一种摘要视频的生成方法、存储介质、电子装置与流程
比例的句子,所述第二类句子是指所述其余分组中其余句子中的剩余句子;
13.基于所述第一类句子生成对应的问题和答案,基于所述第二类句子生成第一文本和 第二文本;
14.在所述摘要视频中显示所述问题、所述第一文本、所述第二文本和/或所述答案。
15.在一种实现方式中,所述获取目标文本中每个句子的重要度包括:
16.将所述每个句子转化为句向量;
17.计算所述每个句子的句向量与所述目标文本中其余句子的句向量之间的余弦值,得 到所述每个句子与所述目标文本中其余句子之间的相似度;
18.计算所述每个句子与所述目标文本中其余句子之间的相似度的加权平均值,得到所 述每个句子的重要度。
19.在一种实现方式中,在所述获取目标文本中每个句子的重要度之前还包括:
20.识别所述目标文本中的指定符号;
21.以所述指定符号将所述目标文本划分为多个句子。
22.在一种实现方式中,所述摘要文本中属于所述排序最高的一个分组的句子的数量大 于属于所述其余分组的句子的数量。
23.在一种实现方式中,所述基于所述第一类句子生成对应的问题和答案,基于所述第 二类句子生成第一文本和第二文本包括:
24.采用随机性解码生成所述答案和所述第一文本,采用确定性解码生成所述问题和所 述第二文本。
25.删除所述第二文本。
26.在一种实现方式中,所述采用随机性解码生成所述答案和所述第一文本,采用确定 性解码生成所述问题和所述第二文本包括:
27.分别计算每一组所述问题与所述答案的第一相似度、每一组所述第一文本与所述第 二文本的第二相似度;
28.基于所述第一相似度和所述第二相似度,按照指定筛选比例保留所述问题、所述答 案、所述第一文本和所述第二文本,其中,所述指定筛选比例是指所保留的所述第一文 本和所述第二文本的组数大于所述问题和所述答案的组数。
29.在本技术的一个实施例中,还提出了一种弹幕显示方法,在上述任一项方法实施例 的摘要视频中,通过预设的虚拟形象播放所述答案。
30.在本技术的一个实施例中,还提出了一种计算机可读的存储介质,所述存储介质中 存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项方法实施例 中的步骤。
31.在本技术的一个实施例中,还提出了一种电子装置,包括存储器和处理器,所述存 储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项 方法实施例中的步骤。
32.通过本技术实施例,可以基于目标文本生成与目标视频对应的摘要视频,以通过该 摘要视频来展示目标视频的主要视频内容,以令用户可以通过观看该摘要视频,快速掌 握目标视频的主要视频内容。并且在展示摘要视频时,显示基于目标文本生成的弹幕, 令用户可以在观看摘要视频时,享受弹幕体验。解决了相关技术中用户无法快速掌握视 频的
主要内容,以及由于无其它用户输入的文本所形成的弹幕,导致用户观看视频的体 验感不佳的问题。
附图说明
33.为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单 地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下, 还可以根据这些附图获得其他的附图。
34.图1是现有弹幕生成方法的交互示意图;
35.图2是根据本技术实施例的一种可选的摘要视频的生成方法的流程图;
36.图3是根据本技术实施例的一种可选的划分句子的方法流程图;
37.图4是根据本技术实施例的一种可选的计算句子重要度的方法流程图;
38.图5是根据本技术实施例的一种可选的弹幕素材筛选的方法流程图;
39.图6是根据本技术实施例的一种可选的生成弹幕的方法流程图;
40.图7是根据本技术实施例的一种可选的在摘要视频上显示弹幕的示意图;
41.图8是根据本技术实施例的一种可选的摘要视频生成装置的结构示意图;
42.图9是根据本技术实施例的一种可选的摘要视频生成装置的结构示意图;
43.图10是根据本技术实施例的一种可选的电子装置结构示意图。
具体实施方式
44.下文中将参考附图并结合实施例来详细说明本技术。需要说明的是,在不冲突的情 况下,本技术中的实施例及实施例中的特征可以相互组合。
45.需要说明的是,本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二
”ꢀ
等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。
46.视频创作者基于目标文本a,将相应的视频素材合成一个目标视频a,通过目标视频 a可以更加生动地展示目标文本a的文本内容,视频创作者将目标视频a发布至网站上 供用户观看。用户1如果想要了解目标文本a的内容,需要观看完整的目标视频a,示 例地,如果目标视频a的总时长为2小时,则用户1至少花费2小时观看完整的目标视 频a,才能够通过了解目标视频a的全部视频内容,以了解目标文本a的内容。而且用 户1在观看目标视频a时,如果用户1是第一个观看目标视频a的用户,或者,如果在 用户1观看目标视频a之前,用户2观看过目标视频a,但是,用户2并未向目标视频a 输入文本,则用户1所观看的目标视频a如图1中
①
所示,仅展示目标视频a的视频内 容(与目标文本a对应的文本内容),不带有弹幕。用户1在观看目标视频a的过程中, 向目标视频a输入文本a1,该文本a1可以是用户1对于目标视频a的观点,以此实现 用户1与目标视频a之间的交互。相应的,目标视频a上将生成与文本a1对应的弹幕。 如果用户3在用户1之后观看目标视频a,此时用户3所观看的目标视频a如图1中
②
所 示,不仅展示目标视频a的视频内容(与目标文本a对应的文本内容),还显示弹幕(文 本a1)。用户3通过浏览弹幕,可以了解其他用户(用户1)对目标视频a的观点,以实 现用户3与其他用户(用户1)之间的交互,而且,用户3可以通过该弹幕快速掌握与 目标视频a相关的信息,令观看更具有指向性。
47.上述场景中,用户1不仅需要花费大量的时间来观看完整的目标视频a,以了解全
部 视频内容,而且用户1可能由于目标视频a的视频内容较为丰富、复杂等原因,无法准 确掌握目标视频a的主要视频内容。同时,由于用户1所观看的目标视频a不带有弹幕, 则用户1将无法享受弹幕体验,导致用户1观看目标视频a的体验感较差。为了解决上 述问题,如图2所示,本技术实施例提供了一种摘要视频生成方法,该摘要视频包括目 标视频的主要视频内容,进而可以通过展示摘要视频以快速展示目标视频的主要视频内 容,具体过程如下:
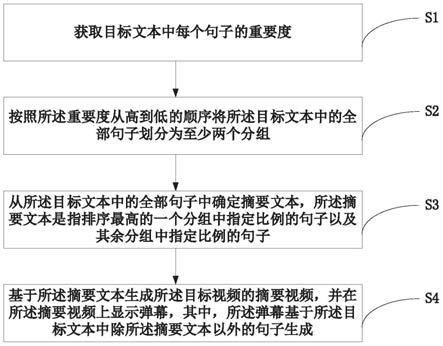
48.s1、获取目标文本中每个句子的重要度,所述目标文本是指用于合成目标视频的文 本,所述重要度是指所述每个句子与所述目标文本中其余句子的相似度的加权平均值。
49.在本实施例中,目标文本是视频创作者设定的文本,其对应生成的视频为目标视频, 其中,目标文本的文本内容与目标视频的视频内容一致,以使得通过播放目标视频可以 展示目标文本的文本内容,令目标文本更加具象化,易于用户理解。
50.在本实施例中,句子的重要度用于反映一个句子与其所在文本中其余句子之间的关 联程度,一个句子与其余句子之间的关联程度越高,可以认为该句子是其余句子的中心, 即重要度越高,其中,句子之间的关联程度可以用句子相似度来表示,即两个句子越相 似,说明两个句子关联程度越高,反之,两个句子越不相似,说明两个句子关联程度越 低。由此,句子的重要度可以用该句子与其所在文本中其余句子之间的相似度来表示。 具体的,每个句子的重要度满足公式(1):
[0051][0052]
其中,impi代表目标文本中第i个句子的重要度,n代表目标文本共有n个句子,sim
ij
代表目标文本中第i个句子与其余句子之间的相似度。
[0053]
在本实施例中,在计算每个句子的重要度之前,首先确定目标文本中的n个句子,如图 3所示,本技术实施例提供了一种划分句子的方法,包括:
[0054]
s01、识别所述目标文本中的指定符号。
[0055]
s02、以所述指定符号将所述目标文本划分为多个句子。
[0056]
示例地,指定符号相当于句子划分的分割点,可以设定为“。”、“;”、“!”、“?
”ꢀ
等标点符号,也可以设定为“1、2、3、...”、“一、二、三、...”等序号,在本实施例中不 对指定符号做出限制,只需要保证相邻两个指定符号之间的文本可以表示一个相对完整 的语义。识别到全部指定符号之后,以每个指定符号作为分割点划分目标文本,其中, 相邻两个指定符号之间的文本为划分后的一个句子,目标文本的第一个字符与第一个指 定符号之间的文本为一个句子,目标文本的最后一个指定符号与目标文本的最后一个字 符之间的文本为一个句子。
[0057]
在一些实施例中,上述将目标文本划分为n个句子的过程可以通过模型完成。示例 地,该模型的预训练过程可以为:将海量文本素材作为输入,每个文本素材包含至少两 个句子,且每个句子之间存在指定符号,将每个句子作为输出,以此将该模型训练为可 以识别文本中指定符号,并按照该指定符号划分句子的模型。
[0058]
由上文所示的方法获得n个句子之后,基于每个句子的句向量,计算每个句子与其 余句子之间的相似度,如图4所示,具体如下:
[0059]
s11、将所述每个句子转化为句向量。
[0060]
通过将句子转化为句向量,并基于句向量计算句子之间相似度的方式,可以将句子 量化,以有效提高句子相似度的计算准确性。可以通过相应的模型将n个句子分别转化 为句向量,示例地,该模型可以采用word2vec、glove、bert等。
[0061]
s12、计算所述每个句子的句向量与所述目标文本中其余句子的句向量之间的余弦值 和物理距离,得到所述每个句子与所述目标文本中其余句子之间的相似度。
[0062]
在本实施例中,为了保证每个句子与其余句子之间的相似度的计算准确性,可以通 过综合计算句子之间的余弦值以及句子之间的物理距离获得每个句子与其余句子之间的相 似度,即公式(1)中的sim
ij
满足公式(2):
[0063]
sim
ij
=sim
ij
*pos
ij
ꢀꢀ
(2)
[0064]
其中,sim
ij
表示第i个句子与第j个句子之间的余弦值,pos
ij
表示第i个句子与第j个 句子之间的物理距离。
[0065]
其中,sim
ii
满足公式(3):
[0066]
sim
ij
=cos(vi,yj)
ꢀꢀꢀꢀ
(3)
[0067]
其中,vi表示第i个句子的句向量,vj表示第j个句子的句向量。
[0068]
pos
ij
满足公式(4):
[0069][0070]
其中,d
ij
表示第i个句子与第j个句子之间的物理距离,n表示目标文本中所有的句子 数量,将第i个句子与第j个句子之间的物理距离除以所有的句子数量n作为最终使用的物理 距离,可以弱化物理距离所带来的影响,尤其降低物理距离较近的句子对第i个句子的重要 度的影响程度。
[0071]
s13、计算所述每个句子与所述目标文本中其余句子之间的相似度的加权平均值,得 到所述每个句子的重要度。
[0072]
整理公式(1)、(2)、(3)、(4),可以得到每个句子与目标文本中其余句子之间的相 似度满足公式(5):
[0073][0074]
基于上述过程,可以准确计算得到目标文本中每个句子的重要度。
[0075]
s2、按照所述重要度从高到低的顺序将所述目标文本中的全部句子划分为至少两个 分组。
[0076]
由上文对句子的重要度的描述可知,句子的重要度越高,表示该句子与其余句子的 关联程度越高,该句子越能够代表其余句子的主要内容,相应的,可以认为句子的重要 度越高,其越能够反映所在文本的主要内容。摘要视频必须包括目标视频的主要视频内 容,即摘要视频的视频内容必须与目标文本的主要文本内容对应,而且句子的重要度可 以反映其与文本的主要内容的关联性,因此,可以基于句子的重要度,确定用于生成摘 要视频的文本。由此,可以按照目标文本中各句子的重要度对各句子进行排序,以便于 准确确定可以用于生成摘要视频的目标句子。
[0077]
按照句子的重要度,可以首先将n个句子大致划分为至少两个分组,即至少一个重 要度较高的分组和一个重要度较低的分组。也可以根据实际需求,将n个句子细分为更 多的分组,例如五个分组。重要度较高的分组内各分句可以代表目标文本最主要的文本 内
影响,从而保证所确定的摘要文本可以反映文本内容的重要程度。
[0085]
在一些实施例中,为了保证摘要视频可以更多地反映目标视频的主要视频内容,避 免所展示的视频内容的重点偏移,需要保证摘要文本中重要度较高的句子的数量大于重 要度较低的句子的数量,即保证摘要文本中属于排序最高的一个分组的句子的数量大于 属于其余分组的句子的数量。
[0086]
s4、基于所述摘要文本生成所述目标视频的摘要视频,并在所述摘要视频上显示弹 幕,其中,所述弹幕基于所述目标文本中除所述摘要文本以外的文本生成。
[0087]
基于上述过程确定的摘要文本,生成对应的视频,即摘要视频。通过播放该摘要视 频可以展示目标视频的主要视频内容。同时,为了增加用户与摘要视频之间的互动,在 摘要视频上显示弹幕,这些弹幕基于目标文本中除摘要文本以外的文本生成,无需基于 用户输入的文本生成。由此,用户可以通过观看摘要视频,快速了解目标视频的主要视 频内容,从而引发观看目标视频的兴趣。同时,即使在用户观看摘要视频之前,无其它 用户对该摘要视频输入文本,以形成相应的弹幕,也可以基于目标文本直接生成弹幕, 并在该用户观看摘要视频时,将这些弹幕显示于摘要视频上,以保证用户可以享受弹幕 体验。进一步地,由于弹幕是基于摘要文本以外的文本生成的,由此,用户可以通过观 看摘要视频快速掌握目标视频的大部分视频内容,同时,可以通过浏览弹幕快速掌握目 标视频的其余视频内容,并通过弹幕的强交互性,进一步激发用户对观看目标视频的兴 趣。
[0088]
对基于目标文本中除摘要文本以外的句子生成弹幕的过程做出相应描述,可以参考 图5,具体过程如下:
[0089]
s41、将所述目标文本中除所述摘要文本以外的句子划分为第一类句子和第二类句子, 所述第一类句子为问答式弹幕素材,所述第二类句子为评论式弹幕素材,其中,所述第 一类句子是指所述排序最高的一个分组中的其余句子以及所述其余分组中其余句子中指 定比例的句子,所述第二类句子是指所述其余分组中其余句子中的剩余句子。
[0090]
在本实施例中,在摘要视频中直接携带弹幕,该弹幕反映目标视频的视频内容。目 标视频中的主要视频内容已经通过摘要视频展示出来,无需再通过弹幕重复展示,只需 要通过弹幕展示目标视频中的其余视频内容即可,该部分内容通过弹幕进行轻量展示, 可以避免展示过于细节的视频内容,也可以通过弹幕的形式加强与用户的交互。
[0091]
通过上述分析可知,将目标文本中除摘要文本以外的句子作为生成弹幕的弹幕素材, 弹幕可以分为两类,即问答式弹幕和评论式弹幕。在本实施例中,问答式弹幕具有实质 的内容,例如句子为“今天是晴天”,则问答式弹幕为“问题:今天是什么天气?”,“答案: 晴天。”,评论式弹幕不具有实质的内容,通常代表情绪,例如句子为“张飞在战场上飞 奔杀敌”,则评论式弹幕为“哇!”,“真厉害!”等。通过问答式弹幕可以向用户传递目标 视频的具体视频内容,例如通过问答式弹幕“问题:今天是什么天气?”,“答案:晴天。”, 用户就可以知道目标视频一定与天气相关,而且,通过问答的形式,可以引发用户的思 考,提高用户对目标视频的注意力。通过评论式弹幕可以向用户传递与目标视频的视频 内容相关的情绪,令用户可以掌握该目标视频的情感基调和所要传达的精神,例如通过 评论式弹幕“哇!”,“真厉害!”,用户就可以知道目标视频所要传达的情绪是兴奋,可 以引导用户的观看情绪,引起用户的情感共鸣,从而提高用户的体验感。
[0092]
在本实施例中,将用于生成问答式弹幕的句子称为第一类句子,这些第一类句子
将 作为生成问答式弹幕的素材,将用于生成评论式弹幕的句子称为第二类句子,这些第二 类句子将作为生成评论式弹幕的素材。由上文对问答式弹幕和评论式弹幕的描述可知, 相较于评论式弹幕,问答式弹幕更加能够反映目标视频的视频内容,更加重要,基于此, 将重要度较高的句子作为第一类句子,将重要度较低的句子作为第二类句子。
[0093]
在一些实施例中,可以将排序最高的一个分组中的其余句子均作为第一类句子,以 保证问答式弹幕素材具有较高的重要度,从而令问答式弹幕可以准确且完整的反映目标 文本中未被展示于摘要视频中的主要文本内容。同时,将其余分组中其余句子中指定比 例的句子也作为第一类句子,以保证问答式弹幕素材具有较高的全面性,从而令问答式 弹幕也可以反映目标文本中未被展示与摘要视频中的其它文本内容。在本实施例中的指 定比例与上文中用于筛选摘要文本所公开的指定比例无关。在一种实现方式中,指定比 例可以是每一次选取句子时针对当前未被选取的句子所述的比例,指定比例也可以是始 终针对全部句子所述的比例。将其余分组中的剩余句子均作为第二类句子,以生成评论 式弹幕。
[0094]
示例地,将50个句子划分为五个分组,即按照重要度排序依次为a、b、c、d、e 组,且每个分组均包括10个句子。将重要度最高的a组中指定比例(如80%)的句子 (即8个句子)作为摘要文本,将b组中指定比例(如20%)的句子(即2个句子)也 作为摘要文本。将a组中其余句子(即剩余的2个句子)作为第一类句子,将b组的其 余句子中指定比例(如50%)的句子(即4个句子)也作为第一类句子。将b组中的剩 余句子(即4个句子),以及c、d、e组中的全部句子(即30个句子)均作为第二类句 子。
[0095]
在一些实施例中,针对从其余分组中选取第一类句子的过程,可以按照句子在目标 文本中的位置来进行选取。首先,从其余分组中其余句子中选取指定比例的句子作为第 一类句子,在本实施例中,将这部分句子称为基准句。然后,确定这些基准句在目标文 本中的段落。最后,以每一个基准句为起点,在该基准句所在段落中,将位于该基准句 之后指定数量的句子也作为第一类句子,并将全部句子中未被选取的剩余句子作为第二 类句子。采用此方式选取的第一类句子可以跨越不同的分组,令第一类句子所对应的文 本内容也具较高的全面性。同时,也可以令所选取的第一类句子具有较近的物理距离。 在一些实施例中,也可以同时将排序最高的一组中其余句子作为基准句,来筛选第一类 句子。
[0096]
示例地,将50个句子划分为五个分组,即按照重要度排序依次为a、b、c、d、e 组,且每个分组均包括10个句子。将重要度最高的a组中指定比例(如80%)的句子 (即8个句子)作为摘要文本,将b组中指定比例(如20%)的句子(即2个句子)也 作为摘要文本。将a组中其余句子(即剩余的2个句子)作为第一类句子,将b组的其 余句子中指定比例(如50%)的句子(即4个句子)也作为第一类句子。同时,将这4 个句子作为基准句,分别确定其所在的段落,并选取每个基准句之后指定数量(如2个) 句子也作为第一类句子。例如,第一个句子所在段落中的后2个句子恰好属于c组,第 二个句子所在段落中的后2个句子恰好属于b组,第三个句子所在段落中的后2个句子 恰好属于d组,第四个句子所在段落中的后2个句子恰好属于d组。将b组中的剩余句 子(即2个句子)、c组中的剩余句子(即8个句子)、d组中的剩余句子(即6个句子)、 以及e组中的剩余句子(即10个句子)作为第二类句子。
[0097]
s42、基于所述第一类句子生成对应的问题和答案,基于所述第二类句子生成第一文 本和第二文本。
[0098]
基于s41确定的第一类句子,生成问答式弹幕,基于s41确定的第二类句子,生成 评论式弹幕。其中,基于每一个第一类句子生成两个文本,即问题和答案,且问题与答 案相对应,基于每一个第二类句子生成两个文本,即第一文本和第二文本,且第一文本 与第二文本表示相同的情绪。
[0099]
在一些实施例中,可以采用相应的模型生成问题和答案,以及第一文本和第二文本, 示例地,采用统一预训练语言模型(unified pre-trained language model,unilm),其中, unilm模型基于双向编码转换表示器(bidirectional encoder representations fromtransformers,bert)修改获得。首先,采用第一类弹幕素材样本(弹幕素材+该弹幕素 材对应的问题和答案),以及第二类弹幕素材样本(弹幕素材+该弹幕素材对应的第一文 本和第二文本)预训练unilm模型。针对第一类弹幕素材样本预训练的过程进行说明, 第一类弹幕素材样本为“输入:句子a;输出:问题a+答案a”,通过bert模型对该第 一类弹幕素材样本进行标注和拼接,得到“[cls]句子a[sep]答案a[sep]问题a[sep]”, 通过unilm模型按照特殊方式(using different self-attention mask)执行序列到序列 (sequence-to-sequence,seq2seq)任务,其中,输入部分的attention为双向,输出部分 的attention为单向,各第一类弹幕素材样本按照如上过程对模型进行预训练。针对第二 类弹幕素材样本预训练的过程进行说明,第二类弹幕素材样本为“输入:句子b;输出: 第一文本b+第二文本b”,通过unilm模型对该第二类弹幕素材样本进行标注和拼接, 得到“[cls]句子b[sep]第二文本b[sep]第一文本b[sep]”,通过unilm模型按照特殊方 式(using different self-attention mask)执行seq2seq任务,其中,输入部分的attention 为双向,输出部分的attention为单向,各第二类弹幕素材样本按照如上过程对模型进行 预训练。预训练得到的unilm模型在使用时,输入弹幕素材(第一类句子和第二类句子), 输出问题和答案,以及第一文本和第二文本,从而得到最终显示于目标视频上的弹幕。
[0100]
通过上述unilm模型可以对第一类句子与第二类句子进行自动分类,即计算p(答 案,问题|第一类句子)和p(第二文本,第一文本|第二类句子),从而准确、快速地 获得各类弹幕。
[0101]
在一些实施例中,为了保证问答式弹幕中答案和评论式弹幕的多样性,同时保证问 答式弹幕中问题和评论式弹幕的情绪的确定性,因此,在解码过程中,使用确定性解码 生成问题和第二文本(第二文本用于确定情绪),使用随机解码生成答案和第一文本。示 例地,确定性解码选用beam_search策略,随机解码选用random_search策略。
[0102]
进一步地,由于第二文本缺乏多样性,因此,可以删除第二文本,只保留第一文本 作为最终的评论式弹幕。
[0103]
在一些实施例中,为了控制问答式弹幕与评论式弹幕的数量比例,可以控制预训练 unilm模型的弹幕素材样本的数据比例,并同时修改解码策略,可以参考图6所示的流 程,具体如下:
[0104]
s4211、分别计算每一组所述问题与所述答案的第一相似度、每一组所述第一文本与 所述第二文本的第二相似度。
[0105]
在random_search策略中比较生成的两个文本的相似度,即比较同一组的问题与答案 的相似度(第一相似度),同一组的第一文本与第二文本的相似度(第二相似度),示例 地,可以通过计算两个文本的余弦值得到文本之间的相似度。通常,答案与问题之间的 相
似度较高,第一文本与第二文本之间的相似度较低,因此,通过相似度可以区分两个 文本是问题和答案,还是第一文本和第二文本。
[0106]
s4212、基于所述第一相似度和所述第二相似度,按照指定筛选比例保留所述问题、 所述答案、所述第一文本和所述第二文本,其中,所述指定筛选比例是指所保留的所述 第一文本和所述第二文本的组数大于所述问题和所述答案的组数。
[0107]
在本实施例中,可以按照实际需求设置指定的筛选比例,例如,为了提高用户对目 标视频的注意力,可以提高问题和答案的指定筛选比例,以保留更多的问答式弹幕。又 如,为了提高用户对目标视频的兴趣,可以提高第一文本和第二文本的指定筛选比例, 以保留更多的评论式弹幕。再如,针对于上文从评论式弹幕中删除第二文本的场景,为 了均衡问答式弹幕与评论式弹幕的数量,可以进一步提高第一文本和第二文本的指定筛 选比例,以保证第一文本的数量与问题和答案的总数量均衡。
[0108]
对基于摘要文本生成摘要视频的过程进行描述。
[0109]
在本实施例中,如果摘要文本包括多个事件,则首先基于事件将摘要文本划分为多 个子文本,并针对每个子文本确定用于合成摘要视频的视频素材。为了便于描述,本实 施例中以摘要文本只对应一个事件为例进行说明。
[0110]
首先确定摘要文本对应的领域,即目标文本对应的领域。在本实施例中,不同的文 本对应不同的领域,例如按照文学题材划分,则可以分为诗词领域、小说领域、音乐领 域、电影领域等。又如,按照文本名称划分,则可以分为三国演义领域、红楼梦领域、 西游记领域、水浒传领域等。每个领域都有其对应的类别信息,其中,领域中较为重要 的文本内容所属的类别为核心类别,领域中其它文本内容所属的类别为非核心类别。基 于领域的类别信息,可以将目标文本划分为两类文本内容,即对应于核心类别的核心文 本和对应于非核心类别的非核心文本。
[0111]
在本实施例中,可以采用提取模型提取摘要文本中的核心文本和非核心文本。在一 些实施例中,可以采用命名实体识别(named entity recognition,ner)模型识别并提 取摘要文本中的第一文本,ner模型可以为bert、blstm、crf模型等,ner模型可 以识别到摘要文本中与核心类别对应的实体名词,并将所提取到的实体名词作为核心文 本。进一步地,为了提高ner模型所提取的核心文本的准确度,可以根据领域对应的领 域词表来修正所提取到的实体名词,以得到最终的核心文本。其中,领域词表包含该领 域内与核心类别对应的全部文本内容。例如,可以通过爬取等方式,从该领域对应的全 部文本素材中提取与核心类别对应的词语。通过匹配ner所提取的实体名词与领域词表 中的各个词语,确定错误实体名词,判断错误实体名词的错误类型,其中,如果错误类 型为部分错误,则将错误实体名词替换为领域词表中对应的词语;如果错误类型为全部 错误,则将错误实体名词剔除。在一些实施例中,上述修正过程可以通过ner模型完成, 此时的ner模型为训练为带有修正功能的实体名词识别模型。
[0112]
在一些实施例中,可以采用分类模型识别并提取摘要文本中与非核心类别对应的非 核心文本,分类模型可以为blstm、cnn模型等,分类模型可以通过分类算法对摘要 文本所描述的事件、情绪等进行分类,以确定与摘要文本对应的分类标签(分类模型中 预先训练的标签,例如与“事件”类别对应的分类标签包括“骑马”、“打仗”、“谈话”等,与
ꢀ“
情绪”类别对应的分类标签包括“开心”、“不开心”、“愤怒”等),即非核心文本。
[0113]
此外,还需要获取摘要文本的文本摘要,在本实施例中,文本摘要是指摘要文本中 可以代表摘要文本的语义的一个或多个句子,这些句子构成的向量与摘要文本的向量之 间的相似度符合向量相似度阈值,示例地,摘要文本为“刘备、关羽、张飞在桃园结义, 三人虽为异姓,既结为兄弟,则同心协力,救困扶危,上报国家,下安黎庶。”其中,最 能够代表摘要文本的语义的一个句子为“刘备、关羽、张飞在桃园结义”,则该摘要文本 的文本摘要为“刘备、关羽、张飞在桃园结义”。
[0114]
通过上述过程,视频合成器可以自动、准确地获得摘要文本的核心文本、非核心文 本以及文本摘要。
[0115]
获取领域对应的视频素材库,视频素材库包括多个视频素材,其中,每个视频素材 具有相应的标签和描述文本。其中,标签通常为词语形式,一个视频素材可以具有一个 或多个标签,每个视频素材的标签均经过消歧处理(如通过比较各个视频素材的内容相 似度,将内容相似度大于或者等于阈值的视频素材所对应的标签统一为同一组标签,以 及将各个视频素材对应的标签中复现数量较少的标签剔除,和/或,通过比较同一个视频 素材对应的各个标签之间的相似度,将相似度过高的多个标签统一为同一个标签等),以 保证每个视频素材的标签的准确性,以及精简性。描述文本通常为短句形式,一个视频 素材可以具有一个或多个描述文本,每个描述文本的字符数量相对较长,描述文本包括 多个词语,通过多个词语的词义,以每个词语在短句中对应的句子成分,由该多个词语 共同完成对视频素材的视频内容的整体描述。
[0116]
根据核心文本与每个视频素材的标签的文本相似度、非核心文本与每个视频素材的 标签的概率相似度、以及文本摘要与每个视频素材的描述文本的句子相似度,从视频素 材库中提取用于生成摘要视频的目标视频素材。具体过程如下:
[0117]
首先,计算核心文本与各视频素材的文本相似度,将文本相似度高于预设相似度阈 值的视频素材确定为候选视频素材。
[0118]
然后,计算非核心文本与各候选视频素材的标签的概率相似度。示例地,非核心文 本为“战场”,通过分类模型可以得到非核心文本被分类到分类标签“战场”、“户外”和“室 内”的概率分别为0.857、0.143、0,视频素材1带有标签“战场”,视频素材2带有标签“户 外”,视频素材3带有标签“室内”,相应的,非核心文本与视频素材1的标签的概率相似 度为0.857,非核心文本与视频素材2的标签的概率相似度为0.143,非核心文本与视频 素材3的标签的概率相似度为0。
[0119]
再计算文本摘要与各候选视频素材的描述文本的句子相似度。具体地,生成与候选 视频素材的描述文本对应的第一句向量,以及与文本摘要对应的第二句向量,通过计算 第一句向量与第二句向量之间的余弦相似度,得到描述文本与文本摘要之间的句子相似 度。示例地,候选视频素材的描述文本为“张飞在战场上骑马杀敌”,文本摘要为“张飞在 战场上骑马飞奔”,通过计算两者的句子相似度,如果句子相似度大于或者等于相似度阈 值,则说明该候选视频素材可以较为准确地反应摘要文本的整体文本内容。
[0120]
为了提高核心文本、非核心文本、文本摘要之间的关联性,可以综合计算匹配度、 概率相似度和句子相似度,以得到摘要文本与候选视频素材之间的内容匹配度。
[0121]
将上述过程得到的核心文本和非核心文本相关联,可以共同计算得到摘要文本与候 选视频素材的第一相似度。具体的,第一相似度满足如下公式:a1=xa*score(a)+xb*
score (b),其中,a1代表第一相似度,score(a)代表核心文本与候选视频素材的标签之间 的占比,score(a)满足公式score(a)=k1*c/a+k2*c/b,其中,a表示摘要文本中出 现核心文本的总数量,b表示候选视频素材的标签中出现与核心类别对应的标签的总数 量,c表示摘要文本的核心文本与候选视频素材的标签中出现与核心类别对应的标签的 交集数量,k1和k2为系数,且k1+k2=1,可以根据实际侧重点设定k1与k2的数值,例 如,更加侧重体现摘要文本,则可以设定k1>k2,如果更加侧重体现候选视频素材,则 可以设定k1<k2。score(b)代表每个非核心文本被归类到候选视频素材的标签中相应 非核心类别的标签的概率,xa和xb分别为与score(a)和score(b)对应的权重值,xa 和xb的值可以根据需要自行设定,但是需要保证xa+xb=1。
[0122]
进一步地,将核心文本、非核心文本和文本摘要相关联,可以共同计算得到摘要文 本与候选视频素材的第二相似度,即摘要文本与候选视频素材的内容匹配度。具体的, 第二相似度满足如下公式:a2=q1*a1+q2*p3,其中,a2代表第二相似度(内容匹配度), a1代表第一相似度,p3代表文本摘要与描述文本的句子相似度,q1和q2分别为与a1 和p3对应的权重值,其中,q1+q2=1,0≤q1≤1,0≤q2≤1,权重值q1和q2可以自行设 定,例如,如果比较侧重于候选视频素材的细节信息,则可以设定q1>q2,如果比较侧 重于候选视频素材的整体信息,则可以设定q2>q1。相应的,设定内容匹配度阈值,如 果a3大于或者等于该内容匹配度阈值,则可以确定该候选视频素材为目标视频素材,否 则,该候选视频素材不是目标视频素材。
[0123]
将目标视频素材作为摘要视频。其中,如果摘要文本中包含多个子文本,则基于每 个子文本确定目标视频素材的过程可以参考上述过程,最后将所确定的全部目标视频素 材进行拼接,得到与摘要文本对应的摘要视频。基于上述过程获得的目标视频素材综合 考虑了摘要文本中对应不同内容类别的文本与视频素材的标签的匹配度,以及摘要文本 的文本摘要与视频素材的描述文本的匹配度,以确保所确定的目标视频素材与摘要文本 的内容准确对应。
[0124]
在一些实施例中,基于目标文本生成目标视频的过程可以参考上述基于摘要文本生 成摘要视频的过程,此处不再赘述。
[0125]
s43、在所述摘要视频中显示所述问题、所述第一文本、所述第二文本和/或所述答 案。
[0126]
将上述过程生成的摘要视频与弹幕进行合成,即在摘要视频中显示问答式弹幕中的 问题和答案,以及显示评论式弹幕中的第一文本和第二文本。示例地,可以将弹幕显示 于与相应弹幕素材对应的画面上,例如评论式弹幕“哇!”,其对应的弹幕素材为“张飞在 战场上飞奔杀敌”,与该弹幕素材相应的视频素材1的视频内容就是“张飞在战场上飞奔 杀敌”,则将“哇!”显示于视频素材1上。以此可以提高弹幕与视频内容的对应性,提高 弹幕所反映内容、情绪的准确性。对于问答式弹幕,为了给用户留出足够的思考时间, 可以将问题与答案分开显示,例如,可以将问题显示于与相应弹幕素材对应的画面上, 将答案显示于目标视频的最后一个视频素材之后的一个单独画面上。
[0127]
在上述摘要视频生成方法中,可以基于目标文本生成与目标视频对应的摘要视频, 以通过该摘要视频来展示目标视频的主要视频内容,以令用户可以通过观看该摘要视频, 快速掌握目标视频的主要视频内容。并且在展示摘要视频时,显示基于目标文本生成
的 弹幕,令用户可以在观看摘要视频时,享受弹幕体验。解决了相关技术中用户无法快速 掌握视频的主要内容,以及由于无其它用户输入的文本所形成的弹幕,导致用户观看视 频的体验感不佳的问题。
[0128]
实施例1
[0129]
目标文本为“刘备被吕布打败无处可去,刘备每日在住处后院种菜掩饰野心,刘备暗 中与国舅董承计划谋除曹操,曹操派人请刘备去赴宴。刘备与曹操青梅煮酒论英雄,曹 操问刘备当世谁能算得上英雄,刘备认为袁术袁绍刘表等人雄霸一方,曹操认为天下只 有刘备和曹操是真正的英雄。曹操讲述望梅止渴的故事,刘备被雷声吓掉筷子,曹操嘲 笑刘备胆小。”[0130]
指定符号为“,”和“。”,则以指定符号为分割点,可以将上述目标文本划分为11个 句子,即“刘备被吕布打败无处可去”,“刘备每日在住处后院种菜掩饰野心”,“刘备暗中 与国舅董承计划谋除曹操”,“曹操派人请刘备去赴宴”,“刘备与曹操青梅煮酒论英雄”,“曹 操问刘备当世谁能算得上英雄”,“刘备认为袁术袁绍刘表等人雄霸一方”,“曹操认为天 下只有刘备和曹操是真正的英雄”,“曹操讲述望梅止渴的故事”,“刘备被雷声吓掉筷子”,
ꢀ“
曹操嘲笑刘备胆小”。
[0131]
将每个句子转换为句向量,并计算每个句子与其余句子之间的相似度,得到每个句 子的重要度(计算公式参考公式(1)-(5))。基于句子的重要度将上述11个句子分为5 组,即a组包括:“刘备与曹操青梅煮酒论英雄”、“曹操问刘备当世谁能算得上英雄”、“曹 操认为天下只有刘备和曹操是真正的英雄”;b组包括:“刘备认为袁术袁绍刘表等人雄 霸一方”、“刘备被雷声吓掉筷子”、“曹操嘲笑刘备胆小”;c组包括:“刘备被吕布打败无 处可去”、“刘备暗中与国舅董承计划谋除曹操”、“刘备每日在住处后院种菜掩饰野心”; d组包括:“曹操派人请刘备去赴宴”;e组包括:“曹操讲述望梅止渴的故事”。
[0132]
从a组中选取2/3的句子,即“刘备与曹操青梅煮酒论英雄”和“曹操认为天下只有刘 备和曹操是真正的英雄”,以及从b组中选取1/3的句子,即“刘备被雷声吓掉筷子”作为 摘要文本。基于上述三个句子采用上文描述的目标视频素材的筛选过程,筛选出对应的 目标视频素材,并拼接所确定的目标视频素材,得到摘要视频。
[0133]
将a组中的其余句子,即“曹操问刘备当世谁能算得上英雄”,将b组中其余句子, 即“刘备认为袁术袁绍刘表等人雄霸一方”和“曹操嘲笑刘备胆小”作为第一类句子。将c 组的全部句子,即“刘备被吕布打败无处可去”、“刘备暗中与国舅董承计划谋除曹操”、“刘 备每日在住处后院种菜掩饰野心”,d组的全部句子,即“曹操派人请刘备去赴宴”,以及 e组的全部句子,即“曹操讲述望梅止渴的故事”,作为第二类句子。
[0134]
分别基于每一个第一类句子生成对应的问题和答案(问答式弹幕),并基于每一个第 二类句子生成对应的第一文本和第二文本(评论式弹幕)。
[0135]
采用unilm模型生成与第一类句子和第二类句子对应的弹幕文本,以第一类句子“曹 操问刘备当世谁能算得上英雄”为例,对生成问答式弹幕的过程进行说明,向unilm模 型输入“曹操问刘备当世谁能算得上英雄”,输出为“问题:曹操认为谁才是真正的英雄, 答案:刘备与曹操”;以第二类句子“刘备每日在住处后院种菜掩饰野心”为例,对生成评 论式弹幕的过程进行说明,向unilm模型输入“刘备每日在住处后院种菜掩饰野心”,输 出为“第一文本:机智,第二文本:真惨”。在输出第一文本和第二文本之前,还可以删 除第二文本,
类句子是指所述排序最高的一个分组中的其余句子以及所述其余分组中其余句子中指定 比例的句子,所述第二类句子是指所述其余分组中其余句子中的剩余句子;
[0147]
基于所述第一类句子生成对应的问题和答案,基于所述第二类句子生成第一文本和 第二文本;
[0148]
在所述摘要视频中显示所述问题、所述第一文本、所述第二文本和/或所述答案。
[0149]
在一个实施例中,所述重要度计算模块1被配置为:
[0150]
将所述每个句子转化为句向量;
[0151]
计算所述每个句子的句向量与所述目标文本中其余句子的句向量之间的余弦值,得 到所述每个句子与所述目标文本中其余句子之间的相似度;
[0152]
计算所述每个句子与所述目标文本中其余句子之间的相似度的加权平均值,得到所 述每个句子的重要度。
[0153]
在一个实施例中,如图9所示,所述摘要视频生成装置还包括句子划分模块5,其 中,所述句子划分模块5被配置为:
[0154]
识别所述目标文本中的指定符号;
[0155]
以所述指定符号将所述目标文本划分为多个句子。
[0156]
在一个实施例中,所述摘要文本中属于所述排序最高的一个分组的句子的数量大于 属于所述其余分组的句子的数量。
[0157]
在一个实施例中,所述摘要视频生成模块4被配置为:
[0158]
采用随机性解码生成所述答案和所述第一文本,采用确定性解码生成所述问题和所 述第二文本。
[0159]
删除所述第二文本。
[0160]
在一个实施例中,所述摘要视频生成模块4被配置为:
[0161]
分别计算每一组所述问题与所述答案的第一相似度、每一组所述第一文本与所述第 二文本的第二相似度;
[0162]
基于所述第一相似度和所述第二相似度,按照指定筛选比例保留所述问题、所述答 案、所述第一文本和所述第二文本,其中,所述指定筛选比例是指所保留的所述第一文 本和所述第二文本的组数大于所述问题和所述答案的组数。
[0163]
根据本技术实施例的又一个方面,还提供了一种用于实施上述摘要视频生成方法的 电子装置,上述电子装置可以但不限于应用于服务器中。如图10所示,该电子装置包括 存储器100和处理器200,该存储器100中存储有计算机程序,该处理器200被设置为 通过计算机程序执行上述任一项方法实施例中的步骤。
[0164]
可选地,在本实施例中,上述电子装置可以位于计算机网络的多个网络设备中的至 少一个网络设备。
[0165]
可选地,在本实施例中,上述处理器可以被设置为通过计算机程序执行以下步骤:
[0166]
s1、获取目标文本中每个句子的重要度,所述目标文本是指用于合成目标视频的文 本,所述重要度是指所述每个句子与所述目标文本中其余句子的相似度的加权平均值;
[0167]
s2、按照所述重要度从高到低的顺序将所述目标文本中的全部句子划分为至少两个 分组;
[0168]
s3、从所述目标文本中的全部句子中确定摘要文本,所述摘要文本是指排序最高
的 一个分组中指定比例的句子以及其余分组中指定比例的句子;
[0169]
s4、基于所述摘要文本生成所述目标视频的摘要视频,并在所述摘要视频上显示弹 幕,其中,所述弹幕基于所述目标文本中除所述摘要文本以外的句子生成。
[0170]
其中,执行s4的具体过程包括:
[0171]
s41、将所述目标文本中除所述摘要文本以外的句子划分为第一类句子和第二类句子, 所述第一类句子为问答式弹幕素材,所述第二类句子为评论式弹幕素材,其中,所述第 一类句子是指所述排序最高的一个分组中的其余句子以及所述其余分组中其余句子中指 定比例的句子,所述第二类句子是指所述其余分组中其余句子中的剩余句子;
[0172]
s42、基于所述第一类句子生成对应的问题和答案,基于所述第二类句子生成第一文 本和第二文本;
[0173]
s43、在所述摘要视频中显示所述问题、所述第一文本、所述第二文本和/或所述答 案。
[0174]
执行s1的具体过程包括:
[0175]
s11、将所述每个句子转化为句向量;
[0176]
s12、计算所述每个句子的句向量与所述目标文本中其余句子的句向量之间的余弦值, 得到所述每个句子与所述目标文本中其余句子之间的相似度;
[0177]
s13、计算所述每个句子与所述目标文本中其余句子之间的相似度的加权平均值,得 到所述每个句子的重要度。
[0178]
在执行s3之后得到的结果为:所述摘要文本中属于所述排序最高的一个分组的句子 的数量大于属于所述其余分组的句子的数量。
[0179]
执行s4的具体过程包括:
[0180]
s421、采用随机性解码生成所述答案和所述第一文本,采用确定性解码生成所述问 题和所述第二文本。
[0181]
s422、删除所述第二文本。
[0182]
执行s421的具体过程包括:
[0183]
s4211、分别计算每一组所述问题与所述答案的第一相似度、每一组所述第一文本与 所述第二文本的第二相似度;
[0184]
s4212、基于所述第一相似度和所述第二相似度,按照指定筛选比例保留所述问题、 所述答案、所述第一文本和所述第二文本,其中,所述指定筛选比例是指所保留的所述 第一文本和所述第二文本的组数大于所述问题和所述答案的组数。
[0185]
可选地,本领域普通技术人员可以理解,图10所示的结构仅为示意,电子装置也可 以是智能手机(如android手机、ios手机等)、平板电脑、掌上电脑以及移动互联网设 备(mobile internet devices,mid)、pad等终端设备。图10并不对上述电子装置的结 构造成限定。例如,电子装置还可包括比图10中所示更多或者更少的组件(如网络接口 等),或者具有与图10所示不同的配置。
[0186]
其中,存储器100可用于存储软件程序以及模块,如本技术实施例中的摘要视频的 生成方法和装置对应的程序指令/模块,处理器200通过运行存储在存储器100内的软件 程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的摘要视频的生成方 法。存储器100可包括高速随机存储器,还可以包括非易失性存储器,如一个或者多个 磁性存
储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器100可进 一步包括相对于处理器200远程设置的存储器,这些远程存储器可以通过网络连接至终 端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。 其中,存储器100具体可以但不限于用于储存弹幕生成方法的程序步骤。
[0187]
可选地,实现上述网络连接功能的传输装置300用于经由一个网络接收或者发送数 据。上述的网络具体实例可包括有线网络及无线网络。在一个实例中,传输装置300包 括一个网络适配器(network interface controller,nic),其可通过网线与其他网络设备 与路由器相连从而可与互联网或局域网进行通讯。在一个实例中,传输装置300为射频 (radio frequency,rf)模块,其用于通过无线方式与互联网进行通讯。
[0188]
此外,上述电子装置还包括:显示器400,用于显示上述摘要视频;和连接总线500, 用于连接上述电子装置中的各个模块部件。
[0189]
本技术的实施例还提供了一种计算机可读的存储介质,该存储介质中存储有计算机 程序,其中,该计算机程序被设置为运行时执行上述任一项摘要视频的生成方法实施例 中的步骤。
[0190]
可选地,在本实施例中,上述存储介质可以被设置为存储用于执行以下步骤的计算 机程序:
[0191]
s1、获取目标文本中每个句子的重要度,所述目标文本是指用于合成目标视频的文 本,所述重要度是指所述每个句子与所述目标文本中其余句子的相似度的加权平均值;
[0192]
s2、按照所述重要度从高到低的顺序将所述目标文本中的全部句子划分为至少两个 分组;
[0193]
s3、从所述目标文本中的全部句子中确定摘要文本,所述摘要文本是指排序最高的 一个分组中指定比例的句子以及其余分组中指定比例的句子;
[0194]
s4、基于所述摘要文本生成所述目标视频的摘要视频,并在所述摘要视频上显示弹 幕,其中,所述弹幕基于所述目标文本中除所述摘要文本以外的句子生成。
[0195]
上述存储介质可以被设置为存储用于执行如下具体步骤的计算机程序:
[0196]
s41、将所述目标文本中除所述摘要文本以外的句子划分为第一类句子和第二类句子, 所述第一类句子为问答式弹幕素材,所述第二类句子为评论式弹幕素材,其中,所述第 一类句子是指所述排序最高的一个分组中的其余句子以及所述其余分组中其余句子中指 定比例的句子,所述第二类句子是指所述其余分组中其余句子中的剩余句子;
[0197]
s42、基于所述第一类句子生成对应的问题和答案,基于所述第二类句子生成第一文 本和第二文本;
[0198]
s43、在所述摘要视频中显示所述问题、所述第一文本、所述第二文本和/或所述答 案。
[0199]
上述存储介质可以被设置为存储用于执行如下具体步骤的计算机程序:
[0200]
s11、将所述每个句子转化为句向量;
[0201]
s12、计算所述每个句子的句向量与所述目标文本中其余句子的句向量之间的余弦值, 得到所述每个句子与所述目标文本中其余句子之间的相似度;
[0202]
s13、计算所述每个句子与所述目标文本中其余句子之间的相似度的加权平均值,得 到所述每个句子的重要度。
[0203]
上述存储介质可以被设置为存储用于执行如下具体步骤的计算机程序:
[0204]
在所述s1之前还执行如下步骤:
[0205]
s01、识别所述目标文本中的指定符号;
[0206]
s02、以所述指定符号将所述目标文本划分为多个句子。
[0207]
其中,上述存储介质可以被设置为存储用于执行如下具体步骤的计算机程序:
[0208]
s421、采用随机性解码生成所述答案和所述第一文本,采用确定性解码生成所述问 题和所述第二文本。
[0209]
s422、删除所述第二文本。
[0210]
上述存储介质可以被设置为存储用于执行如下具体步骤的计算机程序:
[0211]
s4211、分别计算每一组所述问题与所述答案的第一相似度、每一组所述第一文本与 所述第二文本的第二相似度;
[0212]
s4212、基于所述第一相似度和所述第二相似度,按照指定筛选比例保留所述问题、 所述答案、所述第一文本和所述第二文本,其中,所述指定筛选比例是指所保留的所述 第一文本和所述第二文本的组数大于所述问题和所述答案的组数。
[0213]
可选地,存储介质还被设置为存储用于执行上述实施例中的方法中所包括的步骤的 计算机程序,本实施例中对此不再赘述。
[0214]
可选地,在本实施例中,本领域普通技术人员可以理解上述实施例的各种方法中的 全部或部分步骤是可以通过程序来指令终端设备相关的硬件来完成,该程序可以存储于 一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read-only memory, rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
[0215]
上述本技术实施例序号仅仅为了描述,不代表实施例的优劣。
[0216]
上述实施例中的集成的单元如果以软件功能单元的形式实现并作为独立的产品销售 或使用时,可以存储在上述计算机可读取的存储介质中。基于这样的理解,本技术的技 术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软 件产品的形式体现出来,该计算机软件产品存储在存储介质中,包括若干指令用以使得 一台或多台计算机设备(可为个人计算机、服务器或者网络设备等)执行本技术各个实 施例所述方法的全部或部分步骤。
[0217]
在本技术的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详 述的部分,可以参见其他实施例的相关描述。
[0218]
在本技术所提供的几个实施例中,应该理解到,所揭露的客户端,可通过其它的方 式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅 为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结 合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨 论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦 合或通信连接,可以是电性或其它的形式。
[0219]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示 的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个 网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的 目的。
[0220]
另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是 各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单 元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0221]
以上所述仅是本技术的优选实施方式,应当指出,对于本技术领域的普通技术人员 来说,在不脱离本技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也 应视为本技术的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1