始图像;
[0106]
从多张初始图像中,获得多个行人的目标框;
[0107]
将每个行人的目标框裁剪成行人图片后,变换为预设大小的行人图像。
[0108]
在一实施例中,二维特征提取模块具体用于:
[0109]
提取每张行人图像的特征矩阵;
[0110]
将每张行人图像的特征矩阵打扁为对应的二维特征矩阵。
[0111]
在一实施例中,最像素级别注意力特征向量提取模块具体用于:
[0112]
计算每个二维特征矩阵中每个之间像素的注意力权重;
[0113]
对每张行人图像,基于该行人图像对应的二维特征矩阵中每个像素之间的注意力权重,计算聚合了该二维特征矩阵所有位置的像素上下文信息的像素特征向量;
[0114]
将每张行人图像对应的二维特征矩阵中所有像素特征向量拼接在一起,并使用两层全连接层得到每张行人图像的最像素级别注意力特征向量。
[0115]
在一实施例中,最像素级别注意力特征矩阵获得模块具体用于:
[0116]
对于每张行人图像,根据所述行人局部类别矩阵和该行人图像对应的二维特征矩阵,计算每个类别的权重参数;
[0117]
根据每个类别的权重参数,计算每张行人图像对应的聚合了所有类别信息的像素特征向量;
[0118]
将每张行人图像对应的所有类别特征向量拼接在一起,并使用两层全连接层得到最像素级别注意力特征矩阵。
[0119]
在一实施例中,第三特征向量获得模块具体用于:
[0120]
将每张行人图像对应的最像素级别注意力特征矩阵进行全局平均池化,得到类别信息向量;
[0121]
将每张行人图像的最像素级别注意力特征向量进行全局平均池化,获得第一特征向量;
[0122]
将每张行人图像的类别信息向量使用sigmoid函数激活点乘第一特征向量,获得第二特征向量;
[0123]
将每张行人图像的第二特征向量和第一特征向量拼接在一起,得到第三特征向量。
[0124]
在一实施例中,检索模块具体用于:
[0125]
分别计算每张行人图像的第三特征向量与目标行人图像的欧式距离;
[0126]
确定欧式距离最小的行人图像为与目标行人图像最接近的行人图像。
[0127]
综上所述,在本发明实施例提出的装置中,行人图像获取模块,用于获取多张行人图像;二维特征提取模块,用于提取每张行人图像的二维特征矩阵;最像素级别注意力特征向量提取模块,用于根据每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征向量;行人局部类别矩阵获得模块,用于获取预先设定的类别数和基于该类别
数预先训练的行人局部类别矩阵;最像素级别注意力特征矩阵获得模块,用于根据行人局部类别矩阵和每张行人图像的二维特征矩阵,获得每张行人图像的最像素级别注意力特征矩阵;第三特征向量获得模块,用于根据每张行人图像的最像素级别注意力特征向量和最像素级别注意力特征矩阵,获得第三特征向量;检索模块,用于基于第三特征向量,从多张行人图像中,找出与目标行人图像最接近的行人图像并输出。在上述过程中,可以获取每张行人图像的最像素级别注意力特征向量,以及最像素级别注意力特征矩阵,其原理是将相同属性的像素聚合,而预先训练的行人局部类别矩阵,使得可以实现以弱监督的方式找到人体不同部位的特征,从而提高复杂的场景下的鲁棒性,提高行人识别准确度。
[0128]
本技术的实施例还提供一种计算机设备,图9为本发明实施例中计算机设备的示意图,该计算机设备能够实现上述实施例中的行人图像识别方法中全部步骤,所述电子设备具体包括如下内容:
[0129]
处理器(processor)901、存储器(memory)902、通信接口(communications interface)903和总线904;
[0130]
其中,所述处理器901、存储器902、通信接口903通过所述总线904完成相互间的通信;所述通信接口903用于实现服务器端设备、检测设备以及用户端设备等相关设备之间的信息传输;
[0131]
所述处理器901用于调用所述存储器902中的计算机程序,所述处理器执行所述计算机程序时实现上述实施例中的行人图像识别方法中的全部步骤。
[0132]
本技术的实施例还提供一种计算机可读存储介质,能够实现上述实施例中的行人图像识别方法中全部步骤,所述计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述实施例中的行人图像识别方法的全部步骤。
[0133]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0134]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0135]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0136]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一
个方框或多个方框中指定的功能的步骤。
[0137]
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1