一种视觉拓扑认知模型的构建方法、手写汉字识别方法
1.本发明属于人工智能技术领域,尤其涉及一种视觉拓扑认知模型的构建方法、手写汉字识别方法。
背景技术:
2.目前,认知科学综合了心理学、脑科学、电生理学、化学、语言学、计算机科学等多门科学,通过研究人类的认知系统,并将其原理应用在人工系统中,一直是许多研究人员探索的重点。近年来,随着脑科学的发展,人类对神经系统的研究取得了很大的进展,这些进展为工程上的仿真实现提供了重要的理论依据。首先,大脑的层级结构和信息处理机制反映出了一些重要的拓扑性质。navon、陈霖等人在研究视觉初期对图像信息的处理时,发现人类视觉系统具有优先处理几何图形拓扑性质的特点,即大范围优先性原则和拓扑知觉理论。拓扑性质虽然最初是表征几何图形在连续变化下的不变性质,但究其本质还是变化中的不变性的体现。因此既然视觉具有拓扑性质,根据已有的经验推而广之,人类的整个认知系统应该也具有拓扑性质。
3.拓扑学的概念最早可追溯至十七世纪,是研究几何图形或空间在连续改变形状后还能保持不变性质的学科。比如简单的一笔画问题,像“日”字和“田”字,前者可以一笔画写出来,后者则不能,因此这两个字的拓扑性质是不一样的。并且无论两者整体形状如何改变,只要两者的线段数目和连接关系不变,就依然能保持本身的拓扑性质不变。目前结合拓扑性进行各方面的研究已经有了诸多进展,如利用拓扑性质进行字符识别、对线性图形进行着色以来判断图形的拓扑性质、利用拓扑心理空间的概念来解释语言学中的翻译问题、利用拓扑性质中的不变性来研究对联系统以及拓扑理论在机器视觉中的研究等。其中又包括利用流体神经网络对连通性这一拓扑性质的检测,利用拓扑学中同胚的性质应用到2d和3d实体图像的识别,利用平面、柱面折射法这一拓扑变换应用到人脸识别中去等。由陈霖(chen l,2005)将拓扑学同视知觉系统联系起来后,认知上的拓扑不变性开始得到了广泛的认可。目前关于认知的拓扑性的研究多以视知觉为主,结合已有的成熟的神经系统的相关知识,但与计算机科学结合的相对较少。若想以基于规则的方式探索人脑认知的秘密,并将其运用到机器中,必须借鉴人脑的认知原理。可见,虽然对拓扑性的研究由来已久,但与认知的结合相对较迟,智能科学实验室在此基础上提出“拓扑认知”的概念,希望整合拓扑认知与计算机的相关知识,在跨学科的基础上实现基于规则与统计相结合的认知方式。以此验证“认知统一结构存在性猜想(包括五识在内的感知觉具有统一的结构)”和人工智能的第五个基本问题的一种回答。
4.综上所述,现有技术存在的问题是:目前关于认知的拓扑性的研究多以视知觉为主,结合已有的成熟的神经系统的相关知识,但与计算机科学结合的相对较少。其原因在于计算机视觉在拓扑不变性上仍然存在许多尚未攻克的难关,同时目前尚未有成熟的代码上的实现。本方案运用基于视觉拓扑认知模型的构建方法生成的系统,从拓扑不变性出发,能有效识别潦草手写体、错字等现有技术难以识别的手写体汉字。
5.解决上述技术问题的难度:
6.其一,需要拟似人类视觉、具有拓扑不变性的视觉拓扑认知模型,构建支持该模型的算法,而这是现有技术所缺失的;
7.其二,要将这项技术融于计算机视觉技术体系内,为整个计算机视觉学科发展作出贡献,这就要求了很高的开发难度;
8.其三,实现为能用于实际生产的系统,仍然需要时间。
9.解决上述技术问题的意义:用计算机模拟人的认知过程,由弱人工智能发展到强人工智能一直是很多人工智能科学家们孜孜不倦的追求。由于深度学习的出现,计算机学家们将脑神经的工作原理抽象出来形成的神经网络理论在当今重新焕发新生。这种模拟计算机认知的方式已经被应用到了生活中的方方面面,如图像识别、语音识别等,成为了目前主流的计算机认知的实现方式。但这种认知方式需要大量的样本空间与海量的计算量,通过长时间的训练样本集以趋近于结果集,并且训练样本形式较为单一。因而智能科学实验室更希望能以基于规则的方式,以模拟人类的认知方式为基础,进行计算机认知上的研究。一则是实验室规模小,再则认定基于规则是更为基础和富于效率的。如今视知觉神经系统上的拓扑性已经被证明,并且获得了广泛认可。拓扑性作为一种认知规律是普遍存在且有效的,通过对认知的拓扑性的研究,可以从某个侧面发现人类认识世界的规律。在神经生理学方面,有利于对人类的认知方式进行完善,在计算机科学上,有利于由弱人工智能到强人工智能的过渡。因此,从广义上来说,拓扑学被应用到认知科学以及计算机科学是一种必然。
技术实现要素:
10.针对现有技术存在的问题,本发明提供了一种视觉拓扑认知模型的构建方法、手写汉子识别方法。
11.本发明是这样实现的,一种视觉拓扑认知模型的构建方法,所述视觉拓扑认知模型的构建方法包括以下步骤:
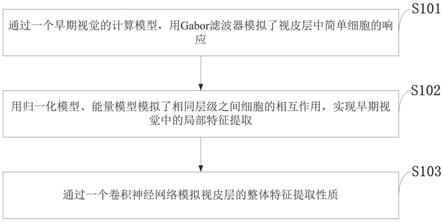
12.第一步,通过一个早期视觉的计算模型,用gabor滤波器模拟视皮层中简单细胞的响应;
13.第二步,用归一化模型、能量模型模拟相同层级之间细胞的相互作用,实现早期视觉中的局部特征提取;
14.第三步,通过一个卷积神经网络模拟视皮层的整体特征提取性质。
15.进一步,所述视觉拓扑认知模型的构建方法将归一化模型、能量模型合并后的步骤如下:
16.(1)根据神经元之间相互抑制的机制,首先将简单细胞的响应进行归一化处理,将响应限定在一定范围以此模拟神经元随刺激的增强而趋于饱和的特点;
17.(2)将归一化后的响应值进行平方求和,模拟能量模型,最终获得与相位无关的响应输出。
18.进一步,所述视觉拓扑认知模型的构建方法的二维gabor滤波器的数学表达形式为:
19.复数形式:
[0020][0021]
实数部分:
[0022][0023]
虚数部分:
[0024][0025]
其中x
′
=xcosθ+ysinθ,y
′
=-xsinθ+ycosθ;其中λ代表波长;θ代表方向,取值范围为0到360度;ψ代表相位偏移,取值范围为-180度到180度;σ代表gabor函数高斯因子的标准差;γ代表空间长宽比,当γ=1时,形状是圆的,当γ《1时,形状随平行条纹方向拉长,通常值为0.5;通过改变θ的值,可以模拟不同方向的简单细胞响应的线性输出,最终输出的结果成为上一节合并机制的输入,并以此过程模拟早期视觉模型的局部性质处理阶段。
[0026]
进一步,所述视觉拓扑认知模型的构建方法结合卷积神经网络的整体特征提取;
[0027]
(1)神经网络中一个单元的结构,其中x1、x2、x3、x4以及偏置+1分别代表神经元的输入,w1、w2、w3、w4分别代表输入的权值,hw,b(x)代表神经元的输出,用公式表示;
[0028][0029]
对于二分类的问题,神经元的激活函数f一般选择sigmoid函数,用公式表示;
[0030][0031]
对应的神经元输出计算公式为:
[0032][0033][0034][0035][0036][0037]
为计算输出值h与目标值的误差,使用平方损失函数;
[0038][0039]
其中h'代表神经网络输出的理想值,而h代表实际值,et代表产生的总误差,n代表
输出神经元的个数,n=1;那么如果要计算参数对整体产生的误差,通过输出产生的误差对求导获得,即公式;
[0040][0041]
其中:
[0042][0043]
如果神经元的输出使用激活函数为sigmoid函数,那么:
[0044][0045][0046]
由于:
[0047][0048]
那么:
[0049][0050]
综上,求得参数对整体产生的误差:
[0051][0052]
那么更新后的权值如下:
[0053][0054]
式中η代表学习率;
[0055]
同理,可得更新后的权值;
[0056]
对于隐含层到输出层的权值更新也和以上类似,对权值求导得:
[0057][0058]
其中:
[0059][0060]
由于:
[0061][0062]
且;
[0063][0064]
那么:
[0065][0066]
又:
[0067][0068][0069]
对整体产生的误差为:
[0070][0071]
则更新后的权值为:
[0072][0073]
同理可得第一层余下权值更新后的值,根据反向权值更新方式,经过多次迭代后,最终获得与期望的输出值最接近的一组权值,这组权值即是最终获得的神经网络模型。
[0074]
进一步,所述视觉拓扑认知模型的构建方法的卷积神经网络通过均值采样和最大值采样可模拟简单细胞响应过程的avg模型和max模型;
[0075]
(1)均值采样的卷积核中每个权值都为0.25,卷积核在原图上的滑动步长为2,将原始图像整体大小减小至原图的1/4,而输出则为原来区域特征值的均值;
[0076]
(2)最大值采样的卷积核中只有一个权值为1,其余都为0,其中权值为1的区域对应原图中特征值最大的部分,卷积核在原图上的滑动步长也为2,经过池化后同样将原图缩小为原来的1/4,并且输出为原来区域特征值的最大值。
[0077]
进一步,所述视觉拓扑认知模型的构建方法结合卷积神经网络的视觉早期计算包括:
[0078]
(1)输入图像,针对图像性质进行预处理,包括二值化等过程;
[0079]
(2)针对图像类型,提取图像的整体拓扑特征;
[0080]
(3)将提取的拓扑特征图像输入gabor滤波器,获得多方向、多尺度的局部滤波图像;
[0081]
(4)根据合并机制对(2)步骤的输出图像依次进行归一化、平方求和处理,获取与
相位无关的多方向图像特征值
[0082]
(5)将(3)步骤的输出图像输入cnn网络进行训练,获得更新权值后的网络模型;
[0083]
(6)输入测试图像,依次重复(1)-(3),将输出结果输入训练好的模型,获得测试结果。
[0084]
本发明的目的在于提供一种由所述视觉拓扑认知模型的构建方法构建的视觉拓扑认知模型,模型本质上是一个由深度学习技术训练的卷积神经网络。
[0085]
本发明的另一目的在于提供一种基于所述视觉拓扑认知模型的手写汉字识别方法,所述手写汉字识别方法包括:
[0086]
第一步,首先将汉字预处理,通过细化汉字以及去除角点的方式提取汉字的整体拓扑结构,减少冗余信息;
[0087]
第二步,然后通过gabor滤波器提取了汉字八个方向的不同特征,接着使用模拟视觉合并机制的几种模型将滤波器的输出更加符合人脑信息处理的拓扑机制;
[0088]
第三步,最后构造了一个卷积神经网络进行图像特征的学习。
[0089]
进一步,所述预处理的过程包括灰度化、二值化、图像大小统一;
[0090]
所述细化处理选择hilditch算法,通过逐步扫目标目标像素,并根据与周围邻域像素之间的关系判断该目标像素是否属于可删除点;
[0091]
所述角点检测并去除将采用harris角点检测的方式,先检测出汉字各线段连接部分的角点,然后去除角点在内的邻域像素信息,以此达到除去汉字各线段连接点的目的;
[0092]
所述gabor提取汉字特征将经过细化并去除角点的图像输入到gabor滤波器中进行局部特征提取,通过改变gabor函数中θ的值可以提取图像不同方向的特征,将提取手写汉字图像八个方向的不同特征值,θ值分别设为0、π/8、π/4、3π/8、π/2、5π/8、3π/4、7π/8。
[0093]
进一步,所述细化处理p的像素值等于255则为汉字像素点,等于0则为白色背景;那么根据情况可将目标像素p0分类为端点、断点、轮廓点、孤立点,并且可求得p0的八连通数,默认p0的像素值为255,那么判断标准如下:
[0094]
(1)若p0的八邻域中有且只有一个值为255,那么p0为端点;
[0095]
(2)若p0的八邻域中所有的值都为0,那么p0为孤立点;
[0096]
(3)若p0的上下左右四个点p1、p3、p5、p7中有且只有一个值为0,那么p0为轮廓点;
[0097]
(4)若消除p0导致图形的连通性发生变化,那么p0断点;p0的八联通数的计算公式如下:
[0098][0099]
那么hilditch算法的步骤为,首先对图像从左至右,从上往下扫描每个像素,整个图像扫描完成一次为一个周期,连续迭代多个周期;如果对于每个点p0满足6个条件,则标记p0为可删除点;当一次迭代周期结束时,将所有的标记点像素值设为0,并进入下一次迭代;若某一次迭代中已经没有标记点,则迭代结束;
[0100]
点p0可标记的6个条件分别为:
[0101]
(1)p0的像素值为1;
[0102]
(2)p1,p3,p5,p7不全为1,即p0不为断点;
[0103]
(3)p1到p8中,至少有两个为1,即p0既不是端点也不是孤立点;
[0104]
(4)p0的八连通数为1;
[0105]
(5)假设p3被标记删除时,p0的连通数为1;
[0106]
(6)假设p5被标记删除时,p0的连通数为1;
[0107]
所述harris算法检测角点的大致思想是在图像上建立一个移动窗口,以窗口为中心向各个方向进行移动;在移动的过程中,如果各个方向的像素值都发生了变化,则认为窗口覆盖了一个角点,如果没有像素值发生变化或仅有某个方向像素值发生变化,则认为没有覆盖角点;
[0108]
首先给出随着图像上窗口移动而产生的像素变化公式如下:
[0109][0110]
式中,w(x,y)表示移动的窗口函数,是常数也是高斯加权函数,i(x+u,y+v)表示窗口移动后的图像像素变化,i(x,y)表示移动前的像素,对式i(x+u,y+v)进行泰勒化简得:
[0111]
i(x+u,y+v)=i(x+y)+i
x
u+iyv+o(u2+v2);
[0112]
代入得:
[0113][0114]
由于u、v的移动量偏小因此式化简为:
[0115][0116]
其中:
[0117][0118]
得:
[0119][0120]
式中:
[0121][0122]
其中m是一个二维偏导数矩阵,将m用两个特征值λ1、λ2替代,可得角点响应函数:
[0123]
r=λ1λ
2-k(λ1+λ2)2;
[0124]
在式中,k为角点检测参数,取值一般在[0.04,0.06]区间中;若r值为大数值正数,则检测区域为角点;若r值为大数值负数,则检测区域为边缘;若r值为小数值,则检测区域为平坦区域;
[0125]
用gabor滤波器进行特征提取的流程为:
[0126]
(1)构造四个不同尺度的gabor滤波器,每个尺度取相位ψ相差90度,每个相位取θ为八个不同方向,根据公式,初始化gabor滤波器,取波长λ的值为10.0,高斯部分的标准差σ取5.0,γ取0.5。;
[0127]
(2)将输入的图片分别与以上4
×8×
2个滤波器进行卷积获得模拟不同简单细胞的输出。;
[0128]
(3)将不同尺度和特征方向的滤波结果按照公式(2)进行归一化处理,这样得到了表征不同相位和方向的滤波输出;
[0129]
(4)然后将不同相位的结果按照公式能量模型进行合并操作,获得与相位无关的八个方向的滤波输出;
[0130]
(5)这样将八个方向的滤波输出叠加到图片的通道维度上,获得八通道的输出图片,最终图片大小为64
×
64
×
8通过此gabor特征提取的步骤,本发明已经获得了表征汉字不同方向的特征图,下一步则将此八通道的图片输入到卷积神经网络中,进行整体特征提取;
[0131]
所述卷积神经网络结构的的计算包括:
[0132]
(1)首先将经过gabor滤波器特征提取的八通道手写汉字图片输入到卷积神经网络中,并与一个64
×3×
3大小的卷积核进行卷积,卷积核滑动步长为1,选择的卷积方式为输出和输入的图像大小一致,因此经过第一次卷积操作后卷积层包括64个64
×
64
×
1大小的图像;
[0133]
(2)然后对卷积层图像进行池化操作,根据对池化操作,这里采用max-pooling,即最大值采样,滑动步长为2,最终池化层的图像大小缩小为原来的四分之一,即包括64个32
×
32
×
1大小的图像;
[0134]
(3)接着按照(1)、(2)步骤的方式再次分别进行两次卷积核池化操作,卷积核的大小依次为128
×3×
3、256
×3×
3,卷积方式与(1)步骤相同,池化方式与(2)步骤相同,最终输出256个大小为8
×8×
1的图像;
[0135]
(4)将最终池化层的输出作为全连接层的输入,全连接层的神经元数量为1024个,输出的图像大小为1
×
1,并且池化层的每一个神经元与全连接层的每一个神经元都有连接;
[0136]
(5)将全连接层1024个1
×
1大小的输出应用激活函数tanh;
[0137]
(6)将应用激活函数的输出输入第二层全连接层,第二层全连接层的神经元数量为总的汉字个数,选择为1000个或3755个,最终产生1000个1
×
1或3755个1
×
1的输出;
[0138]
(7)最后使用softmax函数对结果进行多分类,根据label可以对输入的汉字进行判断。至此则完成神经网络的前向传播过程;
[0139]
(8)计算总误差,通过反向传播算法进行偏导计算更新各层权值,即卷积核的数值,误差的计算使用交叉熵损失函数公式;
[0140]
(9)重复以上步骤,进行多次迭代,不断更新权值,最终获得最优模型。
[0141]
综上所述,本发明的优点及积极效果为:本发明首先将汉字预处理,通过细化汉字以及去除角点的方式提取汉字的整体拓扑结构,减少冗余信息,然后通过gabor滤波器提取了汉字八个方向的不同特征,接着使用模拟视觉合并机制的几种模型将滤波器的输出更加
符合人脑信息处理的拓扑机制,最后构造了一个卷积神经网络来进行图像特征的学习。通过和仅使用卷积神经网络的手写汉字模型进行对比,分析了两种模型在汉字识别精度和损失函数随迭代次数增加的曲线变化。最终实验结果证明,
[0142]
根据本发明提出的认知的拓扑性,取视觉的拓扑性作为切入点,结合一种早期的视觉计算模型,使用gabor滤波器来模拟视皮层中简单细胞对方向这一特征的响应过程,并受到视觉通路相同层级之间细胞的相互作用的启发,使用了一种视觉合并机制来模拟视觉初期的局部特征提取。又使用了除去汉字角点的方式提取汉字的拓扑结构特征,模拟整体拓扑性质计算。最后使用卷积神经网络来模拟视觉后期的整体几何性质计算过程,通过这种方式构造了一个基于视觉拓扑认知的算法模型。为了验证视觉拓扑认知模型更加优于原有的卷积神经网络模型,将本发明的算法应用在了手写汉字的识别上。结合汉字的特点,首先通过细化汉字以及去除角点的方式模拟拓扑特征提取,又用gabor滤波器提取汉字八个方向上的特征,然后用视觉机制加以合并,并将特征矩阵传入到卷积神经网络中训练。最终对比两种算法在两种手写数据集上的识别精度以及损失函数曲线,证明了基于本发明的视觉拓扑认知模型在手写汉字识别上具有一定的优势。从而在视觉上初步验证了拓扑性作为人类认知的一种基本性质。
[0143]
本发明构造的视觉拓扑认知模型在手写汉字的识别上优于仅使用卷积神经网络的特征提取模型,从实践上初步证明了视觉拓扑认知模型的有效性。本发明以视觉为切入点,结合一个早期视觉的计算模型,用gabor滤波器来模拟视觉皮层中的特征提取过程,用视觉合并机制来模拟相同层级细胞间的相互作用过程,用卷积神经网络模拟高级视皮层的特征整合过程。将汉字的拓扑特征提取、gabor滤波器、视觉合并机制、卷积神经网络,综合各自的优点,应用在手写汉字识别上。通过以上方式初步验证“认知统一结构存在性猜想”和人工智能的第五个基本问题,即认知是否具有统一的结构将汉字的整体拓扑特征定为不同线段之间的相对位置关系,以细化并去除角点的方式作为汉字拓扑特征的提取。
[0144]
本发明以视觉的拓扑性质为切入点,结合早期视觉的计算模型,通过归一化模型、能量模型来模拟视觉通路中相同层级之间细胞的信息交互机制。本发明提出使用gabor滤波器来模拟简单细胞的响应过程作为视觉初期的局部几何性质的计算模型,又使用卷积神经网络来模拟视觉后期的整体几何性质的计算过程。结合gabor滤波器、视觉信息交互模型、卷积神经网络这三种模型,构造出了一个早期视觉的拓扑认知模型,并将此模型运用在手写汉字识别上。本发明提出细化汉字并去除角点的方式来提取汉字的整体拓扑结构。
[0145]
本发明构造的视觉拓扑认知模型优于单一的卷积神经网络模型,在手写汉字识别上具有更好的鲁棒性。表明了拓扑性应当是视觉系统处理信息的一个基本性质,从视觉层级上对“认知统一结构存在性猜想”做出了初步验证,也开始了对人工智能的第五个基本问题的回应。本发明为智能科学(intelligence science)基础理论确立打下了基础。
附图说明
[0146]
图1是本发明实施例提供的视觉拓扑认知模型的构建方法流程图。
[0147]
图2是本发明实施例提供的基于视觉拓扑认知模型的手写汉子识别方法流程图。
[0148]
图3是本发明实施例提供的早期视觉的计算模型示意图。
[0149]
图4是本发明实施例提供的二维gabor滤波器的空域和频域示意图。
[0150]
图5是本发明实施例提供的神经网络单元结构示意图。
[0151]
图6是本发明实施例提供的sigmoid函数曲线示意图。
[0152]
图7是本发明实施例提供的一个简单的神经网络模型示意图。
[0153]
图8是本发明实施例提供的卷积神经网络结构示意图。
[0154]
图9是本发明实施例提供的最大值采样和均值采样示意图。
[0155]
图10是本发明实施例提供的gabor滤波器和卷积网络的计算流程图。
[0156]
图11是本发明实施例提供的二值化处理示意图。
[0157]
图12是本发明实施例提供的目标像素p0的八邻域示意图。
[0158]
图13是本发明实施例提供的汉字细化效果示意图。
[0159]
图14是本发明实施例提供的检测汉字角点并去除示意图。
[0160]
图15是本发明实施例提供的汉字四个方向结构示意图。
[0161]
图16是本发明实施例提供的汉字“我”八个方向的gabor特征示意图。
[0162]
图17是本发明实施例提供的使用的卷积神经网络拓扑结构示意图。
[0163]
图18是本发明实施例提供的hwdb1.1的部分样本示意图。
[0164]
图19是本发明实施例提供的hit-or3c的部分样本示意图。
[0165]
图20是本发明实施例提供的1000汉字集上两种模型在hwdb1.1训练集的accuracy曲线图。
[0166]
图21是本发明实施例提供的1000汉字集上两种模型在hwdb1.1训练集的loss曲线图。
[0167]
图22是本发明实施例提供的1000汉字集上两种模型在hwdb1.1测试集的accuracy曲线图。
[0168]
图23是本发明实施例提供的1000汉字集上两种模型在hwdb1.1测试集的loss曲线图。
[0169]
图24是本发明实施例提供的3755汉字集上两种模型在hwdb1.1训练集上的accuracy曲线图。
[0170]
图25是本发明实施例提供的3755汉字集上两种模型在hwdb1.1训练集上的loss曲线图。
[0171]
图26是本发明实施例提供的3755汉字集上两种模型在hwdb1.1测试集上的accuracy曲线图。
[0172]
图27是本发明实施例提供的3755汉字集上两种模型在hwdb1.1测试集上的loss曲线图。
[0173]
图28是本发明实施例提供的1000汉字集上两种模型在hit-or3c训练集的accuracy曲线图。
[0174]
图29是本发明实施例提供的1000汉字集上两种模型在hit-or3c训练集的loss曲线图。
[0175]
图30是本发明实施例提供的1000汉字集上两种模型在hit-or3c测试集的accuracy曲线图。
[0176]
图31是本发明实施例提供的1000汉字集上两种模型在hit-or3c测试集的loss曲线图。
[0177]
图32是本发明实施例提供的3755汉字集上两种模型在hit-or3c训练集的accuracy曲线图。
[0178]
图33是本发明实施例提供的3755汉字集上两种模型在hit-or3c训练集的loss曲线图。
[0179]
图34是本发明实施例提供的3755汉字集上两种模型在hit-or3c测试集accuracy曲线图。
[0180]
图35是本发明实施例提供的3755汉字集上两种模型在hit-or3c测试集的loss曲线图。
具体实施方式
[0181]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0182]
针对现有技术存在的问题,本发明提供了一种视觉拓扑认知模型的构建方法、手写汉子识别方法,下面结合附图对本发明作详细的描述。
[0183]
如图1所示,本发明实施例提供的视觉拓扑认知模型的构建方法包括以下步骤:
[0184]
s101:通过一个早期视觉的计算模型,用gabor滤波器模拟了视皮层中简单细胞的响应;
[0185]
s102:用归一化模型、能量模型模拟了相同层级之间细胞的相互作用,实现早期视觉中的局部特征提取;
[0186]
s103:通过一个卷积神经网络模拟视皮层的整体特征提取性质。
[0187]
如图2所示,本发明实施例提供的基于视觉拓扑认知模型的手写汉子识别方法包括以下步骤:
[0188]
s201:首先将汉字预处理,通过细化汉字以及去除角点的方式提取汉字的整体拓扑结构,减少冗余信息;
[0189]
s202:然后通过gabor滤波器提取了汉字八个方向的不同特征,接着使用模拟视觉合并机制的几种模型将滤波器的输出更加符合人脑信息处理的拓扑机制;
[0190]
s203:最后构造了一个卷积神经网络进行图像特征的学习。
[0191]
下面结合具体实施例对本发明的技术方案作进一步的描述。
[0192]
实施例1:
[0193]
1、早期视觉的一个计算模型
[0194]
早期视觉的计算模型,该模型主要分为三个阶段,分别是图像信息的简单预处理、整体拓扑性质计算和局部性质计算、整体几何性质计算这三个部分,模型结构如图3所示。
[0195]
简单预处理是模拟人眼的视网膜阶段,可见光波只占自然界中光波的一部分,人眼不可能获取全部的光波的信息。视神经的处理速度只是毫秒级别,不可能处理如此多的数据,因此这其中必须经过视网膜的预处理。此外,视网膜上的视杆细胞和视锥细胞数以亿计,而神经节细胞仅有上百万个,这样巨大的数量差距暗示了必然有大量的无用信息被视网膜过滤了,为后面神经元细胞进一步加工信息奠定了基础。
[0196]
经过简单预处理后,视觉信息以神经电信号的形式经过视觉通路传递到大脑皮
层。在这个整合过程中,吴立德认为视觉信息处理的第二阶段是局部性质计算和整体拓扑性质计算的并行进行。比如在本发明对视觉系统的讨论中,发现初级视皮层中有对线段朝向敏感的区域,有对运动敏感的区域,在高级视皮层中还有对某一特异化形状敏感的区域,这些表明视觉处理初期应当有图形局部性质的处理。此模型的最后一个阶段是整体几何性质的计算。整体拓扑性质的计算是对图像的整体特征进行识别,局部几何性质是对图像的细节信息进行识别,最终局部几何性质必须要经过一些有意义的整合。比如各个局部几何性质的连接关系等,这样才能形成对图像的有意义的感知。在视觉认知过程中,图形的各个局部几何性质经过视皮层被整合,它们分别以神经冲动的形式触发记忆。这些记忆则作为场景知识参与到图像信息的整合识别中来,最终在高级视皮层区域完成了图形的感性认知,形成了心理空间中的心象。
[0197]
由此可见,此早期视觉的计算模型能够在一定程度上模拟大脑的图像识别过程,所以本发明将以此为基础构建一个视觉的拓扑认知模型。
[0198]
2模拟初级视皮层的特征提取
[0199]
在对初级视皮层的研究中,发现其主要是对图像的局部低级特征进行整合操作,形成更高级的局部特征,这种整合能够提取图像的不变性。此外在初级视皮层中,本发明发现其在细胞机制上分为简单细胞、复杂细胞和超复杂细胞。简单细胞的输出汇聚成复杂细胞的输入,复杂细胞的输出又汇聚成超复杂细胞的输入。并且具有相同功能的视觉细胞聚合在一起形成了功能柱状结构,形成了对不同特征的分类响应。根据v1区这种细胞的响应机制,许多学者提出了不同的模型对此进行研究,其中有adelson(1985)的能量模型,carandini的归一化模型(1994),poggio的max模型(1999)。能量模型能够保持输入相位的不变性,归一化模型则模拟了细胞随输入刺激的增强而趋向于饱和的特征,max模型则取具有响应相同特征的简单细胞的输出的最大值。后来将已有的各种合并机制用同一个电路进行表征,并且认为各种合并机制的相互整合才更加符合v1区细胞响应的过程。基于此将前面的能量模型、归一化模型、max模型以及取平均进行合并操作,模拟了大脑皮层的细胞响应机制。由于此合并机制在图像特征提取上符合大脑皮层的信息处理过程,并且性能良好,因此本发明希望以此模拟早期视觉中的局部特征提取阶段。
[0200]
2.1视觉合并机制
[0201]
能量模型是指将不同相位的滤波器的响应取平方求和,此模型主要模拟了两种不同简单细胞的合并响应输出,公式如(1):
[0202][0203]
其中xi模拟不同类型的简单细胞的输入,y模拟复杂细胞的响应。归一化模型的原理是在研究神经元的响应过程中发现,神经元的兴奋与抑制会受到其相邻神经元的影响,随着输入刺激的不断增强,神经元的兴奋慢慢趋于饱和状态,而不是线性增加。为了模拟此归一化过程,采用公式(2):
[0204]
[0205]
将(2)变形可得(3):
[0206][0207]
由公式(3)可知,随着输入刺激xi的不断增大,输出y逐渐趋向于1。max模型是模拟邻域内神经元响应最活跃的部分,通过取神经元响应的最大值,可以对局部的某些特征的平移或微小变换产生一定的不变性,采用公式(4);
[0208][0209]
取平均操作则是取多个神经元细胞响应的平均值,以此来表征复杂细胞的响应,采用公式(5);
[0210][0211]
本发明在合并阶段仅采用前两种模型,用来模拟相同层级之间细胞的响应过程,将归一化模型、能量模型合并后的步骤如下:
[0212]
(1)根据神经元之间相互抑制的机制,首先将简单细胞的响应进行归一化处理,将响应限定在一定范围以此来模拟神经元随刺激的增强而趋于饱和的特点。
[0213]
(2)将归一化后的响应值进行平方求和,用来模拟能量模型,最终可以获得与相位无关的响应输出。
[0214]
2.2模拟简单细胞响应的gabor滤波器
[0215]
根据接简单细胞感受野的这种响应特性,找到了gabor滤波器来模拟这种响应方式。gabor滤波器最早由d.gabor提出,将fourier(傅里叶)变换引入时间局部变化的窗函数,得到了加窗fourier变换。gabor函数是一个用于边缘提取的线性滤波器,在频率和方向的表达方式同简单细胞的响应类似。
[0216]
二维gabor滤波器可以在不同尺度和不同方向上对图像进行特征提取。它是一个正弦平面波和高斯核函数的乘积,能够在空间域和频率域同时取得最优局部化。它与简单细胞的感受野相似,能够提取图像方向上的局部信息。一个二维gabor滤波器的空域和频域图如图4所示。
[0217]
二维gabor滤波器的数学表达形式为:
[0218]
复数形式:
[0219][0220]
实数部分:
[0221][0222]
虚数部分:
[0223][0224]
其中x
′
=xcosθ+ysinθ,y
′
=-xsinθ+ycosθ。
[0225]
根据上面的式子,发现二维gabor滤波器分为实数部分和虚数部分,一般用实数部分来进行方向特征的提取。其中λ代表波长;θ代表方向,取值范围为0到360度;ψ代表相位偏移,取值范围为-180度到180度;σ代表gabor函数高斯因子的标准差;γ代表空间长宽比,当γ=1时,形状是圆的,当γ《1时,形状随平行条纹方向拉长,通常值为0.5。通过改变θ的值,可以模拟不同方向的简单细胞响应的线性输出,最终输出的结果成为上一节合并机制的输入,并以此过程模拟早期视觉模型的局部性质处理阶段。
[0226]
3结合卷积神经网络的整体特征提取
[0227]
基于gabor滤波器的特征提取方法虽然在识别某些特定的图像,如手写阿拉伯数字上精确度已经很高。但从神经生物机制上来说,仅仅模拟了初级视皮层简单细胞聚合成复杂细胞的过程;从视觉模型上来说,仅仅处于视觉的局部特征提取阶段。因此为了能够以更接近生物视觉原理的方式进行图像识别,本发明希望找到一种模型能够模拟视觉后期的整体几何性质计算。人工神经网络模型模拟的是大脑神经元拓扑网络之间的信息输入、输出过程,它将大脑识别环境的过程看成一个黑箱,只考虑神经元之间信息的输入与输出,而不考虑神经元对这些信息的进一步作用机制。实践检验,这种基于大规模数据集的模型在图像识别、语音识别等领域发挥着重要作用,识别的准确率往往优于传统的模式识别算法。因此将gabor滤波器同人工神经网络相结合具有一定的实践基础和神经生理学基础。
[0228]
3.1,如图5所示,是神经网络中一个单元的结构,也是最简单的神经网络。其中x1、x2、x3、x4以及偏置+1分别代表神经元的输入,w1、w2、w3、w4分别代表输入的权值,hw,b(x)代表神经元的输出,用公式(9)表示;
[0229][0230]
对于二分类的问题,神经元的激活函数f一般选择sigmoid函数,用公式(10)表示;
[0231][0232]
如图6是sigmoid的曲线图,从中可以看出此神经元的输入与输出是一个逻辑回归的过程,因此此单元也被称之为logistic回归模型。sigmoid函数的值域范围为(0,1),并且在0.5处中心对称,与概率值的范围是相对应的。将单个神经元进行组合成一个具有层级的网路拓扑结构时,就形成了神经网络模型,如图7是一个包含隐藏层的三层简单神经网络模型。
[0233]
对应的神经元输出计算公式为:
[0234]
[0235][0236][0237][0238][0239]
以图6的简单神经网络为例做一个权值更新的公式推导。为了计算输出值h与目标值的误差,这里使用平方损失函数(16);
[0240][0241]
其中h'代表神经网络输出的理想值,而h代表实际值,et代表产生的总误差,n代表输出神经元的个数,对于图6而言,n=1。那么如果要计算参数对整体产生的误差,可以通过输出产生的误差来对求导获得,即公式(17);
[0242][0243]
对于图6而言,其中:
[0244][0245]
如果神经元的输出使用激活函数为sigmoid函数,那么:
[0246][0247][0248]
由于:
[0249][0250]
那么:
[0251][0252]
综上,可求得参数对整体产生的误差:
[0253][0254]
那么更新后的权值如下:
[0255][0256]
(24)中η代表学习率,η的值既不能太大,也不能太小,太大会导致权值在收敛过程中越过最优值,太小会导致网络的收敛速度过慢。同理,可得更新后的权值。
[0257]
对于隐含层到输出层的权值更新也和以上类似,以权值为例,对求导可得:
[0258][0259]
其中:
[0260][0261]
由于:
[0262][0263]
且;
[0264][0265]
那么:
[0266][0267]
又:
[0268][0269]
[0270]
所以对整体产生的误差为:
[0271][0272]
则更新后的权值为:
[0273][0274]
同理可得第一层余下权值更新后的值。
[0275]
根据上述的反向权值更新方式,经过多次迭代后,最终获得与期望的输出值最接近的一组权值,这组权值即是最终获得的神经网络模型。
[0276]
3.2卷积神经网络
[0277]
卷积神经网络就是一个包含多个隐藏层的神经网络,最早是受猫纹状视皮层简单细胞感受野的电生理学启发,因而有人在神经网络中提到了局部感受野的概念。近年来,卷积神经网络在人脸识别、语音识别、自然语言处理等方面取得了显著的成果。
[0278]
图8表示了一个卷积神经网络模型,其中包含了两个卷积层、两个池化层、一个全连接层和一个输出层。
[0279]
在初级视皮层的学习中,本发明知道不同简单细胞的感受野只对特定朝向的线段、方向等图像局部特征敏感,而卷积神经网络区别于一般神经网络的重要概念就在于它的局部感受野,通过局部感受野可以显著的降低网络中参数的数目。卷积神经网络中卷积层的每个神经元只接受图像的某个局部信息,然后由更高层的全连接层神经元将这些局部信息汇聚起来就得到了图像的全局信息。对于一个1000
×
1000像素的输入图像,隐含层包含10000个神经元的神经网络,假如卷积核为10
×
10,即每个神经元与图像中10
×
10的像素相连接,那么,卷积前参数数量:1000
×
1000
×
10000个;卷积后参数数量:10
×
10
×
10000个。可以发现参数的数量减少为原来的万分之一,这样一来大大的提高了网络的训练效率。但此方式参数个数仍然达到了百万级别,若要进一步减少参数的数量则需要用到权值共享,即如果每个神经元连接的卷积核参数都是一样的话,那么网络中的整体参数则降低到了100个,这样再一次减少了参数数量。共享权值的原理在于,一幅图像中不同区域的统计特性是相似的,所以可以用相同的卷积核在图像的不同部分学习特征。如果只有一个卷积核,提取的图像特征显然是不充分,那么通过多个卷积核,本发明就能学习到更多的图像特征。
[0280]
对于卷积神经网络而言,采样层也称之为池化层。根据图像卷积获得了图像的一些特征后,本发明用这些特征训练分类器,最终得到分类结果。以上图28
×
28的图像输入为例,当卷积特征向量的数量非常巨大时,假如用的是5
×
5的卷积核在图像上学习到了400个特征,且滑动步长为1,这样每个图像就会产生(28-5+1)
×
(28-5+1)
×
400=230400维的特征向量。当图像的像素进一步扩大,可以想象特征向量的维数会达到百万甚至千万级别,因此需要通过池化的方式减少特征向量的数量。池化的原理是对一幅图像上不同位置的特征值进行聚合统计,比如计算图像上某一区域的平均值或最大值,这样的统计方式能够显著降低特征向量的维数。池化有两种形式,一种是均值子采样,另一种是最大值子采样。通过
均值采样和最大值采样可模拟简单细胞响应过程的avg模型和max模型。如图9所示。
[0281]
(1)均值采样的卷积核中每个权值都为0.25,卷积核在原图上的滑动步长为2,这样一来就将原始图像整体大小减小至原图的1/4,而输出则为原来区域特征值的均值。
[0282]
(2)最大值采样的卷积核中只有一个权值为1,其余都为0,其中权值为1的区域对应原图中特征值最大的部分,卷积核在原图上的滑动步长也为2,经过池化后同样将原图缩小为原来的1/4,并且输出为原来区域特征值的最大值。
[0283]
3.3结合卷积神经网络的视觉早期计算
[0284]
卷积神经网络虽然具有局部感受野的特征,但却没有明显体现初级视皮层简单细胞感受野对线段朝向、方向选择等功能的模拟。为了让模型在结构上更加符合视觉通路中初级视皮层的工作原理,且gabor滤波器正好能够模拟不同方向和尺度的简单细胞的线性响应过程,因此在这里将gabor滤波器和卷积神经网络结合构造出一个早期视觉的计算模型。整个计算模型分为训练和测试两个阶段,如图10所示,步骤如下:
[0285]
(1)输入图像,针对图像性质进行预处理,包括二值化等过程;
[0286]
(2)针对图像类型,提取图像的整体拓扑特征;
[0287]
(3)将提取的拓扑特征图像输入gabor滤波器,获得多方向、多尺度的局部滤波图像;
[0288]
(4)根据合并机制对(2)步骤的输出图像依次进行归一化、平方求和处理,获取与相位无关的多方向图像特征值
[0289]
(5)将(3)步骤的输出图像输入cnn网络进行训练,获得更新权值后的网络模型;
[0290]
(6)输入测试图像,依次重复(1)(2)(3)步骤,将输出结果输入训练好的模型,获得测试结果。
[0291]
实施例2
[0292]
1预处理
[0293]
不同人书写汉字的习惯不同,造成手写汉字图像中普遍存在着噪声和畸变,这些成为影响手写汉字识别的重要因素。因此汉字输入之后首先要做的应当是进行预处理,以保证能够对汉字特征进行更精确的提取。预处理的过程包括灰度化、二值化、图像大小统一等步骤。对于一般的.jpg或者.png格式的图片往往包括rgb三种通道的颜色信息,但是在手写汉字识别中,本发明提取的仅仅是汉字的拓扑结构特征,与颜色无关,因此需要先对汉字图像进行灰度处理,将其变为一通道的灰度图像。由于识别手写汉字只需要处理它的拓扑结构,和颜色等信息无关。因此需要对与结构无关的信息进行去冗余操作。通过对汉字图片进行二值化处理,去除多余的信息,可以加快后面进行特征提取的速度。二值化的操作原理是将原本的多值图像处理成只包含二值信息的黑白图像,其中黑色代表文字内容,白色代表背景。二值化前后处理的图像对比如图11所示。
[0294]
其中左边表示原始图片,右边表示二值化后的图片,可以看到经过二值化处理后的汉字图像只包括了0和255两种像素信息,其中0代表白色背景,255代表黑色的像素。由于输入图片的大小本身并非完全一致,因此为了后期进行gabor特征提取与输入到卷积神经网络中的方便,需要对图像像素进行规范化,这里将所有的图片像素统一为64
×
64大小。
[0295]
2细化处理
[0296]
针对汉字独有的结构,本发明将在接下来的两节中提取汉字的整体拓扑结构,以
此来模拟早期视觉模型中整体拓扑性质的计算过程。经过二值化处理后的汉字依然包含画的宽度等冗余信息。这些信息在识别汉字整体结构中并没有占到十分重要的作用,因此也应当被祛除。通过汉字的细化处理,可以提取汉字的整体骨架结构,并且消除汉字中存在的冗余点,为后期汉字特征提取与整合减少了运算量,加快了运算速度,缩短了识别时间。常见的细化算法有hilditch、fpa、spta、opta等(vincze etc.,2012)。由于hilditch算法对于各种字符的通用性更好,且算法简单,因此这里选择hilditch算法作为本发明的汉字细化处理算法。hilditch算法细化汉字的原理是通过逐步扫目标目标像素,并根据其与周围邻域像素之间的关系来判断该目标像素是否属于可删除点。目标像素的八邻域示意图如图12。
[0297]
在上图中,p的像素值等于255则为汉字像素点,等于0则为白色背景。那么根据情况可将目标像素p0分类为端点、断点、轮廓点、孤立点,并且可求得p0的八连通数,默认p0的像素值为255,那么其判断标准如下:
[0298]
(1)若p0的八邻域中有且只有一个值为255,那么p0为端点;
[0299]
(2)若p0的八邻域中所有的值都为0,那么p0为孤立点;
[0300]
(3)若p0的上下左右四个点p1、p3、p5、p7中有且只有一个值为0,那么p0为轮廓点;
[0301]
(4)若消除p0导致图形的连通性发生变化,那么p0断点;p0的八联通数的计算公式如下:
[0302][0303]
那么hilditch算法的步骤为,首先对图像从左至右,从上往下扫描每个像素,整个图像扫描完成一次为一个周期,连续迭代多个周期。如果对于每个点p0满足6个条件,则标记p0为可删除点。当一次迭代周期结束时,将所有的标记点像素值设为0,并进入下一次迭代。若某一次迭代中已经没有标记点,则迭代结束。
[0304]
点p0可标记的6个条件分别为:
[0305]
(1)p0的像素值为1;
[0306]
(2)p1,p3,p5,p7不全为1,即p0不为断点;
[0307]
(3)p1到p8中,至少有两个为1,即p0既不是端点也不是孤立点;
[0308]
(4)p0的八连通数为1;
[0309]
(5)假设p3被标记删除时,p0的连通数为1;
[0310]
(6)假设p5被标记删除时,p0的连通数为1;
[0311]
通过以上几步,已经能提取汉字图像的整体骨架结构,用hilditch细化算法提取汉字骨架的前后示意图如图13所示。
[0312]
从上图中可以看到经过细化处理后的汉字笔画宽度大大减小,汉字的信息表示已经与其笔画宽度无关,这样汉字的整体拓扑结构信息已经大致被反应出来。
[0313]
3角点检测并去除
[0314]
虽然经过细化处理后,汉字的结构已经比较分明,但仔细分析汉字的拓扑结构会发现,细化之后的汉字依然存在一定的冗余信息。拓扑结构本质是事物经过变化后依然保持不变的性质。在研究各种手写体汉字中,本发明发现汉字的笔画粗细、笔画长短,甚至轻
微的朝向偏移、洞的开闭、线段的连接,在一定程度上都不影响汉字本身的识别。这是由于人类视觉本身的整体拓扑性质决定的,例如两个笔画即便没有进行严格的连接,视觉依然会自动将其连接,把它当成一个整体来处理,又如笔画中的洞无论是方形的还是圆形的,都不影响视觉对整个汉字的识别。
[0315]
本发明发现汉字的拓扑结构本质上是不同朝向的线段的个数与它们之间的相对位置关系,这种关系构成了本发明识别不同汉字的基础。对于手写体汉字而言,由于其中存在的连笔现象导致本发明不能精确并规范的识别汉字结构。因此为了进一步减少手写汉字中存在的冗余信息,本发明将去掉汉字中存在的连接点,这也是本发明在提取汉字的拓扑结构中的一个创新点。本发明发现汉字的连接点去掉后,汉字的各个线段之间的相对位置关系依然没有发生变化,本发明依然能够精确的识别出不同的汉字。但减少了线段之间的连接点后,对于手写汉字而言,在一定程度上减少了连笔等不规范书写导致的冗余信息。本发明将采用harris角点检测的方式,先检测出汉字各线段连接部分的角点,然后去除角点在内的邻域像素信息,以此达到除去汉字各线段连接点的目的。
[0316]
harris算法检测角点的大致思想是在图像上建立一个移动窗口,以窗口为中心向各个方向进行移动。在移动的过程中,如果各个方向的像素值都发生了变化,则认为窗口覆盖了一个角点,如果没有像素值发生变化或仅有某个方向像素值发生变化,则认为没有覆盖角点。
[0317]
首先给出随着图像上窗口移动而产生的像素变化公式如下:
[0318][0319]
公式(35)中,w(x,y)表示移动的窗口函数,它可以是常数也可以是高斯加权函数,i(x+u,y+v)表示窗口移动后的图像像素变化,i(x,y)表示移动前的像素。对式i(x+u,y+v)进行泰勒化简可得:
[0320]
i(x+u,y+v)=i(x+y)+i
x
u+iyv+o(u2+v2)
ꢀꢀ
(36)
[0321]
将(36)代入(35)中可得:
[0322][0323]
由于u、v的移动量偏小因此式(37)可化简为:
[0324][0325]
其中:
[0326][0327]
将(39)代入(38)中可得:
[0328][0329]
式(40)中:
[0330][0331]
其中m是一个二维偏导数矩阵,将m用两个特征值λ1、λ2替代,可得角点响应函数:
[0332]
r=λ1λ
2-k(λ1+λ2)2ꢀꢀ
(42)
[0333]
在式(42)中,k为角点检测参数,取值一般在[0.04,0.06]区间中。若r值为大数值正数,则检测区域为角点;若r值为大数值负数,则检测区域为边缘;若r值为小数值,则检测区域为平坦区域。用harris算法检测经过细化的汉字图像的角点并去除的示意图如图14。可以看到,经过角点去除后,索性将汉字的每一个笔画线段都分隔开来,但线段之间的相对位置依然不发生改变。对于手写汉字中存在的断笔、连笔等不规范书写行为具有一定的容错能力。
[0334]
4gabor提取汉字特征
[0335]
将经过细化并去除角点的图像输入到gabor滤波器中进行局部特征提取。汉字的笔画虽然复杂多样,但是总的来说可以分为四个方向,分别是横、竖、撇、捺,其中“点”可以近似看作“捺”,而“勾”又可以近似看作“撇”。因此忽略汉字笔画的长短,汉字的拓扑结构就是四个方向线段的相对位置的组合。但是由于不同人之间书写方式的差异,线段的长短和方向并非完全符合标准的四个方位,由此造成不同人之间的字体差异,汉字四个方向结构如图15所示。
[0336]
gabor滤波器具有方向敏感性,通过改变gabor函数中θ的值可以提取图像不同方向的特征,因此这里将提取手写汉字图像八个方向的不同特征值,θ值分别设为0、π/8、π/4、3π/8、π/2、5π/8、3π/4、7π/8。汉字“我”的八个方向的gabor特征图如图16所示。由图16可以看到不同方向的gabor滤波器只对相应方向的笔画特征敏感,这样一来弥补了卷积神经网络的局部感受野不能进行方向特征提取的缺点,使其更加符合人类视觉认知的拓扑结构。输入图片的大小为64
×
64,通道数为1,即输入图片大小为64
×
64
×
1,那么根据视觉合并机制以及汉字的结构特点,用gabor滤波器进行特征提取的流程为:
[0337]
(1)构造四个不同尺度的gabor滤波器,每个尺度取相位ψ相差90度,每个相位取θ为八个不同方向,根据公式,初始化gabor滤波器,取波长λ的值为10.0,高斯部分的标准差σ取5.0,γ取0.5。
[0338]
(2)将输入的图片分别与以上4
×8×
2个滤波器进行卷积获得模拟不同简单细胞的输出。
[0339]
(3)将不同尺度和特征方向的滤波结果按照公式(2)进行归一化处理,这样得到了表征不同相位和方向的滤波输出。
[0340]
(4)然后将不同相位的结果按照公式(1)能量模型进行合并操作,获得与相位无关的八个方向的滤波输出。
[0341]
(5)这样将八个方向的滤波输出叠加到图片的通道维度上,获得八通道的输出图
片,最终图片大小为64
×
64
×
8通过此gabor特征提取的步骤,本发明已经获得了表征汉字不同方向的特征图,下一步则将此八通道的图片输入到卷积神经网络中,进行整体特征提取。
[0342]
5cnn的构造及流程
[0343]
这里为了简化原有的卷积网络结构,将采用一个结构较为简单的卷积神经网络结构。整个卷积网络包括三个卷积层,三个池化层以及两个全连接层,网络拓扑结构如图17所示。
[0344]
根据网络结构可以看到,此cnn的计算流程如下所示:
[0345]
(1)首先将经过gabor滤波器特征提取的八通道手写汉字图片输入到卷积神经网络中,并与一个64
×3×
3大小的卷积核进行卷积,卷积核滑动步长为1,选择的卷积方式为输出和输入的图像大小一致,因此经过第一次卷积操作后卷积层包括64个64
×
64
×
1大小的图像。
[0346]
(2)然后对卷积层图像进行池化操作,根据对池化操作,这里采用max-pooling,即最大值采样,滑动步长为2,最终池化层的图像大小缩小为原来的四分之一,即包括64个32
×
32
×
1大小的图像。
[0347]
(3)接着按照(1)、(2)步骤的方式再次分别进行两次卷积核池化操作,卷积核的大小依次为128
×3×
3、256
×3×
3,卷积方式与(1)步骤相同,池化方式与(2)步骤相同,最终输出256个大小为8
×8×
1的图像。
[0348]
(4)将最终池化层的输出作为全连接层的输入,全连接层的神经元数量为1024个,输出的图像大小为1
×
1,并且池化层的每一个神经元与全连接层的每一个神经元都有连接。
[0349]
(5)将全连接层1024个1
×
1大小的输出应用激活函数tanh。
[0350]
(6)将应用激活函数的输出输入第二层全连接层,第二层全连接层的神经元数量为总的汉字个数,这里选择为1000个或3755个,最终产生1000个1
×
1或3755个1
×
1的输出。
[0351]
(7)最后使用softmax函数对结果进行多分类,根据label可以对输入的汉字进行判断。至此则完成神经网络的前向传播过程。
[0352]
(8)计算总误差,通过反向传播算法进行偏导计算更新各层权值,即卷积核的数值,误差的计算使用交叉熵损失函数公式(48)。
[0353]
(9)重复以上步骤,进行多次迭代,不断更新权值,最终获得最优模型。
[0354]
图17中,第一层全连接层中的激活函数选用了tanh函数,tanh函数比sigmoid函数的收敛速度更快,并且其输出以0为中心,其表达式如下:
[0355][0356]
此外,由于汉字本身数量众多,属于一个多分类问题,因此这里选取softmax函数作为输出层的激活函数。softmax函数是sigmoid函数的一般形式,它的函数表达式如下所示:
[0357][0358]
式(44)中,xi代表训练集中的某一个样本,y即代表xi属于某一类别的概率;(w1,w2,
…
,wk)代表模型的参数,即全连接层与softmax层的连接权值,k代表类别数量,在这里是不同汉字的个数;将所有的概率和归一化为1,通过softmax函数可以对样本属于不同类别的概率情况进行估计。
[0359]
下面结合实验对本发明的技术效果作详细的描述。
[0360]
1机器配置
[0361]
本次实验采用的硬件环境,cpu为英特尔酷睿i5-7500@3.4ghz,gpu为nvidiageforce gtx 1060,显存6g,内存8g。软件环境为python3.6、phycharm、cdua9.0、tensorflow框架,win10操作系统。
[0362]
2训练数据和测试数据
[0363]
本次实验采用的数据集来自casia和hit-or3c手写汉字库。
[0364]
其中casia收录了7185个常用汉字以及171个特殊符号,这里采用了其中的脱机手写数据库hwdb1.1,包括了由300个不同书写者书写的3755个常用汉字,因此每个汉字各有300个不同的样本。取240个不同书写者的样本作为训练集,60个书写者的样本作为测试集,一共包括897758个训练样例和223991个测试样例。由于获取的手写汉字集是以.gnt格式存储的,因此首先通过数据库规定的方式对数据库对汉字集进行解码,最终结果以.png的格式存储图片,并且以文件夹命名的方式对汉字集进行分类。hwdb1.1的部分样本如图18所示。
[0365]
而hit-or3c汉字手写库则取其中的gb1、gb2、digit和letter子集,总数包括6825个不同的汉字、数字和字母,每个字符有122套样本,总共832650个手写字样本。这里取其中3755个汉字的96套字符作为训练集,另外26套字符作为测试集。同样也按照规定格式将图片解码成.png格式,并以文件夹命名的方式对字符进行归类。hit-or3c中的部分样本如图19所示。
[0366]
hwdb1.1中每张汉字图片的大小不一样,而hit-or3c的每张图片大小均为128
×
128,所以首先对每张汉字图片进行预处理,将大小统一归为64
×
64
×
1大小。对每张图片进行gabor滤波器提取八个不同方向的特征图,并且叠加到通道上,形成64
×
64的八通道图片,最后分批导入卷积神经网络中,每批导入128张图片。为了对比本发明采用的基于视觉拓扑结构的算法的优势,将通过两组实验进行对比分析。
[0367]
第一组实验不采用细化处理、角点去除、gabor滤波器进行特征提取,仅采用卷积神经网络分批次对汉字图片进行迭代,并记录实验结果;第二组实验采用细化处理、角点去除、gabor滤波器进行汉字不同方向特征的提取,然后以特征通道的方式传入卷积神经网络中分批次进行迭代。两组实验分别在hwdb1.1和hit-or3c手写汉字库上的1000个汉字集和3755个汉字集上进行,最终将产生四组实验结果。通过比较不同算法在两种数据集上的实验数据,评价两种算法的优劣。
[0368]
3实验结果对比
[0369]
为了判断两种算法的优劣程度,本次实验将采用accuracy准确率曲线和loss损失函数曲线来作为评价指标。准确率就是对于给定的测试数据集,分类器正确分类的样本数与总样本数之比,也就是损失函数是0-1损失时测试数据集上的准确率。本发明将分类器的分类结果分成四大类:
[0370]
(1)正确预测出的正样本个数(tp),即分类器能够正确预测出手写汉字的样本个数;
[0371]
(2)错误预测出的正样本个数(fp),即分类器将负样本预测成了正样本;
[0372]
(3)正确预测出的负样本个数(tn),即分类器正确预测出非该手写汉字的样本个数;
[0373]
(4)错误预测出的负样本个数(fn),即分类器将正样本预测成了负样本;
[0374]
那么,有:
[0375][0376]
通过(45)可以较为有效的估计模型整体的判断能力,因此将其作为评判本发明算法的标准之一。同时本发明用loss损失函数来表征模型对于期望值的误差,它是一个非负函数。一般情况下损失函数的值越小,获得的模型的鲁棒性就越好。当误差越大,网络中权值更新速度就越快,当误差越小,网络中权值更新速度就越慢,而权值更新速度越慢对于神经网络而言是一个很好的性质。这里本发明采用交叉熵函数来作为损失函数,公式如下:
[0377][0378]
那么对于softmax需要对多个样本进行多分类的情况下,其损失函数公式如下:
[0379][0380]
对于(47)式,其中n代表样本的个数,yi代表softmax分类器的输出向量中的第i个值,即模型预测的值,yi′
代表实际标签中的第i个值。可以发现随着yi越来越精确,交叉熵函数的值也会越来越小,最终逐渐收敛于0。结合公式(5-11)可得:
[0381][0382]
其中1{yi=j}表示当yi=j为真时,表达式的值为1,否则为0。在这里,本发明将分别给出模型在训练集和测试集上的accuracy和loss曲线。从不同的汉字数量,以及不同的数据集上,对两种算法的整体趋势做一些比较。
[0383]
3.1 hwdb1.1数据集
[0384]
首先实验将分别取hwdb1.1中的部分1000个汉字和所有的3755个汉字比较两种算法的优劣。
[0385]
图20和图21分别代表了汉字总数为1000个,经过10000次迭代后,两种模型在训练集上的accuracy曲线图和loss曲线图。可以发现随着迭代次数的增加两种模型的accuracy曲线趋近于1,而loss曲线则趋近于0。而本发明构造的结合卷积神经网络的拓扑认知模型明显比单一的卷积神经网络模型有着更快的收敛速度。
[0386]
图22和图23分别代表了汉字总数为1000个,经过10000次迭代后,两种算法在测试集上的accuracy和loss曲线图,可以发现同样可以发现本发明构造的拓扑认知模型能以更快的速度收敛到精确值。
[0387]
图24到图25分别代表了汉字总数为3755个,经过12万次迭代后,两种模型在训练集上的accuracy和loss曲线图。可以发现,本发明提出的拓扑认知模型在经过5万步后逐渐收敛到最优值,而单一的卷积神经网络模型经过了10万次以上的迭代才逐渐收敛到最优值,说明了本发明算法的收敛速度更快。
[0388]
图26到图27分别代表了在3755个汉字上,经过12万次迭代后,两种模型的在测试集上的accuracy和loss曲线图。可以发现,测试集上的收敛速度明显慢于训练集,但本发明提出的拓扑认知模型在测试集的初始阶段也比单一的卷积神经网络模型收敛速度更快。
[0389]
3.2hit-or3c数据集
[0390]
同样,实验将分别取hit-or3c中的部分1000个汉字和部分3755个汉字比较两种算法的优劣。
[0391]
图28和图29分别代表了汉字总数为1000个,经过7000次迭代时,两种模型在hit-or3c训练集上的accuracy曲线图和loss曲线图。由于hit-or3c上汉字的样本数量相比于hwdb1.1较少,因此经过7000次迭代后,两种模型的accuracy曲线逐渐收敛到1,loss曲线逐渐收敛到0。但可以看出,本发明提出的模型依然比单一的卷积神经网络模型有着更快的收敛速度。
[0392]
图30和图31分别代表了汉字总数为1000个,经过7000次迭代时,两种模型在hit-or3c测试集上的accuracy曲线图和loss曲线图。同样可以发现本发明提出模型收敛速度更快。
[0393]
图32和图33分别代表了汉字总数为3755个,经过60000次迭代时,两种模型在hit-or3c训练集上的accuracy曲线图和loss曲线图。拓扑认知模型在前两万步迭代的过程明显有着高于单一卷积神经网络的识别精度,并且收敛速度快于单一卷积神经网络。
[0394]
图34和图35分别代表了汉字总数为3755个,经过60000次迭代时,两种模型在hit-or3c测试集上的accuracy曲线图和loss曲线图。两种模型在测试集上的识别精度依然劣于训练集,但依然可以发现本发明的模型收敛速度更快。
[0395]
综上,在汉字数量不同、数据集不同的情况下,实验的结果均表明本发明的结合拓扑特征提取、gabor滤波器以及卷积神经网络的拓扑认知模型优于单一的卷积神经网络模型。
[0396]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1