一种数据处理方法、装置及设备与流程
本发明涉及数据采集,特别是指一种数据处理方法、装置及设备。
背景技术:
1、数据处理和分发系统(apache nifi,以下简称nifi)是一款功能非常强大的实现数据采集、数据清洗,将数据从来源端经过抽取、转换并加载至目的端(etl,extract-transform-load)的开源的工具。nifi支持图形化操作,对流程设计人员友好;内置200多个处理器(processor),满足大部分数据采集和清洗的需求;支持数据流的全链路追踪,实时查看数据流向;支持单机、集群、docker等灵活部署,适用于多种使用环境。鉴于nifi有这么多优势特性,所以在生产环境的etl场景中得到了广泛的使用。
2、nifi在进行数据处理的时候,处理的对象是流文件(flowfile)。如图1所示,一个flowfile包含两部分内容:元数据(metadata)和业务数据(data)。其中,metadata主要包含了flowfile的属性,如唯一标识符、名称、大小和其他一些自定义属性;data是这个flowfile包含的etl数据。metadata保存在内存中,可以修改。业务数据不可修改,指向一个本地文件系统的真实文件
3、在相关技术中,整个etl流程处理的对象都是flowfile。由于需要多个processor对数据进行多次处理,所以导致要多次读取flowfile,并生成新的flowfile,导致整个etl流程的处理速度很慢,无法高性能地处理大量的数据。随着数据接入数量越来越大,这种“整存整取”的处理方式的劣势越来越凸显出来。
技术实现思路
1、本发明要解决的技术问题是提供一种数据处理方法、装置及设备,解决如何减少新的flowfile产生,以及减少flowfile的读写过程的问题。
2、为解决上述技术问题,本发明的实施例提供技术方案如下:
3、本发明实施例提供了一种数据处理方法,所述方法包括:
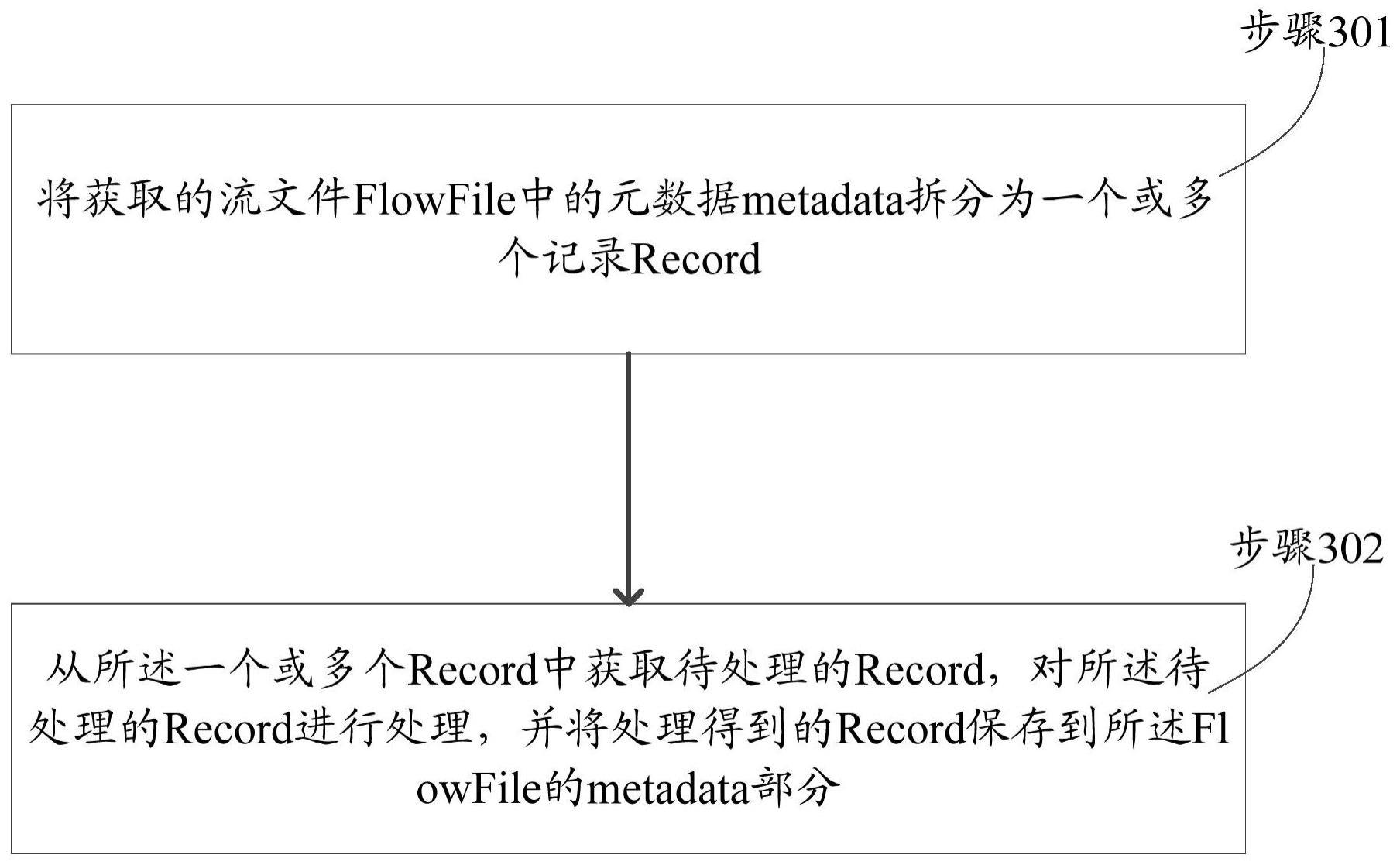
4、将获取的流文件flowfile中的元数据metadata拆分为一个或多个记录record;
5、从所述一个或多个record中获取待处理的record,对所述待处理的record进行处理,并将处理后的record保存到所述flowfile的metadata部分。
6、在本技术的一个优先实施例中,将获取的flowfile中的元数据拆分为一个或多个record,包括:
7、根据元数据的数据类型,将获取的流文件flowfile中的元数据metadata拆分为一个或多个record。
8、在本技术的一个优先实施例中,根据数据类型,将获取的flowfile中的元数据metadata拆分为一个或多个record,包括:
9、如果所述flowfile中的metadata的数据类型包括:逗号分隔值csv文件和/或数据库数据,则所述flowfile中的metadata按行拆分,一行metadata拆分为一个record;
10、和/或,
11、如果所述flowfile中的metadata的数据类型为流式数据,则所述flowfile中的metadata按流式数据中的消息message拆分,一个message拆分为一个record。
12、在本技术的一个优先实施例中,所述record的信息通过关键字-值key-value的方式存放在所述flowfile的元数据部分。
13、在本技术的一个优先实施例中,从所述一个或多个record中获取待处理的record,对所述待处理的record进行处理,并将处理后的record保存到所述flowfile的metadata部分,包括:
14、从所述一个或多个record中获取待过滤的record,对所述待过滤的record进行过滤处理,并将过滤处理得到的record保存到所述flowfile的metadata部分。
15、在本技术的一个优先实施例中,从所述一个或多个record中获取待处理的record,对所述待处理的record进行处理,并将处理后的record保存到所述flowfile的metadata部分,还包括:
16、从所述一个或多个record中获取待转换的record,对所述待转换的record进行转换处理,并将转换处理得到的record保存到所述flowfile的metadata部分。
17、在本技术的一个优先实施例中,从所述一个或多个record中获取待处理的record,对所述待处理的record进行处理,并将处理后的record保存到所述flowfile的metadata部分,还包括:
18、从所述一个或多个record中获取待计算的record,对所述待计算的record进行计算处理,并将计算处理得到的record保存到所述flowfile的metadata部分。
19、在本技术的一个优先实施例中,所述方法还包括:
20、将所述flowfile的metadata部分中的一个或多个record存储到数据库中。
21、本发明实施例还提供了一种数据处理装置,所述装置包括:
22、第一处理模块,用于将获取的flowfile中的metadata拆分为一个或多个record;
23、第二处理模块,用于从所述一个或多个record中获取待处理的record,对所述待处理的record进行处理,并将处理后的record保存到所述flowfile的metadata部分。
24、在本技术的一个优先实施例中,所述第一处理模块包括:
25、记录生成单元,用于根据元数据的数据类型,将获取的flowfile中的元数据metadata拆分为一个或多个记录record。
26、在本技术的一个优先实施例中,所述记录生成单元,具体用于如果所述flowfile中的metadata的数据类型包括:逗号分隔值csv文件和/或数据库数据,则所述flowfile中的metadata按行拆分,一行metadata拆分为一个record;
27、如果所述flowfile中的metadata的数据类型为流式数据,则所述flowfile中的metadata按流式数据中的消息message拆分,一个message拆分为一个record。
28、在本技术的一个优先实施例中,所述record的信息通过key-value的方式存放在所述flowfile的元数据部分。
29、在本技术的一个优先实施例中,所述第二处理模块,包括:
30、过滤单元,用于从所述一个或多个record中获取待过滤的record,对所述待过滤的record进行过滤处理,并将过滤处理后的record保存到所述flowfile的metadata部分。
31、在本技术的一个优先实施例中,所述第二处理模块,还包括:
32、转换单元,用于从所述一个或多个record中获取待转换的record,对所述待转换的record进行转换处理,并将转换处理后的record保存到所述flowfile的metadata部分。
33、在本技术的一个优先实施例中,所述第二处理模块模块,还包括:
34、计算单元,用于从所述一个或多个record中获取待计算的record,对所述待计算的record进行计算处理,并将计算处理后的record保存到所述flowfile的metadata部分。
35、在本技术的一个优先实施例中,还包括:
36、存储模块,用于将所述flowfile的metadata部分中的一个或多个record存储到数据库中。
37、本发明实施例还提供了一种数据采集的设备,包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现所述一种数据处理方法的步骤。
38、本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的数据处理方法中的步骤。
39、本发明的实施例具有以下有益效果:通过将flowfile分割为一个或多个record,并将这些record的信息存储在flowfile的metadata部分,是存储在内存中的,后续对这些record进行过滤、转换和计算就能够基于这些记录record进行操作,而无需对整个的flowfile进行操作,因此,避免了中间flowfile的生成,也减少了对于flowfile的多次读写。
- 还没有人留言评论。精彩留言会获得点赞!