一种基于注意力机制的神经网络模型
1.本发明涉及自然语言处理与计算机视觉领域,涉及语言处理、图像处理、深度学习技术,具体涉及一种基于注意力机制的神经网络模型。
背景技术:
2.当前移动端用户参与网络社交互动需要在更短的时间内产生或接收到更多信息,用户无法容忍阅读大篇幅文字或观看冗长的视频而产生的焦虑感。因此,各种媒体平台上的跨媒体舆情数据呈现出体量小、内容杂、规模大、产生速度快等重要特点,如短视频的时长通常小于五分钟,微博的长度多集中在100字以内,但是舆情分析的研究工作一般是单一的文本数据或者图像数据。
3.本方案拟研究一种基于文本语义的跨媒体舆情分析方法。该方法拟设计一种基于注意力机制的神经网络模型,该模型可同时处理两种社交媒体数据,即纯文本数据和图像数据结合的跨媒体数据,将舆情分析的研究工作从单一的文本数据拓展到更符合现实场景的跨媒体数据上。
技术实现要素:
4.本发明的目的是提供一种基于注意力机制的神经网络模型,该模型可同时处理纯文本数据和图像数据结合的跨媒体数据,并且能够利用注意力机制进行跨媒体数据的舆情分析。
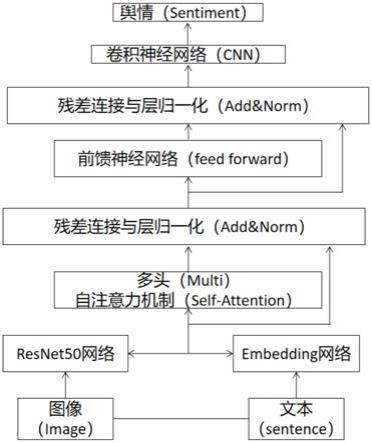
5.一种基于注意力机制的神经网络模型,包括位置编码与数据编码、多头自注意力机制、残差连接与层归一化、前馈神经网络(feed forward)、卷积神经网络这五个模块。其中:残差连接与层归一化模块使用了两次,其他模块各使用一次;位置编码与数据编码采用embedding网络和resnet50网络来实现,所述一种基于注意力机制的神经网络模型设置位置编码用来获取位置信息,并且可以同时输入整个数据。这种数据的编码不仅包含位置信息,也包含数据自身信息,是在三个通道上相应的去计算位置编码。位置编码的公式如下,其中pos代表位置,d代表数据编码的维度。
6.pe
(pos,2i)
=sin(pos/10000
2i/d
)
7.pe
(pos,2i+1)
=cos(pos/10000
2i/d
)
8.对于文本数据编码选择embedding网络随机初始化的方式。对于图像数据编码,利用resnet50网络进行特征提取。图像和文本的数据经过位置编码与数据编码后得到矩阵x,再由多头自注意力机制(muti-head-self attention)处理,多头自注意力机制是由h个自注意力机制(self-attention)层并行组成。将文本与图像对作为输入,经过位置编码与数据编码之后得到的矩阵x经过第一个线性变换得到query(q)矩阵,x经过第二个线性变换得到key(k)矩阵,x经过第三个线性变换得到value(v)矩阵,这三个线性变换的权重参数分别为wq、wk、wv,他们相互独立,通过训练得到。得到的这三个q、k、v矩阵经过以下公式进行计算,可得到attention矩阵。其中d是k矩阵的第二个维度。
[0009][0010]
得到每个词的上下文语义的向量表示,这个向量也能够像我们人一样,更多地包含重要的信息,也就是将重要信息的权重增大,不重要的信息的权重减小。采用自注意力机制将能够让模型更大程度的去理解文本,学习到文本中每个词语之间的语义关系,并且能够给数据合理的分配权重。
[0011]
作为本发明的一种优选技术方案,矩阵x经过三个线性变换后得到的q、k、v矩阵,维度都是词数*词向量维度。h=8,h为“头数”,把q、k、v三个矩阵按词向量维度切割8份,分成维度为h*词数*词向量维度/8,即对于q、k、v都有8个与之对应的矩阵。将这8组q、k、v矩阵分别进行自注意力机制网络处理之后,再将8个attention矩阵拼接起来,经过一个线性层处理就能得到与输入矩阵x维度相同的矩阵z。使用多头注意力机制来处理可以形成多个子空间,可以让模型去关注不同方面的信息。经过多头注意力机制后得到矩阵z,再将矩阵z进行残差连接操作,将z矩阵与输入矩阵x进行相加,之后将得到的新矩阵z1进行层归一化,层归一化可以解决反向传播时的梯度爆炸、可以使用较大的学习率以及缓解过拟合。然后前馈神经网络(feed forward)将z1输入,进行升维,降维操作,学习到更多关于数据的信息。让信息再经过一个残差连接与层归一化(add&norm)层,然后输出一个维度与x一样的矩阵z2,所述的矩阵z2中包含着图像与文字的信息,再利用卷积神经网络(cnn)来进行图文信息的融合。
[0012]
作为本发明的一种优选技术方案,前馈神经网络(feed forward)(feed forward)中包含两个线性变换以及一个relu激活函数,公式如下表示。
[0013]
ffn(z1)=max(0,z1w1+a)w2+b
[0014]
作为本发明的一种优选技术方案,卷积神经网络中采用三个卷积层、三个池化层以及全连接层。全连接层的最后一层是分类层,激活函数是softmax,其它全连接层激活函数是relu。
[0015]
作为本发明的一种优选技术方案,要对基于注意力机制的神经网络模型训练,训练时采用交叉熵损失函数,保存训练好的网络模型用于舆情分析。
[0016]
本发明具有以下优势:
[0017]
1.本发明提出的神经网络模型能够利用深度学习技术融合语言与图像数据信息,将跨媒体数据用在舆情分析上,并且两种类型的数据能够共享模型参数,节约了成本资源。
[0018]
2.本发明能够很好的利用注意力机制来获取数据所表达的信息,设计出了一种具有多头自注意力机制的模型,将跨媒体数据所表达的含义理解透彻,能够有效的进行舆情分析。
附图说明
[0019]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0020]
图1为本发明一种基于注意力机制的神经网络模型示意图。
具体实施方式
[0021]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0022]
实施例:如图1所示,一种基于注意力机制的神经网络模型,包括位置编码与数据编码、多头自注意力机制、残差连接与层归一化、前馈神经网络(feed forward)、卷积神经网络这五个模块。其中:残差连接与层归一化模块使用了两次,其他模块各使用一次;位置编码与数据编码采用embedding网络和resnet50网络来实现,所述一种基于注意力机制的神经网络模型设置位置编码用来获取位置信息,并且可以同时输入整个数据。这种数据的编码不仅包含位置信息,也包含数据自身信息,是在三个通道上相应的去计算位置编码。位置编码的公式如下,其中pos代表位置,d代表数据编码的维度。
[0023]
pe
(pos,2i)
=sin(pos/10000
2i/d
)
[0024]
pe
(pos,2i+1)
=cos(pos/10000
2i/d
)
[0025]
对于文本数据编码选择embedding网络随机初始化的方式。对于图像数据编码,利用resnet50网络进行特征提取。图像和文本的数据经过位置编码与数据编码后得到矩阵x,再由多头自注意力机制(muti-head-self attention)处理,多头自注意力机制是由h个自注意力机制(self-attention)层并行组成。将文本与图像对作为输入,经过位置编码与数据编码之后得到的矩阵x经过第一个线性变换得到query(q)矩阵,x经过第二个线性变换得到key(k)矩阵,x经过第三个线性变换得到value(v)矩阵,这三个线性变换的权重参数分别为wq、wk、wv,他们相互独立,通过训练得到。得到的这三个q、k、v矩阵经过以下公式进行计算,可得到attention矩阵。其中d是k矩阵的第二个维度。
[0026][0027]
得到每个词的上下文语义的向量表示,这个向量也能够像我们人一样,更多地包含重要的信息,也就是将重要信息的权重增大,不重要的信息的权重减小。采用自注意力机制将能够让模型更大程度的去理解文本,学习到文本中每个词语之间的语义关系,并且能够给数据合理的分配权重。
[0028]
作为本发明的一种优选技术方案,矩阵x经过三个线性变换后得到的q、k、v矩阵,维度都是词数*词向量维度。h=8,h为“头数”,把q、k、v三个矩阵按词向量维度切割8份,分成维度为h*词数*词向量维度/8,即对于q、k、v都有8个与之对应的矩阵。将这8组q、k、v矩阵分别进行自注意力机制网络处理之后,再将8个attention矩阵拼接起来,经过一个线性层处理就能得到与输入矩阵x维度相同的矩阵z。使用多头注意力机制来处理可以形成多个子空间,可以让模型去关注不同方面的信息。经过多头注意力机制后得到矩阵z,再将矩阵z进行残差连接操作,将z矩阵与输入矩阵x进行相加,之后将得到的新矩阵z1进行层归一化,层归一化可以解决反向传播时的梯度爆炸、可以使用较大的学习率以及缓解过拟合。然后前馈神经网络(feed forward)将z1输入,进行升维,降维操作,学习到更多关于数据的信息。让信息再经过一个残差连接与层归一化(add&norm)层,然后输出一个维度与x一样的矩阵z2,所述的矩阵z2中包含着图像与文字的信息,再利用卷积神经网络(cnn)来进行图文信息
的融合。
[0029]
进一步的,前馈神经网络(feed forward)(feed forward)中包含两个线性变换以及一个relu激活函数,公式如下表示。
[0030]
ffn(z1)=max(0,z1w1+a)w2+b
[0031]
进一步的,卷积神经网络中采用三个卷积层、三个池化层以及全连接层。全连接层的最后一层是分类层,激活函数是softmax,其它全连接层激活函数是relu。
[0032]
进一步的,要对基于注意力机制的神经网络模型训练,训练时采用交叉熵损失函数,保存训练好的网络模型用于舆情分析。
[0033]
具体的,本发明使用时,按照如下步骤实施:
[0034]
(1)输入一个文本图片对,输入图片维度是3*200*250,经过resnet50之后维度变为2048*16*8,然后加入位置编码,位置编码维度是2048*16*8,再通过降维操作将图片维度变为256*128,此时特征中已经包含图片信息以及相应的位置信息。
[0035]
(2)将输入文本的长度固定为128,由于在所有文本中,最长的文本中有128个字,长度不够128的文本进行增添操作以使文本长度达到128。首先随机初始化一个词向量矩阵。这个矩阵的维度是128*256,即词向量的维度是256。再加入位置编码,位置编码的维度与词向量矩阵维度一致。之后将图片特征矩阵的转置与词向量矩阵进行拼接得到输入矩阵x,此时x的维度是256*256。
[0036]
(3)接下来输入矩阵x进入muti-head-self attention层进行计算,其中q、k、v矩阵的维度与x的维度一致,wq,wk,wv参数矩阵的维度是256*256。
[0037]
经过计算得到的矩阵x1维度仍然是256*256。
[0038]
(4)然后将得到的x1矩阵与x矩阵进行残差连接得到x2矩阵,将x2进行归一化得到z矩阵。其中z矩阵的维度是256*256
[0039]
(5)接下来进行z矩阵进入前馈神经网络(feed forward)中,再将结果送入add&norm层中,得到的z1维度依然不变,是256*256。
[0040]
(6)然后利用卷积神经网络进行特征融合。首先z1进入卷积层,卷积核的大小为3*256,步长为1,然后进入最大池化层,池化窗的大小的是48,步长是1。这里加入了三个卷积层与池化层,即上述步骤进行三次。进行池化后,再进入全连接层。全连接层起到一个降维作用,全连接层的最后一层是分类层,激活函数是softmax,其它全连接层激活函数是relu。
[0041]
通过以上步骤,我们将输出此数据的情感极性,进行舆情分析。
[0042]
试验例:
[0043]
1.数据集
[0044]
本发明使用了从yelp.com的食品和餐馆类别爬取的在线评论数据集,涵盖了5个不同的美国主要城市,即:波士顿(bo)、芝加哥(ch)、洛杉矶(la)、纽约(ny)和旧金山(sf)。该数据集总共有超过4.4万条评论,其中包括24.4万张图片。每个评论大约有3张图像。
[0045]
2.训练策略
[0046]
本次训练采用交叉熵损失函数。在本次训练中,对于每个评论,我们仅使用一张图片进行训练,即一个文本图片对。在训练时,设置每条评论的文本长度为128,每个单词的词向量维度为256。每张图片的初始维度为3*200*250,为了适合模型的输入,需要将它转换为128*256,这个维度是可变的。在多头自注意力机制层,设置h=8。batch size大小为32。
[0047]
3.实验结果:
[0048]
我们在这五个数据集上分别使用了tfn-avgg、tfn-mvgg、bigru-avgg、bigru-mvgg、han-avgg、han-mvgg、ourmodel这七种模型进行了实验。实验结果如表1所示,相比于其他五种模型,本方案提出的模型更能有效的识别跨媒体数据的情感极性。
[0049][0050][0051]
表1实验结果
[0052]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1