一种基于混合架构的表格语义查询粗排方法与流程
1.本发明涉及人机对话、智能语义搜索技术领域,具体来说是一种基于混合架构的表格语义查询粗排方法。
背景技术:
2.目前语义分析中基于粗排的方法主要有基于词典或分词后的倒排索引方法,这种直接快速,但对于同义词或者同义短语缺乏泛化能力。而直接用训练模型(如bert等预训练模型)实时计算,线上成本较高,不能满足大规模数据高并发在线实时计算要求。因此本文提出一种基于缓存技术的混合架构粗排方法,从全量数据集中筛选候选集合,然后再传给精排模型,以提升系统的响应时间。
技术实现要素:
3.本发明用以解决金融领域复杂上下文环境下查询语句的实体粗排问题,提供一种基于混合架构的表格语义查询粗排方法,特征在于构建粗排模型,方法具体如下:
4.步骤一.上下文模型编码,将表名及列名进行编码,为数据库表名和列名构建唯一标识符号,建立映射关系,将标识符与表名及列名含义进行拼接组成上下文,作为查询语句的先验知识;
5.步骤二.构建输入,将问题和上下文进行分别bert编码,采用bert预训练模型作为输入,编码构建方式为:[cls]question[sep],[cls]context[sep],question为输入的问题,context上下文编码;
[0006]
步骤三.构建输出;
[0007]
步骤四.构建训练模型,将步骤二输出的查询向量和上下文向量进行拼接,输入transformer层产生中间向量,后将中间向量接入crf层进行实体识别;
[0008]
步骤五.模型训练,根据步骤二和步骤三产生的输入和输出集并结合步骤四进行微调训练;
[0009]
步骤六.离线上下文向量加载,根据步骤五的模型,事先将所有的上下文进行向量输出并保存至dump文件中,推理时加载本地dump文件中的离线缓存上下文向量vector_context(s),s为离线缓存到dump文件中的向量个数;
[0010]
步骤七.推理阶段,根据步骤五的模型,将编码后的查询语句vector_query扩展到s个,然后与离线缓存向量vector_context(s)一一对应进行拼接产生vector_new(s),输入模型后进行预测;
[0011]
步骤八.对实体标签进行是筛选,将满足条件输出进行合并,得到模型输出的关联数据表名。
[0012]
本发明还具有如下优选的技术方案:
[0013]
1.步骤一包括
[0014]
a.确定好上下文最大长度lvec;
[0015]
b.对于关系型数据表名和列名注释信息,以列名字段注释值或其对应的同义词为列名单元(以下简称列名单元),将表中所有列名单元随机进行打乱组合产生n个组合,表名字段注释值或其对应的同义词(以下简称表名单元)分别与这个n个组合进行拼接,产生n个上下文,与原有的上下文一起共产生n+1个上下文;
[0016]
c.上下文切割归集,对于n+1个上下文,对每一个上下文以列名单元进行切割,保证切割后(表名单元+mcols*列名单元)的长度不超过lvec,其中mcols为本次容纳字段个数,切割完成后即完成编码,供后续步骤使用。
[0017]
2.步骤四和步骤七的拼接方法如下:
[0018]
vector_query拆分成vector_query_v和vector_query_p,vector_query_v为vector_query有效向量(即含[cls]xxx[sep]部分),vector_query_p为填充向量(含[pad]部分)
[0019]
vector_new=vector_query_p(s)+vector_context(s)+vector_query_v(s)。
[0020]
s为向量的个数
[0021]
3.还包括字典定义,构建表名、列名含义与关系型数据库表名建立映射关系,构建字典库。
[0022]
本发明同现有技术相比,其优点在于:
[0023]
1.具备字典识别的高效,满足专业限定领域的专业术语的识别;
[0024]
2.事先将上下文向量离线生成,省去了预训练模型的编码计算过程,提升在线响应时间,同时满足泛化需求,能够识别常用口语化及相似词语。
附图说明
[0025]
图1是混合架构流程图;
[0026]
图2是粗排算法流程图。
具体实施方式
[0027]
下面结合附图对本发明作进一步说明,本发明的结构和原理对本专业的人来说是非常清楚的。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0028]
在精排模型中计算查询语句和上下文是否存在实体映射关系时,没有必要将数据库中所有的上下文和查询语句都计算一遍,我们只需计算可能有关联的上下文即可,在粗排阶段我们可以结合字典值和基于缓存向量的方法来计算可能存在关联的上下文,即得到表名,然后再将查询语句和潜在的表名一一结合送入精排模型,从而找到结果。字典可以弥补专有名词和属性值的识别,高效准确,粗排计算模型是可以从语义级别来识别查询语句是否和当前表有关系,具体步骤为:
[0029]
1.字典定义。以关系型数据库的注释信息为例,构建表名、列名含义与关系型数据库表名建立好映射关系,构建字典库
[0030]
2.构建粗排模型。粗排模型的构建步骤如下:
[0031]
2.1.将上下文模型进行编码。将表名及列名进行编码,为数据库表名和列名构建唯一标识符号,并建立起映射关系,将标识符与表名及列名含义进行拼接组成上下文,作为
查询语句的先验知识。由于预训练模型(如bert)有长度限制,需要对超长的部分进行截取,截取算法如下:
[0032]
a.确定好上下文最大长度lvec;
[0033]
b.对于关系型数据表名和列名注释信息,以列名字段注释值或其对应的同义词为列名单元(以下简称列名单元),将表中所有列名单元随机进行打乱组合产生n个组合,表名字段注释值或其对应的同义词(以下简称表名单元)分别与这个n个组合进行拼接,产生n个上下文,与原有的上下文一起共产生n+1个上下文;如原有表名及列名信息如下:company_basic^上市公司基本信息|stock_abbr^证券简称|col2^xxx|col3^xxxx|
…
,按照表名固定不变,列名字段按照随机调序重新生成n个组合,其中一个举例为:company_basic^上市公司基本信息|col2^xxx|stock_abbr^证券简称|col3^xxxx|
…
[0034]
c.上下文切割归集,对n+1个上下文中的每一个上下文以列名单元进行切割,保证切割后(表名单元+mcols*列名单元)的长度不超过lvec,,其中mcols为本次容纳字段个数,切割完成后即完成编码,供后续步骤使用。
[0035]
2.2.构建输入。将问题和上下文分别独立进行bert编码,采用bert预训练模型作为输入,编码构建方式为:[cls]question[sep],[cls]context[sep],question为输入的问题,context上下文编码。
[0036]
2.3.构建输出(位置输出)。实体标签采用rb、ri、o、[sep]、[cls]、[x]、[pad]标签。rb、ri代表关联实体的开始和连接部分。如浦发银行什么时候上市?可以表示o o o o rb ri ri ri ri ri o。
[0037]
2.4.构建训练模型。将步骤二输出的下游向量进行拼接(逻辑同2.7的拼接逻辑),输入transformer层产生结果向量(transformer的层数为1-3层),后将向量接入crf层进行实体识别。.
[0038]
2.5.模型训练,根据步骤二和步骤三产生的输入和输出集并结合步骤四进行微调训练;
[0039]
2.6.离线上下文向量加载,根据步骤五的模型,事先将所有的上下文进行向量输出并保存至dump文件中,推理时加载本地dump文件中的离线缓存上下文向量vector_context(s),s为离线缓存到dump文件中的向量个数
[0040]
2.7推理阶段,根据步骤五的模型,将编码后的查询语句vector_query扩展到s个,然后与离线缓存向量vector_context(s)一一对应进行拼接产生vector_new(s),输入模型后进行预测;
[0041]
拼接方法如下:
[0042]
vector_query拆分成vector_query_v和vector_query_p,vector_query_v为vector_query有效向量(即含[cls]xxx[sep]部分),vector_query_p为填充向量(含[pad]部分)
[0043]
vector_new=vector_query_p(s)+vector_context(s)+vector_query_v(s),s为向量的个数
[0044]
2.8对实体标签进行是筛选,将满足条件输出进行合并,得到模型输出的关联数据表名。
[0045]
3.将第1步和第2步得到数据库表进行合并并得到最终的数据库表名。
[0046]
在一个优选的实施方式中,
[0047]
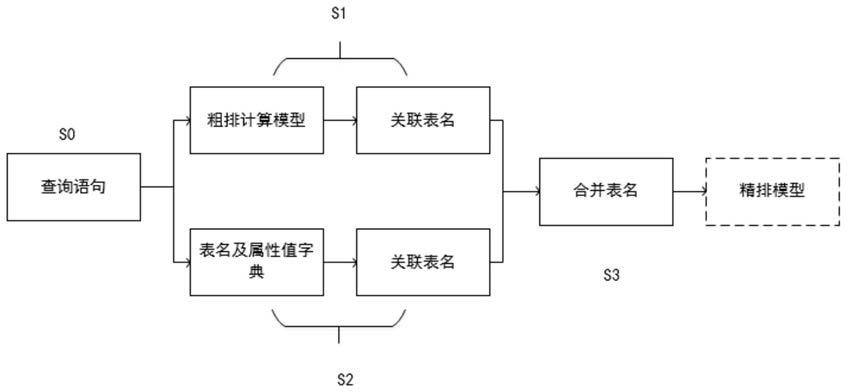
图1出示了混合架构流程图,该系统包括:
[0048]
s0.为用户输入的问题,如“浦发银行什么时候上市”,用以表达用户最直接的问题。
[0049]
s1:将查询语句放入粗排模型中,获取和查询语句关联的数据库表上下文,从而获取潜在的数据库表,本例以关系型数据库的表及列名的注释为上下文,但不仅限于关系型数据库表,常用key-value等键值对的结构也适用本方法,如json、mongodb、图数据库的结构等,有唯一标示符的文本内容也适用此方法。
[0050]
s2:以表名、列名以及字段值为基础数据建立key-value结构的索引(如倒排索引、hash索引等)字典库,将查询语句放入字典库中搜索,采用贪婪原则搜索关键词对应的表。
[0051]
s3:将s1和s2中获取的表进行合并去重,获得的表集合即为与查询语句的潜在关系表。
[0052]
图2出示了粗排模型的结构,具体步骤如下:
[0053]
s4:以关系型数据库表为例,用表注释及列名注释为上下文,根据bert模型的最大长度进行截取和拼接。在模型训练阶段,此步参与流程;在实时推理阶段,由于相关数据已离线缓存,所以在实时推理阶段,此步不参与流程。
[0054]
如上市公司基本信息表结构如下:
[0055]
"company_basic^上市公司基本信息|stock_abbr^证券简称|col2^xxx|col3^xxxx|
…
"
[0056]
如果表上下文超过模型最大长度max_seq,则可以截取拼接处理,逻辑如下:
[0057]
序号上下文编码1上市公司基本信息|证券简称|上市时间|
…
xxx2上市公司基本信息|xxx|[xxx|
…
xxx3...
[0058]
s5:编码处理。在训练阶段:查询语句和对应的上下文经过此步获取bert编码后的向量。在推理阶段,由于上下文的数据已缓存,只需将单个查询语句送入bert进行编码处理。
[0059]
s6:离线缓存。在训练阶段跳过此步。将数据库中所有的表上下文送入微调后的模型,并生成的向量存入dump文件中,在使用时提前加载入内存。在推理时,直接从内存中获取所有的向量集合。
[0060]
s7:查询语句扩展。训练阶段,单个表上下文可能会拼接成p个,查询语句自然扩展成p个。在推理阶段,查询语句会扩展成离线缓存向量集合n的长度
[0061]
s8:将s7和s6获取的向量根据规则进行拼接组成新的向量。
[0062]
s9:将s8获取的向量进行m层transformer。
[0063]
s10:将s9获取的向量作为初始概率送入crf层。
[0064]
s11:产生标签序列结果集合,并得出相应的关联的表字段,从而得出表名。
[0065]
s12:将结果集合合并去重处理,得到粗排后的相关表集合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1