一种基于GAN聚类的文本清洗方法及系统与流程
一种基于gan聚类的文本清洗方法及系统
技术领域
1.本发明涉及文本数据挖掘领域,尤其涉及一种基于gan聚类的文本清洗方法及系统。
背景技术:
2.在文本数据挖掘的应用场景中,数据爬取和清洗是第一步,目前大多采用编写清洗规则,或整理大量正样本和负样本,训练文本分类器将噪声数据区分开来达到清洗的目的,清洗规则的编写需要大量的人工观察、总结并持续投入和优化,当规则数量逐渐增加还会带来规则冲突的情况,需要建立规则引擎对规则进行管理,对于自然语言的多样性较难处理,而训练文本分类器需要人工采集大量正负样本,同样成本较大,对于多变的各种需求不同的场景,需要重复采集标注。
技术实现要素:
3.本发明目的在于针对现有技术的不足,提出一种利用无监督的聚类方法进行数据清洗的方法及系统。本发明结合gan对抗训练方法,对文本进行聚类,进而辅助文本清洗工作,训练过程不需要文本类型标签,标签只用于对聚类结果的测试。
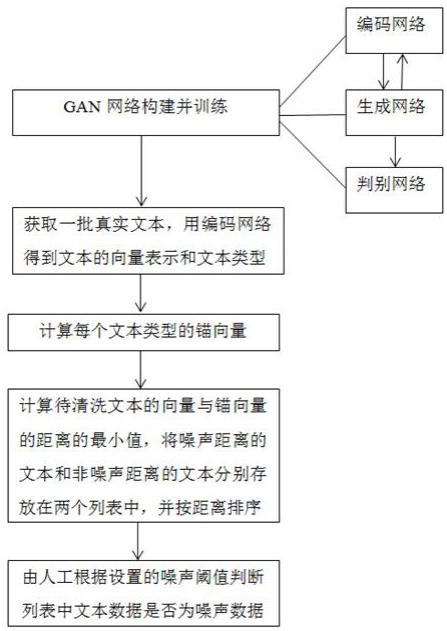
4.本发明的目的是通过以下技术方案来实现的:一种基于gan聚类的文本清洗方法,该方法包括以下步骤:(1)构建包含一个生成网络、一个编码网络和一个判别网络的gan网络结构并训练,其中生成网络输入由一个隐变量和一个长度为n_c的onehot向量组成,其中n_c为预定义的文本类型数;生成网络输出为固定长度的生成文本;编码网络输入为真实文本或生成网络的生成文本,输出为一个隐变量和一个长度为n_c的文本类型分布向量,文本类型分布向量用softmax得到onehot向量;判别网络的输入为真实文本或生成网络的生成文本,输出为数值,表示是否为真实文本的概率;(2)对文本聚类分析并清洗,具体如下:(2.1)对一批真实文本,用编码网络得到其隐变量和文本类型分布向量,并将文本类型分布向量变换为onehot向量,由onehot向量得到文本类型;(2.2)将隐变量与文本类型分布向量拼接后的向量作为文本的向量表示,得到一批真实文本中每个文本类型下的全部文本的向量,并取平均值作为该文本类型的锚向量;(2.3)对于待清洗的文本,计算该文本的向量表示,并计算该向量与各文本类型的锚向量的距离,若各文本类型中包含噪声类型,则选取计算的最小距离,将最小距离为噪声距离、最小距离为非噪声距离的文本分别存放在两个列表中,并按距离排序;若各文本类型中不包含噪声类型,则用待清洗文本的向量与各文本类型锚向量的距离最小值表示噪声度,存放在一个列表中,并按距离排序;(2.4)对于步骤(2.3)得到的列表中的文本数据,由人工根据设置的噪声阈值判断每一条文本数据是否为噪声数据。
5.进一步地,步骤(1)中,所述隐变量是长度为dim_latent的浮点数向量;所述生成网络的输入为长度为dim_latent+n_c的向量,由一个长度为dim_latent的浮点数向量和一个长度n_c的onehot向量拼接而成。
6.进一步地,步骤(1)中,所述文本类型根据实际的文本分类任务进行定义,包含噪声类型文本和非噪声类型文本,或者仅包含非噪声类型文本。
7.进一步地,生成网络由embedding层、多个lstm层以及多个全连接层组成。
8.进一步地,判别网络和编码网络均由embedding层、卷积层或lstm层以及全连接层组成。
9.进一步地,步骤(1)中对gan网络的训练过程具体如下:a. 采样隐变量:随机取编码网络输出的长度为dim_latent的浮点数向量,随机选取文本类别序号zc_idx并转为onehot向量;b. 计算损失函数,具体包括:真实文本判别损失:向编码网络中输入一批数量为n的真实文本,得到n组隐变量,并输入生成网络产生n个生成文本,将真实文本和生成文本输入判别网络,真实文本输入判别网络得到输入为真实文本的概率d_real和生成文本输入判别网络得到输入为真实文本的概率d_gen;梯度惩罚损失:对一批真实文本和生成文本,插值得到一批新文本,用判别网络得到梯度向量,用梯度向量的l2模作为梯度惩罚损失;隐变量重建损失:将生成文本输入编码网络,得到隐变量和文本类型分布向量,对该隐变量与用于产生生成文本的隐变量计算mse损失,用该文本类型分布向量与用于产生生成文本的onehot向量计算交叉熵损失;文本重建损失:用真实文本得到的隐变量和onehot向量,输入生成网络得到生成文本,对真实文本和生成文本计算mse损失;聚类损失:以真实文本的隐变量通过kmeans无监督聚类方法计算聚类损失;计算各损失函数时经过的网络由对应的损失函数值通过反向传播调节,其中真实样本判别损失、梯度惩罚损失用于调节生成网络和判别网络,隐变量重建损失、文本重建损失用于调节生成网络和编码网络,聚类损失用于调节编码网络。
10.进一步地,计算真实文本判别损失时,如果有标注的文本,能够增加对真实文本具体类型的判断,此时判别网络的输出表示文本为各种类型文本或生成文本的概率。
11.本发明还提供了一种基于gan聚类的文本清洗系统,该系统包括gan网络模块、锚向量计算模块和文本清洗模块:所述gan网络模块由一个生成网络模块、一个编码网络模块和一个判别网络模块构成,所述生成网络模块的输入由一个隐变量和一个长度为n_c的onehot向量组成,其中n_c为预定义的文本类型数;生成网络模块的输出为固定长度的生成文本;所述编码网络模块的输入为真实文本或生成网络模块输出的生成文本,输出为一个隐变量和一个长度为n_c的文本类型分布向量,所述文本类型分布向量用softmax得到onehot向量,由onehot向量得到文本类型;所述判别网络模块的输入为真实文本或生成网络模块输出的生成文本,输出为数
值,表示是否为真实文本的概率;所述编码网络模块输出的隐变量与文本类型分布向量拼接后的向量作为文本的向量表示,每个文本类型下的全部文本的向量输入至锚向量计算模块,取全部文本的向量平均值作为输入的文本类型的锚向量;所述文本清洗模块输入为通过编码网络模块得到的文本的向量表示和锚向量计算模块得到的各文本类型的锚向量,计算文本的向量表示与各文本类型的锚向量的距离,若各文本类型中包含噪声类型,则选取计算的最小距离,将最小距离为噪声距离、最小距离为非噪声距离的文本分别存放在两个列表中,并按距离排序;若各文本类型中不包含噪声类型,则用输入文本的向量与各文本类型锚向量的距离最小值表示噪声度,存放在一个列表中,并按距离排序;最后对于得到的列表中的文本数据,由人工根据设置的噪声阈值输出每一条文本数据是否为噪声数据的结果。
12.进一步地,所述编码网络模块输出的隐变量是长度为dim_latent的浮点数向量;所述生成网络模块的输入为长度为dim_latent+n_c的向量,由一个长度为dim_latent的浮点数向量和一个长度n_c的onehot向量拼接而成。
13.进一步地,该系统还包含隐变量采集模块和损失函数计算模块,用于gan网络模块的训练;所述隐变量采集模块随机取编码网络模块输出的长度为dim_latent的浮点数向量,随机选取文本类别序号zc_idx并转为onehot向量;所述损失函数计算模块,具体计算如下的损失函数:真实文本判别损失:向编码网络模块中输入一批数量为n的真实文本,得到n组隐变量,并输入生成网络模块产生n个生成文本,将真实文本和生成文本输入判别网络模块,真实文本输入判别网络模块得到输入为真实文本的概率d_real和生成文本输入判别网络模块得到输入为真实文本的概率d_gen;梯度惩罚损失:对一批真实文本和生成文本,插值得到一批新文本,用判别网络模块得到梯度向量,用梯度向量的l2模作为梯度惩罚损失;隐变量重建损失:将生成文本输入编码网络模块,得到隐变量和文本类型分布向量,对该隐变量与用于产生生成文本的隐变量计算mse损失,用该文本类型分布向量与用于产生生成文本的onehot向量计算交叉熵损失;文本重建损失:用真实文本得到的隐变量和onehot向量,输入生成网络模块得到生成文本,对真实文本和生成文本计算mse损失;聚类损失:以真实文本的隐变量通过kmeans无监督聚类方法计算聚类损失;计算各损失函数时经过的网络由对应的损失函数值通过反向传播调节,其中真实样本判别损失、梯度惩罚损失用于调节生成网络和判别网络,隐变量重建损失、文本重建损失用于调节生成网络和编码网络,聚类损失用于调节编码网络。
14.本发明的有益效果:利用gan的对抗训练方法,在各种损失的辅助下,得到可靠的文本向量表示,用于文本类型锚向量的计算,甚至在没有任何标注的情形下也可以得到锚向量,用与锚向量的距离来度量文本的噪声程度,基于此对文本分类或噪声度排序,可无监督地实现对文本的高效清洗。
附图说明
15.图1为本发明文本清洗方法流程示意图;图2为本发明文本清洗系统结构示意图。
具体实施方式
16.以下结合附图对本发明具体实施方式作进一步详细说明。
17.如图1所示,本发明提供的一种基于gan聚类的文本清洗方法,具体过程如下:一.训练gan网络:1.1 网络结构:包含一个生成网络,一个编码网络,一个判别网络。
18.生成网络输入为长度为dim_latent+n_c的向量,由一个长度为dim_latent的浮点数向量(隐变量)和一个长度n_c的onehot向量组成,n_c为预定义的文本类别数,文本类型根据实际的文本分类任务进行定义,包含噪声类型文本和非噪声类型文本,或者仅包含非噪声类型文本;输出为固定长度的生成文本,生成网络可以由embedding层、多个lstm层、多个全连接层组成。
19.编码网络输入为文本(真实文本或生成网络输出的生成文本),输出为dim_latent+n_c的向量,分为一个长度为dim_latent的浮点数向量(隐变量)和一个长度为n_c的文本类型分布向量,文本类型分布向量用softmax得到onehot向量,可以由embedding层、卷积层或lstm层、全连接层组成,文本类型分布向量的含义为:文本的类型分布是概率分布,假如有3个文本类型,文本的类型分布向量可能是[0.7, 0.3, 0.1],这时就是认为这个文本类型是第1类。
[0020]
判别网络输入为文本(真实文本或生成文本),输出为数值,表示是否为真实文本的概率,编码网络和判别网络可共享输出层以外的网络层,或共享全部网络层,当共享输出层以外的网络层时,输出层的输出维度不同,当共享全部网络层时,此时文本输出类别由onehot向量得到,并且要求文本输出类别数量与onehot向量定义的类别数量一致。
[0021]
1.2 训练:a. 采样隐变量:随机取编码网络输出的长度为dim_latent的浮点数向量,随机选取文本类别序号zc_idx并转为onehot向量。
[0022]
b. 计算损失函数:真实文本判别损失:向编码网络中输入一批数量为n的真实文本,得到n组隐变量,并输入生成网络产生n个生成文本,将真实文本和生成文本输入判别网络,得到为真实文本的概率,d_real和d_gen,其中d_real为真实文本输入判别网络得到输入为真实文本的概率,d_gen为生成文本输入判别网络得到输入为真实文本的概率。
[0023]
可选的,假如有标注的文本,可增加对真实文本具体类型的判断,此时判别网络的输出表示文本为各种类型文本或生成文本的概率。
[0024]
梯度惩罚损失:对一批真实文本和生成文本,插值得到一批新文本,用判别网络得到梯度向量,用梯度向量的l2模作为梯度惩罚损失。
[0025]
隐变量重建损失:将生成文本输入编码网络,得到隐变量和文本类型分布向量,对该隐变量与用于产生生成文本的文本隐变量计算mse损失,用该文本类型分布向量与用于产生生成文本的onehot向量计算交叉熵损失。
[0026]
文本重建损失:用真实文本得到的隐变量和onehot向量,输入生成网络得到生成文本,对真实文本和生成文本计算mse损失。
[0027]
聚类损失:对于真实文本的隐变量,用kmeans等无监督聚类方法计算聚类损失。
[0028]
计算各损失函数时经过的网络由对应的损失函数值通过反向传播调节,其中真实样本判别损失、梯度惩罚损失用于调节生成网络和判别网络,隐变量重建损失、文本重建损失用于调节生成网络和编码网络,聚类损失用于调节编码网络。
[0029]
可选的,对计算量较大的隐变量重建损失、文本重建损失、聚类损失隔m次计算一次。
[0030]
二.对文本聚类分析并清洗:对一批真实文本,用编码网络得到其隐变量和文本类型分布向量,并将文本类型分布向量变换为onehot向量,由onehot向量得到其类型。
[0031]
可选的,得到隐变量+softmax变换前的文本类型分布向量,即将隐变量与文本类型分布向量进行拼接,作为该文本的向量表示,得到一批真实文本中每个文本类型下的全部文本的向量,取平均值作为该文本类型的锚向量。对待清洗的文本,计算该文本的向量表示,计算该向量与各类型的锚向量的距离,如l2距离,如果与噪声类型的距离最小,则认为该文本越接近噪声,若各文本类型中包含噪声类型,则取计算的最小距离,将最小距离为噪声距离和最小距离为非噪声距离的文本分别存放在两个列表中,按其距离排序,其中,噪声距离指的是待清洗的文本向量与噪声文本类型的锚向量的距离,非噪声距离指的是待清洗的文本向量与非噪声文本类型的锚向量的距离,若各文本类型中不包含噪声类型,则用待清洗文本的向量与各文本类型锚向量的距离最小值表示噪声度,存放在一个列表中,并按距离排序;对于得到的列表交给人工判断,此时人工可对每个列表分别得到一个噪声阈值,大于阈值的为噪声文本,或人工判断每一条数据是否噪声,由于大部分噪声都分布在距离大的位置,将其中极少量的非噪声数据进行人工召回后,可进一步提升清洗的质量。
[0032]
本发明还提供了一种基于gan聚类的文本清洗系统,如图2所示,该系统包括gan网络模块、锚向量计算模块和文本清洗模块:所述gan网络模块由一个生成网络模块、一个编码网络模块和一个判别网络模块构成,所述生成网络模块的输入为长度为dim_latent+n_c的向量,由一个长度为dim_latent的浮点数向量和一个长度n_c的onehot向量拼接而成,其中n_c为预定义的文本类型数;生成网络模块的输出为固定长度的文本;所述编码网络模块的输入为真实文本或生成网络模块输出的生成文本,输出为一个隐变量和一个长度n_c的文本类型分布向量,所述隐变量是长度为dim_latent的浮点数向量;所述文本类型分布向量用softmax得到onehot向量,由onehot向量得到文本类型;所述判别网络模块的输入为真实文本或生成网络模块输出的生成文本,输出为数值,表示是否为真实文本的概率;所述编码网络模块输出的隐变量+文本类型分布向量(将隐变量与文本类型分布向量进行拼接)作为文本的向量表示,每个文本类型下的全部文本的向量输入至锚向量计算模块,取全部文本的向量平均值作为输入的文本类型的锚向量;所述文本清洗模块输入为通过编码网络模块得到的文本的向量表示和锚向量计
算模块得到的各文本类型的锚向量,计算文本的向量表示与各文本类型的锚向量的距离,若各文本类型中包含噪声类型,则选取计算的最小距离,将最小距离为噪声距离、最小距离为非噪声距离的文本分别存放在两个列表中,并按距离排序;若各文本类型中不包含噪声类型,则用输入文本的向量与各文本类型锚向量的距离最小值表示噪声度,存放在一个列表中,并按距离排序;最后对于得到的列表中的文本数据,由人工根据设置的噪声阈值输出每一条文本数据是否为噪声数据的结果。
[0033]
文本清洗系统还包含隐变量采集模块和损失函数计算模块,用于gan网络模块的训练;所述隐变量采集模块随机取编码网络模块输出的长度为dim_latent的浮点数向量,随机选取文本类别序号zc_idx并转为onehot向量;所述损失函数计算模块,具体计算如下的损失函数:真实文本判别损失:向编码网络模块中输入一批数量为n的真实文本,得到n组隐变量,并输入生成网络模块产生n个生成文本,将真实文本和生成文本输入判别网络模块,真实文本输入判别网络模块得到输入为真实文本的概率d_real和生成文本输入判别网络模块得到输入为真实文本的概率d_gen;梯度惩罚损失:对一批真实文本和生成文本,插值得到一批新文本,用判别网络模块得到梯度向量,用梯度向量的l2模作为梯度惩罚损失;隐变量重建损失:将生成文本输入编码网络模块,得到隐变量和文本类型分布向量,对该隐变量与用于产生生成文本的隐变量计算mse损失,用该文本类型分布向量与用于产生生成文本的onehot向量计算交叉熵损失;文本重建损失:用真实文本得到的隐变量和onehot向量,输入生成网络模块得到生成文本,对真实文本和生成文本计算mse损失;聚类损失:以真实文本的隐变量通过kmeans无监督聚类方法计算聚类损失。
[0034]
计算各损失函数时经过的网络由对应的损失函数值通过反向传播调节,其中真实样本判别损失、梯度惩罚损失用于调节生成网络和判别网络,隐变量重建损失、文本重建损失用于调节生成网络和编码网络,聚类损失用于调节编码网络。
[0035]
实施例:将该发明用于从网络爬取的医学舆情文本数据的清洗,如从百度知道中按照与“问诊相关”的关键词采集到的“一问一答”形式的数据,由于关键词会命中一些不想要的非医学问答数据,如广告文本,训练gan网络用于去掉这部分文本数据,减少后续的工作量。如数据中包含不相关数据及“医疗器械”“药物”2种类型(n_c=2),且有一定量的标注数据,可用于判别损失的计算,其他损失的计算不需要对类型区分,在清洗步骤中用于计算该类型的锚向量,用输入文本的向量与2种类型的锚向量计算距离得到噪声度,与各锚向量得到的最小距离越大则代表该文本更接近噪声;如数据中包含“不相关”“医疗器械”“药物”3种类型(n_c=3)的标注数据,在清洗步骤中计算包括“不相关”类型在内的类型的锚向量,与3种类型锚向量计算距离得到噪声度,与“不相关”锚向量距离最近的文本更接近噪声;如数据中不包含标注,则用编码网络得到的onehot向量得到其类型,进行锚向量及噪声的计算,计算得到噪声度的结果如表1和表2所示,表1表示与“问诊相关”类型距离较小的文本为非噪声文本,表2表示与“问诊相关”类型距离较大的文本为噪声文本。表1和表2中“标题”与“距
离”分别表示待清洗的文本和计算得到的距离。
[0036]
表1表2
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1