一种基于国产CPU实现公文版面分析的方法与流程
一种基于国产cpu实现公文版面分析的方法
技术领域
1.本发明涉及国产软硬件适配技术领域,特别涉及一种基于国产cpu实现公文版面分析的方法。
背景技术:
2.在国家的大力扶持下,具有自主知识产权的全国产软硬件有了较快的发展,尤其是近年来我国涌现了众多具有自主知识产权的基础软硬件产品。龙芯、飞腾、申威等具有自主知识产权的高端通用芯片蓬勃发展,技术水平达到了同类产品的世界先进水平。
3.同时国产基础软件产品的发展也欣欣向荣,中标麒麟操作系统、神通数据库、金仓数据库、达梦数据库、东方通中间件、金蝶中间件、中标普华办公软件、金山办公软件、福昕版式办公套件、数科版式办公套件、中安源电子签章、信安电子签章等国产基础软件产品不断涌现出来。这些基础软硬件产品在性能、易用性等方面达到或接近世界先进水平。
4.随着国产基础软硬件的蓬勃的发展,给国产基础软硬件的推广和使用带来了前所未有的机遇。另外基于国产软硬件的安全可靠性,在政府、军工等重要领域,更换国产软硬件,已经势在必行。
5.目前,公文图片无法通过计算机来识别公文的文种和公文域,导致无法进行下一步的文字识别流程,需要通过手动对文种和公文域进行标注,或手动将公文输入到办公系统当中。例如:对于纸质外来文需要录入到系统当中,必须要有工作人员查看纸质文对公文的文种,来文单位等公文系统,再在办公系统中进行选择或者输入以录入到系统当中,该过程操作复杂,效率低下,还可能出现失误。
6.基于上述情况,本发明提出了一种基于国产cpu实现公文版面分析的方法。
技术实现要素:
7.本发明为了弥补现有技术的缺陷,提供了一种简单高效的基于国产cpu实现公文版面分析的方法。
8.本发明是通过如下技术方案实现的:
9.一种基于国产cpu实现公文版面分析的方法,其特征在于,包括以下步骤:
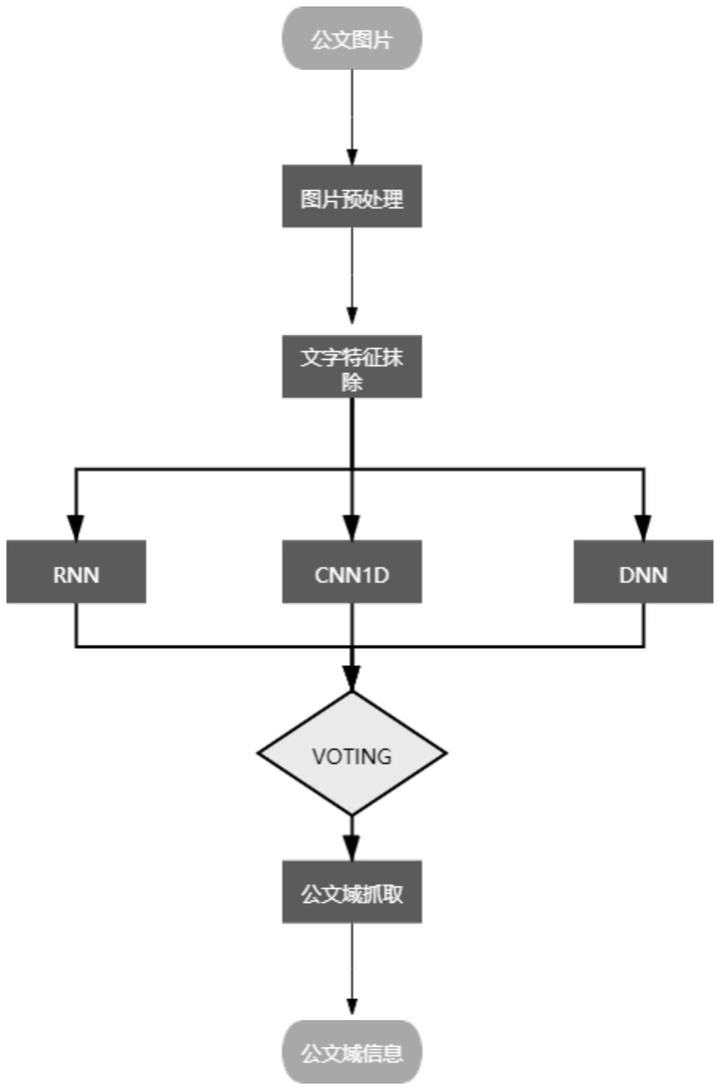
10.第一步,将公文图片上传到服务器,对公文图片进行特征提取,并抹去公文文字特征信息,对抹去公文文字特征信息后的行提取行高、横向起点和横向终点三个特征形成二维张量;
11.第二步,将行高、横向起点和横向终点三个特征形成二维张量输入已训练好的分类模型中,判断公文文种;
12.所述分类模型采用模型集成(model ensembling)机制,包括rnn(recurrent neural network,循环神经网络)模型,1dcnn(1d convolutional neural networks,一维卷积神经网络)模型和dnn(deep neural networks,深度神经内网络)模型;
13.所述rnn模型负责提取顺序特征,所述1dcnn模型负责提取区块特征,所述dnn模型
负责提取全局特征,最终采用投票机制(voting)确定公文文种;
14.第三步,获取到公文文种后,将图片输入针对该文种训练的检测神经网络,利用目标检测技术抓出公文域所在位置信息。
15.所述第一步中,预设支持识别的文件格式,选中的需要识别的公文图片后自动识别选中公文图片的文件格式,并对其进行过滤:若选中的公文图片文件格式为支持识别的文件格式,则将公文图片文件上传到服务器;否则提示用户该文件文件格式不支持识别,请重新选择文件。
16.所述第一步中,抹去公文文字特征信息的方法如下:
17.(1)公文图片旋转摆正
18.对图片进行二值化处理,然后采用canny、拉普拉斯边缘检测算子处理获得图片轮廓图,再对轮廓图使用轮廓提取算法处理获得最大轮廓,最大轮廓即为纸张边缘,针对最大轮廓的偏转角度进行调整,以此来摆正图片;
19.(2)、公文图片文字特征抹除
20.使用投影法统计图片每一行的像素个数,再根据统计计算出连续10行以上像素个数为0的行集合,该集合便是所有横向空白行,即行间距,对行间距进行反选获取到的行即为每行文字,将每一行的首尾空白去掉即为每一行文字实际所占区域,再对所有文字区域填满黑色。
21.所述rnn模型采用双向lstm(long short-term memory,是长短期记忆网络)层,获取公文中顺序特征,并依据顺序特征判断公文文种;
22.所述1dcnn模型采用1dconv(一维向量卷积运算)神经网络,在保留顺序的同时获取公文的图像位置特征和通道特征;
23.所述dnn模型采用全连接方式,获取公文的整体特征,并依次判断公文文种。
24.所述第二步中,将第一步中获取的每行的行高、横向行起始位置和横向行结束位置按顺序排列,形成一个维度为(20,3)的张量,不足20行的以0填充,大于20行的去掉多余的部分,以便输入rnn模型;
25.所述rnn模型通过两层lstm来获取顺序特征,再经过两层全连接层(fully connected layer)识别全局布局,获取one-hot编码(独热编码)的输出,根据输出获取对应的分类结果。
26.所述第二步中,以行数为纵轴,行高、横向行起点、横向行终点为横轴组成(20,3)的二维张量,将张量输入1dconv(一维向量卷积运算)神经网络。
27.所述第二步中,以行数为纵轴,行高、横向行起点、横向行终点为横轴组成(20,3)的二维张量,输入全连接(fully connected)神经网络。
28.所述第二步中,rnn模型,1dcnn模型和dnn模型的投票权重分别为45%,35%和20%。
29.本发明的有益效果是:该基于国产cpu实现公文版面分析的方法,能够自动识别公文文种,抓取出公文中的公文域并进行标注分类,同时采用三种模型采用投票机制确定公文文种,将不同文种的公文图片输入不同的检测神经网络,大幅提高了公文版面分析的精准度。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.附图1为本发明基于国产cpu实现公文版面分析的方法示意图。
32.附图2为本发明rnn模型网络结构示意图。
33.附图3为本发明1dcnn模型网络结构示意图。
34.附图4为本发明dnn模型网络结构示意图。
具体实施方式
35.为了使本技术领域的人员更好的理解本发明中的技术方案,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚,完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
36.该基于国产cpu实现公文版面分析的方法,包括以下步骤:
37.第一步,将公文图片上传到服务器,对公文图片进行特征提取,并抹去公文文字特征信息,对抹去公文文字特征信息后的行提取行高、横向起点和横向终点三个特征形成二维张量;
38.第二步,将行高、横向起点和横向终点三个特征形成二维张量输入已训练好的分类模型中,判断公文文种;
39.所述分类模型采用模型集成(model ensembling)机制,包括rnn(recurrent neural network,循环神经网络)模型,1dcnn(1d convolutional neural networks,一维卷积神经网络)模型和dnn(deep neural networks,深度神经内网络)模型;
40.集成依赖(model ensembling)基于以下的假设,即对于独立训练的不同良好模型,它们识别率表现良好可能是因为不同的原因和特征:每个模型都从略有不同的角度观察数据来做出预测,得到了“真相”的一部分,但不是全部真相。而将他们的观点汇集在一起,则可以得到对数据更加准确的描述。所以使用模型集成的形式可以明显的提高公文文种分类的准确率。
41.所述rnn模型负责提取顺序特征,所述1dcnn模型负责提取区块特征,所述dnn模型负责提取全局特征,最终采用投票机制(voting)确定公文文种;
42.第三步,针对不同文种训练的模型在面对该文种时将会表现出更加强大的公文域检测能力,获取到公文文种后,将图片输入针对该文种训练的检测神经网络,利用目标检测技术抓出公文域所在位置信息,至此公文所有版面信息已被提取。
43.所述第一步中,预设支持识别的文件格式,选中的需要识别的公文图片后自动识别选中公文图片的文件格式,并对其进行过滤:若选中的公文图片文件格式为支持识别的文件格式,则将公文图片文件上传到服务器;否则提示用户该文件格式不支持识别,请重新选择文件。
44.由于公文中的文字是多变的、不能预计的,所以文字不能作为公文的特征进行识
别,为了使神经网络训练更精确,所述第一步中,抹去公文文字特征信息的方法如下:
45.(1)公文图片旋转摆正
46.对图片进行二值化处理,然后采用canny、拉普拉斯边缘检测算子处理获得图片轮廓图,再对轮廓图使用轮廓提取算法处理获得最大轮廓,最大轮廓即为纸张边缘,针对最大轮廓的偏转角度进行调整,以此来摆正图片;
47.(2)、公文图片文字特征抹除
48.使用投影法统计图片每一行的像素个数,再根据统计计算出连续10行以上像素个数为0的行集合,该集合便是所有横向空白行,即行间距,对行间距进行反选获取到的行即为每行文字,将每一行的首尾空白去掉即为每一行文字实际所占区域,再对所有文字区域填满黑色。
49.所述rnn模型采用双向lstm(long short-term memory,是长短期记忆网络)层,获取公文中顺序特征,并依据顺序特征判断公文文种;
50.所述1dcnn模型采用1dconv(一维向量卷积运算)神经网络,在保留顺序的同时获取公文的图像位置特征和通道特征;
51.所述dnn模型采用全连接方式,获取公文的整体特征,并依次判断公文文种。
52.所述第二步中,将第一步中获取的每行的行高、横向行起始位置和横向行结束位置按顺序排列,形成一个维度为(20,3)的张量,不足20行的以0填充,大于20行的去掉多余的部分,以便输入rnn模型;
53.所述rnn模型通过两层lstm来获取顺序特征,再经过两层全连接层(fully connected layer)识别全局布局,获取one-hot编码(独热编码)的输出,根据输出获取对应的分类结果。
54.所述第二步中,以行数为纵轴,行高、横向行起点、横向行终点为横轴组成(20,3)的二维张量,将张量输入1dconv(一维向量卷积运算)神经网络。
55.所述第二步中,以行数为纵轴,行高、横向行起点、横向行终点为横轴组成(20,3)的二维张量,输入全连接(fully connected)神经网络。
56.所述第二步中,rnn模型,1dcnn模型和dnn模型的投票权重分别为45%,35%和20%。
57.以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1