皮肤镜图像分割方法与系统
1.本发明涉及图像分割的技术领域,尤其是指一种基于可变形卷积的注意力网络的皮肤镜图像分割方法与系统。
背景技术:
2.目前,应用于皮肤镜图像的分割模型分为两大类,基于形态学处理的传统分割模型和基于深度学习的分割模型。
3.传统的分割模型可以进一步细分为基于阈值的方法,基于区域的方法,基于边缘的方法。基于阈值的方法基于图像的灰度特征计算相应的灰度阈值,将每个像素与灰度阈值进行比较,依据比较结果对像素进行分类。基于区域的方法将图像按照相似性准则分成不同的区域。基于边缘的方法检测灰度级或者结构具有突变的地方,利用该特征进行图像分割。这类方法在图像中有伪影干扰、复杂环境导致特征设计或者阈值选取较为困难、边界模糊等情况下表现不佳。
4.近年来,许多基于深度学习的皮肤镜图像分割模型被提出,大部分方法以端到端的语义分割模型为基础。这类模型相比于传统分割模型,能通过自我学习提取到极为丰富的特征信息,而无需人工设计,且能利用大量的数据样本使模型的适用范围更广。但在对比度低的皮肤镜图像的分割中保留完整的病灶边界、使模型适应病灶区域的多种形状和尺度特点以及解决复杂伪影的干扰依然是相当有挑战性的难题。
技术实现要素:
5.本发明的第一目的在于克服现有技术的缺点与不足,提供一种基于可变形卷积的注意力网络的皮肤镜图像分割方法,提高皮肤病灶区域分割的效率与准确性,利用可变形卷积自适应病灶的多尺度和不规则的问题,同时构建了注意力模块帮助提升边缘分割的准确性同时,加强了对伪影和病灶区域的辨别能力。
6.本发明的第二目的在于提供一种基于可变形卷积的注意力网络的皮肤镜图像分割系统。
7.本发明的第一目的通过下述技术方案实现:基于可变形卷积的注意力网络的皮肤镜图像分割方法,包括以下步骤:
8.1)收集用于网络训练的皮肤镜图像作为训练样本,并划分有训练集、验证集和测试集,再进行预处理操作;其中,完整的一对训练样本包括原始的皮肤镜图像和对应的分割蒙版;
9.2)使用翻转、旋转、缩放和平移的方法对预处理后的训练样本进行数据扩充;
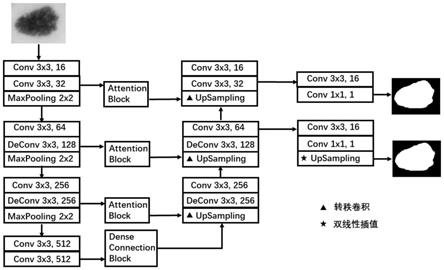
10.3)构建基于可变形卷积的注意力网络,该注意力网络为端到端的编码器-解码器结构,编码器使用了可变形卷积并设计了密集卷积块以得到更丰富的语义特征,解码器设计了监督分支以帮助分割蒙版的重建,此外还在跳过连接部分设计了注意力模块帮助不同层级的特征融合;
11.4)训练基于可变形卷积的注意力网络,将经过步骤2)数据扩充后的训练样本中皮肤镜图像分批送入基于可变形卷积的注意力网络,再将解码器和监督分支输出的特征图经过sigmoid函数分别得到病灶区域概率图,再通过二元交叉熵损失与对应分割蒙版各自计算两部分的损失,按照解码器最后一层与监督分支设定的比例的权重相加得到总损失,最后基于总损失和自适应矩估计优化器调整网络参数,迭代进行至计算的总损失达到最小的状态;
12.5)生成分割结果图,将测试集中的皮肤镜图像输入到训练完成的网络中,得到对应的病灶区域概率图,设定阈值,将病灶区域概率图中大于阈值的值改为255,小于等于阈值的值改为0,最终得到皮肤镜图像对应的分割结果图。
13.进一步,在步骤1)中,收集的训练样本来源于国际皮肤公开挑战赛数据集isic 2017,数据集包括原始的皮肤镜图像和对应的分割蒙版;分割蒙版是由专业的皮肤科医生手动标注的二值图像,其中病灶区域的像素值被标注为1,健康的皮肤区域的像素值被标注为0;数据集已被事先划分为三部分:2000对训练样本作为训练集,150对训练样本作为验证集,600对训练样本作为测试集;最后,对训练样本进行预处理操作:先利用双线性性插值的方式将所有的训练样本对缩放至分辨率为128
×
128,再将皮肤镜图像的像素值进行归一化,缩放到[0,1]区间。
[0014]
进一步,所述步骤2)包括以下内容:
[0015]
翻转操作具体是对训练集中预处理后的训练样本对分别做水平翻转和垂直翻转,得到通过翻转操作后的扩充样本对;
[0016]
旋转操作具体是对训练集中预处理后的训练样本对分别做90
°
、180
°
和270
°
的旋转操作,得到通过旋转操作后的扩充样本对;
[0017]
缩放操作具体是在训练集中抽取20%的预处理后的训练样本对,然后对每个训练样本对进行缩小25%和放大25%的操作,然后利用边界像素进行填充和裁剪边界像素的方法修正缩放后的训练样本对的分辨率,最后去除掉病灶区域位于图像边界区域的分割蒙版所在的训练样本对,其余图像为所需的扩充样本对;
[0018]
平移操作具体是在训练集中抽取20%的预处理后的训练样本对,通过随机分配,让每个训练样本对随机朝上、下、左、右中的某个方向移动20个像素,得到通过平移操作后的扩充样本对。
[0019]
进一步,在步骤3)中,编码器包含五个子模块,第一个子模块和第四个子模块都包含了两个3
×
3的常规卷积且第一个子模块在两次卷积后接一个2
×
2的最大池化,第三和第二个子模块由一个3
×
3的可变形卷积、一个3
×
3的常规卷积和一个2
×
2的最大池化构成,第五个子模块为denseconnectionblock,由五个卷积块构成,每个卷积块包含了一个3
×
3的常规卷积和1
×
1的常规卷积,且卷积块之间采用了密集连接;解码器包含五个子模块,前两个子模块包含一个上采样层、一个3
×
3的可变形卷积和一个3
×
3的常规卷积,第三个子模块包含一个上采样层和两个3
×
3的常规卷积,第四个子模块包含一个3
×
3的常规卷积和一个1
×
1的常规卷积,第五个子模块位于第二个子模块后作为监督分支,包含一个上采样层、一个3
×
3的常规卷积和一个1
×
1的常规卷积;其中,跳过连接将编码器输出的特征图经过attentionblock模块利用权重值重采样,然后与解码器的上采样层输出的同分辨率特征图连接,作为解码器后续操作的输入;attentionblock模块中包含通道注意力模块和空间
注意力模块,前者以通道为维度生成权重值,后者以空间为维度生成权重值。
[0020]
进一步,在步骤4)中,注意力网络的解码器中的第四和第五子模块输出的特征图,分别经过sigmoid函数得到两张病灶区域的分布概率图,与分割蒙版经过二元交叉熵计算得到损失,再通过adam优化器和第五子模块的分割概率图:第四子模块的分割概率图为0.7∶0.3的加权损失和来优化网络参数;在网络训练过程中采用了动态学习率,每5个训练迭代之后输入验证集验证网络的训练效果,训练完成的条件为5次连续的验证集对应的损失之和不再下降。
[0021]
进一步,在步骤5)中,将测试集中的皮肤镜图像输入到训练完成的网络中,得到对应的病灶区域概率图,设定阈值为0.5,将病灶区域概率图中大于0.5的值改为255,小于等于0.5的值改为0,最终得到皮肤镜图像对应的分割结果图。
[0022]
本发明的第二目的通过下述技术方案实现:基于可变形卷积的注意力网络的皮肤镜图像分割系统,包括:
[0023]
数据准备模块,用于收集皮肤镜图像作为训练样本,并划分有训练集、验证集和测试集,再进行预处理操作;其中,完整的一对训练样本包括原始的皮肤镜图像和对应的分割蒙版;再使用翻转、旋转、缩放和平移的方法对预处理后的训练样本进行数据扩充;
[0024]
网络构建模块,用于构建基于可变形卷积的注意力网络,该注意力网络为端到端的编码器-解码器结构,编码器使用了可变形卷积并设计了密集卷积块以得到更丰富的语义特征,解码器设计了监督分支以帮助分割蒙版的重建,此外还在跳过连接部分设计了注意力模块帮助不同层级的特征融合;
[0025]
网络训练模块,用于训练基于可变形卷积的注意力网络,将经过数据扩充后的训练样本中皮肤镜图像分批送入基于可变形卷积的注意力网络,再将解码器和监督分支输出的特征图经过sigmoid函数分别得到病灶区域概率图,再通过二元交叉熵损失与对应分割蒙版各自计算两部分的损失,按照解码器最后一层与监督分支设定的比例的权重相加得到总损失,最后基于总损失和自适应矩估计优化器调整网络参数,迭代进行至计算的总损失达到最小的状态;
[0026]
分割结果生成模块,用于生成分割结果图,将测试集中的皮肤镜图像输入到训练完成的网络中,得到对应的病灶区域概率图,将概率图中大于阈值的值改为255,小于等于阈值的值改为0,最终得到皮肤镜图像对应的分割结果图。
[0027]
进一步,在数据准备模块中,收集的训练样本来源于国际皮肤公开挑战赛数据集isic 2017,数据集包括原始的皮肤镜图像和对应的分割蒙版;分割蒙版是由专业的皮肤科医生手动标注的二值图像,其中病灶区域的像素值被标注为1,健康的皮肤区域的像素值被标注为0;数据集已被事先划分为三部分:2000对训练样本作为训练集,150对训练样本作为验证集,600对训练样本作为测试集;最后,对训练样本进行预处理操作:先利用双线性性插值的方式将所有的训练样本对缩放至分辨率为128
×
128,再将皮肤镜图像的像素值进行归一化,缩放到[0,1]区间;
[0028]
对预处理后的训练样本进行数据扩充,包括以下内容:
[0029]
翻转操作具体是对训练集中预处理后的训练样本对分别做水平翻转和垂直翻转,得到通过翻转操作后的扩充样本对;
[0030]
旋转操作具体是对训练集中预处理后的训练样本对分别做90
°
、180
°
和270
°
的旋
转操作,得到通过旋转操作后的扩充样本对;
[0031]
缩放操作具体是在训练集中抽取20%的预处理后的训练样本对,然后对每个训练样本对进行缩小25%和放大25%的操作,然后利用边界像素进行填充和裁剪边界像素的方法修正缩放后的训练样本对的分辨率,最后去除掉病灶区域位于图像边界区域的分割蒙版所在的训练样本对,其余图像为所需的扩充样本对;
[0032]
平移操作具体是在训练集中抽取20%的预处理后的训练样本对,通过随机分配,让每个训练样本对随机朝上、下、左、右中的某个方向移动20个像素,得到通过平移操作后的扩充样本对。
[0033]
进一步,在网络构建模块中,编码器包含五个子模块,第一个子模块和第四个子模块都包含了两个3
×
3的常规卷积且第一个子模块在两次卷积后接一个2
×
2的最大池化,第三和第二个子模块由一个3
×
3的可变形卷积、一个3
×
3的常规卷积和一个2
×
2的最大池化构成,第五个子模块为denseconnectionblock,由五个卷积块构成,每个卷积块包含了一个3
×
3的常规卷积和1
×
1的常规卷积,且卷积块之间采用了密集连接;解码器包含五个子模块,前两个子模块包含一个上采样层、一个3
×
3的可变形卷积和一个3
×
3的常规卷积,第三个子模块包含一个上采样层和两个3
×
3的常规卷积,第四个子模块包含一个3
×
3的常规卷积和一个1
×
1的常规卷积,第五个子模块位于第二个子模块后作为监督分支,包含一个上采样层、一个3
×
3的常规卷积和一个1
×
1的常规卷积;其中,跳过连接将编码器输出的特征图经过attentionblock模块利用权重值重采样,然后与解码器的上采样层输出的同分辨率特征图连接,作为解码器后续操作的输入;attentionblock模块中包含通道注意力模块和空间注意力模块,前者以通道为维度生成权重值,后者以空间为维度生成权重值。
[0034]
进一步,在网络训练模块中,注意力网络的解码器中的第四和第五子模块输出的特征图,分别经过sigmoid函数得到两张病灶区域的分布概率图,与分割蒙版经过二元交叉熵计算得到损失,再通过adam优化器和第五子模块的分割概率图:第四子模块的分割概率图为0.7∶0.3的加权损失和来优化网络参数;在网络训练过程中采用了动态学习率,每5个训练迭代之后输入验证集验证网络的训练效果,训练完成的条件为5次连续的验证集对应的损失之和不再下降。
[0035]
本发明与现有技术相比,具有如下优点与有益效果:
[0036]
1、本发明采用了可变形卷积,能对形状不规则且尺度变化大的皮肤病灶做自适应的特征提取,突破常规卷积操作中卷积核固定方形的限制,提升了卷积过程中特征提取的完整性,确保模型同时兼顾不规则的小目标和大目标的分割。
[0037]
2、本发明与其它基于深度学习的皮肤镜图像分割网络相比,在网络的较深层设计了带有密集连接的特征提取块,在加强了网络特征提取,丰富语义信息提升分割准确性的同时,一定程度上解决了深度学习模型常出现的过拟合问题。
[0038]
3、本发明中设计了注意力模块,保留了特征图中的重要低级特征信息尤其是边缘特征信息,解决了现有技术中常见的病灶边缘分割不准确的问题。
[0039]
4、本发明在皮肤癌诊断任务中具有广泛的使用空间,操作简单、适应性强、分割速度快,具有广阔的应用前景。
附图说明
[0040]
图1为注意力网络的结构示意图。
[0041]
图2为denseconnectionblock模块的结构示意图。
[0042]
图3为attentionblock模块的结构示意图。
[0043]
图4为本发明系统的架构图。
具体实施方式
[0044]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0045]
实施例1
[0046]
本实施例在keras深度学习框架下实现,计算机配置采用:intel core i5 6600k处理器,16gb内存,nvidia geforce gtx1080显卡,linux操作系统。本实施例公开了一种基于可变形卷积的注意力网络的皮肤镜图像分割方法,包括以下步骤:
[0047]
1)收集用于网络训练的皮肤镜图像作为训练样本,并进行预处理操作,其中完整的一对训练样本包括原始的皮肤镜图像和对应的分割蒙版。收集的训练样本来源于国际皮肤公开挑战赛数据集(isic 2017),数据集包括原始的皮肤镜图像和对应的分割蒙版,且数据集已被事先划分为三部分:2000对训练样本作为训练集,150对训练样本作为验证集,600对训练样本作为测试集。为了方便后续网络的训练,我们将所有的原始皮肤镜图像由rgb图像转换为灰度图像,另外利用双线性插值将皮肤镜图像和对应的分割蒙版缩放到统一的128x128的分辨率。最后,使用min-max标准化,对样本数据进行线性变换,是像素值归一化到[0,1]区间,方便后续的网络训练。
[0048]
2)使用缩放、旋转、翻转和平移的方法对预处理后的训练样本进行数据扩充,包括以下内容:
[0049]
翻转操作具体是对训练集中的预处理后的训练样本对分别做水平翻转和垂直翻转,得到通过翻转操作后的扩充样本对;
[0050]
旋转操作具体是对训练集中的预处理后的训练样本对分别做90
°
、180
°
和270
°
的旋转操作,得到通过旋转操作后的扩充样本对;
[0051]
缩放操作具体是在训练集中抽取20%的预处理后的训练样本对,然后对每个训练样本对进行缩小25%和放大25%的操作,然后利用边界像素进行填充和裁剪边界像素的方法修正缩放后的训练样本对的分辨率,最后去除掉病灶区域位于图像边界区域的分割蒙版所在的训练样本对,其余图像为所需的扩充样本对;
[0052]
平移操作具体是在训练集中抽取20%的预处理后的训练样本对,通过随机分配,让每个训练样本对随机朝上、下、左、右中的某个方向移动20个像素,得到通过平移操作后的扩充样本对。
[0053]
3)构建基于可变形卷积的注意力网络,网络结构见图1所示,该网络为一个u型结构,可以分为编码器(左侧)和解码器(右侧)两部分。编码器部分通过不断地卷积和下采样操作提取皮肤镜图像中的特征信息,解码器部分可以通过转秩卷积和上采样在恢复分辨率的同时对每个像素值进行病灶区域/健康皮肤区域的二分类。网络的各部分具体结构如下:
[0054]
编码器包括五个子模块,第一个子模块和第四个子模块都包含了两个3
×
3的常规
卷积且第四个子模块在两次卷积后接一个2
×
2的最大池化,第三和第二个子模块由一个3
×
3的可变形卷积、一个3
×
3的常规卷积和一个2
×
2的最大池化构成,第五个子模块为denseconnectionblock。denseconnectionblock模块的结构见图2所示,该模块由五个卷积块构成,每个卷积块包含了一个3
×
3的常规卷积和1
×
1的常规卷积,卷积块之间采用了密集连接将该卷积块之前的所有卷积块的输出特征图以通道维度为轴进行串联,作为当前卷积块的输入特征图,在加强特征提取的同时减少参数冗余,避免深层网络中常出现的梯度消失的问题。另外,卷积块中的1
×
1的常规卷积操作是为了避免串联后的特征图通道数量过多,使后续的3
×
3的常规卷积操作消耗大量的计算和内存资源,因而通过该卷积操作将输入特征图的通道数固定为512。
[0055]
解码器包含了五个子模块,前两个子模块包含了一个上采样层、一个3
×
3的可变形卷积和一个3
×
3的常规卷积,第三个子模块包含了一个上采样层和两个3
×
3的常规卷积,第四个子模块包含了一个3
×
3的常规卷积和一个1
×
1的常规卷积,第五个子模块位于第二个子模块后作为监督分支,包含了一个上采样层、一个3
×
3的常规卷积和一个1
×
1的常规卷积。其中,跳过连接将编码器输出的特征图经过attentionblock模块利用权重值重采样,在突出重要特征信息的同时边缘化特征图中的噪声(如伪影相关的特征信息),然后重采样后的特征图与解码器的上采样层输出的同分辨率特征图以通道轴为维度串联,作为解码器后续操作的输入。attentionblock模块的结构见图3所示,输入的特征图(h
×w×
c,其中h、w、c分别为高度、宽度和通道数)首先经过3
×
3的常规卷积,然后经过基于高度和宽度的两个维度的全局平均池化操作,得到1
×1×
c的特征图。将该特征图送入到层数为2的多层感知机中,第一层的神经元数量为c/2,第二层的神经元数量为c。多层感知机输出的特征图通过sigmoid激活函数得到的基于通道的注意力权重图w1。然后将w1与前面经过3
×
3常规卷积后的特征图做点乘操作得到加权后的特征图,该特征图与输入特征图做按点加和(element-sum)操作得到新的特征图。新特征图通过三个平行的1
×
1的常规卷积,其中两个卷积操作将特征图的通道维度变为c/4,一个卷积操作将特征图的通道维度变为c。然后通过reshape操作将三个特征图从三维变为二维,高度和宽度合并为一个维度。然后通过transpose对通道维度为c/4的其中一个特征图做转置后,与另一个通道维度为c/4的特征图做矩阵相乘的操作,接着经过softmax激活函数得到基于空间的注意力权重图w2。最后,w2与之间经过按点加和操作后的特征图进行矩阵乘法,得到最终的结合了通道注意力和空间注意力的特征图。
[0056]
4)训练基于可变形卷积的注意力网络,将经过数据扩充后的训练样本中皮肤镜图像分批送入基于可变形卷积的注意力网络,再将解码器和监督分支输出的特征图经过sigmoid函数分别得到病灶区域概率图,再通过二元交叉熵损失与对应分割蒙版各自计算两部分的损失,按照解码器最后一层:监督分支为0.7∶0.3的权重相加得到总损失,最后基于总损失和自适应矩估计优化器调整网络参数,具体操作是:解码器中的第四和第五子模块输出的特征图,分别经过sigmoid函数得到两张病灶区域的分布概率图,与分割蒙版经过二元交叉熵计算得到损失,再通过adam优化器和第五子模块的分割概率图:第四子模块的分割概率图为0.7∶0.3的加权损失和来优化网络参数。
[0057]
网络训练过程中采用了动态学习率,每5个训练迭代之后输入验证集验证网络的训练效果,训练完成的条件为5次连续的验证集对应的损失之和不再下降。
[0058]
5)生成分割结果图:将测试集中的皮肤镜图像输入到训练完成的网络中,得到对应的病灶区域概率图,,设定阈值为0.5,将病灶区域概率图中大于0.5的值改为255,小于等于0.5的值改为0,最终得到网络预测的分割结果图。
[0059]
实施例2
[0060]
参见图4所示,本实施例公开了一种基于可变形卷积的注意力网络的皮肤镜图像分割系统,包括以下功能模块:
[0061]
数据准备模块,用于收集皮肤镜图像作为训练样本,并划分有训练集、验证集和测试集,再进行预处理操作;其中,完整的一对训练样本包括原始的皮肤镜图像和对应的分割蒙版;再使用翻转、旋转、缩放和平移的方法对预处理后的训练样本进行数据扩充。
[0062]
网络构建模块,用于构建基于可变形卷积的注意力网络,该注意力网络为端到端的编码器-解码器结构,编码器使用了可变形卷积并设计了密集卷积块以得到更丰富的语义特征,解码器设计了监督分支以帮助分割蒙版的重建,此外还在跳过连接部分设计了注意力模块帮助不同层级的特征融合。
[0063]
网络训练模块,用于训练基于可变形卷积的注意力网络,将经过数据扩充后的训练样本中皮肤镜图像分批送入基于可变形卷积的注意力网络,再将解码器和监督分支输出的特征图经过sigmoid函数分别得到病灶区域概率图,再通过二元交叉熵损失与对应分割蒙版各自计算两部分的损失,按照解码器最后一层与监督分支设定的比例的权重相加得到总损失,最后基于总损失和自适应矩估计优化器调整网络参数,迭代进行至计算的总损失达到最小的状态。
[0064]
分割结果生成模块,用于生成分割结果图,将测试集中的皮肤镜图像输入到训练完成的网络中,得到对应的病灶区域概率图,首先设定阈值为0.5,将病灶区域概率图中大于0.5的值改为255,小于等于0.5的值改为0,最终得到皮肤镜图像对应的分割结果图。
[0065]
优选的,在数据准备模块中,收集用于网络训练的皮肤镜图像作为训练样本,并进行预处理操作,其中完整的一对训练样本包括原始的皮肤镜图像和对应的分割蒙版。收集的训练样本来源于国际皮肤公开挑战赛数据集(isic 2017),数据集包括原始的皮肤镜图像和对应的分割蒙版,且数据集已被事先划分为三部分:2000对训练样本作为训练集,150对训练样本作为验证集,600对训练样本作为测试集。为了方便后续网络的训练,我们将所有的原始皮肤镜图像由rgb图像转换为灰度图像,另外利用双线性插值将皮肤镜图像和对应的分割蒙版缩放到统一的128x128的分辨率。最后,使用min-max标准化,对样本数据进行线性变换,是像素值归一化到[0,1]区间,方便后续的网络训练。
[0066]
使用翻转、旋转、缩放和平移的方法对预处理后的训练样本进行数据扩充,数据扩充的具体方法包括:
[0067]
翻转操作具体是对训练集中的预处理后的训练样本对分别做水平翻转和垂直翻转,得到通过翻转操作后的扩充样本对;
[0068]
旋转操作具体是对训练集中的预处理后的训练样本对分别做90
°
、180
°
和270
°
的旋转操作,得到通过旋转操作后的扩充样本对;
[0069]
缩放操作具体是在训练集中抽取20%的预处理后的训练样本对,然后对每个训练样本对进行缩小25%和放大25%的操作,然后利用边界像素进行填充和裁剪边界像素的方法修正缩放后的训练样本对的分辨率,最后去除掉病灶区域位于图像边界区域的分割蒙版
所在的训练样本对,其余图像为所需的扩充样本对;
[0070]
平移操作具体是在训练集中抽取20%的预处理后的训练样本对,通过随机分配,让每个训练样本对随机朝上、下、左、右中的某个方向移动20个像素,得到通过平移操作后的扩充样本对。
[0071]
优选的,在网络构建模块中,构建基于可变形卷积的注意力网络,网络结构见图1所示,该网络为一个u型结构,可以分为编码器(左侧)和解码器(右侧)两部分。编码器部分通过不断地卷积和下采样操作提取皮肤镜图像中的特征信息,解码器部分可以通过转秩卷积和上采样在恢复分辨率的同时对每个像素值进行病灶区域/健康皮肤区域的二分类。网络的各部分具体结构如下:
[0072]
编码器包括五个子模块,第一个子模块和第四个子模块都包含了两个3
×
3的常规卷积且第四个子模块在两次卷积后接一个2
×
2的最大池化,第三和第二个子模块由一个3
×
3的可变形卷积、一个3
×
3的常规卷积和一个2
×
2的最大池化构成,第五个子模块为denseconnectionblock。denseconnectionblock模块的结构见图2所示,该模块由五个卷积块构成,每个卷积块包含了一个3
×
3的常规卷积和1
×
1的常规卷积,卷积块之间采用了密集连接将该卷积块之前的所有卷积块的输出特征图以通道维度为轴进行串联,作为当前卷积块的输入特征图,在加强特征提取的同时减少参数冗余,避免深层网络中常出现的梯度消失的问题。另外,卷积块中的1
×
1的常规卷积操作是为了避免串联后的特征图通道数量过多,使后续的3
×
3的常规卷积操作消耗大量的计算和内存资源,因而通过该卷积操作将输入特征图的通道数固定为512。
[0073]
解码器包含了五个子模块,前两个子模块包含了一个上采样层、一个3
×
3的可变形卷积和一个3
×
3的常规卷积,第三个子模块包含了一个上采样层和两个3
×
3的常规卷积,第四个子模块包含了一个3
×
3的常规卷积和一个1
×
1的常规卷积,第五个子模块位于第二个子模块后作为监督分支,包含了一个上采样层、一个3
×
3的常规卷积和一个1
×
1的常规卷积。其中,跳过连接将编码器输出的特征图经过attentionblock模块利用权重值重采样,在突出重要特征信息的同时边缘化特征图中的噪声(如伪影相关的特征信息),然后重采样后的特征图与解码器的上采样层输出的同分辨率特征图以通道轴为维度串联,作为解码器后续操作的输入。attentionblock模块的结构见图3所示,输入的特征图(h
×w×
c,其中h、w、c分别为高度、宽度和通道数)首先经过3
×
3的常规卷积,然后经过基于高度和宽度的两个维度的全局平均池化操作,得到1
×1×
c的特征图。将该特征图送入到层数为2的多层感知机中,第一层的神经元数量为c/2,第二层的神经元数量为c。多层感知机输出的特征图通过sigmoid激活函数得到的基于通道的注意力权重图w1。然后将w1与前面经过3
×
3常规卷积后的特征图做点乘操作得到加权后的特征图,该特征图与输入特征图做按点加和(element-sum)操作得到新的特征图。新特征图通过三个平行的1
×
1的常规卷积,其中两个卷积操作将特征图的通道维度变为c/4,一个卷积操作将特征图的通道维度变为c。然后通过reshape操作将三个特征图从三维变为二维,高度和宽度合并为一个维度。然后通过transpose对通道维度为c/4的其中一个特征图做转置后,与另一个通道维度为c/4的特征图做矩阵相乘的操作,接着经过softmax激活函数得到基于空间的注意力权重图w2。最后,w2与之间经过按点加和操作后的特征图进行矩阵乘法,得到最终的结合了通道注意力和空间注意力的特征图。
[0074]
优选的,在网络训练模块中,注意力网络的解码器中的第四和第五子模块输出的特征图,分别经过sigmoid函数得到两张病灶区域的分布概率图,与分割蒙版经过二元交叉熵计算得到损失,再通过adam优化器和第五子模块的分割概率图:第四子模块的分割概率图为0.7∶0.3的加权损失和来优化网络参数;在网络训练过程中采用了动态学习率,每5个训练迭代之后输入验证集验证网络的训练效果,训练完成的条件为5次连续的验证集对应的损失之和不再下降。
[0075]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1