一种多目标混合零空闲置换流水车间调度方法及系统
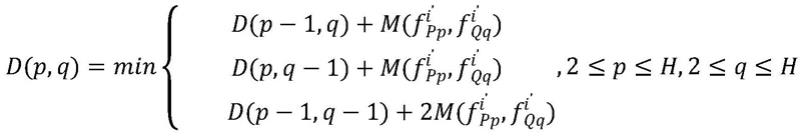
1.本发明属于流水车间调度领域,具体涉及一种基于动态时间规整距离的多目标混合零空闲置换流水车间调度方法及系统。
背景技术:
2.零空闲置换流水车间调度问题(no-idle permutation flow shop scheduling problem,npfsp)是一种遍布在电子电路生产行业、铸造领域等现代工业组合的问题,npfsp是在置换流水车间调度的基础上进一步加约束,它要求机器不停歇的加工,以减少贵重机器的磨损和维修。
3.由于不是所有机器都属于高耗能、贵重的机器,故引入了混合零空闲置换流水车间调度问题(mixedno-idle permutationflow shop scheduling problem,mnpfsp),它要求指定机器处于零空闲约束状态,其余机器处于正常运行状态。由于其自身问题复杂,如包含多个目标、多个约束,并具有np-hard特性,故随着研究问题规模的扩大,使其具有较大的研究价值。目前解决此类问题的方法主要有精确算法、启发式算法、智能优化算法,但大多实现效果不佳。因此,有必要开发一种新的方法来对混合零空闲置换流水车间调度进行优化。
技术实现要素:
4.本发明的目的在于提供一种多目标混合零空闲置换流水车间调度方法及系统,该方法及系统有利于优化混合零空闲置换流水车间调度,从而为工厂合理安排工件工序提供有效的调度方案。
5.为实现上述目的,本发明采用的技术方案是:一种多目标混合零空闲置换流水车间调度方法,包括以下步骤:
6.步骤s1:对多目标混合零空闲置换流水车间调度问题进行描述;
7.步骤s2:建立满足所述问题的约束条件;
8.步骤s3:建立实际生产过程中所期望的目标函数;
9.步骤s4:构建基于动态时间规整距离的群体智能算法;
10.步骤s5:依据动态时间规整距离完成迭代寻优,找出最优解的集合,得到最终的调度方案。
11.进一步地,所述步骤s1中,设n为总工件数量,m为总机器数量,u={u1,u2,
…
ui,
…
un},u表示工件的加工序列,ui为序列中位置位于i的工件,fh是第h个目标函数值,yj为受零空闲约束条件时工件ui在机器j上推后加工的总时间,属于零空闲状态的机器集合为
12.进一步地,所述步骤s2中,建立满足所述问题的约束条件如下:
13.开始加工的完工时间约束条件为:c
1,1
=t
1,1
;
14.机器1加工的约束条件:c
i,1
≥c
i-1,1
+t
i,1
,(i=2,
…
n);
15.工件u1加工的约束条件:c
1,j
≥c
1,j-1
+t
1,j
+y
j-1
,(j=2,
…
m);
16.其余工件和机器需满足的约束条件:
17.c
i,j
≥max{c
i,j-1
,c
i-1,j
+y
j-1
}+t
i,j
,(i=2,
…
n;j=2,
…
m);
18.零空闲约束:当j∈n时,c
i-1,j
=s
i,j
,(i=2,
…
n);
19.各机器延迟时间约束:y1=0,
[0020][0021]
其中,s
i,j
为工件ui在机器j上的开始加工时间,c
i,j
为工件ui在机器j上的完工时间,t
i,j
为工件ui在机器j上的加工时间,n为总工件数量,m为总机器数量,yj为受零空闲约束条件时工件ui在机器j上推后加工的总时间,属于零空闲状态的机器集合为
[0022]
进一步地,所述步骤s3中,设最大完工时间的目标函数f1,最大延期时间的目标函数f2,总库存成本的目标函数f3,总托期成本的目标函数f4:
[0023]
f1=c
n,m
;
[0024]
f2=max{max(0,c
i,m-di)},i=1,2
…
n;
[0025][0026][0027]
式中,c
n,m
为工件un在机器m上的完工时间,即最大完工时间;c
i,m
为工件ui在机器m上的完工时间,di为工件ui的要求交货时间,αi为工件ui单位时间内的存放费用,li为工件ui的实际交货时间,εi为工件ui单位时间内的延时费用。
[0028]
进一步地,所述步骤s4包括以下步骤:
[0029]
步骤s41:定义所研究问题参数;
[0030]
步骤s42:对群体智能算法中个体进行编码;
[0031]
步骤s43:构建基于动态时间规整的距离表达;
[0032]
步骤s44:以动态时间规整距离的倒数作为群体智能算法中个体的适应度值,依据适应度值选择策略开展算法中个体的选择操作。
[0033]
进一步地,所述步骤s41中,定义gen为此时的迭代数,maxgen为总的迭代次数,popsize为种群大小,pcross为交叉概率,pmutation为变异概率,ω、ε、δ都为区间[0,1]内的随机数,第r个个体的第v位基因为b
rv
,b
max
为基因b
rv
的上界,即为工件总数n;b
min
为基因b
rv
的下界,其值为1;
[0034]
所述步骤s42中,个体编码采用整数编码,具体为先随机产生一个长度为工件数的数组,再将其按照大小排序得出一个符合研究问题的排列数组,个体总数为种群数目。
[0035]
进一步地,所述步骤s43包括以下步骤:
[0036]
步骤s431:计算种群迭代第i次的不同个体的目标函数值为选出所有个体中各个目标函数的最大值,记为选出所有个体中各个目标函数的最小值,记为
[0037]
步骤s432:通过min-max标准化将不同量纲的目标函数值落在[0,1]区间,标准化方法如下:
[0038][0039]
其中,i表示种群迭代第i次,为个体标准化后的第h个目标函数标准化值,表示个体的第h个目标函数值,表示种群中第h个目标函数的最小函数值,表示种群中第h个目标函数的最大函数值;
[0040]
步骤s433:计算动态时间规整距离,将其倒数作为群体智能算法中个体的适应度值,建立依据适应度值的个体选择策略,把种群中各个体的动态时间规整距离的倒数按照大小排序,最大的值即为种群中与理想解目标函数值相似度最高的最优解,此处理想解目标函数值为单目标优化时各目标函数的最小值。
[0041]
进一步地,所述步骤s433中,计算动态时间规整距离具体包括以下步骤:
[0042]
步骤s4331:假设任意一个个体的函数目标值min-max标准化后序列和种群个体中各个目标函数的最小值min-max标准化后序列分别为max标准化后序列分别为将其构成一个h
×
h型式矩阵mhd,即距离矩阵:
[0043][0044]
矩阵中的元素代表和之间的曼哈顿距离;
[0045]
其中,i代表种群迭代第i次,为个体标准化后的第h个目标函数值,为种群个体中第h个目标函数的最小值标准化后的值,m表示曼哈顿距离,其计算公式为:
[0046][0047]
步骤s4332:所述矩阵mhd中,各元素的连续集形成多条路径,该路径为规整后的路径,用w表示:w=(w1,w2…
,wk),h≤k≤2h-1;
[0048]
规整路径w符合如下约束条件:
[0049]
(1)边界条件:规整路径从矩阵mhd左下角的开始,对应坐标点w1=(1,1),到右上角的结束,对应坐标点wk=(h,h);
[0050]
(2)连续性:若此时坐标为(p,q),则行至下一个坐标点(p
′
,q
′
)需要满足的条件为p
′‑
p≤1,q
′‑
q≤1,相当于不能跳过某个点,只能行至紧临的点;
[0051]
(3)单调性:满足p
′‑
p≥0,q
′‑
q≥0,即要求w是单调的;
[0052]
步骤s4333:满足条件的规整路径有很多条,其中规整代价最小的路径为:
[0053][0054]
式中,k为经过点的个数,wk′
为坐标点wk在矩阵mhd中所对应的值,选择一条路径使得最后得到的总距离最小,该总距离衡量着两序列的相似度,其值越小相似度越高;
[0055]
计算累计距离d,累计距离计算方式为从距离矩阵mhd的左下角累加至右上角,将其经过点的距离累加起来得到累计距离d,计算公式为:
[0056][0057]
其中,d(p-1,q)代表行驶至(p-1,q)点时的累计距离,d(p,q-1)代表行驶至(p,q-1)点时的累计距离,d(p-1,q-1)代表行驶至(p-1,q-1)点时的累计距离;初始条件通过迭代最终求出累计距离d(h,h),此距离即上述所说的总距离,累计距离d(h,h)即为动态时间规整距离dtw(p,q),所经过的路径也是规整代价最小的路径。
[0058]
进一步地,所述步骤s44包括以下步骤:
[0059]
步骤s441:种群初始化,随机产生大小为popsize的种群,迭代次数i=1,开始迭代;
[0060]
步骤s442:求解出种群的各个目标函数值;
[0061]
步骤s443:计算适应度值,采用动态时间规整距离作为个体选择策略,动态时间规整距离的倒数即为适应度值大小;
[0062]
步骤s444:更新外部档案,当有两个及以上目标函数值优于父代种群目标函数值时,则保存下来,最后再将相同个体去掉;
[0063]
步骤s445:采用二元锦标赛法进行选择操作,从父代种群中每次随机选择两个个体,个体被选择的概率是相同的,根据每个个体的适应度值来确定选择的个体,适应度值大的被选择下来进入到子代种群,重复多次,直到子代种群规模达到父代种群规模的大小;
[0064]
步骤s446:进行交叉操作,从种群中随机选择两个个体,通过个体的交换组合,将旧的个体好的方面遗传给新的个体,从而产生新的优异个体;先采用实数交叉法进行交叉,再将交叉后的个体基因按从小到大的顺序排序;其中第x个个体和第y个个体在z位置上的交叉方式为:
[0065]bxz
=b
xz
(1-ω)+b
yz
ω;
[0066]byz
=b
yz
(1-ω)+b
xz
ω;
[0067]
式中,b
xz
为第x个个体的第z位基因,b
yz
为第y个个体的第z位基因,ω为区间[0,1]内的随机数;
[0068]
步骤s447:进行变异操作,从种群中随机选择一个个体,先选择个体中的任意一点进行变异,再将变异后的基因按照从小到大的顺序排序;其中第r个个体在v位置上的变异方式为:
[0069][0070]
式中,b
rv
为第r个个体的第v位基因,b
max
为基因b
rv
的上界,即为工件总数n;b
min
为基因b
rv
的下界,其值为1;f(g)=δ(1-gen/maxgen)2,ε、δ都为区间[0,1]内的随机数,gen为此时的迭代数,maxgen为总的迭代次数;
[0071]
步骤s448:当i<maxgen时,i=i+1,跳到s443步骤,否则跳出循环,算法停止。
[0072]
本发明还提供了一种多目标混合零空闲置换流水车间调度系统,包括存储器、处理器以及存储于存储器上并能够被处理器运行的计算机程序指令,当处理器运行该计算机程序指令时,能够实现上述的方法步骤。
[0073]
与现有技术相比,本发明具有以下有益效果:本发明结合工厂生产可能碰到的约束条件,以工厂高度关注的最大完工时间、最大延期时间、总库存成本、总托期成本作为优化目标,提供了一种基于动态时间规整距离的多目标混合零空闲置换流水车间调度方法,该方法可以快速精准的寻找到目标值,并改善搜索性能,从而优化混合零空闲置换流水车间调度,为工厂合理安排工件工序提供有效的调度方案。
附图说明
[0074]
图1是本发明实施例的实现流程图。
具体实施方式
[0075]
下面结合附图及实施例对本发明做进一步说明。
[0076]
应该指出,以下详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
[0077]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0078]
如图1所示,本实施例提供了一种多目标混合零空闲置换流水车间调度方法,包括以下步骤:
[0079]
步骤s1:对多目标混合零空闲置换流水车间调度问题进行描述。
[0080]
所述步骤s1中,设n为总工件数量,m为总机器数量,u={u1,u2,
…
ui,
…
un},u代表工件的加工序列,ui为序列中位置位于i的工件,c
i,j
表示工件ui在机器j上的完成加工时间,s
i,j
(i=1,2,
…
,n,j=1,2,
…
,m)表示工件ui在机器j上的开始加工时间,fh是第h个目标函数值,f=(f1,f2,
…fh
)
t
代表目标向量,t
i,j
为工件ui在机器j上的加工时间,di为工件ui的要求交货时间,li为工件ui的实际交货时间,αi为工件ui单位时间内的存放费用,εi为工件ui单位时间内的延时费用,w
p
为第p批的实际输送量,h为单个批次的最大输送量,b为输送次数,yj为受零空闲约束条件时工件ui在机器j上推后加工的总时间,属于零空闲状态的机器集合为
[0081]
步骤s2:建立满足所述问题的约束条件。
[0082]
所述步骤s2中,建立满足所述问题的约束条件如下:
[0083]
开始加工的完工时间约束条件为:c
1,1
=t
1,1
;
[0084]
机器1加工的约束条件:c
i,1
≥c
i-1,1
+t
i,1
,(i=2,
…
n);
[0085]
工件u1加工的约束条件:c
1,j
≥c
1,j-1
+t
1,j
+y
j-1
,(j=2,
…
m);
[0086]
其余工件和机器需满足的约束条件:
[0087]ci,j
≥max{c
i,j-1
,c
i-1,j
+y
j-1
}+t
i,j
,(i=2,
…
n;j=2,
…
m);
[0088]
零空闲约束:当j∈n时,c
i-1,j
=s
i,j
,(i=2,
…
n);
[0089]
各机器延迟时间约束:y1=0,
[0090][0091]
输送量约束条件:w
p
≤h,p=1,2,
…
b;
[0092]
其中,s
i,j
为工件ui在机器j上的开始加工时间,c
i,j
为工件ui在机器j上的完工时间,t
i,j
为工件ui在机器j上的加工时间,n为总工件数量,m为总机器数量,yj为受零空闲约束条件时工件ui在机器j上推后加工的总时间,属于零空闲状态的机器集合为
[0093]
步骤s3:建立实际生产过程中所期望的目标函数。
[0094]
所述步骤s3中,设最大完工时间的目标函数f1,最大延期时间的目标函数f2,总库存成本的目标函数f3,总托期成本的目标函数f4:
[0095]
f1=c
n,m
;
[0096]
f2=max{max(0,c
i,m-di)},i=1,2
…
n;
[0097][0098][0099]
式中,c
n,m
为工件un在机器m上的完工时间,即最大完工时间;c
i,m
为工件ui在机器m上的完工时间,di为工件ui的要求交货时间,αi为工件ui单位时间内的存放费用,li为工件ui的实际交货时间,εi为工件ui单位时间内的延时费用。
[0100]
步骤s4:构建基于动态时间规整距离的群体智能算法。
[0101]
所述步骤s4包括以下步骤:
[0102]
步骤s41:定义所研究问题参数。
[0103]
所述步骤s41中,定义gen为此时的迭代数,maxgen为总的迭代次数,popsize为种群大小,pcross为交叉概率,pmutation为变异概率,ω、ε、δ都为区间[0,1]内的随机数,第r个个体的第v位基因为b
rv
,b
max
为基因brv的上界,即为工件总数n;b
min
为基因b
rv
的下界,其值为1。
[0104]
步骤s42:对群体智能算法中个体进行编码。
[0105]
所述步骤s42中,个体编码采用整数编码,具体为先随机产生一个长度为工件数的数组,再将其按照大小排序得出一个符合研究问题的排列数组,个体总数为种群数目。
[0106]
步骤s43:构建基于动态时间规整的距离表达。
[0107]
所述步骤s43包括以下步骤:
[0108]
步骤s431:计算种群迭代第i次的不同个体的目标函数值为选出所有个体中各个目标函数的最大值,记为选出所有个体中各个目标函数的最小值,记为
[0109]
步骤s432:通过min-max标准化将不同量纲的目标函数值落在[0,1]区间,标准化方法如下:
[0110][0111]
其中,i表示种群迭代第i次,为个体标准化后的第h个目标函数标准化值,表示个体的第h个目标函数值,表示种群中第h个目标函数的最小函数值,表示种群中第h个目标函数的最大函数值。
[0112]
步骤s433:计算动态时间规整距离,将其倒数作为群体智能算法中个体的适应度值,建立依据适应度值的个体选择策略,把种群中各个体的动态时间规整距离的倒数按照大小排序,最大的值即为种群中与理想解目标函数值相似度最高的最优解,此处理想解目标函数值为单目标优化时各目标函数的最小值。
[0113]
所述步骤s433中,计算动态时间规整距离具体包括以下步骤:
[0114]
步骤s4331:假设任意一个个体的函数目标值min-max标准化后序列和种群个体中各个目标函数的最小值min-max标准化后序列分别为max标准化后序列分别为将其构成一个h
×
h型式矩阵mhd,即距离矩阵:
[0115][0116]
矩阵中的元素代表和之间的曼哈顿距离;
[0117]
其中,i代表种群迭代第i次,为个体标准化后的第h个目标函数值,为种群个体中第h个目标函数的最小值标准化后的值,m表示曼哈顿距离,其计算公式为:
[0118][0119]
步骤s4332:所述矩阵mhd中,各元素的连续集可以形成多条路径,该路径为规整后的路径,通常用w表示:w=(w1,w2…
,wk),h≤k≤2h-1,例:路径w={(1,1),(2,2),(2,3),(3,3),(4,4)}。
[0120]
规整路径w需要符合如下约束条件:
[0121]
(1)边界条件:规整路径从矩阵mhd左下角的开始,对应坐标点w1=(1,1),到右上角的结束,对应坐标点wk=(h,h);
[0122]
(2)连续性:若此时坐标为(p,q),则行至下一个坐标点(p
′
,q
′
)需要满足的条件为p
′‑
p≤1,q
′‑
q≤1,相当于不能跳过某个点,只能行至紧临的点;
[0123]
(3)单调性:除了满足连续性所要求的条件外,还需要满足p
′‑
p≥0,q
′‑
q≥0,即要求w是单调的。
[0124]
步骤s4333:满足条件的规整路径有很多条,其中规整代价最小的路径为:
[0125][0126]
式中,k为经过点的个数,wk′
为坐标点wk在矩阵mhd中所对应的值,选择一条路径使得最后得到的总距离最小,该总距离衡量着两序列的相似度,其值越小相似度越高。
[0127]
计算累计距离d,累计距离计算方式为从距离矩阵mhd的左下角累加至右上角,将其经过点的距离累加起来得到累计距离d,计算公式为:
[0128]
[0129]
其中,d(p-1,q)代表行驶至(p-1,q)点时的累计距离,d(p,q-1)代表行驶至(p,q-1)点时的累计距离,d(p-1,q-1)代表行驶至(p-1,q-1)点时的累计距离;初始条件通过迭代最终可以求出累计距离d(h,h),此距离即上述所说的总距离,累计距离d(h,h)即为动态时间规整距离dtw(p,q),所经过的路径也是规整代价最小的路径。
[0130]
步骤s44:以动态时间规整距离的倒数作为群体智能算法中个体的适应度值,依据适应度值选择策略开展算法中个体的选择操作。
[0131]
所述步骤s44包括以下步骤:
[0132]
步骤s441:种群初始化,随机产生大小为popsize的种群,迭代次数i=1,开始迭代。
[0133]
步骤s442:求解出种群的各个目标函数值。
[0134]
步骤s443:计算适应度值,采用动态时间规整距离作为个体选择策略,动态时间规整距离的倒数即为适应度值大小。
[0135]
步骤s444:更新外部档案,当有两个及以上目标函数值优于父代种群目标函数值时,则保存下来,最后再将相同个体去掉。
[0136]
步骤s445:采用二元锦标赛法进行选择操作,从父代种群中每次随机选择两个个体,个体被选择的概率是相同的,根据每个个体的适应度值来确定选择的个体,适应度值大的被选择下来进入到子代种群,重复多次,直到子代种群规模达到父代种群规模的大小。
[0137]
步骤s446:进行交叉操作,从种群中随机选择两个个体,通过个体的交换组合,将旧的个体好的方面遗传给新的个体,从而产生新的优异个体;先采用实数交叉法进行交叉,再将交叉后的个体基因按从小到大的顺序排序;其中第x个个体和第y个个体在z位置上的交叉方式为:
[0138]bxz
=b
xz
(1-ω)+b
yz
ω;
[0139]byz
=b
yz
(1-ω)+b
xz
ω;
[0140]
式中,b
xz
为第x个个体的第z位基因,b
yz
为第y个个体的第z位基因,ω为区间[0,1]内的随机数。
[0141]
步骤s447:进行变异操作,从种群中随机选择一个个体,先选择个体中的任意一点进行变异,再将变异后的基因按照从小到大的顺序排序;其中第r个个体在v位置上的变异方式为:
[0142][0143]
式中,b
rv
为第r个个体的第v位基因,b
max
为基因b
rv
的上界,即为工件总数n;b
min
为基因b
rv
的下界,其值为1;f(g)=δ(1-gen/maxgen)2,ε、δ都为区间[0,1]内的随机数,gen为此时的迭代数,maxgen为总的迭代次数。
[0144]
步骤s448:当i<maxgen时,i=i+1,跳到s443步骤,否则跳出循环,算法停止。
[0145]
步骤s5:依据动态时间规整距离完成迭代寻优,找出最优解的集合,得到最终的调度方案。
[0146]
本实施例还提供了一种多目标混合零空闲置换流水车间调度系统,包括存储器、处理器以及存储于存储器上并能够被处理器运行的计算机程序指令,当处理器运行该计算
机程序指令时,能够实现上述的方法步骤。
[0147]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0148]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0149]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0150]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0151]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1