一种跨数据规模的配置参数的调优方法、装置及电子设备
本发明属于参数调优,特别涉及一种跨数据规模的配置参数的调优方法、装置及电子设备。
背景技术:
1、近年来,随着互联网技术的快速发展,大数据得到了越来越多的应用。为了快速处理大数据,加州大学伯克利分校的amp实验室设计了spark大数据系统通用并行框架。它使用bsd开源许可,并于2013年被捐赠给了apache软件基金会。spark涵盖各种负载,如批处理程序、用户交互式程序、迭代算法等。它扩展了mapreduce模型,通过内存集群计算,大大减少了磁盘的读/写操作,从而大幅提升了数据处理速度。
2、spark框架在运行过程中性能会受到配置参数的影响。为了满足在不同场景下的使用需求,spark框架将大量的配置参数,甚至多达240个,暴露给终端用户。由于应用程序的特性不同,在程序运行过程中如果使用默认参数,在很多情况下会限制系统的性能,无法充分使用系统资源。这其中最大的挑战就是为spark程序选择一组合适的配置参数来缩短spark程序的运行时间。因此人们提出了自动配置参数调优方法。该类参数调优方法首先通过收集不同参数下的运行时间,然后运行人工智能等方法对配置参数和运行时间的关系进行训练,从而得到性能模型。在对新数据进行处理时,通过搜索性能模型得到合适的配置,从而达到优化配置参数的目的。
3、现有的spark自动配置参数调优方法需要收集大量的不同配置参数下的运行时间(通常需要运行数百组至数千组数据),然后使用这些原始数据进行训练。由于在使用较差配置参数时程序的运行时间非常长(较差配置参数和较优配置参数的运行时间可以相差高达三十倍),导致在创建训练集时需要的时间成本非常高。在原有的数据规模下,使用上述的人工智能方法的时间成本已经很高了。
4、在真实的生产环境中,往往都是spark程序固定,即业务代码不变,但每天处理的是不同的数据。这些spark程序以连续不断的方式连续得运行,每次运行处理的是不同的数据。但是根据目前的观察发现,配置参数的选取和所处理的数据规模有很大的联系。目前关于解决不同数据规模时,搜索相应的最优配置参数的解决方案是:在新的数据规模下,使用上述的人工智能等方法对配置参数和运行时间的关系重新进行训练,从而得到性能模型,时间成本的开销非常大,是难以接受的。
技术实现思路
1、本说明书实施例的目的是提供一种跨数据规模的配置参数的调优方法、装置及电子设备。
2、为解决上述技术问题,本技术实施例通过以下方式实现的:
3、第一方面,本技术提供一种跨数据规模的配置参数的调优方法,该方法包括:
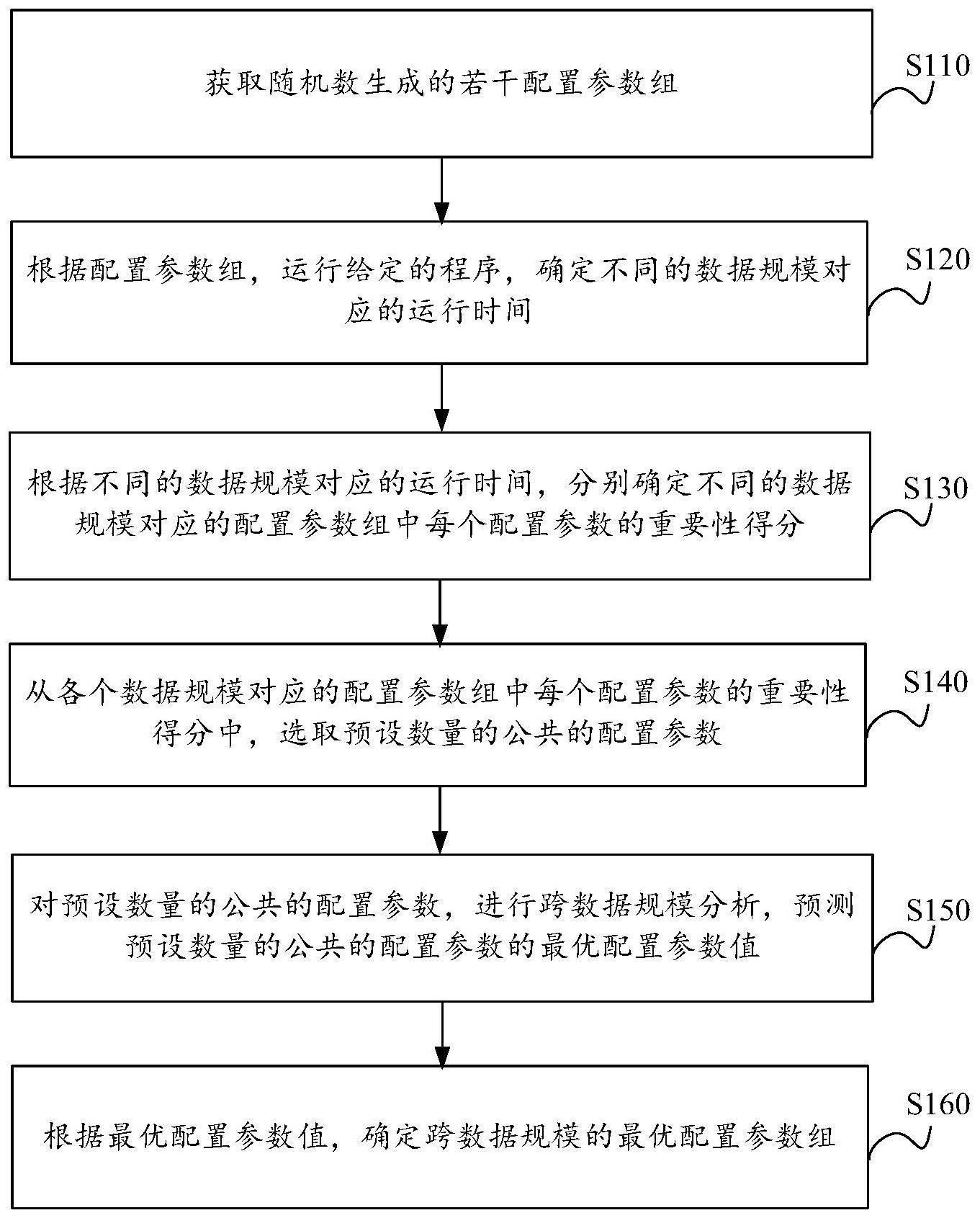
4、获取随机数生成的若干配置参数组,配置参数组包括若干配置参数;
5、根据配置参数组,运行给定的程序,确定不同的数据规模对应的运行时间;
6、根据不同的数据规模对应的运行时间,分别确定不同的数据规模对应的配置参数组中每个配置参数的重要性得分;
7、从各个数据规模对应的配置参数组中每个配置参数的重要性得分中,选取预设数量的公共的配置参数;
8、对预设数量的公共的配置参数,进行跨数据规模分析,预测预设数量的公共的配置参数的最优配置参数值;
9、根据最优配置参数值,确定跨数据规模的最优配置参数组。
10、在其中一个实施例中,获取随机数生成的配置参数组,包括:
11、获取配置参数组中每个配置参数的取值范围;
12、根据每个配置参数的取值范围,生成各个配置参数。
13、在其中一个实施例中,配置参数的类型包括:布尔型参数、类别型参数、连续型参数。
14、在其中一个实施例中,数据规模的范围为[最小数据规模,最大数据规模],其中,最大数据规模为最小数据规模的预设倍数。
15、在其中一个实施例中,根据不同的数据规模对应的运行时间,分别确定不同的数据规模对应的配置参数组中每个配置参数的重要性得分,包括:
16、将每个数据规模对应的配置参数组及运行时间,输入随机梯度增强回归树,得到对应数据规模的配置参数组中每个配置参数的重要性得分。
17、在其中一个实施例中,配置参数组包括非硬件型资源参数;
18、从各个数据规模对应的配置参数组中每个配置参数的重要性得分中,选取预设数量的公共的配置参数,包括:
19、从各个数据规模对应的配置参数组中每个配置参数的重要性得分中,选取预设数量的公共的非硬件资源型参数。
20、在其中一个实施例中,对预设数量的公共的配置参数,进行跨数据规模分析,预测预设数量的公共的配置参数的最优配置参数值,包括:
21、获取当前数据规模中配置参数组中最长的运行时间、最短的运行时间及每个配置参数组对应的运行时间;
22、根据最长的运行时间、最短的运行时间及每个配置参数组对应的运行时间,确定每个配置参数组对应的运行得分;
23、将每个配置参数组对应的运行得分作为配置参数组中每个配置参数的运行得分;
24、将对应的数据规模、配置参数的运行得分、配置参数的参数值,输入至线性回归模型,得到在当前数据规模下、运行得分最高时配置参数的取值,作为配置参数的最优配置参数值。
25、在其中一个实施例中,根据最优配置参数值,确定跨数据规模的最优配置参数组,包括:
26、获取预设数量的公共的配置参数之外的参数值;
27、求每个非公共的配置参数的参数值的平均值;
28、将平均值作为对应的各个非公共的配置参数的最优配置参数值;
29、根据非公共的配置参数的最优配置参数值和公共的配置参数的最优配置参数值,确定跨数据规模的最优配置参数组。
30、第二方面,本技术提供一种跨数据规模的配置参数的调优装置,该装置包括:
31、获取模块,用于获取随机数生成的若干配置参数组,配置参数组包括若干配置参数;
32、第一确定模块,用于根据配置参数组,运行给定的程序,确定不同的数据规模对应的运行时间;
33、第二确定模块,用于根据不同的数据规模对应的运行时间,分别确定不同的数据规模对应的配置参数组中每个配置参数的重要性得分;
34、选取模块,用于从各个数据规模对应的配置参数组中每个配置参数的重要性得分中,选取预设数量的公共的配置参数;
35、预测模块,用于对预设数量的公共的配置参数,进行跨数据规模分析,预测预设数量的公共的配置参数的最优配置参数值;
36、第三确定模块,用于根据最优配置参数值,确定跨数据规模的最优配置参数组。
37、第三方面,本技术提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现如第一方面的跨数据规模的配置参数的调优方法。
38、由以上本说明书实施例提供的技术方案可见,该方案:通过小数据规模情况下的最优配置参数迁移得到大数据规下的最优配置,可以有效地减少新数据规模下参数调优的时间。
- 还没有人留言评论。精彩留言会获得点赞!