一种数据集约化管理转分发的方法与流程
1.发明数据集处理领域,尤其涉及一种数据集约化管理转分发的方法。
背景技术:
2.相对于大量常规数据来说,数据集中存在的离群点是一种异常孤立的数据模式。通常情况下,数据集中存在的离群点会被作为噪声而被消除,但部分离群点中会存在一些重要的信息。离群点检测就是结合可视化、统计学、智能计算、机器学习等多种技术对数据集中存在的离群点进行识别, 便于后续的数据处理和分析。因为离群点中可能存在有效信息,因此离群检测在气象预测、预防电信诈骗、市场分析、医疗保险和预防信用卡欺诈等领域中得到了广泛的应用,具有重要的现实意义和学术意义。
3.现有的基于马氏距离的数据集离群点检测算法,该算法通过阶比重采样方法对大规模数据集中存在的原始数据进行预处理,并对数据进行量纲-因子分析,结合马氏距离采用多元线性归回方法构建离群点检测模型,实现对大规模数据集离群点的检测。然而因在大规欧模数据集下量纲-因子分析过程较为复杂,导致该算法转变数据形式所用的时间较长,存在检测效率低的问题。
技术实现要素:
4.为了克服现有技术存在的缺点与不足,本发明提供一种数据集约化管理转分发的方法。
5.本发明所采用的技术方案是,包括数据装备功能模块、数据管理功能模块、数据应用功能模块;所述数据装备功能模块对设备过去和现在的参数进行数据统计、归类、查询和输出,在不同生命周期内对设备的属性进行适当的分类,并在系统中进行重复查询和搜索使用;对于新购入设备以及设备的参数可以进行修改,对于改扩建工程根据工程内容,对设备参数进行更新,设备与工程需要进行关联,完成数据的流转,从而对工程和设备参数进行流程化管理;所述数据管理功能模块,完成对数据模式定义、数据存取的物理构建、数据操纵、数据的完整性、安全性定义和检查、数据库的并发控制与故障恢复、数据的服务,根据不同的数据模式,将数据信息发送给调度中心,建立运行方式审查和实时监测平台,在此过程中,调用相关的设备和网络结构数据;所述数据应用功能模块,该功能模块与调度系统进行接口,提供运行设备参数,设备参数以公共信息模型的标准格式进行输出,并且为其他的调度外系统进行设备参数查询和调用,外系统可以利用输出设备参数进行比对或导入,输出时可以按单个设备、所有设备、一类设备或某地区等条件进行设置。
6.进一步地,建立责任机制,从而管理人员或运维人员对自己的操作行为负责,包括应用日志记录和数字签名等技术手段进行抗抵赖设计;
(1) 日志记录通过对用户行为记录日志,并采取措施保障日志信息的完整性;(2) 数字签名用户的所有操作行为进行数字签名,记录操作行为及操作时间。
7.进一步地,数据安全性防护,包括应用、操作系统和网络,是防止系统被篡改,或被注入病毒木马,或者恶意调整了系统结构,统一用户管理和身份认证、rbac 授权管理与rbac、统一加解密,跨区数据交互的主要安全基础设施如下:(1)身份管理与身份认证基础设施;(2)授权管理和 rbac 基础设施;(3)加密解密基础设施;(4)系统安全管理、监控与审计基础设施。
8.进一步地,所述数据管理功能模块利用离群点检测算法对数据集进行降维处理,去除大规模数据集中存在的冗余数据,进而缩短离群点检测过程所需的时间;输入空间中存在 n个数据,a代表样本对应的协方差,其表达式如下:(1)其中,t表示数据离散度,输入空间中存在的样本点,并通过非线性映射函数将其转变为特征空间中存在的样本点 ,代表的是特征空间中存在的协方差,其表达式如下:(2)在求解式(3)的基础上,结合所得的特征空间协方差,可得到特征空间中存在的特征值:(3)其中,表示特征空间中存在的特征量,且:(4)其中,表示数据容量,通过式(3)、(4)特征空间的特征值与数据容量和样本点有直接的联系。
9.进一步地,在此基础上,设置一个大小为m
×
m的矩阵b,其表达式如下:(5)其中,n,m∈m,通过式(5)获得映射空间中存在的特征量,在空间向量上测试样本对应的投影为:(6)如果在特征空间中,数据无法满足中心化条件,则修正矩阵,将公式(5)中的用
进行描述:(7)。
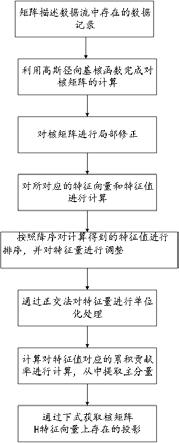
10.进一步地,利用核主成分分析方法对大规模数据集进行降维处理,具体过程如下:(1)用i
×
j维的矩阵h描述数据流中存在的j条数据记录:(8)(2)利用高斯径向基核函数完成对核矩阵 q 进行计算,过程如下:(9)由式(9)可知,核矩阵与测试样本对应的投影存在直接关联,同时也受到输入空间中样本数据的影响;(3)对核矩阵q进行局部修正;(4)对 q所对应的特征向量和特征值进行计算;(5)按照降序对计算得到的特征值进行排序,并对特征量进行调整;(6)通过 gram
‑
schmidt 正交法对特征量进行单位化处理,获得;(7)计算对特征值对应的累积贡献率进行计算,从中提取t个主分量;(8)通过下式获取核矩阵 h 特征向量上存在的投影:(10)根据式(10)中对特征量、核矩阵和特征值主分量的计算,获得的投影k即为降维处理后的大规模数据集。
11.本发明针对传统方法在检测离群点时常因冗余数据的干扰而导致检测用时较长、检测准确率偏低的问题,利用大规模数据集离群点检测算法,采用核主成分分析方法对大规模数据集进行降维处理,去除其中存在的冗余数据,该方法的检测时间始终低于0.4min,且检测准确率始终保持在 90%以上,说明该算法能够快速、准确地检测大规模数据集中的离群点。
附图说明
12.图1为本发明数据集处理流程图。
具体实施方式
13.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互结合,下面结合附图和有具体实施例对本技术作进一步详细说明。
14.如图1所示,一种数据集约化管理转分发的方法, 包括数据装备功能模块、数据管理功能模块、数据应用功能模块;
数据装备功能模块对设备过去和现在的参数进行数据统计、归类、查询和输出,在不同生命周期内对设备的属性进行适当的分类,并在系统中进行重复查询和搜索使用;对于新购入设备以及设备的参数可以进行修改,对于改扩建工程根据工程内容,对设备参数进行更新,设备与工程需要进行关联,完成数据的流转,从而对工程和设备参数进行流程化管理;数据管理功能模块,完成对数据模式定义、数据存取的物理构建、数据操纵、数据的完整性、安全性定义和检查、数据库的并发控制与故障恢复、数据的服务,根据不同的数据模式,将数据信息发送给调度中心,建立运行方式审查和实时监测平台,在此过程中,调用相关的设备和网络结构数据;数据应用功能模块,该功能模块与调度系统进行接口,提供运行设备参数,设备参数以公共信息模型的标准格式进行输出,并且为其他的调度外系统进行设备参数查询和调用,外系统可以利用输出设备参数进行比对或导入,输出时可以按单个设备、所有设备、一类设备或某地区等条件进行设置。
15.建立责任机制,从而管理人员或运维人员对自己的操作行为负责,包括应用日志记录和数字签名等技术手段进行抗抵赖设计;(1) 日志记录通过对用户行为记录日志,并采取措施保障日志信息的完整性;(2) 数字签名用户的所有操作行为进行数字签名,记录操作行为及操作时间。
16.数据安全性防护,包括应用、操作系统和网络,是防止系统被篡改,或被注入病毒木马,或者恶意调整了系统结构,统一用户管理和身份认证、rbac 授权管理与rbac、统一加解密,跨区数据交互的主要安全基础设施如下:(1)身份管理与身份认证基础设施;(2)授权管理和 rbac 基础设施;(3)加密解密基础设施;(4)系统安全管理、监控与审计基础设施。
17.数据管理功能模块利用离群点检测算法对数据集进行降维处理,去除大规模数据集中存在的冗余数据,进而缩短离群点检测过程所需的时间;配置管理层和用户数据层组成。配置管理层要实现的功能如下:(1) 用户数据表注册、检索配置和访问权限配置:主要是在数据库中增加用户信息,并对用户的访问范围进行相关定义。
18.(2) 数据模型(表关联)定义功能:定义关联表之间字段的引用关系(相当于数据库主键、外键)。系统数据表中应包括显式描述字段引用的“字段引用数据表”;能够列出关联的两个表中的所有字段,用户可从关联表中分别选择一个字段分别作为主键、外键。
19.(3) 主表及派生表的数据视图定义功能:视图是用户在浏览、查询界面可访问的数据表的集合。它可包含多个独立的、可联合查询的逻辑表。当指定一张主表后,所有与此表关联的表自动按级联关系呈现;当一个表被多个表引用时,这个表在视图定义过程中只出现一次。
20.(4) txt、excel 用户数据导入功能:可通过文本复制、粘贴或文件上传,将用户数
据导入数据表。
21.(5) 创建文件访问链接功能:用户表中某些字段表示文件在服务器文件系统中的存储路径(url),通过创建 http 访问链接功能配置服务器访问目录,应能将这些本地或外部访问路径转换为对所在服务器有效的 http 访问链接。
22.用户数据层要实现的功能如下:(1) 按数据视图实现列表浏览、单记录浏览和交叉索引浏览功能:对多表逻辑表,列出在数据视图中定义的所有字段,用户可选择希望在浏览页面中呈现的字段。
23.(2) 数据视图多表查询功能:多表逻辑表查询界面中,列出数据视图中各“属性”字段的查询条件输入框;查询结果为所有使查询条件逻辑与为真的逻辑表记录。
24.(3) 浏览、查询结果下载功能:查询浏览结果可下载到本地;所下载文本文件可用 excel 直接打开。
25.数据中心网络( data center network, dcn) 承载了多样的服务。网页搜索等在线服务产生的流称为截止时间流( deadline flow),当一条流错过其规定的截止时间时, 会影响最终的计算结果, 因此降低该类流的截止时间错失率( deadline miss rate, dmr) 十分重要。虚拟机迁移等服务所产生的流称为非截止时间流 ( nondeadline flow),流的平均完成时间( average flow complete time, afct) 是衡量此类服务性能 的一项关键指标。
26.随着服务种类和数量的增多,端到端的传输时延增加,严重影响了用户体验。为提高服务性能,当前研究主要从拥塞控制和流量调度两个方面进行优化设计。拥塞控制通过调整每条流发送窗口的大小,控制交换机内队列的长度。dctc利用显式拥塞通告机制( explicit congestion notification, ecn) 按比例调整每条流的发送量,缓解网络拥塞,但其忽略了不同流的传输特性,导致较高的截止时间错失率。为了对不同需求特性的流加以区分, d2 tcp 和 l2 dct引入优先级系数,采用伽马校 正函数对网络拥塞程度进行修正。d2tcp定义了流的紧迫程度,有效降低了截止时间错失率。l2dct 借鉴最短服务时间优先( least attained service, las) 的思想,根据每条流的累计发送量动态地调整流的发送速率,实现流的平均完成时间最小。伽马校正函数存在的问题是,当网络拥塞程度比较大时,所有优先级相似的流的窗口缩减比例相近,优化效果退化为dctcp.流量调度通过调整流在交换机内的排队顺序,保证不同流的传输需求。pdq一种最早截止时间优先( earliest deadline first, edf) 和最短流优先( shortest job first, sjf) 相结合的抢占机制,实现了流的快速调度,但其需要对交换机的硬件进行修改,无法在商用交换机上实现.为方便部署,pias将流调度的决策功能转移到了主机端,结合现有交换机可提供多级优先级队列的特点,在主机端设计了多级反馈队列( multiple level feedback queue, mlfq) ,发送方根据每条流累计发送总量对数据包的优先级进行设定,交换机只需根据包头的优先级将包分配到指定的队列中,通过发送端和接收端主机的协作,有效的降低了流的平均完成时间。
27.输入空间中存在 n个数据,a代表样本对应的协方差,其表达式如下:(1)其中,t表示数据离散度,输入空间中存在的样本点,并通过
非线性映射函数将其转变为特征空间中存在的样本点 ,代表的是特征空间中存在的协方差,其表达式如下:(2)在求解式(3)的基础上,结合所得的特征空间协方差,可得到特征空间中存在的特征值:(3)其中,表示特征空间中存在的特征量,且:(4)其中,表示数据容量,通过式(3)、(4)特征空间的特征值与数据容量和样本点有直接的联系。
28.在此基础上,设置一个大小为m
×
m的矩阵b,其表达式如下:(5)其中,n,m∈m,通过式(5)获得映射空间中存在的特征量,在空间向量上测试样本对应的投影为:(6)如果在特征空间中,数据无法满足中心化条件,则修正矩阵,将公式(5)中的用进行描述:(7)。
29.进一步地,利用核主成分分析方法对大规模数据集进行降维处理,具体过程如下:(1)用i
×
j维的矩阵h描述数据流中存在的j条数据记录:(8)(2)利用高斯径向基核函数完成对核矩阵 q 进行计算,过程如下:(9)由式(9)可知,核矩阵与测试样本对应的投影存在直接关联,同时也受到输入空间中样本数据的影响;(3)对核矩阵q进行局部修正;(4)对 q所对应的特征向量和特征值进行计算;(5)按照降序对计算得到的特征值进行排序,并对特征量进行调整;
(6)通过 gram
‑
schmidt 正交法对特征量进行单位化处理,获得;(7)计算对特征值对应的累积贡献率进行计算,从中提取t 个主分量;(8)通过下式获取核矩阵 h 特征向量上存在的投影:(10)根据式(10)中对特征量、核矩阵和特征值主分量的计算,获得的投影k即为降维处理后的大规模数据集。
30.本发明针对传统方法在检测离群点时常因冗余数据的干扰而导致检测用时较长、检测准确率偏低的问题,利用大规模数据集离群点检测算法,采用核主成分分析方法对大规模数据集进行降维处理,去除其中存在的冗余数据,该方法的检测时间始终低于0.4min,且检测准确率始终保持在 90%以上,说明该算法能够快速、准确地检测大规模数据集中的离群点。
31.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解的是,在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种等效的变化、修改、替换和变型,本发明的范围由所附权利要求及其等同范围限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1