基于CRAFT和SCRN-SEED框架的自然场景文字检测识别方法
基于craft和scrn-seed框架的自然场景文字检测识别方法
技术领域
1.本发明涉及文字检测方法技术领域,特别涉及基于craft和scrn-seed框架的自然场景文字检测识别方法。
背景技术:
2.光学字符识别(optical character recognition,ocr)传统上指对输入扫描文档图像进行分析处理,识别出图像中的文字信息,此类技术假设输入图像背景干净、字体简单且文字排布整齐,在符合要求的情况下能够达到较高的识别水平。而场景文字识别(scene text recognition,str)指识别自然场景图片中的文字信息,其难度远大于扫描文档图像中的文字识别,自然场景文字展现形式极其丰富,可能存在以下多种情况:文本行有横向、竖向、弯曲、旋转、扭曲等多种式样;图像中的文字区域产生残缺、模糊等现象;背景多样,如文字出现在平面、曲面或褶皱面,文字区域附近有复杂的干扰纹理,或非文字区域有近似文字的纹理,比如沙地、草丛、栅栏、砖墙等。
3.基于神经网络的场景文本检测方法取得了较好的效果,在检测和识别中远超传统技术,但仍然不能很好的解决自然场景中出现的弯曲、模糊干扰纹理等问题。现有的自然场景文字检测方法存在以下问题:文字定位不精确,传统文本定位模型框架,大多关注整行文本,需要很大的感受野,且采用单一的矩形框来标注文本所在位置,这对于弯曲、变形或者极长的文本不太适用,难以精确定位标注;文字识别不准确,提出的许多基于编码器-解码器框架的识别方法,用于处理弯曲文本,然而其大多基于局部视觉特征,而忽略了全局语义信息,因而,在面对如图像模糊、光照不均和字符不完整等情况时,识别准确度大大降低。
技术实现要素:
4.发明目的:针对以上问题,本发明目的是提供一种基于craft和scrn-seed框架的自然场景文字检测识别方法。
5.技术方案:本发明的一种基于craft和scrn-seed框架的自然场景文字检测识别方法,包括如下步骤:
6.(1)利用真实数据集和合成数据集建立图像数据集,将图像数据集分为训练集和测试集;
7.(2)利用图像数据集训练craft网络:
8.(201)将craft网络进行改进,以resnet50网络作为主干网络,将合成数据集中的图片输入到改进后的craft网络进行特征提取,输出区域得分和亲和度得分;
9.(202)根据两项得分通过高斯热力映射进行编码,生成高斯热力图;
10.(203)根据分水岭算法将输入图片中完整文本切割成单个字符,通过后处理操作将字符生成任意形状文本的多边形;
11.(203)应用迁移学习的思想,利用预训练模型初始化改进后的craft网络;
12.(3)利用真实数据集训练不规则文本纠正网络scrn;
13.(4)将scrn与seed网络结合,训练结合后的scrn-seed网络;
14.(5)将改进后的craft网络、scrn-seed网络连接,构建完整的模型并进行训练。
15.进一步,所述应用迁移学习的思想,利用预训练模型初始化改进后的craft网络的步骤包括:
16.首先,使用合成数据集训练craft网络,使用adam优化器优化网络,再利用多个真实数据集微调网络,在微调期间,以1:5的比率使用synthtext数据集,以1:3的比例使用在线难例挖掘;
17.然后,使用含有四边形标注的真实数据集和synthtext数据集训练craft网络,将其中一部分划分为测试集对网络参数进行调整。
18.进一步,所述将scrn与seed网络结合,训练结合后的scrn-seed网络的步骤包括:
19.用训练后的scrn网络代替seed网络中的图像纠正模块,构建scrn-seed网络,利用语义模型fasttext的预训练语言模型初始化预训练模型的参数,利用测试集初步训练scrn-seed网络,根据训练效果调整网络参数。
20.进一步,将改进后的craft网络与scrn-seed网络连接,构建完整的模型并对其进行训练的步骤包括:将任意形状文本的多边形生成包含所有字符的最小矩形框,将矩形框裁剪出来,调整裁剪后图片格式,然后输入到scrn-seed网络完成模型的构建,利用验证集对模型进行训练,将训练效果最优的参数保留,输入自然场景下的图片到模型中,进行自动文字检测与识别任务。
21.进一步,所述真实数据集来自icdar2013、icdar2015、icdar2017、msra-td500、totaltext、ctw-1500等,所述合成数据集为synthtext数据集;
22.调整图像数据集中每个图片的大小,将数据集中的图片格式转换mdb格式。
23.有益效果:本发明与现有技术相比,其显著优点是:
24.1、本发明能够充分检测弯曲变形文本或长篇文本实例,通过精确地定位每一个字符,然后再把检测到的字符通过亲和力机制连接成一个文本达到检测的目的,只需要关注字符以及字符之间的距离,不需要关注整行文本,不需要很大的感受野,对于弯曲、变形或者极长的文本都适用;
25.2、本发明能够精确的识别低质量的文本实例:本发明将检测器的输出结果通过scrn的矫正模块来矫正不规则文本图片,scrn网络借助每个文字实例的中心线,并通过一些几何属性,来达到矫正的目的,效果更好;矫正后的文本图片通过seed网络中的识别模块进行文字识别工作,将语义信息用于全局信息的预测,在有缺损、模糊现象等的文本识别上精确度大大提高。
附图说明
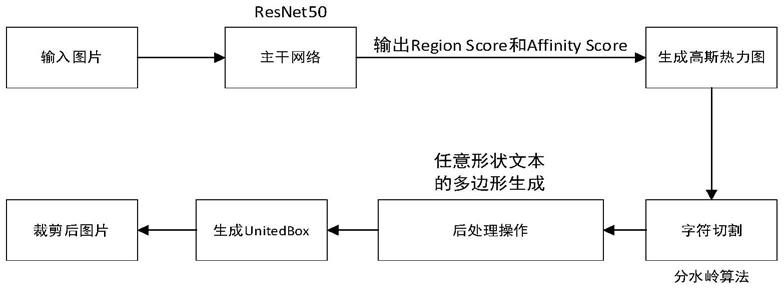
26.图1为本发明改进后craft模型基本框架图;
27.图2为本发明采用的不规则文本纠正网络scrn的基本框架图;
28.图3为本发明采用的seed网络识别模块的基本框架图;
29.图4为本发明的自然场景文字检测识别方法的整体模型结构图;
30.图5为本发明的自然场景文字检测识别方法的样例效果图。
具体实施方式
31.本实施例所述的基于craft和scrn-seed框架的自然场景文字检测识别方法,包括如下步骤:
32.(1)利用真实数据集和合成数据集建立图像数据集,将图像数据集分为训练集和测试集,调整图像数据集中每个图片的大小,将数据集中的图片格式转换mdb格式。
33.其中真实数据集来自icdar2013、icdar2015、icdar2017、msra-td500、totaltext、ctw-1500中,合成数据集为synthtext数据集。
34.(2)利用图像数据集训练craft网络,流程图如图1所示。
35.(201)将craft网络进行改进,以resnet50网络作为主干网络,将合成数据集中的图片输入到改进后的craft网络进行特征提取,输出区域得分region score和亲和度得分affinity score;
36.(202)根据两项得分通过高斯热力映射进行编码,生成高斯热力图;
37.(203)根据分水岭算法将输入图片中完整文本切割成单个字符,通过后处理操作将字符生成任意形状文本的多边形;
38.(203)应用迁移学习的思想,利用预训练模型初始化改进后的craft网络:
39.首先,使用合成数据集训练craft网络,使用adam优化器优化网络,再利用多个真实数据集微调网络,在微调期间,以1:5的比率使用synthtext数据集,以确保字符区域肯定是分开的,以1:3的比例使用在线难例挖掘,还可以应用数据增强技术,如裁剪、旋转或颜色变化。
40.然后,使用含有四边形标注的真实数据集和synthtext数据集训练craft网络,将其中一部分划分为测试集对网络参数进行调整。
41.(3)利用真实数据集训练不规则文本纠正网络scrn,网络框架如图2所示。
42.(4)将scrn与seed网络结合,训练结合后的scrn-seed网络将其作为识别网络。原seed网络中识别模块的框架如图3所示。
43.用训练后的scrn网络代替原seed网络中的图像矫正模块,构建scrn-seed网络,以此提高不规则文本的矫正效果和识别的准确度,降低模型训练的难度。根据所需识别语言,下载语义模型语义模型fasttext的预训练语言模型,初始化预训练模型的参数,利用测试集初步训练scrn-seed网络,根据训练效果调整网络参数。
44.(5)将改进后的craft网络与scrn-seed网络连接,构建完整的模型并进行训练。
45.将任意形状文本的多边形生成包含所有字符的最小矩形框,将矩形框裁剪出来,调整裁剪后图片格式,然后输入到scrn-seed网络完成模型的构建。构建之后的模型框架如图4所示,包括三部分,利用craft网络作为检测器部分,scrn网络作为纠正网络部分,seed网络作为识别部分。利用验证集对模型进行训练,将训练效果最优的参数保留,输入自然场景下的图片到模型重,进行自动文字检测与识别任务,图5为自然场景下的图片通过模型进行定位和识别时经过每一部分的效果图。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1