一种基于词间依赖的生成式文本信息隐藏检测方法及系统
1.本发明涉及信息安全及深度学习技术领域,特别涉及一种基于词间依赖的生成式文本信息隐藏检测方法及系统。
背景技术:
2.信息隐藏,亦称为隐写术,是一种将秘密信息嵌入到载体中而使秘密信息难于被监管者察觉的技术。现有的文本信息隐藏技术可分为四类。第一类是基于文本图像特征修改的方法,该方法通过修改人眼不可感知的文本字距、行距、字体颜色或特定像素值实现秘密信息的嵌入。第二类是基于文本内容替换的方法,该方法通过对原有文本中的部分词句内容进行增删或替换的方式实现秘密信息的嵌入。第三类是生成式文本信息隐藏方法,该方法根据秘密信息直接生成一段自然文本实现信息隐藏。第四类是基于不可见字符嵌入的方法,该方法通过将字符编码表中的不可见字符插入到文本中实现秘密信息的嵌入。在这四类方法中,生成式文本信息隐藏技术因其嵌入效率高且无需修改载体文本而成为最近的研究热点,是对网络安全造成最大威胁的方法之一。为了消除这些威胁,必须开展相应生成式文本信息隐藏检测方法的研究。
3.现有的生成式文本信息隐藏检测方法可以分为两类,基于手工设计特征的方法和基于深度学习的方法。基于手工设计特征的方法的主要思想是根据文本数据和隐写算法的特点从原始文档中提取各种统计特征,然后将这些特征输入到机器学习模型(如支持向量机)中进行分类。该类方法的主要缺点是手工设计特征过程繁琐、错误检测率较高以及缺乏鲁棒性。近年来,随着将深度学习技术引入生成式文本信息隐藏检测中,使其产生了长足的进步。然而,这些方法也存在着一些问题。
4.在现有的基于深度学习的生成式文本隐写分析方法中,一些方法未从文本中提取上下文依赖特性,直接将对文本进行词嵌入后得到的嵌入向量输入到分类网络中。一些方法利用循环神经网络(rnn)结构提取上下文依赖信息。然而,rnn的结构存在许多问题,如对长距离上下文利用不足,不能同时建模正向和向后依赖关系,以及训练过程中的梯度消失或梯度爆炸等。另外,在分类网络的设计中,现有网络在处理中间特征时没有引入选择机制滤除噪声信息,导致特征处理效率较低。
技术实现要素:
5.本发明的目的在于克服现有生成式文本信息隐藏检测方法的技术缺陷,提出了一种基于词间依赖的生成式文本信息隐藏检测方法及系统。
6.为了实现上述目的,本发明提出了一种基于词间依赖的生成式文本信息隐藏检测方法,所述方法包括:
7.对待检测的文本信息进行预处理;
8.将预处理后的文本映射为分布式嵌入向量;
9.将分布式嵌入向量输入预先建立和训练好的文本信息隐藏检测模型,得到待检测
文本中是否包含秘密信息的决策;
10.所述文本信息隐藏检测模型基于词间依赖注意力机制和聚合依赖特征,通过全局加权推理实现。
11.作为上述方法的一种改进,所述对待检测的文本信息进行预处理;具体包括:对待检测的文本信息采用填充或丢弃操作,将文本段中所含单词数规整为预先设定的长度。
12.作为上述方法的一种改进,所述将预处理后的文本映射为分布式嵌入向量;具体包括:
13.读取预处理后的文本,对包含k个单词的输入文本分别进行静态分布式嵌入映射和动态分布式嵌入映射,得到每一段文本对应的长度均为l的静态分布式嵌入向量es以及动态分布式嵌入向量ed,将两个分布式嵌入向量逐点相加得到嵌入向量e。
14.作为上述方法的一种改进,所述文本信息隐藏检测模型包括串联的词间依赖提取模块和全局加权推理模块;其中,
15.所述词间依赖提取模块,用于提取文本单词间的显式词间依赖特征和潜在词间依赖特征,并进行依赖融合;
16.所述全局加权推理模块,用于综合利用提取到的文本中的词间依赖特征,得出当前文本段中是否包含秘密信息的决策。
17.作为上述方法的一种改进,所述词间依赖提取模块为显式依赖注意力模块和潜在依赖注意力模块经并联后连接词间依赖特征融合模块,所述词间依赖提取模块的处理过程具体包括:
18.嵌入向量e通过显式依赖注意力模块进行显式词间依赖提取,得到显式依赖特征fe,同时嵌入向量e通过潜在依赖注意力模块进行潜在词间依赖提取,得到潜在依赖特征f
l
,fe和f
l
通过词间依赖特征融合模块进行交叉融合处理,得到融合后的依赖特征fc。
19.作为上述方法的一种改进,所述全局加权推理模块包括依次串联的特征位置注意力模块、区域卷积模块、词间卷积模块和线性决策模块;所述全局加权推理模块的处理过程具体包括:
20.对融合后的依赖特征fc通过特征位置注意力机制进行特征位置优化选择,经信息聚合、拼接以及增加注意力权重系数,得到加权后的特征映射fw;将fw依次通过区域卷积模块和两个权值共享的词间卷积模块得到局部加强后的特征f
l
,再通过线性决策模块进行高层抽象特征向输出层输出结果的特征映射及归一化处理,得到是否包含秘密信息的分类结果。
21.作为上述方法的一种改进,所述特征位置注意力模块为平均池化和最大池化经并联后依次连接不同核大小的卷积层以及softmax激活函数层,再将softmax激活函数层的输出与特征位置注意力模块的输入端逐点相乘。
22.作为上述方法的一种改进,所述线性决策模块包括依次连接的全连接层和sigmoid函数;其中,
23.所述全连接层包括两个神经元,用于实现高层抽象特征向输出层输出结果的特征映射;
24.所述sigmoid函数,用于进行归一化处理,得到输入文本中是否包含秘密信息的分类结果。
25.作为上述方法的一种改进,所述方法还包括文本信息隐藏检测模型的训练步骤;具体包括:
26.步骤1)建立样本集,将样本集中的文本按每组a段随机分成m组;所述样本集包括若干文本段以及每个文本段对应的是否包含秘密信息的标签;
27.步骤2)随机选取一组文本,将预处理后的文本输入文本信息隐藏检测模型,得到预测结果,将预测结果与真实标签采用交叉熵进行误差求取,得到真实标签与预测结果y之间的误差重复步骤2)直至样本训练完毕,转至步骤3);
28.步骤3)根据误差选取最优参数组合,得到训练好的文本信息隐藏检测模型。
29.一种基于词间依赖的生成式文本信息隐藏检测系统,所述系统包括:文本信息隐藏检测模型、预处理模块、分布式读入模块和输出模块;其中,
30.所述预处理模块,用于对待检测的文本信息进行预处理;
31.所述分布式读入模块,用于将预处理后的文本映射为分布式嵌入向量;
32.所述输出模块,用于将分布式嵌入向量输入预先建立和训练好的文本信息隐藏检测模型,得到待检测文本信息是否包含秘密信息的决策;
33.所述文本信息隐藏检测模型基于词间依赖注意力机制和聚合依赖特征,通过全局加权推理实现
34.与现有技术相比,本发明的优势在于:
35.1、本发明的方法能够进行高精度的生成式文本信息隐藏检测,提升了检测精度,也更适用于复杂情况下的生成式文本信息隐藏检测;
36.2、本发明提供的生成式文本信息隐藏检测技术方案,通过分布式读入模块对输入的原始文本进行多维映射,得到对应的分布式嵌入向量;
37.3、采用词间依赖提取模块提取分布式嵌入向量之间存在的显式词间依赖和潜在词间依赖,这两种依赖特征的提取主要通过显式依赖注意力和潜在依赖注意力机制来完成,并采用依赖特征聚合模块来整合分别提取到的显式和潜在依赖特征;
38.4、根据得到的聚合依赖特征,采用全局加权推理模块首先对其进行特征位置选择,其次将加权后的特征映射输入到由不同核大小的卷积窗口及激活函数堆叠而成的卷积模块中,最后由全连接层做出文本段中是否被嵌入了秘密信息的推理决策;
39.5、在测试基准数据集时,本发明取得了超过现有方法的性能。
附图说明
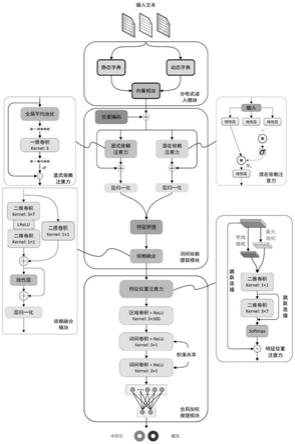
40.图1是本发明的基于词间依赖的生成式文本信息隐藏检测方法流程示意图。
具体实施方式
41.下面结合附图和实施例对本发明的技术方案进行详细的说明。
42.实施例1
43.如图1所示,本发明的实施例1提出了一种基于词间依赖的生成式文本信息隐藏检测方法,该方法包括:
44.对待检测的文本信息进行预处理;
45.将预处理后的文本映射为分布式嵌入向量;
46.将分布式嵌入向量输入预先建立和训练好的文本信息隐藏检测模型,得到待检测文本中是否包含秘密信息的决策;
47.所述文本信息隐藏检测模型基于词间依赖注意力机制和聚合依赖特征,通过全局加权推理实现。
48.本发明提出的生成式文本信息隐藏检测方法由分布式读入模块、词间依赖提取模块以及全局加权推理模块完成数据处理,具体过程包括:
49.步骤1)数据预处理,将训练所需文本按每组a段随机分成m组,并对每一段文本通过填充和丢弃等操作进行长度规整,规整后,每段文本的长度都是20个单词;
50.步骤2)随机读取一组文本,由分布式读入模块中的静态映射和动态映射对包含20个单词的输入文本进行分别进行300维的分布式嵌入映射,得到每一段文本对应的长度为300的分布式嵌入向量es∈r
20
×
300
和ed∈r
20
×
300
,将二者相加得到最终的嵌入向量e∈r
20
×
300
,所述静态映射和动态映射分别由静态词典和动态词典完成,其中静态词典加载了语料库预训练词典后保持参数不变,动态词典中的参数进行随机初始化后在后续网络训练过程中根据梯度反向传播算法进行参数更新;
51.步骤3)将步骤2)中得到的嵌入向量e∈r
20
×
300
,通过不同的注意力机制进行显式词间依赖提取和潜在词间依赖提取,从两个不同的角度捕捉文本段中丰富的词间依赖信息,得到显式依赖特征fe和潜在依赖特征f
l
。
52.步骤4)对步骤3)中得到的依赖特征fe和f
l
,进行交叉融合处理,整合同一个文本段的不同视角下的依赖特征,得到融合后的依赖特征fc。
53.步骤5)对步骤4)中得到的融合特征fc,进行特征位置优化选择,加大有区分度的特征局部在全局中的重要性,滤除不必要的特征噪声,得到加权后的融合特征fc',对fc'进行区域融合处理,整合分布式的词间依赖信息,得到降维后的特征映射fd,提取不同单词间的局部关联信息,并逐步增大感受野,最终得到特征映射fn。
54.步骤6)对步骤5)中最后得到的特征映射fn,将其变换为一维特征,经过检测模块得到对当前文本段中是否包含秘密信息的预测结果。
55.步骤7)采用梯度下降法对上述模型中的参数进行更新;反复迭代,直至训练出最优参数组合;
56.步骤8)基于最优参数模型实现生成式文本信息隐藏检测。
57.该方法包括:通过分布式读入模块对输入的原始文本进行多维映射,得到对应的分布式嵌入向量;采用词间依赖提取模块提取分布式嵌入向量之间存在的显式词间依赖和潜在词间依赖,这两种依赖特征的提取主要通过显式依赖注意力和潜在依赖注意力机制来完成,并采用依赖特征聚合模块来整合分别提取到的显式和潜在依赖特征;根据得到的聚合依赖特征,采用全局加权推理模块首先对其进行特征位置选择,其次将加权后的特征映射输入到由不同核大小的卷积窗口及激活函数堆叠而成的卷积模块中,最后由全连接层做出文本段中是否被嵌入了秘密信息的推理决策。
58.如图1所示,本发明提出的词间依赖提取模块由显式依赖注意力模块、潜在依赖注意力模块以及依赖融合模块构成。图中,表示矩阵逐点相加,
“⊙”
表示矩阵逐点相乘,“σ”表示激活函数。
59.所述步骤3)具体包括:
60.步骤3-1)采用位置编码模块对文本序列进行前后关联关系建模,位置编码向量可由如下公式得到:
[0061][0062][0063]
其中pos代表位置,i表示维度。由公式可以看出,偶数维度和奇数维度的位置编码向量数值分别由不同的函数计算得来。位置编码的每一个维度都将对应于一个正弦信号。接着,将位置编码向量pe所建模的序列方向特征叠加到原始分布式向量e上,以得到具有前后方向性信息的分布式向量eo:
[0064]eo
=e+pe
[0065]
步骤3-2)所述显式依赖注意力包括全局平均池化和卷积核大小为3,步长为1,填充为1的卷积层,由所述全局平均池化(global average pooling)整合单词分布式向量的不同维度的特征信息,采用一维卷积核在单词的邻域内滑动,输入通道和输出通道数都为1,并采用sigmoid激活函数来获取代表当前单词和前后相邻单词间显式依赖特征的权重系数,计算公式如下:
[0066]
p=gap(eo)
[0067]
pc=1d-conv(p)
[0068][0069]
l=pz⊙eo
[0070]
其中,“gap”表示全局平均池化处理,“1d-conv”表示一维卷积操作,“σ”表示sigmoid激活函数,
“⊙”
表示逐点相乘;
[0071]
步骤3-3)所述潜在依赖注意力分支由线性层组成,将步骤3-1)所得到的分布式向量通过三个不同的线性层分别映射为q,k和v,线性层的神经元个数与原始分布式向量的维度相同(300),对q与k的转置执行矩阵相乘操作,经尺度缩放后借由softmax激活函数进行归一化处理再与v相乘,上述操作在不同头下的计算结果被拼接起来后借由线性层映射得到最后的潜在词间依赖特征g,计算公式如下:
[0072][0073][0074][0075][0076][0077]
其中,“(
·
)
(i)”表示第i个头的中间运算结果,“w
q”,“w
k”,“w
v”和“w
ml”表示线性层
的权重矩阵,表示缩放因子,“concat”表示特征拼接操作,图中的“n
h”表示头的个数,在实施中设定为8。
[0078]
所述步骤4)具体包括:
[0079]
步骤4-1)对所述显式依赖特征l和潜在依赖特征g分别进行层归一化处理随后进行拼接,计算公式如下:
[0080]
b=concat(layernorm(l),layernorm(g))
[0081][0082]
其中,“layernorm”表示层归一化操作,“e(x)”和“var(x)”分别代表均值和标准差函数,“η”和“β”代表可学习的仿射变换系数,跟随网络的训练一起更新,“ε”为人为设定的超参数,在实施中设为1e-5;
[0083]
步骤4-2)将b输入到依赖融合模块中,依赖融合模块由不同大小的卷积核和激活函数组成,其计算公式如下:
[0084]bc1
=conv1×1(σ(conv3×7(b)))
[0085]bc2
=conv1×1(b)
[0086]bc
=b
c1
+b
c2
[0087]
其中,“conv
k”代表卷积核大小为k的二维卷积操作。图中依赖融合模块左侧支路卷积核从下到上的参数分别为:输入通道为2,输出通道为16,填充为1*3;输入通道为16,输出通道为1,填充为零,右侧支路卷积核的参数为:输入通道为2,输出通道为1,填充为零。
[0088]
步骤4-3)对bc进行线性变换和归一化操作,其计算公式如下:
[0089]bl
=bcw
l
+b
l
+bc[0090]bn
=layernorm(b
l
)
[0091]
其中,“w
l”和“b
l”代表线性层的权重矩阵和偏置系数。
[0092]
本发明所述全局加权推理模块结构如图1所示。
[0093]
所述步骤5)具体包括:
[0094]
步骤5-1)将词间依赖提取部分得到的融合了潜在依赖和显式依赖的特征bn进行特征位置优化选择,特征位置优化选择由特征位置注意力机制来完成,首先采用平均池化和最大池化对原始特征进行信息聚合,二者结果进行拼接后先后经过不同核大小的卷积层以及softmax激活函数层后得到注意力权重系数,将该系数与原始特征进行逐点相乘,得到加权后的特征映射,其计算公式如下:
[0095]fp
=concat(avgpool(bn),maxpool(bn))
[0096]fs
=conv1×1(f
p
)
[0097]
ma(fs)=σ(fs+conv3×7(fs))
[0098]fw
=ma(fs)
⊙fs
[0099]
其中,“avgpool”和“maxpool”代表平均池化和最大池化操作,“ma(fs)”表示得到的注意力权重系数,“f
w”表示经注意力权重加权后的特征。
[0100]
步骤5-2)将加权特征fw经过卷积核尺寸为3
×
300的二维卷积,得到降维后的特征映射fr,对fr进行relu非线性特征激活操作,得到输出特征fa,作为模型后续部分的输入;
[0101]
步骤5-3)将特征fa先后经过两个权值共享的卷积核尺寸为3
×
1的卷积以及relu非线性特征激活操作,得到局部加强后的特征f
l
。
[0102]
检测模块包括1个全连接层和1个sigmoid函数;所述全连接层包括两个神经元,实现高层抽象特征向输出层输出结果的特征映射;采用sigmoid归一化函数进行归一化处理,得到输入文本中是否包含秘密信息分类结果。
[0103]
步骤7)具体包括:
[0104]
步骤7-1)将模型输出的结果与真实标签进行误差求取;所述误差求取采用交叉熵,其可以表示为:
[0105][0106]
其中,表示真实标签与预测结果y之间的误差,p(xi)表示模型的前向输出结果,q(xi)表示真实标签,σ表示求和;
[0107]
步骤7-2)采用步骤7-1)得到的参数作为本次迭代的权重值;从剩余的文本中随机选取一组文本,经步骤2)、步骤3)、步骤4)、步骤5)、步骤6)和步骤7-1),得到新的参数组合;反复迭代,直至完成一个迭代周期;
[0108]
步骤7-3)对训练文本进行重新洗牌,转至步骤1);反复执行,直至训练出最优参数组合。
[0109]
步骤8)具体包括:
[0110]
步骤8-1)对于待检测文本,利用填充和丢弃等操作将文本段中所含单词数规整为20;
[0111]
步骤8-2)将规整后的文本输入至最优参数模型,经模型前向传输得到预测结果;
[0112]
步骤8-3)将每一文本段的预测结果最大概率值所对应的类别是与真实标签进行比较,若一致,则预测正确,反之,则预测错误;
[0113]
步骤8-4)执行步骤8-1)、步骤8-2)和步骤8-3),直到测完所有待测文本。
[0114]
实施例2
[0115]
本发明的实施例2提供了一种基于词间依赖的高精度生成式文本信息隐藏检测系统,根据实施例1的方法构建的生成式文本信息隐藏检测网络模型实现,所述系统包括:
[0116]
预处理模块,用于对待检测的文本信息进行预处理;
[0117]
分布式读入模块,用于将预处理后的文本映射为分布式嵌入向量;
[0118]
输出模块,用于将分布式嵌入向量输入预先建立和训练好的文本信息隐藏检测模型,得到待检测文本信息是否包含秘密信息的决策;
[0119]
文本信息隐藏检测模型基于词间依赖注意力机制和聚合依赖特征,通过全局加权推理实现。
[0120]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1