一种利用掉队节点计算能力的编码矩阵乘法方法
1.本发明涉及信息论与编码技术领域,尤其涉及一种利用掉队节点计算能力的编码矩阵乘法方法。
背景技术:
2.分布式计算系统通过将难以在一个计算机上完成的大规模计算任务细分到多个工作节点,并在工作节点上并行运算更小的任务,然后通过网络传输给主节点,有效分散了单台计算机的计算负载,显著提高大规模计算任务的整体执行效率。因此,分布式计算在大规模科学问题研究和机器学习中发挥着重要作用。但是随着计算集群规模越来越大,由于大规模计算集群本质上是异构的,且存在网络拥塞、设备故障等原因,有些工作节点会出现“掉队”情况,即有些节点完成任务的速度显著慢与其他节点,或者上传运算结果时存在延时等现象。显然,集群总体计算速度通常是由这些掉队节点所控制的,由此导致的计算延时通常也是无法忍受的。这意味着掉队节点已成为分布式计算的一个主要性能瓶颈。网络化的编码计算(coded computation)策略能有效缓解分布式计算中掉队节点对计算效率的影响,尤其对一些特定的计算问题具有显著作用,例如矩阵乘法。
3.编码矩阵乘法计算策略通过将大规模矩阵划分成多个子矩阵,并对子矩阵进行编码,然后给每个工作节点分配编码后子矩阵之间的乘法任务,有效缓解了高维矩阵乘法分布式计算时面临的节点掉队问题。虽然现有的绝大多数编码矩阵乘法计算策略能够达到最优恢复阈值δ
opt
(恢复阈值指主节点为了恢复原始结果所需等待的成功完成所有计算任务的工作节点数量),例如基于多项式的编码矩阵乘法计算,后续简称多项式码,基于旋转矩阵和循环转置矩阵的编码策略,基于无速率码的编码策略等。但是,这些编码计算都是将掉队节点作为被擦除的节点来处理,只有当一个节点完成并上传了所有分配的任务,这个节点的计算才是有用的。这意味着这些现有工作无法利用掉队节点已经完成的部分计算。目前只有少量工作研究如何充分利用所有节点的中间计算能力,例如基于udm的编码矩阵-向量乘法计算、基于mds码和乘积码的编码矩阵-矩阵乘法计算、基于随机线性组合的编码稀疏矩阵乘法计算。但是这些工作要么无法推广到矩阵-矩阵乘法的情况,要么无法高效率利用节点的部分计算能力,导致译码时需要的编码子矩阵乘法数量大于未编码子矩阵乘法的数量。因此,设计能够充分利用所有掉队节点计算能力、且能达到最优恢复阈值的低时延编码矩阵-矩阵乘法计算方法,对进一步显著提升大规模矩阵乘法的计算效率具有重要意义。
技术实现要素:
4.本发明的目的在于提供一种利用掉队节点计算能力的编码矩阵乘法方法,以解决如何在分布式编码矩阵-矩阵乘法系统中充分利用所有节点已经完成的中间计算的技术问题。
5.本发明采用的技术方案是:
6.一种利用掉队节点计算能力的编码矩阵乘法方法,主节点不需要等待工作节点完
成所有分配的编码子矩阵之间的乘法任务才能利用这个节点的计算能力,而是能够利用所有工作节点已经完成的中间结算结果,包括掉队节点,所述编码计算方法包括如下步骤:
7.1)主节点对两个输入矩阵的子矩阵分别采用有限域下不同的编码方法进行编码;
8.2)每个工作节点按顺序每计算完一对编码子矩阵乘法就将结果返回主节点;
9.3)当主节点接收到的所有工作节点返回的编码子矩阵乘法计算结果的总数量不少于未编码子矩阵乘法数量时,通过译码能正确恢复出未编码矩阵乘法结果。
10.2、根据权利要求1所述的编码矩阵乘法方法,其特征在于,所述对两个输入矩阵进行编码的步骤,之前还包括:
11.约束编码参数来构建工作节点中间计算结果的mds结构和udm性质,具体包括:p是一个素数,n是一个正整数,工作节点数量n<pn,c
×
r维输入矩阵a按列划分的子矩阵数量ka和c
×
w维输入矩阵b按列划分的子矩阵数量kb要满足p|kb,kakb<nl,l是一个正整数满足l≤min{pk,k
b-1},其中k是一个正整数使得kb=apk,a是一个不能被p整除的正整数。考虑中n个互不相等的非零元素α0,α1,
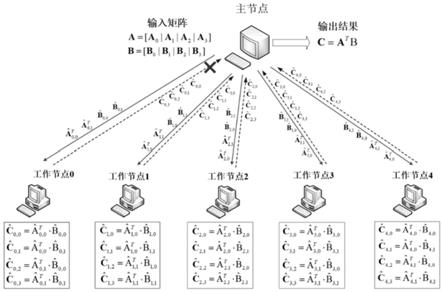
…
,α
n-1
。
12.3、根据权利要求2所述的编码矩阵乘法方法,其特征在于,所述对两个输入矩阵进行编码的步骤,具体包括:
13.1)将有限域下的高维输入矩阵a按其列分成ka个具有相同维数的子矩阵,并采用有限域下的mds码进行编码,得到n个编码子矩阵,0≤i<n,其中等于项数为ka的矩阵多项式在αi上的求值,并将传递给工作节点i;
14.2)将有限域下的高维输入矩阵b按其列分成kb个具有相同维数的子矩阵,并采用有限域下基于udm的编码方法进行编码,得到nl个编码子矩阵,0≤i<n,其中分别等于度为k
b-1的矩阵多项式的0,1,2,
…
,l-1阶hasse导数在αi上的求值,0≤s<l,并将传递给工作节点i。本专利中所有的都表示对整数值取模p。
15.4、根据权利要求3所述的编码矩阵乘法方法,其特征在于,每个工作节点按顺序每计算完一对编码子矩阵乘法就将结果返回主节点的步骤包括:对0≤i<n,工作节点i按顺序首先计算编码子矩阵与的乘积然后将计算结果返回给主节点,接下来再开始计算编码子矩阵与的乘积并将结果返回主节点,依此类推,依次完成剩余所有编码子矩阵乘法,2≤s<l,的计算和结果返回。
16.5、根据权利要求4所述的编码矩阵乘法方法,其特征在于,所述的主节点通过基于udm的高效译码算法能唯一地恢复出未编码矩阵乘法结果的步骤,之前还包括:
17.对0≤i<n,计算每个工作节点上所有计算结果,所对应的kakb×
l阶生成矩阵工作节点i的生成矩阵中的第s列对应于度为kak
b-1的多项式的s阶hasse导数在αi上的计算,0≤s<l。最终得到下一个大小为kakb×
nl的矩阵
18.6、根据权利要求5所述的编码矩阵乘法方法,其特征在于,所述的主节点通过基于udm的高效译码算法能唯一地恢复出未编码矩阵乘法结果的步骤,具体包括:
19.一旦主节点接收到的当前每个工作节点按顺序返回的编码子矩阵乘法的数量vi满足满足时,其中vi是任意一个满足0≤vi≤l的整数,每个工作节点生成矩阵的前vi列,构成的kakb×
v矩阵全满秩,并且是一个udm,因此主节点可以利用基于udm的高效译码方法进行译码,唯一地恢复出所有的未编码子矩阵乘法并输出完整的计算任务
20.本发明采用以上技术方案,通过控制有限域下多项式的根与编码参数,提出同时嵌入mds码和基于udm的编码的计算方法,有效地构建工作节点中间计算结果的mds结构和udm性质,充分利用了所有节点,包括掉队节点,已经完成的中间计算结果,并具有最优的恢复阈值,且本发现提出的编码计算方法需要的有限域大小只需大于工作节点个数n。通过采用本发明所提供的一种能利用掉队节点计算能力的编码矩阵乘法方法,显著提高了大规模矩阵-矩阵乘法的计算效率。
附图说明
21.以下结合附图和具体实施方式对本发明做进一步详细说明;
22.图1示出了一个包含一个主节点,5个工作节点的编码矩阵-矩阵乘法计算典型框架;
23.图2示出了本发明弹性编码矩阵乘法计算方法的基本框架示意图;
24.图3示出了本发明弹性编码矩阵乘法计算方法的流程示意图;
25.图4示出了本发明弹性编码矩阵乘法计算方法中一个工作节点上的中间计算结果示意图。
具体实施方式
26.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图对本技术实施例中的技术方案进行清楚、完整地描述。
27.先定义一些数学概念。对任意的正整数m,令对任意的矩阵g,令g(i,j)表示g中的第(i,j)个元素,g(:,j)和g(i,:)表示g中的第j列和第i行,g
《v》
表示g中的前v列。矩阵聚集的强满秩条件指:由维数都为v
×
l的n个矩阵构成的矩阵聚集对任意满足(vi是任意一个满足0≤vi≤l的整数,i∈[n])的向量v=[v0,v1,
…
,v
n-1
],由每个矩阵gi的前vi列构成的v
×
v矩阵
都一定是满秩的(此时矩阵g可以认为是一个udm),则称矩阵聚集满足强满秩条件。
[0028]
图1所示即为一个编码矩阵-矩阵乘法计算典型框架例子,该例子由一个主节点和5个工作节点以及连接两种节点的网络构成,主节点有一个c
×
r的高维输入矩阵a和一个c
×
w的高维输入矩阵b,为了得到高维矩阵乘法结果c=a
t
b,分别将两个输入矩阵按列划分成四个相同维数的子矩阵:a=[a0|a1|a2|a3]和b=[b0|b1|b2|b3],并分别作为原始信息序列进行编码,分别得到与未编码子矩阵aj具有相同维数的编码后的子矩阵(后面简称为编码子矩阵)以及与未编码子矩阵b
t
具有相同维数的编码子矩阵然后将所有编码子矩阵和都分配给工作节点i,其中索引i∈{0,1,2,3,4}。工作节点i依次计算接收到的两类编码子矩阵之间的对积其中u∈{0,1},s∈{0,1},并将完成计算的子矩阵乘法依次传回主节点。每个工作节点的计算结果可以等效为对未编码子矩阵乘法进行编码的结果,其中j,t∈{0,1,2,3},主节点只需等待任意4个工作节点完成所有计算并返回计算结果,例如节点1是最慢的节点,主节点无需等待节点1的结果只需要接收到剩下4个节点的计算结果,就可以对接收结果进行译码,恢复出所有子矩阵乘法结果j,t∈{0,1,2,3},从而得到完整的计算任务g=a
t
b。
[0029]
如图2至4之一所示,本发明公开了基于编码矩阵-矩阵乘法计算框架的弹性编码计算方法,进行了如下方面的改进:
[0030]
1)主节点对两个输入矩阵的子矩阵采用有限域下不同的编码方法进行编码,其中输入矩阵a采用有限域下的mds码进行编码,输入矩阵b采用有限域下基于udm的编码方法进行编码,并约束编码系数,构建有限域下矩阵a对应生成矩阵与矩阵b对应生成矩阵的克罗内克积聚集的强满秩性。
[0031]
2)对每个工作节点,主节点对其只分配一个对应于输入矩阵a的编码子矩阵和l个对应于输入矩阵b的编码子矩阵s∈[l],然后每个工作节点按顺序依次计算与之间的对积,每计算完成一对编码子矩阵乘法计算,就将结果返回主节点,再开始下一对编码子矩阵乘法计算,并返回结果,依次类推。
[0032]
3)当主节点接收到的任意工作节点返回的编码子矩阵乘法计算结果总数不少于未编码子矩阵乘法数量(以下简称最优局部恢复阈值q
opt
)时,就可以利用基于udm的译码方法进行译码,恢复出完整的计算任务c=a
t
b,而不需要等待工作节点完成所有的计算才能利用该节点,因此能够充分利用所有工作节点已经完成的计算,包括掉队节点。
[0033]
本发明提供的利用所有节点计算能力的编码矩阵-矩阵乘法计算方法是基于有限域的,p是一个素数,n是一个正整数。因此考虑系统中所有运算都在上的情况,完整的编码计算流程图如图2所示,基本框架示意图如图3所示,假设系统中有一个主节点,n个工作节点,n<pn,选择中n个互不相等的元素α0,α1,
…
,α
n-1
,主节点有一个c
×
r的高维输入矩阵a,和一个c
×
w的高维输入矩阵b,
[0034]
本发明提供的编码计算方法按以下步骤进行:
[0035]
步骤一、将两个高维输入矩阵a和b划分出多个子矩阵。主节点将输入矩阵a按其列
分成ka个具有相同维数的子矩阵,即输入矩阵b按其列分成kb个具有相同维数的子矩阵要求p|kb,kakb<nl,其中l是一个满足l≤min{pk,k
b-1}的正整数,k是一个使得kb=apk的正整数(a是一个不能被p整除的正整数)。完整的计算任务为显然kakb就是最优的局部恢复阈值,即q
opt
=kakb。如果想要达到最小的恢复阈值,则需要进一步要求l|kakb,此时最优恢复阈值δ
opt
=kakb/l。
[0036]
步骤二、分别对两个输入矩阵a和b进行编码。
[0037]
2.1)对输入矩阵a采用有限域下的mds码进行编码,得到n个编码子矩阵,i∈[n],其中等于矩阵多项式在αi上的求值,对应的生成矩阵为对应的生成矩阵为即
[0038][0039]
2.2)对输入矩阵b采有限域下基于udm的编码方法进行编码,得到nl个编码子矩阵,其中i∈[n]。编码得到的l个编码子矩阵分别等于度为k
b-1的矩阵多项式的0,1,2,
…
,l-1阶hasse导数1阶hasse导数在αi上的求值,其中该l个编码子矩阵对应的生成矩阵是下一个大小为kb×
l的矩阵,其中第s个编码子矩阵对应生成矩阵的第s列的第s列的第t个系数
[0040][0041]
其中,t∈[kb],s∈[l]。当t<s时,矩阵聚集满足强满秩条件。
[0042]
步骤三、工作节点依次计算编码子矩阵乘法和返回计算结果。
[0043]
3.1)主节点分别将输入矩阵a编码得到的编码子矩阵以及输入矩阵b编码得到的l个编码子矩阵s∈[l],传送给工作节点i。
[0044]
3.2)对工作节点i按顺序依次计算和返回编码子矩阵与之间的对积工作节点i上的中间计算结果示例如图4所示:
[0045][0046]
其中s∈[l],即工作节点按顺序首先计算第一对编码子矩阵乘法然后将计算结果返回主节点,接下来再开始第二对编码子矩阵乘法的计算,并将结果返回主节点,接下来再计算第三对编码子矩阵乘法并将结果
返回主节点,依此类推,依次完成剩余所有编码子矩阵乘法,3≤s<l,的计算和结果返回。
[0047]
本发明提供的编码计算中可以将工作节点i中每个编码子矩阵乘法计算结果等效为将所有未编码子矩阵乘法作为信息块,并采用有限域下基于udm的编码方法进行编码的结果,s∈[l],j∈[ka],t∈[kb],即每个工作节点上所有计算结果所对应的生成矩阵(等于生成矩阵和的克罗内克积,的克罗内克积,)的聚集满足强满秩条件。因此矩阵具有udm性质。这是根据下udm与多项式高阶hasse导数的同构性决定的。
[0048]
工作节点i中的每个编码子矩阵乘法s∈[l],等于多项式乘法在αi上的求值,其中第一个编码子矩阵乘法对应度为kak
b-1,项数为kakb的多项式为:
[0049][0050]
在αi上的求值。由于kb=apk,且l≤min{pk,k
b-1},多项式的1,2,
…
,l-1阶hasse导数的所有系数模p都等于0,即s∈{1,2,
…
,l-1},因此多项式的s阶hasse导数化简为:
[0051][0052]
意味着在有限域和参数约束kb=apk,l≤min{pk,k
b-1}下,多项式乘法1}下,多项式乘法等价于多项式的s阶hasse导数所以每个编码子矩阵乘法s∈[l],也等于度为kak
b-1的多项式的s阶hasse导数在αi上的求值。因此,工作节点i的生成矩阵中的第s列也对应于多项式的s阶hasse导数在αi上的计算。因此,当α0,α1,
…
,α
n-1
是有限域中n个互不相等的元素时,对任意满足(vi是任意一个满足0≤vi≤l的整数,i∈[n])的向量v=[v0,v1,
…
,v
n-1
],由每个矩阵的前vi列构成的kakb×
kakb系数矩阵的行列式等于一个广义范德蒙行列式的行列式值,因此一定是满秩的,从而聚集满足强满秩条件。
[0053]
步骤四、主节点接收返回的计算结果,并进行译码恢复出c=a
t
b。当主节点接收到的每个工作节点当前按顺序返回的编码子矩阵乘法的数量vi一旦满足一旦满足时(vi是任意一个满足0≤vi≤l的整数,i∈[n]),主节点对接收到的所
有计算结果采用基于每个工作节点生成矩阵前vi列构成的kakb×
kakb系数矩阵系数矩阵和udm简化译码算法进行译码,唯一地恢复出所有未编码子矩阵乘法j∈[ka],t∈[kb],从而得到完整的计算任务c=a
t
b。
[0054]
步骤五、主节点输出c=a
t
b,编码计算结束。
[0055]
本专利提出的弹性编码矩阵乘法计算方法在有限域下不仅能达到最优恢复阈值,而且能够充分利用所有节点已经完成的中间计算结果,从而显著降低计算时延,提高大规模矩阵-矩阵乘法的计算效率。
[0056]
下面通过具体实施例进一步进行具体的说明。
[0057]
本实施例考虑一个有限域下包含n=9个工作节点的分布式矩阵-矩阵乘法计算系统,取p=2,l=2,ka=2,kb=4。该实施例能实现最优局部恢复阈值q
opt
=kakb=8,最优恢复阈值δ
opt
=4。假设α0,α1,
…
,α8是中互不相同的9个域元素,取αi=αi,α是的一个本原元,主节点有一个c
×
r的高维输入矩阵a,和一个c
×
w的高维输入矩阵b,
[0058]
主节点将输入矩阵a按列划分成具有相同维数的两个子矩阵a=[a0|a1],输入矩阵b按列划分成具有相同维数的四个子矩阵b=[b0|b1|b2|b3]。为了能够通过9个工作节点以分布式的形式来计算高维矩阵乘法
[0059][0060]
输入矩阵a的编码考虑下的矩阵多项式输入矩阵b的编码考虑下的矩阵多项式多项式的s阶hasse导数,s=0,1,是:
[0061][0062][0063]
对输入矩阵a采用有限域下的mds码进行编码,得到n个编码子矩阵,i∈[n],并将分配给工作节点i,其中等于多项式在αi上的求值,即上的求值,即上的求值,即对应的生成矩阵为对输入矩阵b采有限域下基于udm的编码方法进行编码,得到18个编码子矩阵,i∈[n],并给工作节点i分配2个编码子矩阵其中等于(6)中多项式在αi上的求值,即上的求值,即等于(7)中多项式在αi上的求值,即上的求值,即对应的生成矩阵为
[0064][0065]
对工作节点i先计算第一个编码子矩阵乘法然后将计算结果返回主节点,接下来再计算并将结果返回主节点。工作节点i上编码子矩阵乘法对应多项式对应多项式对应的1阶hasse导数的1阶hasse导数的1阶hasse导数对应的生成矩阵
[0066][0067]
由(10)中所有工作节点对应生成矩阵构成的矩阵聚集如下所示:
[0068][0069]
由于α是有限域的一个本原元,所以(11)中的聚集满足强满秩条件。
[0070]
当主节点接收到的每个工作节点当前返回的编码子矩阵乘法的数量vi的总和满足足时,每个工作节点生成矩阵前vi列构成的8
×
8矩阵是全满秩的,其中0≤vi≤2。因此,主节点能通过译码正确恢复出所有未编码子矩阵乘积:最终得到并输出完整的高维矩阵乘法计算任务c=a
t
b。
[0071]
本发明采用以上技术方案,通过控制有限域下多项式的根与编码参数,提出同时嵌入mds码和基于udm的编码的计算方法,有效地构建工作节点中间计算结果的mds结构和
udm性质,充分利用了所有节点,包括掉队节点,已经完成的中间计算结果,并具有最优的恢复阈值,且本发现提出的编码计算方法需要的有限域大小只需大于工作节点个数n。通过采用本发明所提供的一种能利用掉队节点计算能力的编码矩阵乘法方法,显著提高了大规模矩阵-矩阵乘法的计算效率。
[0072]
显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。通常在此处附图中描述和示出的本技术实施例的组件可以以各种不同的配置来布置和设计。因此,本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1