基于深度学习的可见光、红外和雷达融合目标检测方法与流程
1.本发明涉及人工智能目标检测和匹配技术领域,具体为基于深度学习的可见光、红外和雷达融合目标检测方法。
背景技术:
2.目标检测是计算机视觉领域研究的主要问题,图像分割、目标跟踪、目标行为分析等都以目标检测为基础,随着基于卷积神经网络的深度学习算法的发展,目标检测取得了巨大的突破,基于可见光相机图像的目标检测算法已经得到广泛的应用,可见光相机作为传感器的一种,有几何形状逼真、立体感强、分辨率好等优点,也有其局限性,如:可见光相机是被动相机,在受到低光照或雨雪雾等干扰时,成像质量显著下降,甚至导致算法失效;热红外相机是另一种被动相机,依靠与正常光照相当,可以用于补充可见光相机在低光照下的成像性能;激光雷达是一种主动探测器,通过向目标发射一束光(通常是一束脉冲激光)来测量目标的距离、反射率等参数,激光雷达能补充可见光相机所缺乏的距离信息,在低光照下也能有效工作;
3.单一、不融合的目标检测获取到的场景内的信息不够丰富,也不能帮助更好地理解目标以及周围的环境,不能适应复杂的场景变化和动态变化,随着训练集目标种类的增多和训练集的增加,检测的效率和性能或逐渐降低。
4.所以,人们需要基于深度学习的可见光、红外和雷达融合目标检测方法来解决上述问题。
技术实现要素:
5.本发明的目的在于提供基于深度学习的可见光、红外和雷达融合目标检测方法,以解决上述背景技术中提出的问题。
6.为了解决上述技术问题,本发明提供如下技术方案:基于深度学习的可见光、红外和雷达融合目标检测方法,其特征在于:包括以下步骤:
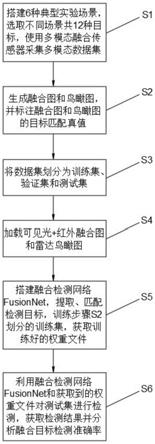
7.s1:搭建n=6种典型实验场景,选取不同场景共2n=12种目标(动态目标+静态目标),使用搭载在无人车上自研的多模态融合传感器sensorbox在不同实验场景中随机行走以采集多模态数据集,多模态数据存储为rosbag包;
8.s2:生成融合图和鸟瞰图,并标注融合图和鸟瞰图的目标匹配真值;
9.s3:将数据集划分为训练集、验证集和测试集;
10.s4:加载可见光+红外融合图和雷达鸟瞰图;
11.s5:搭建融合检测网络fusionnet,提取、匹配检测目标,训练步骤s2划分的训练集,获取训练好的权重文件;
12.s6:利用融合检测网络fusionnet和获取到的权重文件对测试集进行检测,获取检测结果并分析融合目标检测准确率。
13.进一步的,所述多模态数据集是指包含n=6种典型场景和2n=12种典型目标的可
见光、热红外和激光雷达数据集,其中6种典型场景是指室内、开放(白天)、开放(夜晚)、半开放(白天)、半开放(夜晚)和地下,不同的环境差异较大,如地下和夜晚环境的光照较弱,可见光数据较暗;室内和地下环境的雷达数据被局限在一定的高度范围内;不同场景的热红外相机数据受到的光照影响较弱,但受到运动目标的动态干扰较强,且热红外相机的成像分辨率和视场较小,在室内场景中:该场景主要利用摄像头得到的rgb数据,对得到的数据进行目标检测,红外传感器采集到的数据、毫米波雷达数据以及激光雷达数据是对目标检测的重要补充;
14.在开放场景(白天)中:该场景主要利用摄像头得到的rgb数据进行目标检测,热红外数据以及激光雷达数据是对rgb目标检测的重要补充,另外毫米波雷达的数据是对目标位置检测的重要补充;
15.在开放场景(夜晚)中:该场景主要利用红外传感器得到的红外数据进行目标检测,摄像机得到的rgb数据以及激光雷达数据是对红外目标检测的重要补充;
16.在半开放场景(白天)中:该场景主要利用摄像头得到的rgb数据和红外传感器得到的数据进行目标检测,毫米波雷达数据以及激光雷达数据是对目标检测的重要补充;
17.在半开放场景(夜晚)中:该场景主要利用激光雷达点云数据和红外传感器得到的数据进行目标检测,毫米波雷达数据以及红外数据是对目标检测的重要补充;
18.在地下场景中:在弱光照的地下车库场景下,热红外数据是基于视觉的目标检测的重要补充;在仅有前向摄像头情况下,激光雷达数据是视觉盲区目标检测的重要补充;
19.其中,12种典型目标是指选取的12种待检测的目标:人、汽车、车轮、坦克模型、椅子、小凳子、空调、笔记本电脑、桌子、骑车的人、交通灯、卡车,其中动态目标有:骑车的人、人、汽车和坦克模型,人和汽车也有静态情形,各个目标非均匀得分布在不同场景中,其中,地下车库包含人、汽车和车轮;室内场景包含人、坦克模型、椅子、小凳子、空调、笔记本电脑和桌子;半开放和开放的室外场景包含:人、卡车、骑车的人和交通灯。
20.进一步的,在步骤s2中:根据可见光和红外相机的标定文件将对应帧的可见光和红外图像进行对齐,合并生成融合图,使用label image工具对融合图进行12种目标的标注,标注保存为txt格式,设计cloud2bev算法,将每帧的3d激光雷达点云转换为包含雷达信息的鸟瞰图,使用label image对鸟瞰图进行目标标注,保存为txt格式,根据可见光和雷达标定文件,手动对齐可见光和雷达的目标标注,保存可见光-雷达匹配真值,根据可见光和雷达标定文件标注融合图和鸟瞰图的目标匹配真值:分别读取融合图标注、鸟瞰图标注和原始点云数据,根据鸟瞰图的标注框确定被标注的目标包含的点云,根据标定的内外参把包含的点云投影到融合图的像素坐标下,完成鸟瞰图和融合图总同一个目标的匹配,由于标注误差、内外参误差等导致自动配准不精确,可以进行手动匹配提高精确度。
21.进一步的,所述cloud2bev算法是指将三维空间点云数据转换为鸟瞰图的算法,将雷达点云的感兴趣区域设置为从左侧10米到右侧10米、从雷达后方10米到前方10米的区域,区域长宽比为1:1,转换后鸟瞰图的像素为640
×
640,鸟瞰图每个像素点有3个通道,分别为:该像素点包含的所有点的平均反射强度、平均高度,即z轴的值和归一化密度,其中,感兴趣区域指的是将被处理的图像以方框、圆、椭圆、不规则多边形等方式勾勒出的需要处理的区域。
22.进一步的,所述步骤s4中:编写融合数据加载程序,同时加载可见光+红外融合图
和雷达鸟瞰图,实现多种类型的随机数据增强方法和并行加载。
23.进一步的,所述数据增强方法是针对包含可见光+红外信息的融合图和包含雷达信息的鸟瞰图进行的,包括:色域变换、光照畸变、随机比例缩放、随机左右翻转、随机上下翻转和mosaic数据增强,mosaic数据增强指的是:利用4张图片,对目标和背景进行随机裁剪和缩放,并合成一张图片,更新对目标的标注,丰富了数据的背景信息,增强了鲁棒性。
24.进一步的,在步骤s5中:搭建融合检测网络fusionnet,基于yolov5,采用cspnet、sppnet和panet等包,修改网络,引入se模块实现通道注意力机制,设计leg层实现融合特征的分离,依据图神经网络gnn引入graph层,将融合图和鸟瞰图的检测结果进行图匹配和图卷积,最终实现三种模态的融合,使用步骤s3中划分得到的训练集进行训练,利用验证集实时显示每一代训练后的效果,训练结束后获得训练好的权重文件。
25.进一步的,所述fusionnet是指所设计的对可见光、红外和激光雷达数据进行融合目标检测的深度神经网络,网络的输入为(bs,6,640,640),其中bs指批尺寸batch size,640为图像的高和宽,6指的是两张图像共计6通道,两张图像分别为:可见光和红外合并后的一张图和雷达点云转换为bev后的鸟瞰图,网络内部采用残差网络、跨阶段局部网络、压缩和激发块、空间金字塔池化网络和路径聚合网络等科技,解决了其他大型卷积神经网络框架中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,可以有效缓解梯度消失问题,支持特征传播,鼓励网络重用特征,减少了模型参数数量和flops数值,其中,使用的残差网络为bottleneck残差网络结构,增加了网络深度,使得网络有更强大的特征提取能力,在每个检测头之前,使用特征分岔网络将特征分裂为两块,而后使用检测头回归,将回归结果分别于可见光+红外图像的标注文件和bev图像的标注文件计算损失函数,将输出匹配结果与标注真值进行比较计算损失函数,损失函数采用l1损失,用于网络学习。
26.进一步的,所述leg层是指处理三种不同尺度特征的分岔网络构成的层,尺度分别为20
×
20、40
×
40和80
×
80,将合并在一起的可见光红外融合图特征和雷达鸟瞰图特征分离,有利于分别对两张图进行目标检测。
27.进一步的,所述graph层是指采用图神经网络gnn搭建的用于匹配可见光+红外的检测结果和雷达的检测结果的网络层,首先采用图嵌入的方法将两个结果嵌入为图graph,即根据融合图结果的n个目标和鸟瞰图的m个目标搭建节点匹配和边匹配的“图”,而后采用图卷积对该“图”进行处理,输出匹配结果,匹配结果与真实的标注匹配数据计算损失函数,有利于更新网络权重。
28.与现有技术相比,本发明所达到的有益效果是:
29.1.相比于以往的目标检测算法,本发明能够针对多模态传感器采集到的融合数据实现融合目标检测,实现了能同时处理多模态信息的算法和网络,解决了不同模态的信息进行融合的问题,充分利用了不同模态的信息互补特性,具有稳定性高、抗干扰能力强、鲁棒性良好等优点;
30.2.本发明基于目标检测算法yolov5,具有目前目标检测领域单模态检测的最强性能,将yolov5进一步扩展,使其具备了处理融合信息的能力,引入se模块,在增加少量计算的同时提升了目标检测的准确率,引入leg层,实现了不同模态信息的分离,使用图神经网络gnn实现了不同模态信息的融合匹配,提高了目标检测的综合性能。
附图说明
31.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
32.图1是本发明基于深度学习的可见光、红外和雷达融合目标检测方法的流程图;
33.图2是本发明的三种模态传感器数据示例图;
34.图3是本发明的整体深度学习网络模型图;
35.图4是本发明的多场景多目标多模态融合目标检测结果图。
具体实施方式
36.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
37.请参阅图1-4,本发明提供技术方案:基于深度学习的可见光、红外和雷达融合目标检测方法,其特征在于:包括以下步骤:
38.s1:搭建n=6种典型实验场景,选取不同场景共2n=12种目标,使用多模态融合传感器采集多模态数据集;
39.s2:生成融合图和鸟瞰图,并标注融合图和鸟瞰图的目标匹配真值;
40.s3:将数据集划分为训练集、验证集和测试集;
41.s4:加载可见光+红外融合图和雷达鸟瞰图;
42.s5:搭建融合检测网络fusionnet,提取、匹配检测目标,训练步骤s2划分的训练集,获取训练好的权重文件;
43.s6:利用融合检测网络fusionnet和获取到的权重文件对测试集进行检测,获取检测结果并分析融合目标检测准确率。
44.多模态数据集是指包含n=6种典型场景和2n=12种典型目标的可见光、热红外和激光雷达数据集。
45.在步骤s2中:根据可见光和红外相机的标定文件将对应帧的可见光和红外图像进行对齐,合并生成包含可见光和红外信息的融合图,对融合图进行目标标注,设计cloud2bev算法,将每帧的3d激光雷达点云转换为包含雷达信息的鸟瞰图,对鸟瞰图进行目标标注,根据可见光和雷达标定文件标注融合图和鸟瞰图的目标匹配真值。
46.cloud2bev算法是指将三维空间点云数据转换为鸟瞰图的算法,范围为雷达左右[-10,10]米、前后[-10,10]米,转换后鸟瞰图像素为640
×
640,鸟瞰图每个像素点有3个通道,分别为:像素点包含的所有点的平均反射强度、平均高度,即z轴的值和归一化密度。
[0047]
步骤s4中:编写融合数据加载程序,同时加载可见光+红外融合图和雷达鸟瞰图,实现多种类型的随机数据增强方法和并行加载。
[0048]
数据增强方法是针对融合图和鸟瞰图进行的,包括:色域变换、光照畸变、随机比例缩放、随机左右翻转、随机上下翻转和mosaic数据增强。
[0049]
在步骤s5中:搭建融合检测网络fusionnet,利用卷积神经网络cnn对融合图和鸟瞰图进行统一特征提取和分岔目标检测,再利用图神经网络gnn对融合图和鸟瞰图的检测目标进行匹配,使用步骤s3中划分得到的训练集进行训练,利用验证集实时显示每一代训练后的效果,训练结束后获取训练好的权重文件。
[0050]
fusionnet是指设计的能同时处理融合图和鸟瞰图的深度神经网络,基于yolov5修改输入层,将se模块引入到跨阶段布局网络中,将通道注意力机制se引入到bottleneck中形成se-bottleneck进而形成se-csp网络,引入分岔层leg层,设置双倍检测头,引入图神经网络的graph层匹配两个目标检测结果,便于提高目标检测的准确率。
[0051]
leg层是指处理三种不同尺度特征的分岔网络构成的层,尺度分别为:20
×
20、40
×
40和80
×
80。
[0052]
graph层是指采用图神经网络gnn搭建的用于匹配可见光+红外的检测结果和雷达的检测结果的网络层。
[0053]
实施例一:首先,在数据采集和数据前处理阶段:采集如图2所示的可见光、热红外和激光雷达数据,实现时间同步,如图2(a)和(b)所示,可见光数据是分辨率为1280*720的3通道灰度图,3通道数值相同,热红外相机的数据已经过传感器处理,是分辨率为384*288的3通道彩色图,两个相机的视场范围不同,需要根据相机标定数据,将两个图像合并为一张融合图,雷达为16线velodyne激光雷达,雷达数据为三维空间点云数据,经过cloud2bev算法转换后的鸟瞰图如图2(c)所示,融合图和鸟瞰图的resize均为(640,640,3),而后堆垛resize为(640,640,6)的张量tensor送入到模型中,对融合图和鸟瞰图分别进行标注,标注数据包含:类别、bbox,即为12类目标在像素坐标系下的归一化坐标,保存为yolo格式(txt),标注文件路径与原始图像文件路径一一对应,编写数据加载可见光+红外融合图和雷达鸟瞰图和数据增强算法,实现色域变换、光照畸变、随机比例缩放、随机左右翻转、随机上下翻转和mosaic数据增强;
[0054]
其次,在网络设计阶段:网络架构如图3所示,在经典的backbone+neck+head目标检测架构基础上添加leg层,形成backbone+neck+leg+head架构,如图3(b)所示,强大的特征提取能力主要来源与主干网络backbone,backbone使用了空间注意力机制foucus使感受野变为原来的4倍;使用包含卷积、批归一化和激活函数的卷积块代替池化,作为不同层之间的中间链接;使用空间金字塔池化自适应不同尺寸的子图像;backbone中最主要的层是se-csp,se-csp基于跨阶段局部网络csp,csp基于densnet的思想,复制基础层的特征映射图,通过dense block发送副本到下一个阶段,从而将基础层的特征映射图分离出来,在csp内部,使用bottleneck残差网络结构,用于增加网络深度,将通道注意力机制se引入到bottleneck中形成se-bottleneck进而形成se-csp,在原始剩余块的基础上增加另一条路线,使用全局池化来获得初始信道权重,然后使用两个完整的连接层和sigmoid激活函数来更新每个通道的权重,最后使用原始通道乘以每个通道的权重,这样,在网络训练过程中,通过梯度下降学习每个通道的权值,提高检测精度;如图3(c)所示,特征的增强和针对不同尺寸对象的特征提取主要由neck层完成;neck层采用了路径聚合网络panet,panet的特征提取器采用了一种新的增强自下向上路径的特征金字塔网络fpn,改善了底层的特征传播,自上向下的特征传播采用生采样upsample,自下向上的特征传播采用卷积块conv代替,通过横向连接和堆垛方式,把上一阶段的特征添加到特征图中,这些特征又为下一阶段的特征提供信息,每个阶段都有3种不同尺度的特征,从而实现不同大小和尺度的同一物体的检测,如图3(d)所示,融合特征的分岔主要依靠leg层,neck层输出的3种不同尺度特征包含融合图和鸟瞰图的特征,leg层使用切片方法将特征进行分离,如图3(e)所示,检测主要依靠检测头head实现;将分离后的融合图和鸟瞰图共计6种特征分别送入3种尺度的检测头进行
检测,检测头主要使用conv2d实现,如图3(f)所示,可见光+红外的目标检测结果和雷达的目标检测结果主要依靠graph层实现融合,检测头的检测结果经过非极大值抑制nms后,融合图和鸟瞰图检测到的目标通过图嵌入的方法形成“图”,该图经过图神经网络处理,输出匹配结果;
[0055]
然后,在网络训练阶段:融合图和鸟瞰图的数据及网络准备完毕后,将融合图和雷达图的堆垛张量输入到模型中,达到检测头输出检测结果,与标注真值比较计算损失函数,损失函数包括分类损失、定位损失和置信度损失,分类损失根据目标预测类别与真值类别的差别计算,定位损失根据预测bbox和真值bbox的iou计算,置信度损失根据有无真值标志计算。,根据损失函数进行梯度下降更新模型,训练完成后获取权重文件,在测试集上进行测试,查看模型的目标检测结果,根据检测结果和真值统计混淆矩阵(confusion matrix),然后计算性能指标,有:精确率precision、召回率recall、各类别ap平均值map和f1分数f1_score,若效果不理想,使用网络和该权重文件自动标注更多数据集,而后进行人工微调,调整网络参数,重新训练直至f1分数达到90%,graph层的权重需要单独训练,待目标匹配数据及网络准备完毕后,将检测到的目标输入到构成graph层的图神经网络中,进行图嵌入和图卷积计算,输出匹配结果,与标注真值比较计算损失函数,损失函数采用l1损失。根据损失函数进行梯度下降更新模型,训练完成后获取权重文件,在测试集上进行测试,查看目标匹配结果,包括:map和f1分数;
[0056]
最后,在模型部署和推断阶段:将可见光和红外图像融合程序、激光点云转鸟瞰图程序、数据加载程序、图3所示的网络架构及训练好的权重文件以及源码部署到计算机中,传入多模态传感器采集的多模态数据集,自动实现数据前处理、目标检测和目标融合,实时输出检测结果,实验测试的检测结果如图4所示。
[0057]
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1