风险预测模型的构建方法、装置、电子设备和存储介质与流程
1.本技术涉及信息处理技术领域,具体而言,涉及一种风险预测模型的构建方法、装置、电子设备和存储介质。
背景技术:
2.现在互联网金融公司有很多信贷业务,比如汽车以租代购、个人信用贷款等,通过增加月供本金或者收取利息的形式获取利润。但在实际情况中,有些客户会因为各种原因不能如期还款,比如没有足够经济来源、主观意愿不还等,导致公司受到很大的损失,因此,在信贷业务中,公司期望为信用更好的用户提供服务。在互联网金融公司中,有很多基于机器学习或深度学习的评分模型来筛选优质客户,比如逻辑回归、随机森林等模型,但这些模型要么太简单,达不到一定的准确率,要么太复杂,导致可解释性较低。
技术实现要素:
3.本技术实施例的目的在于提供一种风险预测模型的构建方法、装置、电子设备和存储介质,实现了通过历史用户数据来建立风险预测模型从而预测用户的风险程度,进而通过用户的不同风险程度来提供不同的信贷服务,避免公司遭受损失。
4.本技术实施例第一方面提供了一种风险预测模型的构建方法,包括:从历史用户数据中解析出用户个人数据和用户关系网络数据;基于所述用户个人数据和所述用户关系网络数据,构建历史用户特征;根据所述历史用户特征对机器学习模型进行训练,获得子预测模型;将所述子预测模型与预设风险判断规则进行融合,获得风险预测模型。
5.于一实施例中,所述基于所述用户个人数据和所述用户关系网络数据,构建历史用户特征,包括:对所述用户个人数据进行特征工程处理,得到用户个人特征;基于所述用户关系网络数据,确定用户关系网络特征;将所述用户个人特征和所述用户关系网络特征进行融合,得到所述历史用户特征。
6.于一实施例中,所述历史用户数据包括标签数据;所述基于所述用户关系网络数据,确定用户关系网络特征,包括:基于所述用户关系网络数据,构建图卷积神经网络的输入参数;依据所述输入参数和所述标签数据,对所述图卷积神经网络进行训练;当所述图卷积神经网络收敛,将所述输入参数在所述图卷积神经网络的中间处理结果作为所述用户关系网络特征。
7.于一实施例中,所述输入参数包括特征数据矩阵和邻接矩阵;所述基于所述用户关系网络数据,构建图卷积神经网络的输入参数,包括:基于所述用户关系网络数据,构建关系图谱;基于所述关系图谱中每一节点的属性数据,构建所述特征数据矩阵;基于所述关系图谱中节点之间的连接关系,构建所述邻接矩阵。
8.于一实施例中,所述机器学习模型为梯度提升决策树gbdt模型;所述根据所述历史用户特征对机器学习模型进行训练,获得子预测模型,包括:在lightgbm框架中,根据所述历史用户特征对所述gbdt模型进行训练,得到所述子预测模型。
9.于一实施例中,所述方法还包括:通过所述风险预测模型对目标用户数据进行处理,获得所述子预测模型输出的第一预测结果和所述风险判断规则确定的第二预测结果;基于所述第一预测结果和所述第二预测结果,确定目标预测结果。
10.本技术实施例第二方面提供了一种风险预测模型装置,包括:解析模块,用于从历史用户数据中解析出用户个人数据和用户关系网络数据;特征模块,用于根据所述用户个人数据和所述用户关系网络数据,构建历史用户特征;预测模块,用于根据所述历史用户特征对机器学习模型进行训练,获得子预测模型;融合模块,用于将所述子预测模型与预设风险判断规则进行融合,获得风险预测模型。
11.本技术实施例第三方面提供了一种电子设备,包括:存储器,用以存储计算机程序;处理器,用以执行所述计算机程序,以实现本技术实施例第一方面及其任以实施例的方法。
12.本技术实施例第四方面提供了一种非暂态电子设备可读存储介质,包括程序,当其藉由电子设备运行时,使得所述电子设备执行本技术实施例第一方面及其任一实施例的方法。
13.本技术提供的风险预测模型的构建方法、装置、设备和存储介质,首先从历史用户数据中解析出用户个人数据和用户关系网络数据,之后,基于所述用户个人数据和所述用户关系网络数据,构建历史用户特征,然后根据所述历史用户特征对机器学习模型进行训练,获得子预测模型,最后将所述子预测模型与预设风险判断规则进行融合,获得风险预测模型。如此,实现了通过历史用户数据来建立风险预测模型从而预测用户的风险程度,进而通过用户的不同风险程度来提供不同的信贷服务,避免公司遭受损失。
附图说明
14.为了更清楚地说明本技术实施例的技术方案,下面将对本技术实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本技术的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
15.图1为本技术一实施例的电子设备的结构示意图;
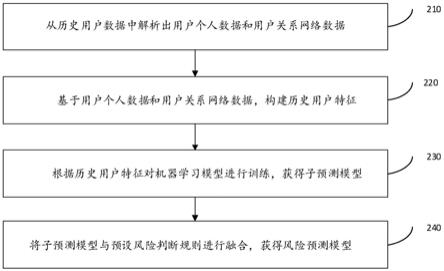
16.图2为本技术一实施例的风险预测模型的构建方法流程示意图;
17.图3为本技术一实施例的风险预测模型的构建方法流程示意图;
18.图4为本技术一实施例的风险预测模型装置示意图。
具体实施方式
19.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行描述。在本技术的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
20.如图1所示,本实施例提供一种电子设备1,包括:至少一个处理器11和存储器12,图1中以一个处理器为例。处理器11和存储器12通过总线10连接,存储器12存储有可被处理器11执行的指令,指令被处理器11执行,以使电子设备1可执行下述的实施例中方法的全部或部分流程,实现了通过历史用户数据来建立风险预测模型从而预测用户的风险程度,进
而通过用户的不同风险程度来提供不同的信贷服务,避免公司遭受损失。
21.于一实施例中,电子设备1可以是手机、笔记本电脑、台式计算机、或者多个计算机设备组成的大型计算系统等设备。
22.请参看图2,其为本技术一实施例的风险预测模型的构建方法流程示意图,该方法可由图1所示的电子设备1来执行,实现了通过历史用户数据来建立风险预测模型从而预测用户的风险程度,进而通过用户的不同风险程度来提供不同的信贷服务,避免公司遭受损失。该方法包括如下步骤:
23.步骤s210:从历史用户数据中解析出用户个人数据和用户关系网络数据。
24.在本步骤中,历史用户数据包括个人基本信息数据、消费数据、历史借贷数据、第三方征信数据、关系网络数据和标签数据等等,其中标签数据包括但不限于逾期时间、是否违约等。
25.步骤s220:基于用户个人数据和用户关系网络数据,构建历史用户特征。
26.步骤s230:根据历史用户特征对机器学习模型进行训练,获得子预测模型。
27.在本步骤中,机器学习模型为梯度提升决策树gbdt模型,将历史用户特征作为模型的输入,用户的标签作为输出,并在lightgbm框架中,根据历史用户特征对gbdt模型进行训练,得到子预测模型。
28.于一实施例中,将gbdt模型用于建立预测分类模型,其中训练样本为{xi,yi},i=1...n,其中xi为用户i的历史用户特征,具体形式为xi=(x
i1
,x
i2
,...,x
id
),d是特征数量,yi为用户的标签。若用户的标签是违约,则yi=1,若用户的标签是不违约,则yi=0。
29.步骤s240:将子预测模型与预设风险判断规则进行融合,获得风险预测模型。
30.在本步骤中,预设风险判断规则指的是根据用户的历史数据中某一类直接设置等级危险程度。
31.根据子预测模型对目标用户数据进行处理,获得子预测模型输出的第一预测结果,同时根据风险判断规则会确定的第二预测结果,最后根据第一预测结果和第二预测结果,确定目标预测结果。
32.于一实施例中,根据用户的历史借贷数据以及还款情况,设置预设风险判断规则,将历史借贷金额设置成三个等级,0~5000,5000~20000,20000以上,并且对应的风险危险程度为低危、中危和高危,若目标用户a的历史借贷数据中,曾借贷6000元且违约,则可判定该用户的危险程度为中危。
33.于一实施例中,根据子预测模型对目标用户数据进行处理,获得第一预测结果为低危,但是根据风险判断规则得出目标用户的危险程度是中危,则目标用户的最后预测结果就为中危。
34.请参看图3,其为本技术一实施例的风险预测模型的构建方法流程示意图,该方法包括如下步骤:
35.步骤s310:从历史用户数据中解析出用户个人数据和用户关系网络数据。详细参见上述实施例中对步骤s210的描述。
36.步骤s320:针对每一类别的个人子数据,对个人子数据进行多个维度的分箱处理,获得分箱结果。
37.在本步骤中,每一类别的个人子数据可以指的是用户的借贷金额、逾期时间、逾期
金额等数据。分箱处理指的是等距分箱、等频分箱、卡方分箱等。多个维度的分箱处理指的是不同尺寸或者不同的分箱方法,如采用等距分箱,尺寸可选用100、500、1000等。
38.步骤s330:从多个维度的分箱结果中,确定与标签数据相关性最大的分箱结果,作为类别初始特征。
39.在本步骤中,标签数据为是否违约,若用户的某个借贷金额没有违约,则该借贷金额对应的标签就是好,否则标签就为坏。
40.于一实施例中,依靠woe和iv值进行分箱好坏的判断,若iv值大于预设值,则可得到该分箱状态下的用户的初始特征,其中,woe和iv值的计算公式如下:
[0041][0042][0043]
其中,woei表示第i组的证据权重,goodi表示第i组中标签为好的数量,goods表示所有数据中标签为好的数量,badi表示第i组中标签为坏的数量,bads表示所有数据中标签为坏的数量。
[0044]
若iv大于0.03,则可以判断该分箱处理就是好的,即把该分箱处理下的结果作为类别初始特征。
[0045]
于一实施例中,若用户a的借贷金额为500、600、1100、2200、2500,使用等距分箱,且分箱的尺寸大小为1000下的iv值大于0.03,则即0-1000映射为1,1000-2000映射为2,2000-3000映射为3,则上面的借贷金额分别映射为1、1、2、3、3,即为用户a的借贷金额的初始特征。
[0046]
步骤s340:对所有类别的类别初始特征进行筛选,得到用户个人特征。
[0047]
在本步骤中,特征筛选的方法包括方差过滤法、递归特征消除法、模型选择法。
[0048]
于一实施例中,使用随机森林模型进行选择,随机森林由多棵决策树组成,当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个随机森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的依据,减少的不纯度越多越好。
[0049]
于一实施例中,通过逻辑回归进行特征选择,针对用户数据进行多次的训练,每一次训练后,都会根据权值系数来移除权重绝对值最低的特征,此时,再根据新的特征,继续下一轮的特征,不断递归直至剩余的特征数量达到所需的特征数量。
[0050]
步骤s350:基于用户关系网络数据,确定用户关系网络特征。
[0051]
在本步骤中,用户关系网络特征是由图卷积神经网络对用户的关系网络进行训练,当模型训练达到收敛时,将模型对输入数据的进行训练后的中间处理结果作为所述用户关系网络特征。
[0052]
于一实施例中,通过用户的联系人建立关系图谱,该关系图谱的形式为邻接矩阵,即根据用户之间的关系形成根据n
×
n的矩阵a,而根据用户的属性特征,如是否是渠道员
工、是否公司员工(在职、离职、非员工等)、订单数量、是否命中反欺诈、是否为在某借贷金融公司的黑名单等等,形成n个用户节点特征n
×
d的矩阵x。其中,图卷积的神经网络传播规则为:
[0053][0054]
其中i是一个单位矩阵。是矩阵的节点度对角矩阵,σ(.)是一个激活函数,如relu(.)=max(0,.),h
l
∈rn×d是一个第l层的激励矩阵,h0=x,即第一层的激励矩阵是每一个节点的特征向量构成的特征矩阵。当图卷积模型收敛时,h
l+1
即为用户关系网络的特征矩阵。
[0055]
步骤s360:将用户个人特征和用户关系网络特征进行融合,得到历史用户特征。
[0056]
在本步骤中,用户个人特征和用户关系网络特征的融合指的将用户的关系网络特征放到用户特征的后边,如若用户a的个人特征为[特征a,特征b,特征c],用户的关系网络特征是[特征d,特征e],则a的历史用户特征为[特征a,特征b,特征c,特征d,特征e]。
[0057]
步骤s370:根据历史用户特征对机器学习模型进行训练,获得子预测模型。详细参见上述实施例中对步骤s230的描述。
[0058]
步骤s380:将子预测模型与预设风险判断规则进行融合,获得风险预测模型。详细参见上述实施例中对步骤s240的描述。
[0059]
请参看图4,其为本技术一实施例的风险预测模型装置400,该装置可应用于图1所示的电子设备1,该装置包括:解析模块401、特征模块402、预测模块403和融合模块404,各个模块的原理关系如下:
[0060]
解析模块401,用于从历史用户数据中解析出用户个人数据和用户关系网络数据;特征模块402,用于根据用户个人数据和用户关系网络数据,构建历史用户特征;预测模块403,用于根据历史用户特征对机器学习模型进行训练,获得子预测模型;融合模块404,用于将子预测模型与预设风险判断规则进行融合,获得风险预测模型。
[0061]
上述数据访问装置400的详细描述,请参见上述实施例中相关方法步骤的描述。
[0062]
本发明实施例还提供了一种非暂态电子设备可读存储介质,包括:程序,当其在电子设备上运行时,使得电子设备可执行上述实施例中方法的全部或部分流程。其中,存储介质可为磁盘、光盘、只读存储记忆体(read-only memory,rom)、随机存储记忆体(random access memory,ram)、快闪存储器(flash memory)、硬盘(hard disk drive,缩写:hdd)或固态硬盘(solid-state drive,ssd)等。存储介质还可以包括上述种类的存储器的组合。
[0063]
虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下作出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1