一种基于残差注意力Transformer的光学乐谱图像识别方法
一种基于残差注意力transformer的光学乐谱图像识别方法
技术领域
1.本发明涉及乐谱图像数字化技术领域,具体涉及一种基于残差注意力transformer的光学乐谱图像识别方法。
背景技术:
2.随着计算机技术的飞速发展,文本、图像、音频等内容正逐步被转化为数字化信息资源保存、开发利用和传播,其中,纸介质乐谱的数字化对于数字音乐图书馆、计算机音乐辅助教学和音乐信息检索的发展十分重要。纸介质乐谱的数字化就是利用计算机将纸质乐谱内容转换为数字化的音乐格式文件(如midi文件)——即光学乐谱识别技术。通过光学乐谱识别技术将乐谱数字化后存储在计算机中,不仅存贮空间小,传播范围广、速度快,而且相比纸质乐谱更容易长时间完好保存。另外,数字化乐谱使得传统手工方式的乐曲创作、修改、演奏、传播变得高级,为人类的音乐活动带来了生产方式的根本变革。再者,用户在使用数字化乐谱时不仅可以通过关键字(如曲名、作者、发表年代等信息)进行文本检索,还可以基于音乐内容(如某段旋律)进行检索,从而查询到想要的乐曲。这些功能的实现依赖于不断进步的光学乐谱识别技术,然而,目前光学乐谱识别准确率还较低。因此,光学乐谱识别技术的提高仍然是一项值得研究的课题。
3.传统光学乐谱识别的主要步骤包括:图像预处理、谱线检测与删除、原始音符对象(如符头、符干、符尾、谱号、休止符等)识别、特征音符对象重建、音符语义数字化编码。在这些步骤中有基于音符几何特征、基于音符先验知识或基于模板匹配等方法,为了实现这些方法,一方面需要专业音乐人的音乐知识和复杂的算法,因此这限制了研究人员类别;另一方面,这五个步骤中的每一步都难以达到很高的精度,并且每一步骤产生的一定数量的误差在后续的步骤中可能会呈指数放大。然而,机器学习的兴起使得光学乐谱识别简单化。研究者不需要音乐专业知识就可以手工提取音符特征,然后采用隐马尔科夫模型、支持向量机和最小k邻近等机器学习模型识别出音符,音符识别准确率有了显著提高。但是,机器学习类方法仍需要人工提取音符特征,耗时耗力,并且当人工提取的音符特征不足或不够准确,对准确性有很大的影响。
4.近些年来,以深度卷积神经网络和循环神经网络为代表的监督学习在图像分类、目标检测、机器翻译等任务中发挥了显著作用。虽然卷积神经网络能有效地捕获单个音符的丰富特征,但并不能提取到丰富的音符序列特征,而循环神经网络虽然可以解决音符序列上下文信息提取不足的问题,却存在音符序列过长导致梯度消失的问题。再者,在使用连接时序分类损失函数训练模型时,其串行计算方式会导致训练时间过长且模型难以拟合。基于现有的光学乐谱识别方案效率低,且音符序列识别准确率还有待提升,因此,本发明提出了一种基于残差注意力transformer的光学乐谱图像识别方法解决上述问题。
技术实现要素:
5.本发明的目的在于提出一种基于残差注意力transformer的光学乐谱图像识别方
法,以解决现有的光学乐谱图像识别技术对音符序列识别准确率不高且效率低的问题。
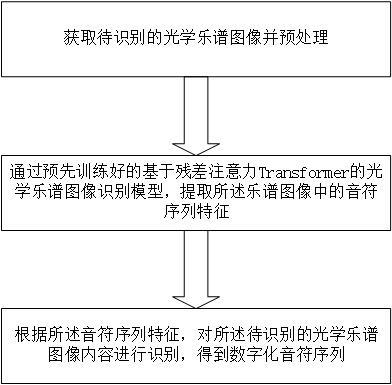
6.本发明提供的一种基于残差注意力transformer的光学乐谱图像识别方法,包括以下内容:s1:获取待识别的光学乐谱图像并预处理;s2:通过预先训练好的基于残差注意力transformer的光学乐谱图像识别模型,提取所述待识别乐谱图像中的音符序列特征;s3:根据所述音符序列特征,对所述待识别的光学乐谱图像内容进行分析与识别,得到数字化音符序列。
7.进一步的,所述步骤s1预处理待识别的光学乐谱图像包括以下具体步骤:获取待识别乐谱图像的列像素和;根据上述所求列像素和,去除图像中非音符范围的像素,只保留所有的音符像素并按原顺序拼接成预处理后的乐谱图像。
8.进一步地,所述步骤s2的具体内容如下所示:基于残差注意力transformer的光学乐谱图像识别模型由一个编码器层、一个解码器层和一个注意力层构成。
9.预处理后的乐谱图像首先被输入到编码器层,编码器层由浅层的预训练resnet网络和两层双向的lstm神经网络组成,并且在resnet网络的输出与最后一层lstm网络的输出之间建立一个残差连接,然后得到编码器层的输出特征图enc∈rb×
l
ˊ
×c;其中resnet网络用于提取音符的基本特征,lstm网络用于提取音符序列上下文信息;在解码器层,标签序列先被embedding,再经过两层lstm神经网络进行信息提取,得到解码器层的输出特征图dec∈rb×
l
ˊ
×cˊ
;然后将编码器层与解码器层的输出特征图进行维度拼接,再加上对其positional encoding后的值,共同作为注意力层的输入;在注意力层,利用残差注意力机制学习权重分布系数,加强重点区域的关注,抑制非重点区域的关注,进一步捕获音符序列特征,同时采用并行计算的统一掩码语言模型防止泄露未来信息和加快模型训练;最后,注意力层输出特征信息向量。
10.进一步的,上述lstm神经网络结构包含遗忘门、输入门、输出门与记忆单元,通过这些门控机制控制音符信息的输入、更新、添加和输出;遗忘门f
t
、输入门i
t
、输出门o
t
分别用公式表示为:f
t =σ(wf·
[h
t-1
, r
t
] + bf)i
t =σ(wi·
[h
t-1
, r
t
] + bi)o
t =σ(wo·
[h
t-1
, r
t
] + bo)其中,h
t-1
表示上一个时刻t-1的输出,r
t
表示当前时刻t的输入,σ(
·
)表示sigmoid函数,wf、wi、wo、bf、bi、bo均为参数;单元状态更新部分用公式表示为:c
t = f
t * c
t-1 + i
t * c
t
′
其中,c
t-1
、c
t
分别表示t-1、t时刻的记忆状态,c
t
′
= tanh(wi·
[h
t-1
, r
t
] + bi);当前时刻t的输出结果h
t
可用公式表示为:h
t = o
t * tanhc
t
其中,tanh(
·
)表示双曲正切函数。
[0011]
进一步的,上述positional encoding采用相对位置编码,其计算方式为:pe
(pos,2k) = sin(pos / 10000
2k / d
)pe
(pos,2k +1) = cos(pos / 10000
2k / d
)其中,pos表示音符在音符序列中的位置,d表示词向量的维度,k表示词向量中的第k个位置,sin(
·
)表示正弦函数,cos(
·
)表示余弦函数;注意力层的输入特征可用公式表示为:x = enc + dec + pe其中,x∈r b
×
l
ˊ
×cˊ
表示注意力层的输入特征。
[0012]
进一步的,上述注意力层包括多头掩码注意力块和前馈网络块,其中,在多头掩码注意力块中包含统一掩码语言模型和残差注意力块的计算;前馈网络块包含两个线性变换和一个函数激活操作。而在多头掩码注意力块和前馈网络块中均存在一个残差连接,并且其后均含有层归一化操作,使数据分布相对稳定;在多头掩码注意力块,上述特征x经过线性映射分别得到三个特征向量k、q、v,可分别用公式表示为:q = xwq,k = xwk,v = xwv其中,wq、wk、wv为参数,w
j = {j∈{q,k,v}|{w
0j
,w
1j
,
…
,wij,
…
}},i表示参数核的数目;统一掩码语言模型中的掩码矩阵m
ij
的计算公式为:其中,i表示音符词向量在序列的中的位置,j表示音符词向量中的位置;注意力权重系数scores的计算公式为:scores
l = softmax(qk
t / + m) + scores
l-1
其中,scores
l
表示当前层l的注意力权重系数,scores
l-1
表示上一层l-1的注意力权重系数,d表示q、v的向量维度;多头掩码注意力块的输出特征attention的计算公式为:attention
l = scores
l * v
l
其中,attention
l
表示第l层的多头掩码注意力块的输出特征,v
l
表示第l层的特征经过线性变换后的特征向量。
[0013]
进一步地,所述步骤s3具体包括以下步骤:通过获取到的基于残差注意力transformer的光学乐谱图像识别模型,提取到待识别乐谱图像中的音符序列特征f∈rb×
l〞
×
c〞
,该特征维度为(b, l〞, c〞),其中,b为每一批的数目,l〞为预测标签数,c〞为类别数。最后,使用softmax函数对像素特征进行概率预测,从而得到音符序列数字化结果,该输出结果y
_
的计算公式为:y_ = argmax(softmax(δ(f)))其中,δ(
·
)表示linear函数。
[0014]
进一步的,在训练基于残差注意力transformer的光学乐谱图像识别模型时,使用交叉熵损失函数对音符进行分类,通过最小化损失函数,对网络参数进行优化,使得输入乐
谱序列与数字化序列对齐。该交叉熵损失函数的表示公式为:其中,x、y分别为输入图像序列和其对应的真实标签,n∈[1,2,
…
,n],n为真实标签长度,c∈[1,2,
…
,c],c为类别数目,wyn为参数。
[0015]
上述内容表明,本发明提出的一种基于残差注意力transformer的神经网络方法用于光学乐谱图像识别,采用预训练的浅层残差卷积神经网络对参数初始化,提取音符基本特征,并且利用循环神经网络对获得的音符特征和标签序列分别进行编码和解码,提取音符序列的关联信息;而基于残差注意力transformer结构,对重点关注区域加强关注,抑制无关区域的关注,进一步提取音符序列上下文特征,同时以并行计算的统一掩码语言模型进行模型训练,能有效地降低音符序列错误率,缩短模型训练时间。
附图说明
[0016]
为了更清楚地说明本说明书的技术方案,下面将对技术方案中所需要使用的附图作简单地介绍。
[0017]
图1为本发明提供的基于残差注意力transformer的光学乐谱图像识别模型的一种流程示意图。
[0018]
图2为本发明提供的光学乐谱图像和预处理后的图像的一种示意图。
[0019]
图3为本发明提供的基于残差注意力transformer的光学乐谱图像识别模型的一种示意图。
[0020]
图4为本发明提供的编码器层的一种示意图。
[0021]
图5为本发明提供的解码器层的一种示意图。
[0022]
图6为本发明提供的统一掩码语言模型的一种示意图。
[0023]
图7为本发明提供的注意力层中某个注意力头结果可视化的一种示意图。
具体实施方式
[0024]
如图1所示为本发明提出的基于残差注意力transformer的光学乐谱图像识别模型的框架图,通过resnet网络、lstm和残差注意力transformer捕获音符的丰富特征,以及音符序列的全局和局部信息,使得乐谱图像中的音符序列识别准确率更高,并降低模型训练时间。
[0025]
本发明提出的一种基于残差注意力transformer的光学乐谱识别方法,具体包括以下步骤:第一步:获取待识别的光学乐谱图像并预处理;本发明首先对待识别的光学乐谱图像进行预处理。通过计算图像的列像素和,去除图像中非音符范围的像素,只保留所有的音符像素,并将保留下来的像素按原顺序拼接成预处理后的乐谱图像。如图2所示,(a)表示输入图像,(b)表示只由音符像素按序构成的乐谱图像。这种删除音符之间的空白方法可以减少冗余数据的计算,缩短训练时间。
[0026]
第二步:通过预先训练好的基于残差注意力transformer的光学乐谱图像识别模型,提取上述待识别的乐谱图像中的音符序列特征;如图3所示,基于残差注意力transformer的光学乐谱图像识别模型由一个编码器层、一个解码器层和一个注意力层构成。
[0027]
预处理后的乐谱图像首先被输入到编码器层,编码器层由预训练好的resnet18和两层双向的lstm神经网络组成。如图4所示,在编码器层,先是7*7的卷积和最大池化操作,接着连接3个3*3的卷积残差块,从而提取到图像中音符的基本特征。然后,特征图再经过两层双向lstm神经网络提取音符序列的特征信息,并且在resnet网络的输出和最后一层lstm网络的输出之间建立一个残差连接。最后获得编码器层的输出特征图 enc∈rb×
l
ˊ
×cˊ
。
[0028]
对于解码器层,先对标签序列进行embedding,再经过两层lstm神经网络进行序列信息提取,得到解码器层的输出特征图 dec∈rb×
l
ˊ
×cˊ
。解码器层结构如图5所示。
[0029]
进一步的,上述lstm神经网络包含遗忘门、输入门、输出门与记忆单元,通过这些门控机制控制音符信息的输入、更新、添加和输出;遗忘门f
t
、输入门i
t
、输出门o
t
分别用公式表示为:f
t =σ(wf·
[h
t-1
, r
t
] + bf)i
t =σ(wi·
[h
t-1
, r
t
] + bi)o
t =σ(wo·
[h
t-1
, r
t
] + bo)其中,h
t-1
表示上一个时刻t-1的输出,r
t
表示当前时刻t的输入,σ(
·
)表示sigmoid函数,wf、wi、wo、bf、bi、bo均为参数;单元状态更新部分用公式表示为:c
t = f
t * c
t-1 + i
t * c
t
′
其中,c
t-1
、c
t
分别表示t-1、t时刻的记忆状态,c
t
′
= tanh(wi·
[h
t-1
, r
t
] + bi);当前时刻 t的输出结果可用公式表示为:h
t = o
t * tanhc
t
其中,h
t
表示当前时刻t的输出结果,tanh(
·
)表示双曲正切函数。
[0030]
接着,将编码器层与解码器层的输出特征 enc和dec进行维度拼接,再加上positional encoding值,共同作为注意力层的输入;positional encoding采用相对位置编码,其用公式可表示为:pe
(pos,2k) = sin(pos / 10000
2k / d
)pe
(pos,2k +1) = cos(pos / 10000
2k / d
)其中,pos表示音符在音符序列中的位置,d表示词向量的维度,k表示词向量中的第k个位置,sin(
·
)表示正弦函数,cos(
·
)表示余弦函数;注意力层的输入特征可用公式表示为:x = enc + dec + pe其中,x∈r b
×
l
ˊ
×cˊ
表示注意力层的输入特征。
[0031]
然后,特征x进入注意力层。注意力层一共有4层,每一层含有一个多头掩码注意力块和一个前馈网络块,如图3中的注意力层部分所示。
[0032]
每个多头掩码注意力块包含统一掩码语言模型和残差注意力块的计算。一方面,注意力机制可以学习音符序列的全局和局部特征,进一步捕获音符序列上下文信息;而残
差注意力机制通过对前面注意力权重系数进行记录,并将其加入到下一层的注意力层中,这样方式能够考虑到前面的特征关联信息,加强重点区域的关注,而抑制非重点区域的关注;另一方面,在训练模型时,采用并行计算的统一掩码语言模型防止未来信息的泄露,可以加快模型训练。如图6所示,统一掩码语言模型中将整个序列“[s]t1t2t3t4[e]t5t6t7”作为输入,其中“[s]t1t2t3t4[e]”表示输入图像序列,“t5t6t7”表示对应的标签序列。图中蓝色格表示信息能看到,紫色格表示信息被遮掩。在预测输出音符时,其只能看到所有输入序列的信息和当前预测音符前面及其自己的信息,而不能看到当前预测音符后面的信息,这样可以防止泄露未来信息。
[0033]
在多头掩码注意力块,上述特征x经过线性映射分别得到三个特征向量k、q、v,可分别用公式表示为:q = xwq,k = xwk,v = xwv其中,wq、wk、wv为参数,w
j = {j∈{q,k,v}|{w
0j
,w
1j
,
…
,wij,
…
}},i表示参数核的数目;统一掩码语言模型中的掩码矩阵m
ij
的计算公式为:其中,i表示音符词向量在序列的中的位置,j表示音符词向量中的位置;注意力权重系数scores的计算公式为:scores
l = softmax(qk
t / + m) + scores
l-1
其中,scores
l
表示当前层l的注意力权重系数,scores
l-1
表示上一层l-1的注意力权重系数,d表示q、v的向量维度;多头掩码注意力块的输出特征attention的计算公式为:attention
l = scores
l * v
l
其中,attention
l
表示第l层的多头掩码注意力块的输出特征,v
l
表示第l层的特征经过线性变换后的特征向量。
[0034]
前馈网络块中包含两个线性变换和一个激活函数操作。另外,在多头掩码注意力块和前馈网络模块中各含有一个残差连接,之后再接层归一化操作,保持数据分布的稳定性。
[0035]
第三步:通过获取到的基于残差注意力transformer的光学乐谱图像识别模型,提取待识别乐谱图像中的音符序列特征f∈rb×
l〞
×
c〞
,该特征输出维度为(b, l〞, c〞),其中b为每一批的数目,l〞为预测标签数,c〞为类别数。最后,使用线性映射和softmax函数对最后一层注意力层的输出向量特征进行概率预测,从而得到最终的音符序列数字化输出结果,该输出结果公式y
_
的计算公式为:y_ = argmax(softmax(δ(f)))其中,δ(
·
)表示linear函数。
[0036]
在训练基于残差注意力transformer的光学乐谱图像识别模型时,使用交叉熵损失函数对音符进行分类,通过最小化损失函数,对网络结构进行优化,使得输入乐谱序列与数字化序列对齐。该交叉熵损失函数的计算公式为:
其中,x、y分别为输入图像序列和其对应的真实标签,n∈[1,2,
…
,n],n为真实标签长度,c∈[1,2,
…
,c],c为类别数目,wyn为参数。
[0037]
最后,本发明所提出的方法在公共数据集上进行基准测试,测试结果表明,该方法对音符序列的识别具有高准确率。
[0038]
数据集:本发明使用的数据集为printed images of music staves(简称primus),包含了87,678个真实世界的光学乐谱样本和其对应的数字化语义编码。每个样本图像是一行被小节线划分为多节的带有谱线的音符序列,含有谱号、音符、休止符、小节线和附点等多种识别难度不同的符号。本发明将所有数据集划分为训练集和测试集,训练集含有78,755个样本,测试集含有8,923个样本,其中训练集中的90%用于模型训练,剩余的10%用于优化参数以验证模型性能。
[0039]
参数设置与训练:本发明提出的方法基于pytorch框架采用python语言实现,计算在nvidia geforce rtx 3090,cuda 11.3,memory 24g条件下进行。每个样本图像预处理后缩放为高等于64像素,宽长度可变的图像,再输入到光学乐谱图像识别模型中进行识别。为了保证目标函数在适当的时间收敛于最优值,将batch size设置为16,学习率设置为0.0001;采用adam优化器,使得计算高效,对内存需求少,参数更新不受梯度的伸缩变换影响,且通常无需调整或仅需很少的微调;设置停止策略,当模型在50轮以内指标未下降时停止训练。结果表明,上述参数设置可以优化识别模型,有效提高音符序列的识别准确度。
[0040]
评价指标:本发明采用了光学乐谱识别中常用的两个评价指标,序列错误率和符号错误率。序列错误率是指不正确的音符序列数(音符序列中至少有1个音符被错误识别)占总序列数的比例。符号错误率是指将预测序列与真实标签进行比较,计算编辑操距离(包括插入、修改和删除)的平均数。序列错误率seer和符号错误率syer可用公式分别表示为:seer = i
sequence / t
sequence
syer = e
symbol / t
symbol
其中,i
sequence
表示预测不正确的序列数,t
sequence
表示所有的序列数,e
symbol
表示对预测序列操作的编辑距离,t
symbol
表示所有的音符数。
[0041]
本发明提出的基于残差注意力transformer的光学乐谱图像识别方法应用在primus数据集上,以光学乐谱图像作为输入,以音符序列的语义编码作为输出,为进一步评估该方法的有效性,设计了如下几个实验:(1)基于卷积循环神经网络与connectionist temporal classification损失函数的光学乐谱图像识别(简称crnn-ctc);(2)基于多尺度卷积循环神经网络与transformer的光学乐谱图像识别(简称scalecrnn-trans);(3)基于残差卷积循环神经网络与transformer的光学乐谱图像识别(简称resnet-rnn-trans);(4)本发明提出的基于残差注意力transformer的光学乐谱图像识别。表1列出了上述四种方法在测试集上得到的评价结果。
[0042]
表1 本发明提出的基于残差注意力transformer神经网络模型性能比较
由表1可以看出,本发明所提出的方法在音符序列语言编码中可以获得更低的序列错误率和符号错误率。
[0043]
图7是注意力层中某个注意力头结果可视化示意图。从图中可以看出,对于所示的光学乐谱图像(如绿色部分所示),可以得到一一对应的数字化音符序列(如坐标轴上的纵坐标所示)。而且对于如附点、小节线等难以识别的音符或是像素重叠在一起的音符,本发明提出的方法都可以准确识别。因此,本发明提出的基于残差注意力transformer的光学乐谱图像识别方法可以有效地提高音符序列识别准确度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1