考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法
1.本发明涉及电力信息技术领域,具体是考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法。
背景技术:
2.2015年3月15日,中共中央、国务院下发《关于进一步深化电力体制改革的若干意见》,标志着售电侧放开,传统电力市场的“单买-单卖”垂直一体化管控模式将向“多买-多卖”的定制化、市场化模式转变;2019年6月,国家发展和改革委员会发布《关于全面放开经营性电力用户发用电计划的通知》,进一步扩大了零售市场的用户覆盖范围,用户由原来的被动接受供电模式向自主选择售电公司的模式发展。与此同时,随着高质量发展的理念得以贯彻,对于电力用户而言,其不仅要求供电的可靠性和安全性,还希望获得多样化、便捷化的增值服务;对于售电公司而言,也期望通过售电套餐、综合能源服务、节能服务等增值服务增强已有用户黏度,并吸引大量新用户。售电套餐作为竞争性售电市场环境下的服务和运营模式创新,是售电公司提高收益、获得市场竞争力的必要手段。德国、美国、英国等国外的电力市场已为用户提供了上千种的售电套餐,我国也设计了多种形式的电价套餐供用户抉择,如:面向工商业用户设计了考虑用户行为改变对削峰填谷作用,以及其对自身带来影响的电力套餐;基于用户参考价格决策及用户黏性,对售电套餐进行了优化设计;考虑用户有限理性选择行为,分别设计了定制化的分时电价套餐和峰谷组合电力套餐。然而,面对售电市场中众多的售电套餐,售电公司应该如何准确、科学地为用户推荐满足其需求的电力套餐是提升用户满意度、增加其市场份额的关键。此外,现有文献[1]和[2]考虑用户有限理性选择行为,也分别设计了定制化的分时电价套餐和峰谷组合电力套餐。
[0003]
现有国内外对售电套餐的推荐可大致分为直接推荐方法和间接推荐方法。售电套餐直接推荐方法多数应用于在线推荐平台,其基本思路为基于用户用电情况,比较各售电套餐的成本,将成本最低的售电套餐推荐给相应的用户,如:iselect,power to choose,energy made easy,check24等平台。在线推荐方法简单、易于实施,但此种仅从用户电费成本出发的售电套餐推荐方法忽略了用户评价信息的多样性,如:绿电、忠诚度。除直接基于成本的推荐方法外,还有基于用户的用电多样性特征量,对用户进行分层聚类,分别为用电行为多变用户和用电行为规律用户推荐了阶梯电价套餐和阶梯分时电价套餐。虽然上述推荐方法考虑了用户的用电行为特性和偏好,但仍然忽略了用户对售电套餐评价时表现出的犹豫模糊特性,以及不同用户由于知识和文化背景的差异性导致的评价信息的异质性,将会给售电套餐的精准推荐带来较大的误差。此外,考虑到用户对售电套餐属性的知识有限,其提供的权重信息存在不完整的情况,如:用户可能提供的属性权重信息为“属性a比属性b重要”或“属性a比属性b重要2倍”,如何处理上述多样化的属性权重语言信息,将用户提供的不完全权重信息转化为确定的属性权重信息是售电公司为用户精准推荐售电套餐必须要解决的问题。
[0004]
[1]肖白,崔涵淇,姜卓,等.基于有限理性用户选择行为的定制化电价套餐设计
[j].电网技术,2021,45(3):1050-1058.
[0005]
xiao bai,cui hanqi,jiang zhuo,et al.customized electricity price package design based on limited rational user selection behavior[j].power system technology,2021,45(3):1050-1058.
[0006]
[2]张智,卢峰,林振智,等.考虑用户有限理性的售电公司峰谷组合电力套餐设计[j].电力系统自动化,2021,45(16):114-123.
[0007]
zhang zhi,lu feng,lin zhenzhi,et al.peak-valley combination electricity package design for electricity retailer considering bounded rationality of consumers[j].automation of electric power systems,2021,45(16):114-123.
技术实现要素:
[0008]
本发明要解决的技术问题是提供考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法,用以基于用户满意度量化结果,给用户提供了售电套餐的推荐。
[0009]
为了解决上述技术问题,本发明提供考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法,包括具体过程如下:
[0010]
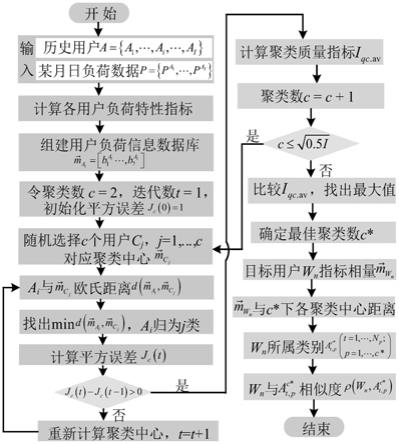
步骤s1、基于用户用电特性指标,建立用户负荷信息数据库,并基于改进k-means聚类算法,对用户进行聚类,确定目标用户所属类别;
[0011]
步骤s2、考虑用户提供的不完全权重信息和多粒度犹豫模糊语言评价集,构建用户对售电套餐的评价矩阵;
[0012]
步骤s3、分别计算历史用户和目标用户对售电套餐的满意度;
[0013]
步骤s4、基于用户满意度量化结果,获得了全排序的售电套餐推荐和top-m的售电套餐推荐。
[0014]
作为本发明的考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法的改进:
[0015]
所述步骤s1具体过程为:
[0016]
步骤s1.1、用户负荷信息数据库组建
[0017]
基于用户a={a1,a2,
…
,ai,
…
,ai}某月的日负荷数据为:其中,k为某月总的小时数;基于月负荷率最高利用小时数工作日峰谷差率均值非工作日峰谷差率均值峰期负载率均值平期负载率均值和谷期负载率均值获得用户ai的负荷特性指标向量并组建用户与其负荷特性指标向量对应的用户负荷信息数据库;
[0018]
(1)月负荷率:
[0019]
[0020]
其中,和分别为用户ai的月平均负荷和最大负荷,为用户ai某月总的小时数中第k小时的日负荷数据;
[0021]
(2)最高利用小时数
[0022][0023]
其中,为用户ai的整月用电量;
[0024]
(3)工作日峰谷差率均值
[0025][0026]
其中,kw为工作日总的天数,为工作日第i天的日最大负荷,为非工作日第i天的日最小负荷;
[0027]
(4)非工作日峰谷差率均值
[0028][0029]
其中,k
nw
为非工作日总的天数,为非工作日第j天的日最大负荷,为非工作日第j天的日最小负荷;
[0030]
(5)峰期负载率均值
[0031][0032]
其中,峰时段定义为08:00-11:00和18:00-21:00,t为总的天数,满足t=kw+k
nw
,为第t天峰时段用户ai的负荷均值,为第t天用户ai的负荷均值;
[0033]
(6)平期负载率均值
[0034][0035]
其中,平时段定义为06:00-08:00,11:00-18:00和21:00-22:00,为第t天平时段用户ai的负荷均值;
[0036]
(7)谷期负载率均值
[0037][0038]
其中,谷时段定义为22:00-24:00和00:00-06:00,为第t天谷时段用户ai的负荷均值;
[0039]
步骤s1.2、基于历史用户负荷信息数据库的聚类
[0040]
基于步骤s1.1组建的用户负荷信息数据库,采用改进的k-means聚类算法对历史用户进行聚类,具体步骤如下:
[0041]
步骤s1.2.1、令聚类数c=2,随机选取c个用户,记为c1,c2,
…
,cj,
…
,cc,将其负荷特性指标向量作为聚类中心
[0042]
步骤s1.2.2、分别计算用户ai(i=1,2,
…
,i)与各聚类中心的欧式距离
[0043]
步骤s1.2.3、针对用户ai,比较并得到的最小值,并将用户ai归为j类,设属于第j类的用户数为ij,相应的用户表示为
[0044]
步骤s1.2.4、基于步骤s1.2.3的分类结果,如式(8)计算平方误差jc(t):
[0045][0046]
其中,t为迭代次数,为对应a
i,j
第j类中用户ai的负荷特性指标向量;
[0047]
步骤s1.2.5、重新计算聚类中心
[0048]
计算每一类中所有用户负荷特性指标向量与聚类中心的平均距离d,将该类中与聚类中心距离小于2d的用户选出,然后重新计算选出用户的负荷特性指标的均值作为新的聚类中心;
[0049]
步骤s1.2.6、判断是否满足式(9):
[0050]
jc(t+1)-jc(t)≥0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0051]
如否,则t=t+1,然后返回步骤s1.2.1继续迭代;
[0052]
如满足式(9),则迭代结束,并基于第t次迭代的聚类结果,计算聚类质量指标i
qc.av
:
[0053][0054]
其中,i
qc
(i)表示聚类数为c时,第i个用户与其所属类的聚类中心的紧密程度:
[0055][0056]
其中,表示类间平均距离,为用户ai与所属类别以外的其他用户负荷特性指标相量间距离的平均值;表示类内平均距离,为用户ai与所属类别内的其他用户负
荷特性指标相量间距离的平均值;
[0057]
步骤s1.2.7、令聚类数c=c+1,返回并执行步骤s1.2.1-步骤s1.2.6直到聚类数达到最大值
[0058]
步骤s1.2.8、比较不同聚类数下的聚类质量指标i
qc.av
,i
qc.av
最大时对应的聚类数为最佳聚类数c*;
[0059]
步骤s1.3、基于pearson相关系数的目标用户与历史用户相似度计算
[0060]
目标用户为需推荐售电套餐的用户,表示为w={w1,w2,
…
,wn,
…
,wm},基于各用户某月的日负荷数据,结合式(1)-式(7),获得各目标用户的负荷特性指标向量计算最佳聚类数c*下各聚类中心与的距离,距离最小者对应的类为目标用户wn所属类别;
[0061]
设目标用户wn属于第p类历史用户,该类用户数量为n
p
,表示为利用pearson相关系数刻画目标用户与历史用户间的相似度:
[0062][0063]
其中,表示目标用户wn和历史用户的相似度;和分别表示用户wn和历史用户的第d个负荷特性指标,和分别表示用户wn和历史用户负荷特性指标的平均值。
[0064]
作为本发明的考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法的进一步改进:
[0065]
所述步骤2具体过程为:
[0066]
步骤s2.1、基于犹豫模糊语言集的用户对售电套餐评价矩阵的构建
[0067]
售电套餐集合为t={t1,t2,
…
tj,
…
,tj},用户a={a1,a2,
…
,ai,
…
,ai}对售电套餐评价属性集为采用犹豫模糊语言描述用户对售电套餐的评价信息:
[0068]
设用户ai的语言评价集为其中,g(ai)表示语言评价集的粒度,且为奇数,表示第p个语言评价量,p=0,1,
…
,g
(ai)-1为语言评价量的符号角标;语言评价集中元素按照顺序排列:
[0069]
若p》q,则:
[0070]
用户ai基于自身语言评价集对售电套餐做出评价,评价矩阵为:
[0071]
其中,表示用户ai对售电套餐tj的属性给出的犹豫模糊语言评价信息,j,k分别为第j个套餐,第k个属性;
[0072]
步骤s2.2、考虑不完全权重的售电套餐属性权重确定
[0073]
采用离差最大化方法确定各属性权重
[0074][0075]
其中,“其他”代表用户ai提供的不完全权重信息,表示对于第k个属性的用户ai对各售电套餐给出的语言评价间的偏差程度:
[0076][0077]
其中,p=0,1,
…
,g(ai)-1,为用户ai对第q个套餐中的第k个属性的评价;
[0078]
采用犹豫模糊语言加权平均算子(hflwao)对各用户的评价信息进行集成,得到各用户对售电套餐的评价矩阵
[0079][0080]
其中,表示用户ai对售电套餐tj的评价结果;
[0081]
hflwao的计算方法如下:
[0082]
(1)、基于售电套餐tj的k个属性,设如下集合:
[0083][0084]ak
为第k个属性的评价结果;
[0085]
(2)、分别令进行如下迭代:
[0086][0087]
其中,trunc(
·
)为取整函数;δ(
·
)代表语言评价量的符号角标与犹豫模糊语言集间的一个映射关系,mh为用户对套餐的评价结果,为评价程度,为评价隶属度;
[0088]
令β∈[0,g(ai)-1],用一个二元组描述β的等值信息:
[0089][0090]
存在变换函数δ-1
(
·
),将二元组等值信息转换为等值的数值:
[0091][0092]
(3)、采用分布式语言评价算子daa计算获得
[0093][0094]
其中,为一个语言评价二元组,代表语言评价变量的比例:
[0095][0096]
步骤s2.3、用户对售电套餐的多粒度犹豫模糊语言评价信息的统一化
[0097]
将用户评价售电套餐时使用不同粒度下的语言评价集转化为同一粒度下的语言评价集,将基于粒度为g(ai)评价集的评价信息转化为基于粒度为g(af)评价集的评价信息过程如下:
[0098]
步骤s2.3.1、令g(*)=lcm(g(ai)-1,g(af)-1)+1,其中,lcm(
·
)表述取最小公倍数;
[0099]
步骤s2.3.2、建立虚拟语言集
[0100]
令θe=0,e=0,1,
…
,g(*)-1;
[0101]
步骤s2.3.3、若zh=0,1,
…
,g(ai)-1,计算得:
[0102]
步骤s2.3.4、令zh=0,1,
…
,g(*)-1,若计算
[0103]
步骤s2.3.5、基于计算统一化后的语言评价变量比例,如式(22)所示:
[0104][0105]
步骤s2.3.6、基于式(22),得统一化后的语言评价信息
[0106]
基于步骤s2.3.1-s2.3.6,获得统一粒度下用户对售电套餐的评价矩阵其中,表示统一粒度下用户ai对售电套餐tj的评价信息:
[0107][0108]
为在af粒度下的语言评价,为新的评价隶属度,为新的评价程度。
[0109]
作为本发明的考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法的进一步改进:
[0110]
所述步骤3的具体过程为:
[0111]
基于式(23)统一粒度下用户ai对售电套餐tj的评价信息对用户的评价信息
求期望,获得用户对售电套餐的满意度矩阵其中,为用户ai对售电套餐tj的满意度:
[0112][0113]
目标用户wn对售电套餐tj的满意度sc
nj
为:
[0114][0115]
作为本发明的考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法的进一步改进:
[0116]
所述全排序的售电套餐推荐具体为:
[0117]
基于目标用户对各售电套餐的满意度结果计算均方根误差ε
1n
,然后按均方根误差ε
1n
按从小到大对应的售电套餐排序推荐给目标用户,供目标用户抉择:
[0118][0119]
其中,j为售电套餐总数,o
nj
和分别表示针对目标用户wn、售电套餐tj的实际排序结果和式(25)算法所得的排序结果;
[0120]
所述top-m的售电套餐推荐具体为:
[0121]
基于目标用户对各售电套餐的满意度结果,售电公司仅将排序为前m的套餐推荐给目标用户,且不提供排序结果;
[0122]
推荐给目标用户wn的前m个售电套餐的集合与实际排名为前m的套餐集合的推荐准确度ε
2n
为:
[0123][0124]
为目标用户wn实际排名为前m的套餐集合,为算法得到目标用户wn排名为前m的套餐集合,m为推荐的套餐总数。
[0125]
本发明的有益效果主要体现在:
[0126]
1、本发明提出了考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法,利用改进k-means聚类算法对用户进行聚类,能有效减少噪声点的影响,使得聚类结果能更有效地反映各类用户的负荷特性;
[0127]
2、本发明提出了考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法,采用多粒度犹豫模糊语言评价集对用户的评价信息进行表征,且考虑用户提供售电套餐属性权重信息的不完整性,不仅能反映用户评价售电套餐时的犹豫模糊性,还能使得具有不同文化背景的用户能更加灵活弹性地提供评价信息,能更真实地反映用户对售电套餐的满意度,为售电公司推荐售电套餐提供了新思路;
[0128]
3、本发明提出了考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法能够保证较高的推荐准确度和较好的推荐性能。
附图说明
[0129]
下面结合附图对本发明的具体实施方式作进一步详细说明。
[0130]
图1为本发明的用户负荷信息数据库的组建与聚类流程的示意图;
[0131]
图2为本发明的考虑多粒度犹豫模糊集和不完全权重信息的售电套餐推荐流程的示意图;
[0132]
图3为实验1中的园区各用户平均每天负荷频次分布直方图;
[0133]
图4为实验1中的园区各用户平均日负荷率、平均日峰谷差率与语言评价集粒度示意图;
[0134]
图5为实验1中的不同聚类数对应的聚类质量指标值的示意图;
[0135]
图6为实验1中的各类用户的聚类结果和各类用户的数量的示意图;
[0136]
图7为实验1中的晚高峰型历史用户对售电套餐的满意度的示意图;
[0137]
图8为实验1中的目标用户与晚高峰型历史用户的相似度的示意图;
[0138]
图9为实验1中的目标用户w1对各售电套餐的满意度量化结果的示意图;
[0139]
图10为实验1中的改进k-means聚类算法和原始k-means聚类算法得到的聚类中心的示意图;
[0140]
图11为实验1中的不同噪声比例下的最佳聚类数和聚类质量指标的示意图;
[0141]
图12为实验1中的各类目标用户对售电套餐的满意度评价结果的示意图;
[0142]
图13为实验1中的不同方法所得售电套餐推荐排序结果比较的示意图。
具体实施方式
[0143]
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
[0144]
实施例1、考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法,如图1-2所示,首先,基于用户用电特性指标,建立用户负荷信息数据库,并基于改进k-means聚类算法,对用户进行聚类,确定目标用户所属类别;然后,考虑用户提供的不完全权重信息和多粒度犹豫模糊语言评价集,构建用户对售电套餐的评价矩阵;接着,分别计算历史用户和目标用户对售电套餐的满意度;最后,基于用户满意度量化结果,提出了全排序推荐和top-m推荐方法。
[0145]
1、用户负荷信息数据库组建与聚类
[0146]
1.1、用户负荷信息数据库组建
[0147]
不同类型用户的用电特性存在差异,其差异体现在用户负荷特性指标的不同,基
于用户a={a1,a2,
…
,ai,
…
,ai}某月的日负荷数据其中,k为某月总的小时数,以月负荷率、最高利用小时数、工作日和非工作日峰谷差率均值、峰平谷期负载率均值为特性指标,刻画各用户的用电特性。以用户ai为例,各特性指标的物理意义和定义如下。
[0148]
(1)月负荷率
[0149]
月负荷率用于反映用户整月的负荷变化波动情况,为月平均负荷和最大负荷的比值,其计算式如式(1)所示。
[0150][0151]
其中,和分别为用户ai的月平均负荷和最大负荷,为用户ai某月总的小时数中第k小时的日负荷数据;
[0152]
月负荷率越大,用户ai整月的负荷波动越大。
[0153]
(2)最高利用小时数
[0154]
最高利用小时数用于反映用户负荷的时间利用效率,为月总用电量与月最大负荷的比值,其计算式如式(2)所示:
[0155][0156]
其中,为用户ai的整月用电量,最高利用小时数越大;用户ai整月的负荷时间利用效率越高。
[0157]
(3)工作日峰谷差率均值
[0158]
工作日峰谷差率均值用于反映用户工作日用电的平稳性,为工作日最大负荷与最小负荷差值与工作日最大负荷比值的比值的均值,其计算式如式(3)所示。
[0159][0160]
其中,kw为工作日总的天数,为工作日第i天的日最大负荷,为非工作日第i天的日最小负荷;
[0161]
工作日峰谷差率均值越大,用户的工作日负荷波动越大。
[0162]
(4)非工作日峰谷差率均值
[0163]
非工作日峰谷差率均值用于反映用户非工作日用电的平稳性,为非工作日最大负
荷与最小负荷差值与非工作日最大负荷比值的均值,其计算式如式(4)所示:
[0164][0165]
其中,k
nw
为非工作日总的天数,为非工作日第j天的日最大负荷,为非工作日第j天的日最小负荷;
[0166]
非工作日峰谷差率均值越大,用户ai的非工作日负荷波动越大。
[0167]
(5)峰期负载率均值
[0168]
峰期负载率均值用于反映用户峰时段负荷的变化波动情况,峰时段定义为08:00-11:00和18:00-21:00,为峰时段时段负荷均值与当天负荷均值比值的均值,其计算式如式(5)所示:
[0169][0170]
其中,t为总的天数,满足t=kw+k
nw
,为第t天峰时段用户ai的负荷均值,为第t天用户ai的负荷均值;
[0171]
峰期负载率均值越大,用户ai的负荷在峰时段的波动就越明显。
[0172]
(6)平期负载率均值
[0173]
平期负载率均值用于反映用户平时段负荷的变化波动情况,平时段定义为06:00-08:00,11:00-18:00和21:00-22:00,为平时段负荷均值与当天负荷均值比值的均值,其计算式如式(6)所示:
[0174][0175]
其中,为第t天平时段用户ai的负荷均值;
[0176]
平期负载率均值越大,用户ai的负荷在平时段的波动就越明显。
[0177]
(7)谷期负载率均值
[0178]
谷期负载率均值用于反映用户谷时段负荷的变化波动情况,谷时段定义为22:00-24:00和00:00-06:00,为谷时段负荷均值与当天负荷均值比值的均值,其计算式如式(7)所示:
[0179][0180]
其中,为第t天谷时段用户ai的负荷均值。谷期负载率均值越大,用户ai的负荷在谷时段的波动就越明显。
[0181]
基于上述用户负荷特性指标,可得用户ai的负荷特性指标向量
并组建用户与其负荷特性指标向量对应的用户负荷信息数据库,为历史用户聚类和目标用户与历史用户相似度的计算提供支撑。
[0182]
1.2基于历史用户负荷信息数据库的聚类
[0183]
考虑到现有历史用户数量较大,为了降低计算量,需将具有相似负荷特性的用户进行聚类。基于组建的用户负荷信息数据库,采用改进的k-means聚类算法对历史用户进行聚类,具体步骤如下:
[0184]
1)令聚类数c=2,随机选取c个用户,记为c1,c2,
…
,cj,
…
,cc,将其负荷特性指标向量作为聚类中心
[0185]
2)分别计算用户ai(i=1,2,
…
,i)与各聚类中心的欧式距离
[0186]
3)针对ai,比较并得到的最小值,并将用户ai归为j类,设属于第j类的用户数为ij,相应的用户表示为
[0187]
4)基于步骤3)的分类结果,计算平方误差jc(t),如式(8)所示,其中,t为迭代次数;
[0188][0189]
其中,为对应a
i,j
第j类中用户ai的负荷特性指标向量
[0190]
5)重新计算聚类中心
[0191]
原始k-means聚类算法直接将每一类的均值作为新的聚类中心,为了减小噪声点的影响,需对其进行改进。首先,计算每一类中所有用户负荷特性指标向量与聚类中心的平均距离d;然后,将该类中与聚类中心距离小于2d的用户选出;最后,重新计算选出用户的负荷特性指标的均值作为新的聚类中心。上述操作能排除噪声点的影响,使得聚类中心更能反映正常用户负荷的特性;
[0192]
6)判断是否满足式(9):
[0193]
jc(t+1)-jc(t)≥0
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0194]
如否,则t=t+1,然后返回步骤1)继续迭代;
[0195]
如满足式(9),则迭代结束,并基于第t次迭代的聚类结果,计算聚类质量指标i
qc.av
,如式(10);
[0196]
[0197]
其中,i
qc
(i)表示聚类数为c时,第i个用户与其所属类的聚类中心的紧密程度,取决于类内距离和类间距离,如式(11)所示。
[0198][0199]
其中,表示类间平均距离,为用户ai与所属类别以外的其他用户负荷特性指标相量间距离的平均值;表示类内平均距离,为用户ai与所属类别内的其他用户负荷特性指标相量间距离的平均值。可见,类间平均距离越大,类内平均距离越小,聚类质量越好;
[0200]
7)令聚类数c=c+1,返回步骤1),执行步骤1)-步骤6),直到聚类数达到最大值
[0201]
8)比较不同聚类数下的聚类质量指标i
qc.av
,i
qc.av
最大时对应的聚类数为最佳聚类数c*。
[0202]
1.3基于pearson相关系数的目标用户与历史用户相似度计算
[0203]
目标用户为需推荐售电套餐的用户,表示为w={w1,w2,
…
,wn,
…
,wm},基于各用户某月的日负荷数据,结合式(1)-式(7),可获得各目标用户的负荷特性指标向量计算最佳聚类数c*下各聚类中心与的距离,距离最小者对应的类为目标用户wn所属类别。
[0204]
设目标用户wn属于第p类历史用户,该类用户数量为n
p
,表示为考虑到pearson相关系数能够有效衡量各用户负荷特性间的相关性和密切程度,利用该系数刻画目标用户与历史用户间的相似度,如式(12)所示。
[0205][0206]
其中,表示目标用户wn和历史用户的相似度,其值越大,表示两用户的负荷特性越相似,越有可能选择相同的售电套餐。和分别表示用户wn和历史用户的第d个负荷特性指标,和分别表示用户wn和历史用户负荷特性指标的平均值。
[0207]
2考虑多粒度犹豫模糊集和不完全权重的用户对售电套餐的评价
[0208]
2.1基于犹豫模糊语言集的用户对售电套餐评价矩阵的构建
[0209]
设售电套餐集合为t={t1,t2,
…
tj,
…
,tj},用户a={a1,a2,
…
,ai,
…
,ai}对售电套餐评价属性集为考虑到用户对售电套餐属性进行评价时很难给出定量信息,并表现出一定的犹豫模糊性,因此,采用犹豫模糊语言描述用户对售电套餐的评价信息。
[0210]
设用户ai的语言评价集为其中,g(ai)表示语言评价集的粒度,且为奇数,表示第p个语言评价量,p=0,1,
…
,g(ai)-1为语言评价量的符号角标。语言评价集中元素按照顺序排列,即:若p》q,则:
[0211]
用户ai基于自身语言评价集对售电套餐做出评价,评价矩阵为其中,表示用户ai对售电套餐tj的属性给出的犹豫模糊语言评价信息。值得注意的是,可包含多个中的语言评价量,j,k分别为第j个套餐,第k个属性。
[0212]
2.2考虑不完全权重的售电套餐属性权重确定
[0213]
售电套餐属性权重反映了该属性在售电套餐评价中的重要程度。考虑到用户对售电套餐属性重要性的知识有限,且可能提供的权重信息不完整,如:用户ai提供的权重信息为:属性1比属性2更重要属性1的权重不超过属性3与属性4的重要性之差不小于上述信息称为不完全权重信息,为了保证所得权重能综合反映各属性的重要程度,采用离差最大化方法确定各属性权重模型如式(13)所示。
[0214][0215]
其中,“其他”代表用户ai提供的不完全权重信息。表示对于第k个属性的用户ai对各售电套餐给出的语言评价间的偏差程度,如式(14)所示。
[0216][0217]
其中,p=0,1,
…
,g(ai)-1,为用户ai对第q个套餐,第k个属性的评价
[0218]
求解式(13)所示单目标优化模型,可获得售电套餐各属性的权重为了保证用户评价信息的完整性和可解释性,采用犹豫模糊语言加权平均算子(hflwao,hesitant fuzzy linguistic weighted average operator)对各用户的评价信息进行集成,得到各用户对售电套餐的评价矩阵其中,表示用户ai对售电套餐tj的评价结果,其确定方法如式(15):
[0219][0220]
其中,hflwao的计算方法如下:
[0221]
1)基于售电套餐tj的k个属性,设如下集合:
[0222][0223]ak
为第k个属性的评价结果;
[0224]
2)分别令进行如下迭代:
[0225][0226]
其中,trunc(
·
)为取整函数,直接去除小数部分;δ(
·
)代表语言评价量的符号角标与犹豫模糊语言集间的一个映射关系。
[0227]
mh为用户对套餐的评价结果,为评价程度,为评价隶属度;
[0228]
以用户ai的语言评价集为例,令β∈[0,g(ai)-1],可用一个二元组描述β的等值信息,即:
[0229][0230]
同理,存在变换函数δ-1
(
·
),将二元组等值信息转换为等值的数值,即:
[0231][0232]
3)基于步骤2)中获得的结果,采用分布式语言评价算子daa可计算获得即:
[0233][0234]
其中,为一个语言评价二元组,代表语言评价变量的比例,其计算式如式(21)所示。
[0235][0236]
2.3用户对售电套餐的多粒度犹豫模糊语言评价信息的统一化
[0237]
考虑到用户负荷信息数据库中各用户的文化和知识背景的差异性,不同用户评价售电套餐时使用的语言评价集的粒度存在差异,即:用户对售电套餐的评价信息呈现出多粒度犹豫模糊特性。不失一般性,为了保证评价结果的准确性和公平性,需将不同粒度下的语言评价集转化为同一粒度下的语言评价集。假设需将基于粒度为g(ai)评价集的评价信息转化为基于粒度为g(af)评价集的评价信息具体步骤如下:
[0238]
1)令g(*)=lcm(g(ai)-1,g(af)-1)+1,其中,lcm(
·
)表述取最小公倍数;
[0239]
2)建立虚拟语言集
[0240]
令θe=0,e=0,1,
…
,g(*)-1;
[0241]
3)若zh=0,1,
…
,g(ai)-1,计算得:
[0242]
4)令zh=0,1,
…
,g(*)-1,若计算
[0243]
5)基于计算统一化后的语言评价变量比例,如式(22)所示:
[0244][0245]
6)基于式(22),得统一化后的语言评价信息
[0246]
基于步骤1)-6),可得统一粒度下用户对售电套餐的评价矩阵其中,表示统一粒度下用户ai对售电套餐tj的评价信息,以二元组的形式呈现,即:
[0247][0248]
为在af粒度下的语言评价,为新的评价隶属度,为新的评价程度
[0249]
3、基于用户满意度的售电套餐推荐与效果评价
[0250]
售电公司对售电套餐的推荐需考虑用户对售电套餐的满意度,满意度越高,推荐
成功的概率越大。首先计算历史用户信息数据库中用户对售电套餐的满意度,再结合目标用户与所属类用户的相似度,可得目标用户对售电套餐的满意度。
[0251]
基于获得的信息数据库中用户对售电套餐的评价信息(即步骤2.3中式(23)统一粒度下用户ai对售电套餐tj的评价信息),对用户的评价信息求期望,可得该数据库中用户对售电套餐的满意度矩阵其中,为用户ai对售电套餐tj的满意度,计算方法如式(24)所示。
[0252][0253]
目标用户对售电套餐的满意度取决于所属历史用户库中用户对售电套餐的满意度,以及目标用户与历史用户的相似度。以目标用户wn和所属的第p类历史用户为例,目标用户wn对售电套餐tj的满意度sc
nj
如式(25):
[0254][0255]
基于目标用户对各售电套餐满意度的计算结果,本文提出两种推荐方法:全排序推荐和top-m推荐,并分别通过均方根误差和交集比较评价售电套餐的推荐效果。
[0256]
(1)全排序推荐
[0257]
基于目标用户对各售电套餐的满意度结果,售电公司将对各售电套餐进行排序,将所有的售电套餐和相应的排序结果推荐给目标用户,供目标用户抉择。
[0258]
为了衡量所提全排序推荐方法的性能,基于排序结果,计算均方根误差。以目标用户wn为例,均方根误差ε
1n
,可用式(26)计算。
[0259][0260]
其中,j为售电套餐总数,o
nj
和分别表示针对目标用户wn、售电套餐tj的实际排序结果(即用户自己提供的排序结果)和算法所得的排序结果(即式(25)的排序结果)。均方根误差ε
1n
越小,所提售电套餐推荐算法的性能越好。
[0261]
(2)top-m推荐
[0262]
基于目标用户对各售电套餐的满意度结果,售电公司仅将排序为前m的套餐推荐
给目标用户,且不提供排序结果。
[0263]
为了衡量所提top-m推荐方法的性能,比较所提算法得到的前m个售电套餐的集合与实际排名为前m的套餐集合计算推荐准确度。以目标用户wn为例,准确度ε
2n
可用式(27)计算:
[0264][0265]
为目标用户wn实际排名为前m的套餐集合,为算法得到目标用户wn排名为前m的套餐集合,m为推荐的套餐总数。
[0266]
实验1:
[0267]
1、案例背景
[0268]
基于实施1所述的考虑多粒度犹豫模糊集和不完全权重的售电套餐推荐方法,以我国东部某大型园区为分析试点对象,该园区内用户包含居民、工业、商业等各类型用户,基于智能电表采集的2020/1/1~2020/1/31负荷数据,以700位用户a={a1,a2,
…
,a
700
}在该月份的共21700条负荷曲线数据为基础进行实施验证。其中,随机选取600位用户为历史用户,100位用户为目标用户。各用户平均每天的负荷频次分布直方图,如图3所示。售电公司为园区用户提供的售电套餐集为t={t1,t2,
…
,t
10
},如表1所示:
[0269]
表1售电公司为园区用户提供的售电套餐
[0270][0271]
在试点期间,售电公司对园区各用户进行了问卷调查,基于售电套餐评价属性集如表2所示:
[0272]
表2售电套餐评价属性集
[0273]
[0274][0275]
收集各用户基于自身语言评价集的用户售电套餐评价信息。据统计,园区内用户对售电套餐的语言评价集粒度可分为3、5、7、9,如式(28)~(31),各用户平均日负荷率、平均日峰谷差率与其对应的语言评价集粒度如图4所示。
[0276][0277][0278][0279][0280]
2、历史用户聚类分析
[0281]
基于式(1)~(7),计算园区内600位历史用户的负荷特性指标,并按照所提的改进k-means聚类算法对历史用户进行聚类,不同聚类数对应的聚类质量指标如图5所示。
[0282]
由图5知,当聚类数为5时,即:c*=5时,聚类质量指标值最大,聚类效果最好,聚类结果和各类用户的数量如图6所示,分别为晚高峰型、峰平型、避峰型、重工业型和双峰型。其中,晚高峰型以居民用电负荷为主,白天工作,晚上19:00左右下班回家的上班族;峰平型以办公用户、商业、写字楼等工作场所为主,早上9:00左右上班,晚上19:00~20:00左右下班的用户;避峰型针对酒吧、ktv、面包厂、交通照明等夜间场所或错峰用电用户;重工业型针对负荷一直维持在较高的水平的钢铁工业、冶金工业等;双峰型用户从早上持续用电,午饭后适度降低,以工作时间固定且规律的农业、纺织业等用户为主。
[0283]
然后,基于历史用户聚类结果,计算各目标用户特征指标相量与各聚类中心的距离,判定各目标用户所属类别,如图8所示。
[0284]
3、历史用户对售电套餐的评价
[0285]
以晚高峰型中的某一用户a1为例,其语言评价集为l5,该用户针对各售电套餐的属性,给出的评价矩阵为:
[0286][0287]
由可知,用户对售电套餐进行评价时表现出一定的犹豫模糊特性,评价信息呈现出亦此亦彼的状态,更能真实地反映用户的评价行为。
[0288]
结合评价矩阵与用户a1提供的售电套餐属性权重信息,如式(32),基于式(13),建立的离差最大化模型如式(33)所示。
[0289][0290][0291]
利用matlab的linprog(),得各属性的权重为
在此基础上对用户的评价信息进行集成,得用户a1对售电套餐的评价结果,如表3所示:
[0292]
表3用户a1基于自身语言评价集对售电套餐的评价结果
[0293][0294]
进一步地,将不同粒度下的语言评价信息转化为同一粒度下的评价信息。本文以l7作为统一化后的评价粒度,基于2.3节,得统一粒度下用户对售电套餐的评价结果,如表4所示:
[0295]
表4统一语言评价粒度下用户a1对售电套餐的评价结果
[0296][0297]
4、用户对售电套餐的满意度评价
[0298]
基于获得的统一粒度下用户a1对售电套餐的评价结果,对其求期望,得用户a1对各
售电套餐的满意度,如表5所示。
[0299]
表5用户a1对各售电套餐的满意度
[0300][0301]
同理可得其他历史用户对售电套餐的满意度评价结果,如图7所示,结合目标用户与所属类中历史用户的相似度,基于式(25),计算得到目标用户对各售电套餐的满意度。以属于晚高峰型的目标用户w1为例,其与晚高峰型的历史用户的相似度结果如图8所示,对各售电套餐的满意度量化结果如图9所示。
[0302]
由图7可知,针对同一售电套餐,晚高峰型中的不同历史用户的满意度评价结果存在差异,且相同历史用户对不同售电套餐的满意度也不同。由图8知,目标用户w1与晚高峰型历史用户的相似度均在97.5%以上,可见,实施例1提出的改进k-means聚类算法可有效地将具有相同负荷特性的用户归为一类。
[0303]
基于获得的历史用户满意度,和目标用户w1与历史用户的相似度,进一步获得目标用户w1对各售电套餐的满意度。由图9知,目标用户w1对售电套餐t7的满意度最大,为587.4434。而实际中,目标用户w1的用电时段主要集中在19:00-22:00,且其为低碳行动的倡导者,与售电套餐t7的属性相吻合。可见,所得结果与实际相一致,说明了所提用户满意度量化方法的正确性。
[0304]
5、售电套餐的推荐与性能评价
[0305]
基于目标用户对各售电套餐的满意度量化结果,可分别采用全排序推荐方法和top-m推荐方法对售电套餐进行推荐,其中,本文取m=5。仍然以目标用户w1为例,采用全排序推荐方法,售电公司提供给目标用户w1的售电套餐及排序结果如表6所示。各售电套餐的实际排序结果也列于表6。
[0306]
表6售电公司采用全排序推荐方法为目标用户w1推荐的结果
[0307][0308]
由表6知,本文所提方法所得售电套餐的排序结果与实际排序结果大部分一致,除售电套餐t9和t
10
的排序结果有差异外,其他排序结果均一致。由式(26)可计算得到均方根误差ε
11
=0.447。售电套餐t9和t
10
的排序结果有差异的原因在于两者在用电成本相当的情况下,用户w1更关注套餐的环保程度和增值服务类型,对于居民用户来说,其对家用设备的维护需求高于对设备的故障诊断预测需求,因此,其对售电套餐t
10
的满意度高于t9,说明实
施例1所提方法获得的排序结果符合实际。
[0309]
同理,采用top-5推荐方法,售电公司直接为用户w1推荐售电套餐集合由式(27)可计算得到推荐准确度ε
21
=100%。可见,实施例1的推荐方法的准确性。
[0310]
6、改进k-means聚类结果比较
[0311]
为了证明本文改进k-means聚类算法的有效性,对采集的园区用户负荷数据叠加5%的随机噪声,得到最佳聚类数(c*=5)下改进k-means聚类结果和聚类中心,如图10所示。并利用原始k-means聚类算法对叠加随机噪声后的负荷数据进行计算,得到各次计算结果的聚类中心,如图10。由图10可知,利用原始k-means聚类算法所得的结果受随机噪声的影响较大,除(a)(c)外,其他聚类中心均有所偏移,然而,采用本文的改进k-means聚类算法能有效降低噪声点的影响,较好地反映用户的负荷分布特征。
[0312]
为了进一步说明本文的改进k-means聚类算法对噪声的鲁棒性,分别对采集的用户负荷数据叠加不同比例的随机噪声,得到对应的最佳聚类数c*和聚类质量指标i
qc.av
,如图11所示。由图11知,当叠加的噪声比例小于30%时,改进k-means聚类算法得到的最佳聚类数均为5,而原始k-means聚类算法则在噪声比例达到10%时最佳聚类数就开始偏离。此外,随着叠加噪声比例的增加,两种聚类算法下对应的聚类质量指标均下降,但改进k-means聚类算法对应的聚类质量指标高于原始k-means聚类算法,且下降速度更缓慢。可见,实施例1的改进k-means聚类算法对噪声的鲁棒性较强。
[0313]
7、各类目标用户的售电套餐推荐排序结果比较
[0314]
利用实施例1所提售电套餐推荐方法,计算各类目标用户对售电套餐的满意度评价结果,如图12所示。由图12可知,对于同一类型的目标用户,各用户对售电套餐的满意度趋势相同,各售电套餐的排序结果近似一致。不同类型的目标用户对同一售电套餐的满意度差异较大。可见,实施例1所提售电套餐推荐方法能满足不同类型用户对售电套餐的需求。其中,以居民用电负荷为主的晚高峰型用户和以商业、写字楼为主的峰平型用户比较关注用电成本,因此,其对成本较低且奖励电量较多的售电套餐t7和t3更为满意。对于避峰型用户而言,其用电时间较其他用户更为特殊,为典型的错峰用户,比较关注售电套餐的峰谷时间设置,而售电套餐t9相较于t
10
电费更为节省,因此,其更青睐于售电套餐t9。此外,以钢铁、冶金工业为主的重工业型用户对电能质量扰动非常敏感,扰动造成的损失远大于电费成本,因此,其对电能质量增值服务的关注程度相比于售电套餐的其他属性更大,因此,其对售电套餐t4的满意度最大,符合实际。同理,以纺织业为主的双峰型用户生产设备对电压暂降很敏感,提高设备的免疫力能有效降低用户损失风险,因此,其对售电套餐t8的满意度较大。
[0315]
8、售电套餐推荐排序结果比较
[0316]
为了进一步证明实施例1实施例1所提售电套餐推荐方法的有效性,将各类目标用户的售电套餐实际排序结果与实施例1所提售电套餐推荐方法所得排序结果、仅考虑成本所得排序结果、利用原始k-means进行聚类所得排序结果、不聚类直接采用实施例1所提售电套餐推荐方法所得结果进行比较,分别计算全排序推荐和top-5推荐下各类目标用户的均方根误差平均值ε1和准确度平均值ε2,如图13所示。
[0317]
由图13可见,实施例1所提售电套餐推荐方法所得排序结果与实际排序结果相差
不大,虽有2~4个套餐排序有所差异,最大均方根误差为0.6325,但排序为前5的售电套餐与实际一致,准确度均达100%,由此说明了实施例1所提售电套餐推荐方法的准确性。
[0318]
与实际排序结果相比,仅考虑售电套餐成本的推荐结果的均方根误差较大,最大为4.8374,推荐准确度不高于60%,可见,用户对售电套餐的评价存在多样性,在成本相差不大的情况下,售电套餐包含的增值服务、奖励政策等也是用户的关注点。
[0319]
此外,若采用原始k-means聚类算法对历史用户进行聚类,由图10知,除晚高峰型用户和避峰型用户外,其他类型用户的聚类中心均有所偏移,如图13,晚高峰型用户和避峰型用户的均方根误差分别为0.4472和0.7746,准确度均为100%,而其他类型用户的均方根误差分别为1.7321,3.1623和0.8944,均高于实施例1所提售电套餐推荐方法所得结果的均方根误差,且推荐准确度分别为80%,60%和80%,均低于100%。而且,如果不考虑历史用户的聚类,直接根据目标用户与所有历史用户的相似度对售电套餐进行推荐,推荐结果对应的均方根误差较大,最小为1,最大为3.3466,推荐准确度不大于80%,推荐性能较差。
[0320]
综上,实施例1所提售电套餐推荐方法提出的改进k-means聚类算法对用户进行聚类,能更准确地将具有相似负荷特性的用户聚为一类,且考虑售电套餐多属性,以及用户评价信息的多粒度犹豫模糊特性和不完全权重信息的售电套餐推荐方法所得推荐结果的均方根误差较小,推荐准确度较高,推荐性能较好。
[0321]
最后,还需要注意的是,以上列举的仅是本发明的若干个具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1