一种基于Spark的分布式数据库存储直连查询分析方法与流程
一种基于spark的分布式数据库存储直连查询分析方法
技术领域
1.本发明公开一种方法,涉及数据存储技术领域,具体地说是一种基于spark的分布式数据库存储直连查询分析方法。
背景技术:
2.目前数据库主要分为两类:oltp(online transactional processing),侧重处理在线事务请求,对一致性和实时性要求高;另一种是olap(online analytical processing),测试大数据量下的分析处理。为了面对各种需求,oltp、olap在技术上分道扬镳,在很多企业架构中,这两类任务处理由不同团队完成。一般需要通过etl(extract-transform-load),将数据从oltp数据库中经过抽取、转换、加载到olap数据库进行分析,导致数据一般会有几分钟甚至几小时的延迟,而且etl过程运维成本高,容易出现问题。
技术实现要素:
3.本发明针对现有技术的问题,提供一种基于spark的分布式数据库存储直连查询分析方法,可以在不影响分布式数据库oltp性能的情况下,直连其中的分布式存储进行数据分析。整个过程没有etl,避免在传统架构中,oltp与olap数据库之间大量的数据交互。
4.本发明提出的具体方案是:
5.一种基于spark的分布式数据库存储直连查询分析方法,基于spark,根据元数据分布并发查询读取分布式数据库存储里的数据,根据查询读取结果解析为spark可识别的数据字段,组装成spark的rdd,并将计算处理逻辑传递至分布式数据库存储上用于数据分析,
6.同时基于spark,根据rdd中的数据组装成键值对,根据键值对支持事务一致性并发写入分布式数据库存储。
7.进一步,所述的一种基于spark的分布式数据库存储直连查询分析方法中所述基于spark,根据元数据分布并发查询读取分布式数据库存储里的数据,包括:
8.基于spark,向分布式数据库的网关节点发送元数据请求,
9.获取元数据查询表的数据存储信息,
10.根据数据存储信息获得元数据分布,发起查询读取数据的请求。
11.进一步,所述的一种基于spark的分布式数据库存储直连查询分析方法中所述支持事务一致性并发写入分布式数据库存储,包括:
12.基于spark,提交写入任务,请求分布式数据库开启新事务,并获得所述新事务id,
13.根据rdd中数据的键值对和所述新事务id再次提交所述新事务,完成写入任务。
14.进一步,所述的一种基于spark的分布式数据库存储直连查询分析方法中所述写入任务中断或失败,则被分布式数据库清理,并设置所述写入任务中产生的数据对外不可见。
15.进一步,所述的一种基于spark的分布式数据库存储直连查询分析方法中通过分
布式数据库根据地区部署对应的spark集群,基于所述spark集群,仅查询读取本地区的数据或指定优先读写的地区的数据。
16.一种基于spark的分布式数据库存储直连查询分析系统,包括查询及读取模块、rdd组装模块、逻辑传递模块、键值对组装模块及写入模块,
17.查询及读取模块基于spark,根据元数据分布并发查询读取分布式数据库存储里的数据,rdd组装模块根据查询读取结果解析为spark可识别的数据字段,组装成spark的rdd,逻辑传递模块将计算处理逻辑传递至分布式数据库存储上用于数据分析,
18.键值对组装模块基于spark,根据rdd中的数据组装成键值对,写入模块根据键值对支持事务一致性并发写入分布式数据库存储。
19.进一步,所述的一种基于spark的分布式数据库存储直连查询分析系统中所述查询及读取模块基于spark,根据元数据分布并发查询读取分布式数据库存储里的数据,包括:
20.基于spark,向分布式数据库的网关节点发送元数据请求,
21.获取元数据查询表的数据存储信息,
22.根据数据存储信息获得元数据分布,发起查询读取数据的请求。
23.进一步,所述的一种基于spark的分布式数据库存储直连查询分析系统中所述写入模块支持事务一致性并发写入分布式数据库存储,包括:
24.基于spark,提交写入任务,请求分布式数据库开启新事务,并获得所述新事务id,
25.根据rdd中数据的键值对和所述新事务id再次提交所述新事务,完成写入任务。
26.进一步,所述的一种基于spark的分布式数据库存储直连查询分析系统中所述写入模块提交的写入任务中断或失败,则被分布式数据库清理,并设置所述写入任务中产生的数据对外不可见。
27.进一步,所述的一种基于spark的分布式数据库存储直连查询分析系统中所述查询及读取模块获得分布式数据库根据地区部署对应的spark集群信息,基于所述spark集群,仅查询或读取本地区的数据或指定优先读写的地区的数据。
28.本发明的有益之处是:
29.本发明提供一种基于spark的分布式数据库存储直连查询分析方法,基于开源架构的spark,在不影响分布式数据库oltp性能的情况下,直连其中的分布式存储进行数据分析,整个过程没有etl,避免在现有架构中,oltp与olap数据库之间大量的数据交互。此外,基于分布式架构,本发明支持弹性扩容,可按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
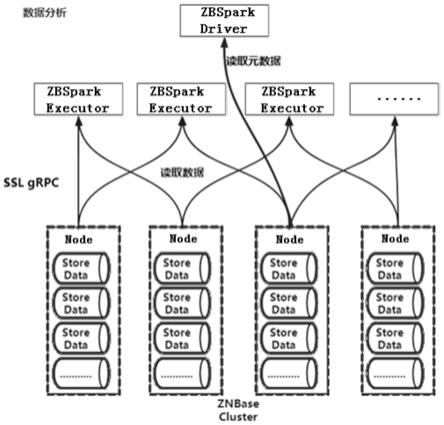
31.图1是本发明应用架构示意图。
具体实施方式
32.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
33.本发明提供一种基于spark的分布式数据库存储直连查询分析方法,基于spark,根据元数据分布并发查询读取分布式数据库存储里的数据,根据查询读取结果解析为spark可识别的数据字段,组装成spark的rdd,并将计算处理逻辑传递至分布式数据库存储上用于数据分析,
34.同时基于spark,根据rdd中的数据组装成键值对,根据键值对支持事务一致性并发写入分布式数据库存储。
35.本发明方法中能够提供对计算的精确控制,从而使spark可以有效地从分布式存储中读取数据,并且可以支持索引查找,从而显着提高了点查询执行的性能。
36.本发明方法利用多种策略来降低计算量,以减少spark sql处理数据集的大小,从而加快查询执行速度。从数据集成的角度来看,基于spark,通过分布式数据库可以直接在同一平台上执行事务和分析,而无需构建和维护任何etl。简化了系统架构并降低了维护成本。
37.此外,可以部署和利用spark生态系统中的工具来在分布式数据库上进行进一步的数据处理和操作。例如,使用spark进行数据分析,从分布式数据库中检索数据作为机器学习的数据源,调度系统生成报告等。
38.具体应用中,以znbase基于开源数据库cockroachdb为例,它源自google的全球性分布式数据库spanner,是将数据分布在多数据中心的多台服务器上,实现一个可扩展,多版本,全球分布式并支持同步复制的数据库。
39.则在本发明方法的一些实施例中,进行分布式数据库存储直连查询分析时,过程可参考如下:
40.基于spark,可命名为zbspark,在查询读取过程中向znbase网关节点发送grpc请求获取元数据,然后根据数据分布向znbase分布式存储里并发查询或者读取数据,其中当查询任务提交到zbspark,zbspark向znbase的网关节点发送元数据请求gprc,用于获取数据查询表的数据存储信息,数据存储信息包括表结构、数据在各节点的范围分布、各节点的连接端口信息等。然后按照数据的组织分布,分成多个任务并发发起键值查询请求,实现基于sparksql的datasource v2接口。根据查询的结果根据表结构解析成spark可识别的数据字段,组装成spark的rdd(resiliennt distributed datasets,弹性分布式数据集)。为了能够减少查询过程的数据交互,还进行一部分计算下推,查询请求将过滤、聚合等处理逻辑传递到znbase分布式存储上进行,从而减少全表扫描,也降低了网络间的数据传输。
41.同时基于spark,在写入过程中,根据rdd中的数据组装成键值对,根据键值对支持事务一致性并发写入分布式数据库存储,其中为了保证事务的一致性。提交zbspark任务后,会通过spark驱动器通过gprc请求向znbase开启一个新的事务,并将该事务id返回。在后续的spark执行器处理时,写入消息中除了要携带rdd中转换的表数据和表索引的键值对,还要携带这个事务id。如果所有数据写入成功,再将该事务进行提交,完成写入任务。如果任务中断或者失败,由于写入通过事务机制进行了管理,这部分写入任务数据对外不可见,之后会被znbase清理。
42.上述过程使znbase这类分布式事务型数据库增加高性能的分析能力,无需etl实现htap混合事务分析处理。通过zbspark扩展分布式数据库与spark生态的有效融合,可以通过spark引擎对分布式数据库数据进行高速的分析处理。为了能够减少查询过程的数据交互,进行计算下推的过程方法。查询请求将过滤、聚合等处理逻辑传递到znbase分布式存储上进行。从而减少全表扫描,也降低了网络间的数据传输。
43.在本发明的另一些实施例中,基于spark,支持地区亲和的数据查询,可以有效提高跨地区集群部署时的分析查询性能。其中由于现在的分布式数据库如znbase支持按地区部署,并在不同地区部署spark对数据进行分析。为了更高的分析性能,对应的spark集群只读取自己地区的副本数据,并可以通过配置项指定想要优先读写的地区,从而减少跨数据中心的网络传输。如果使用了地区亲和,数据读取将会从一致性读取退化为非一致性读取。因为无法保证亲和的地区,都具有该副本的主本,这时就会选择数据的只读副本进行数据读取。如果该副本在亲和的地区有主本,还是优先读取该副本所在的存储节点。
44.利用本发明方法使像znbase这类分布式事务型数据库,可以在不影响其执行的情况下,进行分析型任务处理,无需elt过程,成为htap混合事务分析引擎。在znbase上验证,可使ap分析查询性能提升20倍左右,使写入性能提升10倍左右。
45.使用zbspark,可以将znbase这样的分布式数据库,与spark生态的产品进行更好的融合。并支持按地区亲和性选择副本读取,提高跨地区集群查询分析性能。
46.同时本发明还提供一种基于spark的分布式数据库存储直连查询分析系统,包括查询及读取模块、rdd组装模块、逻辑传递模块、键值对组装模块及写入模块,
47.查询及读取模块基于spark,根据元数据分布并发查询读取分布式数据库存储里的数据,rdd组装模块根据查询读取结果解析为spark可识别的数据字段,组装成spark的rdd,逻辑传递模块将计算处理逻辑传递至分布式数据库存储上用于数据分析,
48.键值对组装模块基于spark,根据rdd中的数据组装成键值对,写入模块根据键值对支持事务一致性并发写入分布式数据库存储。
49.上述系统内的各模块之间的信息交互、执行过程等内容,由于与本发明方法实施例基于同一构思,具体内容可参见本发明方法实施例中的叙述,此处不再赘述。
50.同样地,本发明系统可以基于开源架构的spark,在不影响分布式数据库oltp性能的情况下,直连其中的分布式存储进行数据分析,整个过程没有etl,避免在现有架构中,oltp与olap数据库之间大量的数据交互。此外,基于分布式架构,本发明支持弹性扩容,可按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
51.需要说明的是,上述各流程和各系统结构中不是所有的步骤和模块都是必须的,可以根据实际的需要忽略某些步骤或模块。各步骤的执行顺序不是固定的,可以根据需要进行调整。上述各实施例中描述的系统结构可以是物理结构,也可以是逻辑结构,即,有些模块可能由同一物理实体实现,或者,有些模块可能分由多个物理实体实现,或者,可以由多个独立设备中的某些部件共同实现。
52.以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1