一种数据处理方法、设备以及计算机可读存储介质与流程
本技术涉及互联网,尤其涉及一种数据处理方法、设备以及计算机可读存储介质。
背景技术:
1、随着人工智能的快速发展,智能化数据分析渐渐代替了传统的人工数据分析,如业务公司开始利用人工智能实现自动化数据分析。
2、文本的实体抽取以及实体间的关系识别是自动化数据分析中的常用场景,现有的实体间的关系识别方法是业务人员预先设定好客体实体词对应的关系实体词(表征主体与客体之间的关联关系),即得到客体实体词与关系实体词的映射关系。当需要识别文本中的主客体实体词之间的关联关系时,先抽取文本中的主体实体词以及客体实体词,然后将与客体实体词具有映射关系的关系实体词所指向的关系,确定为主体实体词以及客体实体词之间的关联关系。例如,业务人员预先构建异常活动a(属于客体实体词)与涉嫌(属于关系实体词)之间的映射关系,后续,识别文本“公司c认真落实指示,打击异常活动a”,基于现有方法抽取出公司c(属于主体实体词)以及异常活动a,故生成三元组(公司c,涉嫌,异常活动a),但是实际上公司c与异常活动a不具有涉嫌关联关系,所以采用现有关系识别方法可能会错误地抽取实体间的关联关系,即降低了实体间的关系识别率。
技术实现思路
1、本技术实施例提供一种数据处理方法、设备以及计算机可读存储介质,可以提高第一实体词以及第二实体词之间的关联关系的识别率。
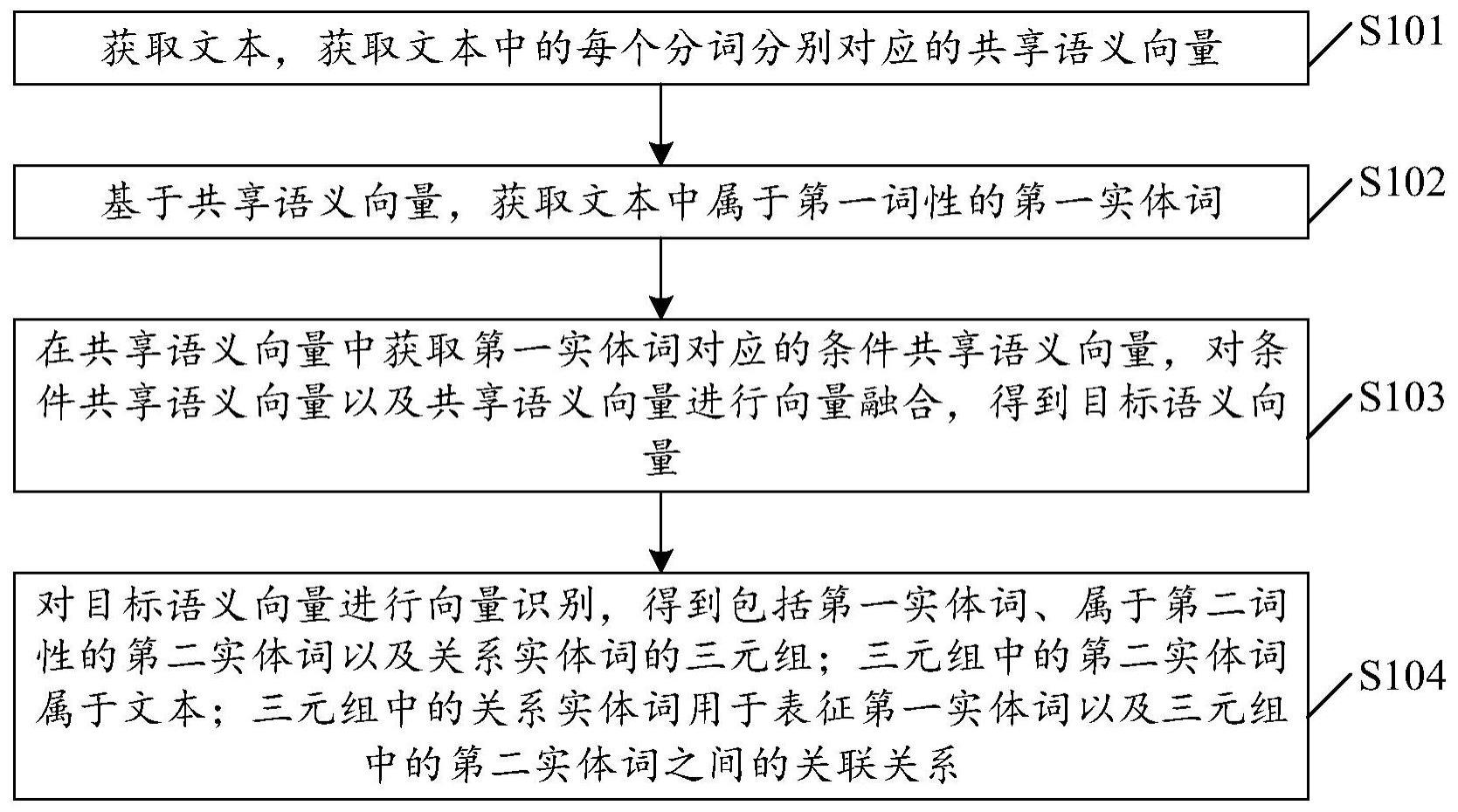
2、本技术实施例一方面提供了一种数据处理方法,包括:
3、获取文本,获取文本中的每个分词分别对应的共享语义向量;
4、基于共享语义向量,获取文本中属于第一词性的第一实体词;
5、在共享语义向量中获取第一实体词对应的条件共享语义向量,对条件共享语义向量以及共享语义向量进行向量融合,得到目标语义向量;
6、对目标语义向量进行向量识别,得到包括第一实体词、属于第二词性的第二实体词以及关系实体词的三元组;三元组中的第二实体词属于文本;三元组中的关系实体词用于表征第一实体词以及三元组中的第二实体词之间的关联关系。
7、本技术实施例一方面提供了一种数据处理方法,包括:
8、获取训练样本集;训练样本集包括样本文本、样本文本中的第一标签实体词以及与样本文本相关联的标签三元组;第一标签实体词的词性属于第一词性;标签三元组包括第一标签实体词、属于第二实体词的第二标签实体词以及标签关系实体词;第一词性不同于第二词性;标签三元组中的第二标签实体词属于样本文本;标签三元组中的标签关系实体词用于表征,第一标签实体词以及标签三元组中的第二标签实体词之间的关联关系;
9、将样本文本输入文本识别初始模型,在文本识别初始模型中,获取样本文本中的每个样本分词分别对应的预测共享语义向量;
10、基于预测共享语义向量,获取样本文本中的第一预测实体词;
11、在预测共享语义向量中获取第一预测实体词对应的预测条件共享语义向量,对预测条件共享语义向量以及预测共享语义向量进行向量融合,得到预测目标语义向量;
12、对预测目标语义向量进行向量识别,得到包括第一预测实体词、第二预测实体词以及预测关系实体词的预测三元组;预测三元组中的第二预测实体词属于样本文本;
13、根据第一预测实体词、第一标签实体词、预测三元组以及标签三元组,对文本识别初始模型中的参数进行调整,生成文本识别模型;文本识别模型用于生成针对文本的三元组。
14、本技术实施例一方面提供了一种数据处理装置,包括:
15、第一获取模块,用于获取文本,获取文本中的每个分词分别对应的共享语义向量;
16、第二获取模块,用于基于共享语义向量,获取文本中属于第一词性的第一实体词;
17、第一生成模块,用于在共享语义向量中获取第一实体词对应的条件共享语义向量,对条件共享语义向量以及共享语义向量进行向量融合,得到目标语义向量;
18、第二生成模块,用于对目标语义向量进行向量识别,得到包括第一实体词、属于第二词性的第二实体词以及关系实体词的三元组;三元组中的第二实体词属于文本;三元组中的关系实体词用于表征第一实体词以及三元组中的第二实体词之间的关联关系。
19、其中,数据处理装置,还包括:
20、第一获取模块,还用于获取文本识别模型,将文本输入至文本识别模型;文本识别模型包括输入层以及共享编码层;
21、第一获取模块,还包括基于输入层对文本进行切分处理,得到至少两个分词;至少两个分词包括分词ef,f为正整数,且f小于或等于至少两个分词对应的总数量;
22、第三获取模块,用于获取分词ef在文本中的位置信息,将针对分词ef的位置信息输入共享编码层;
23、第三生成模块,用于基于共享编码层,对针对分词ef的位置信息进行向量编码,得到分词ef对应的共享位置向量;
24、则第一生成模块,包括:
25、确定位置单元,用于确定第一实体词在文本中的位置信息;第一实体词在文本中的位置信息属于至少两个分词分别在文本中的位置信息;
26、第一获取单元,用于基于第一实体词在文本中的位置信息,在至少两个分词分别对应的共享位置向量中,获取第一实体词对应的共享位置向量;
27、第二获取单元,用于基于第一实体词对应的共享位置向量,在共享语义向量中获取第一实体词对应的条件共享语义向量。
28、其中,第一生成模块,包括:
29、第三获取单元,用于获取文本识别模型;文本识别模型包括第一编码层;第一编码层包括自注意力组件、第一归一化组件、前馈组件以及第二归一化组件;
30、第一输入单元,用于将共享语义向量输入自注意力组件,基于自注意力组件对共享语义向量进行向量编码,得到第一待归一化语义向量;
31、第二输入单元,用于将第一待归一化语义向量以及共享语义向量分别输入第一归一化组件,基于第一归一化组件对第一待归一化语义向量以及共享语义向量进行加权融合,得到待前馈语义向量;
32、第三输入单元,用于将待前馈语义向量输入至前馈组件,基于前馈组件对待前馈语义向量进行向量编码,得到第二待归一化语义向量;
33、第四输入单元,用于将条件共享语义向量、第二待归一化语义向量以及待前馈语义向量分别输入第二归一化组件,基于第二归一化组件,对条件共享语义向量、第二待归一化语义向量以及待前馈语义向量,进行向量融合,得到目标语义向量。
34、其中,第二归一化组件包括平均子组件、距离子组件、标准子组件、缩放子组件、加权子组件以及融合子组件;
35、第四输入单元,包括:
36、第一生成子单元,用于基于平均子组件,对第二待归一化语义向量以及待前馈语义向量进行向量平均,得到平均语义向量;
37、第二生成子单元,用于基于距离子组件,获取第二待归一化语义向量以及平均语义向量之间的向量距离,得到第一距离向量,获取待前馈语义向量以及平均语义向量之间的向量距离,得到第二距离向量;
38、第三生成子单元,用于基于标准子组件,对第二待归一化语义向量以及待前馈语义向量进行向量标准,得到标准语义向量;
39、第四生成子单元,用于基于缩放子组件,对第一距离向量以及标准语义向量进行向量缩放,得到第一缩放向量,对第二距离向量以及标准语义向量进行向量缩放,得到第二缩放向量;
40、第五生成子单元,用于生成条件共享语义向量对应的第一权重特征,以及条件共享语义向量对应的第二权重特征;
41、第六生成子单元,用于基于加权子组件,对第一缩放向量、第二缩放向量以及第一权重特征进行加权融合,得到待融合语义向量;
42、第七生成子单元,用于基于融合子组件,对第二权重特征以及待融合语义向量进行向量融合,得到目标语义向量。
43、其中,第二生成模块,包括:
44、第四获取单元,用于获取文本识别模型;文本识别模型包括关系识别层;
45、第四获取单元,还用于将目标语义向量输入关系识别层,基于关系识别层,对目标语义向量进行向量识别,得到识别语义向量;
46、第一生成单元,用于基于识别语义向量,生成包括第一实体词、属于第二词性的第二实体词以及关系实体词的三元组。
47、其中,第一获取模块,包括:
48、第五获取单元,用于获取文本识别模型,将文本输入至文本识别模型;文本识别模型包括输入层以及共享编码层;
49、第二生成单元,用于基于输入层对文本进行切分处理,得到至少两个分词,将至少两个分词分别输入共享编码层;
50、第三生成单元,用于基于共享编码层,对至少两个分词分别进行向量编码,得到每个分词分别对应的共享语义向量。
51、其中,第二获取模块,包括:
52、第六获取单元,用于获取文本识别模型;文本识别模型包括第二编码层、实体识别层以及解码层;
53、第五输入单元,用于将共享语义向量输入第二编码层,基于第二编码层对共享语义向量进行向量编码,得到待识别语义向量;
54、第六输入单元,用于将待识别语义向量输入实体识别层,基于实体识别层对待识别语义向量进行向量识别,得到用于表征第一实体词的待解码语义向量;
55、第七输入单元,用于将用于表征第一实体词的待解码语义向量输入解码层,基于解码层,对用于表征第一实体词的待解码语义向量进行向量解码,得到文本中属于第一词性的第一实体词。
56、其中,待识别语义向量包括待识别语义向量ab,b为正整数,且b小于或等于待识别语义向量对应的总数量;实体识别层包括针对待识别语义向量ab的实体识别组件cb;
57、第六输入单元,包括:
58、第八生成子单元,用于若实体识别组件cb为实体识别层中的首个实体识别组件,则在实体识别组件cb中对待识别语义向量ab进行向量识别,得到待识别语义向量ab对应的待解码语义向量db;
59、第九生成子单元,用于若实体识别组件cb不为实体识别层中的首个实体识别组件,则在实体识别组件cb中,对待识别语义向量ab以及与待识别语义向量ab存在位置关联关系的目标待识别语义向量进行向量融合,得到待识别语义向量ab对应的待解码语义向量db;目标待识别语义向量属于待识别语义向量;
60、第十生成子单元,用于基于每个待识别语义向量分别对应的待解码语义向量,得到用于表征第一实体词的待解码语义向量。
61、其中,三元组包括针对第一实体词的至少两个三元组;至少两个三元组包括三元组gh,h为正整数,且h小于或等于至少两个三元组的总数量;
62、数据处理装置,还包括:
63、第一确定模块,用于确定三元组gh中的关系实体词所表征的关联关系属性,若关联关系属性为负面关联关系,则将第一实体词所表征的对象确定为目标对象;
64、第二确定模块,用于从至少两个三元组中获取包括简称关系实体词的三元组,将包括简称关系实体词的三元组中的第二实体词确定为简称实体词;简称实体词所表征的对象等于目标对象;简称关系实体词是指表征的关联关系属性为简称关联关系的关系实体词;
65、第二确定模块,用于从至少两个三元组中获取包括归属关系实体词的三元组,将包括归属关系实体词的三元组中的第二实体词确定为归属实体词;归属实体词所表征的对象归属于目标对象;归属关系实体词是指表征的关联关系属性为归属关联关系的关系实体词;
66、关联存储模块,用于关联存储三元组gh、简称关系实体词、简称实体词、归属关系实体词以及归属实体词。
67、本技术实施例一方面提供了一种数据处理装置,包括:
68、第一获取模块,用于获取训练样本集;训练样本集包括样本文本、样本文本中的第一标签实体词以及与样本文本相关联的标签三元组;第一标签实体词的词性属于第一词性;标签三元组包括第一标签实体词、属于第二实体词的第二标签实体词以及标签关系实体词;第一词性不同于第二词性;标签三元组中的第二标签实体词属于样本文本;标签三元组中的标签关系实体词用于表征,第一标签实体词以及标签三元组中的第二标签实体词之间的关联关系;
69、第一获取模块,还用于将样本文本输入文本识别初始模型,在文本识别初始模型中,获取样本文本中的每个样本分词分别对应的预测共享语义向量;
70、第二获取模块,用于基于预测共享语义向量,获取样本文本中的第一预测实体词;
71、第一生成模块,用于在预测共享语义向量中获取第一预测实体词对应的预测条件共享语义向量,对预测条件共享语义向量以及预测共享语义向量进行向量融合,得到预测目标语义向量;
72、第二生成模块,用于对预测目标语义向量进行向量识别,得到包括第一预测实体词、第二预测实体词以及预测关系实体词的预测三元组;预测三元组中的第二预测实体词属于样本文本;
73、第三生成模块,用于根据第一预测实体词、第一标签实体词、预测三元组以及标签三元组,对文本识别初始模型中的参数进行调整,生成文本识别模型;文本识别模型用于生成针对文本的三元组。
74、其中,第三生成模块,包括:
75、第一生成单元,用于根据第一预测实体词以及第一标签实体词,生成实体损失值;
76、第二生成单元,用于根据预测三元组以及标签三元组,生成关系损失值;
77、第三生成单元,用于根据实体损失值以及关系损失值确定文本识别初始模型对应的总损失值;
78、第三生成单元,还用于根据总损失值对文本识别初始模型中的参数进行调整,生成文本识别模型。
79、本技术一方面提供了一种计算机设备,包括:处理器、存储器、网络接口;
80、上述处理器与上述存储器、上述网络接口相连,其中,上述网络接口用于提供数据通信功能,上述存储器用于存储计算机程序,上述处理器用于调用上述计算机程序,以使得计算机设备执行本技术实施例中的方法。
81、本技术实施例一方面提供了一种计算机可读存储介质,上述计算机可读存储介质中存储有计算机程序,上述计算机程序适于由处理器加载并执行本技术实施例中的方法。
82、本技术实施例一方面提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中;计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行本技术实施例中的方法。
83、在本技术实施例中,计算机设备通过获取文本中的每个分词分别对应的共享语义向量,可以获取文本中属于第一词性的第一实体词,进一步,在共享语义向量中获取第一实体词对应的条件共享语义向量,对条件共享语义向量以及共享语义向量进行向量融合,可以得到目标语义向量;对目标语义向量进行向量识别,可以得到包括第一实体词、属于第二词性的第二实体词以及关系实体词的三元组,其中,三元组中的关系实体词可以用于表征第一实体词以及三元组中的第二实体词之间的关联关系。上述可知,本技术先获取文本中的第一实体词,将针对第一实体词的条件共享语义向量作为条件输入,与共享语义向量进行融合,故目标语义向量是一个包含条件的语义向量,即将识别出的第一实体词作为条件,以在给定第一实体词的条件下,识别文本中的第二实体词以及第一实体词具有关系实体词所指向的关联关系,故本技术实施例可以提高第一实体词以及第二实体词之间的关联关系的识别率。
- 还没有人留言评论。精彩留言会获得点赞!