基于对手动作预测的智能体策略获取方法及相关装置
1.本技术涉及人工智能技术领域,尤其涉及一种基于对手动作预测的智能体策略获取方法及相关装置。
背景技术:
2.随着人工智能技术的发展,多智能体强化学习技术在机器博弈、实时策略游戏、机器人控制、汽车自动驾驶等领域得到了应用。多智能体强化学习任务中,通常包括一个共享的对抗环境和多个智能体,每个智能体与环境本身以及其他智能体进行交互。每个时刻,智能体根据自身状态,依据特定的策略从动作空间中选择动作并执行,对环境产生作用进而得到奖励或惩罚,直到时间终止或任务完成。
3.与单智能体强化学习的设定不同,多智能体强化学习中存在典型的“非平稳性”(non-stationarity)问题,马尔可夫决策过程不再适用。这是因为在多智能体环境中,智能体的策略不仅取决于环境,还受到其他智能体动作的影响。而且,随着每个智能体策略学习的进行,它们的决策模型是随时间变化的(不平稳的),因此智能体学习环境的动力学模型(奖励函数和状态转移概率)不再满足马尔可夫性,使得学习变得更加困难。
技术实现要素:
4.有鉴于此,本技术的目的在于提出一种基于对手动作预测的智能体策略获取方法及相关装置。
5.基于上述目的,本技术提供了一种基于对手动作预测的智能体策略获取方法,包括:
6.从所述智能体所处的环境中获取环境状态,并提取所述环境状态的特征,得到环境状态特征;
7.将所述环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征;
8.提取所述环境状态特征的隐层特征,得到q值隐层特征;
9.融合所述q值隐层特征和所述对手策略特征,得到融合特征;
10.将所述融合特征输入预先构建的竞争网络,得到q值函数;
11.获取所述智能体的备选动作,根据所述q值函数,得到所述备选动作对应于所述环境状态的q值,将所述q值最大的所述备选动作作为所述智能体的执行动作。
12.可选的,所述对手动作预测网络中包含全连接隐层;
13.所述将所述环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征,具体包括:
14.将所述环境状态特征输入所述全连接隐层,得到全连接隐层特征,将所述全连接隐层特征作为所述对手策略特征。
15.可选的,所述对手动作预测网络中还包含动作表示层;
16.所述方法,还包括:
17.将所述全连接隐层特征输入所述动作表示层,得到预测的对手策略分布;
18.从所述环境中获取真实的对手策略分布;
19.基于所述预测的对手策略分布和所述真实的对手策略分布,利用预设的对手动作预测网络的损失函数调整所述全连接隐层的参数。
20.可选的,所述将所述全连接隐层特征输入所述动作表示层,得到预测的对手策略分布,具体包括:
21.响应于确定对手动作空间为离散空间,所述动作表示层输出每个动作的概率分布,作为所述预测的对手策略分布;
22.响应于确定所述对手动作空间为连续空间,利用高斯分布表示所述预测的对手策略分布,所述动作表示层输出所述预测的对手策略分布的均值和方差。
23.可选的,所述融合所述q值隐层特征和所述对手策略特征,得到融合特征,具体包括:
24.串联拼接所述q值隐层特征和所述对手策略特征,得到所述融合特征。
25.可选的,所述将所述融合特征输入预先构建的竞争网络,得到q值函数,具体包括:
26.将所述融合特征输入预先构建的竞争网络,得到状态价值函数和动作优势函数;
27.聚合所述状态价值函数和所述动作优势函数,得到所述q值函数。
28.可选的,所述获取所述智能体的备选动作,根据所述q值函数,得到所述备选动作对应于所述环境状态的q值,将所述q值最大的所述备选动作作为所述智能体的执行动作,具体包括:
29.将所述q值最大的所述备选动作输入预先构建的目标网络,得到目标q值;
30.基于所述目标q值和最大的所述q值,利用预设的竞争网络的损失函数调整所述竞争网络的参数。
31.基于同一发明构思,本技术提供了一种基于对手动作预测的智能体策略获取装置,包括:
32.环境状态特征获取模块,用于从所述智能体所处的环境中获取环境状态,并提取所述环境状态的特征,得到环境状态特征;
33.对手策略特征获取模块,用于将所述环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征;
34.q值隐层特征获取模块,用于提取所述环境状态特征的隐层特征,得到q值隐层特征;
35.融合特征获取模块,用于融合所述q值隐层特征和所述对手策略特征,得到融合特征;
36.q值函数获取模块,用于将所述融合特征输入预先构建的竞争网络,得到q值函数;
37.执行动作确定模块,用于获取所述智能体的备选动作,根据所述q值函数,得到所述备选动作对应于所述环境状态的q值,将q值最大的所述备选动作作为所述智能体的执行动作。
38.基于同一发明构思,本技术提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述的方法。
39.基于同一发明构思,本技术提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使计算机执行上述方法。
40.从上面所述可以看出,本技术提供的基于对手动作预测的智能体策略获取方法及相关装置,从智能体所处的环境中获取环境状态,并提取环境状态的特征,得到环境状态特征;将环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征;提取环境状态特征的隐层特征,得到q值隐层特征;融合q值隐层特征和对手策略特征,得到融合特征;将融合特征输入预先构建的竞争网络,得到q值函数;获取智能体的备选动作,根据q值函数,得到备选动作对应于环境状态的q值,将q值最大的备选动作作为智能体的执行动作。本技术能够有效预测对手动作,加快学习收敛速度,可以应对多种类型的对手。
附图说明
41.为了更清楚地说明本技术或相关技术中的技术方案,下面将对实施例或相关技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
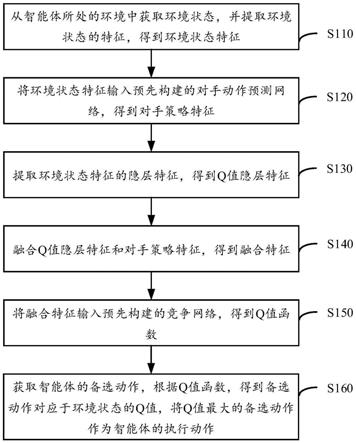
42.图1为本技术实施例提供的基于对手动作预测的智能体策略获取方法的流程示意图;
43.图2为根据本技术实施例提供的基于对手动作预测的智能体策略获取方法的数据流的示意图;
44.图3为根据本技术实施例提供的实验环境的示意图;
45.图4为根据本技术实施例提供的对手决策树的示意图;
46.图5为本技术实施例提供的策略预测准确率曲线的示意图;
47.图6为本技术实施例提供的损失函数曲线的示意图;
48.图7为本技术实施例提供的策略学习曲线对比的示意图;
49.图8为本技术实施例提供的基于对手动作预测的智能体策略获取装置的结构示意图;
50.图9本技术实施例提供的一种更为具体的电子设备硬件结构示意图。
具体实施方式
51.为使本技术的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本技术进一步详细说明。
52.需要说明的是,除非另外定义,本技术实施例使用的技术术语或者科学术语应当为本技术所属领域内具有一般技能的人士所理解的通常意义。本技术实施例中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
53.如背景技术部分所述,多智能体强化学习中存在典型的“非平稳性”(non-stationarity)问题。
54.本技术缓解多智能体学习中“非平稳性”问题的发明思路在于对手建模,即对环境中对手的行为信息进行建模和预测,智能体决策时再加以利用以做出更具有前瞻性的决策。
55.相关技术中,对对手建模的方法主要有两种,一种是信念-愿望-意图(belief-desire-intention,bdi)模型,其本质是传统符号主义人工智能学派的逻辑推演方法,该方法解释性强,但建模困难,只能解决单一领域内的问题。另一种是基于动态影响图的方法,其本质是概率图模型中的贝叶斯网络,建模时需要较强的领域内先验知识,而且学习后验概率时计算复杂。
56.有鉴于此,本技术提出一种基于对手动作预测的智能体策略获取方法及相关装置。
57.本技术实施例提供的基于对手动作预测的智能体策略获取方法及相关装置,可以应用在机器博弈、实时策略游戏、机器人控制、汽车自动驾驶等领域。
58.参考图1,其为本技术实施例提供的基于对手动作预测的智能体策略获取方法的一种流程示意图。
59.基于对手动作预测的智能体策略获取方法,执行主体为智能体。
60.智能体(agent)是人工智能领域中的一个概念,指能自主活动的软件或者硬件实体。智能体是驻留于环境中的实体,它可以解释从环境中获得的反映环境中所发生事件的数据,并执行对环境产生影响的行动。如上所述,智能体感测环境并且执行相应的动作,其中,智能体策略指的是智能体从动作空间中选择动作并执行。
61.基于对手动作预测的智能体策略获取方法,包括:
62.s110、从智能体所处的环境中获取环境状态,并提取环境状态的特征,得到环境状态特征。
63.其中,环境状态指的是反映环境中所发生事件的数据。
64.在一些实施例中,从环境中获取环境状态,并对环境状态进行特征编码提取环境状态的特征,得到环境状态特征h
t
。h
t
表征了环境状态的浅层次的特征,其作为后续步骤的输入,后续步骤将对其进行更有针对性的、更深入的提取。
65.在一些实施例中,通过递归神经网络、卷积神经网络和全连接神经网络中的至少一种对环境状态进行特征编码提取环境状态的特征。其中,递归神经网络用于处理时间(序列)类数据;卷积神经网络用于处理空间(图像)类数据;全连接神经网络用于处理统计类数据。基于此,可以处理不同数据类型的环境状态。
66.s120、将环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征。
67.其中,对手动作预测网络中包含全连接隐层;将环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征,具体包括:
68.将环境状态特征输入全连接隐层,得到全连接隐层特征,将全连接隐层特征作为对手策略特征。
69.在一些实施例中,环境状态特征h
t
经过全连接隐层得到全连接隐层特征h
pi
,将全连接隐层特征h
pi
作为对手策略特征。
70.需要说明的是,环境状态特征h
t
是对手动作预测网络的中间产物而不是输出,因此,实质上是对对手的隐式建模。对手动作预测网络的输出,用于学习对手的策略分布,以更新对手动作预测网络。
71.在一些实施例中,对手动作预测网络中还包含动作表示层;
72.所述方法,还包括:
73.将全连接隐层特征输入动作表示层,得到预测的对手策略分布;
74.从环境中获取真实的对手策略分布;
75.基于预测的对手策略分布和真实的对手策略分布,利用预设的对手动作预测网络的损失函数调整全连接隐层的参数。
76.在一些实施例中,全连接隐层特征h
pi
经过动作表示层,得到预测的对手策略分布π
oppo
。
77.构建对手动作预测网络的损失函数,用于学习对手的策略分布。对手动作预测网络的损失函数通过预测的对手策略分布和真实的对手策略分布的交叉熵构建。
78.预设的对手动作预测网络的损失函数为:
[0079][0080]
其中,l
pi
(θ)表示对手动作预测网络的损失函数;d
cross entropy
表示交叉熵函数;π
oppo*
表示真实的对手策略分布;π
oppo
(θ)表示预测的对手策略分布;s表示环境状态;a表示对手动作。
[0081]
在一些实施例中,真实的对手策略分布通过获取环境中对手一系列时间步的行为动作得到。
[0082]
在一些实施例中,用独热编码(one-hot encoding)表示真实的对手策略分布。
[0083]
对于不同的对手动作空间,预测的对手策略分布的表示方式不同。
[0084]
在一些实施例中,将全连接隐层特征输入动作表示层,得到预测的对手策略分布,具体包括:
[0085]
响应于确定对手动作空间为离散空间,动作表示层输出每个动作的概率分布,作为预测的对手策略分布;
[0086]
响应于确定对手动作空间为连续空间,利用高斯分布表示预测的对手策略分布,动作表示层输出预测的对手策略分布的均值和方差。
[0087]
在一些实施例中,对手动作空间为离散空间。
[0088]
动作表示层为softmax层,动作表示层输出每个动作的概率分布,即预测的对手策略分布π
oppo
(a|s;θ)。
[0089]
其中,
[0090][0091]
其中,s表示环境状态;θ表示环境状态和对手动作之间的映射;a表示对手动作。
[0092]
在一些实施例中,对手动作空间为连续空间。
[0093]
利用高斯分布表示预测的对手策略分布π
oppo
(a|s;μ
α
,σ
β
),动作表示层输出预测的对手策略分布π
oppo
(a|s;μ
α
,σ
β
)的均值μ
α
和方差σ
β
。
[0094]
其中,
[0095][0096]
其中,s表示环境状态;μ
α
和σ
β
分别表示对手动作的均值和方差;a表示对手动作。
[0097]
s130、提取环境状态特征的隐层特征,得到q值隐层特征。
[0098]
作为一个示例,用hq表示q值隐层特征。
[0099]
s140、提取环境状态特征的隐层特征,得到q值隐层特征。
[0100]
可选的,融合q值隐层特征和对手策略特征,得到融合特征,具体包括:
[0101]
串联拼接q值隐层特征和对手策略特征,得到融合特征。
[0102]
在一些实施例中,特征融合方法,包括:
[0103]
串联拼接对手策略特征h
pi
和q值隐层特征hq,得到融合特征hc。融合特征hc保留了原有特征的全部信息。
[0104]
在一些实施例中,特征融合方法,还包括:
[0105]
对对手策略特征h
pi
和q值隐层特征hq做点乘运算,得到融合特征hc。其中,需要统一对手策略特征h
pi
和q值隐层特征hq的维度,但是,这种方法可能会损失特征信息。
[0106]
s150、将融合特征输入预先构建的竞争网络,得到q值函数。
[0107]
在一些实施例中,将融合特征输入预先构建的竞争网络,得到q值函数,具体包括:
[0108]
将融合特征输入预先构建的竞争网络,得到状态价值函数和动作优势函数;
[0109]
聚合状态价值函数和动作优势函数,得到q值函数。
[0110]
其中,状态价值函数表示静态的环境状态本身具有的价值;
[0111]
动作优势函数表示选择某个动作所带来的额外价值,输出一个维度大小为|a|的向量;
[0112]
将状态价值函数网络的输出和优势函数网络的输出线性聚合得到每个动作的q值。
[0113]
用adv(s,a)表示动作优势函数,v(s)表示状态价值函数,q(s,a)表示q值函数。
[0114]
其中,
[0115][0116][0117]
s160、获取智能体的备选动作,根据q值函数,得到备选动作对应于环境状态的q值,将q值最大的备选动作作为智能体的执行动作。
[0118]
可选的,获取智能体的备选动作,根据q值函数,得到备选动作对应于环境状态的q值,将q值最大的备选动作作为智能体的执行动作,具体包括:
[0119]
将q值最大的备选动作输入预先构建的目标网络,得到目标q值;
[0120]
基于目标q值和最大的q值,利用预设的竞争网络的损失函数调整竞争网络的参数。
[0121]
更新价值网络q时,首先通过目标网络q’输出最大q值所对应的动作,然后将其输入到价值网络q中以产生目标值y’,从而消除q值的过估计,y’表示为:
[0122][0123]
其中,θ和θ’分别是价值网络q和目标网络q’的参数。
[0124]
则,预设的竞争网络的损失函数为:
[0125][0126][0127]
其中,lq(θ)表示竞争网络的损失函数,θ表示价值网络的参数。
[0128]
在不同的学习阶段,网络参数更新的侧重点不同。参数更新时,只有首先获得较为准确的对手策略特征h
pi
,融合了对手策略特征h
pi
的q值学习才能拟合得到最优的q值函数。因此,本技术提供学习自适应调节机制,通过比例因子里面λ对损失项lq进行放缩,调节不同阶段整个损失函数的大小,平衡智能体学习过程中对对手模型的“探索和利用”。
[0129]
其中,预设的损失函数为:
[0130]
[0131][0132]
其中,l表示的损失函数;l
pi
(θ)表示对手动作预测网络的损失函数,lq表示竞争网络的损失函数;λ表示比例因子。
[0133]
网络训练的初始阶段,相对于q值学习的损失项lq而言,对手策略特征学习的损失项l
pi
较大,通过比例因子λ的调节,使得网络更集中于策略特征h
pi
的训练。而随着训练的进行,l
pi
逐渐变小,lq开始发挥主要作用,使得网络的注意力集中到q值学习上。学习自适应调节机制的作用在于,使智能体充分掌握对手的行为信息,并利用其辅助决策。
[0134]
从上面所述可以看出,本技术提供的基于对手动作预测的智能体策略获取方法及相关装置,从智能体所处的环境中获取环境状态,并提取环境状态的特征,得到环境状态特征;将环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征;提取环境状态特征的隐层特征,得到q值隐层特征;融合q值隐层特征和对手策略特征,得到融合特征;将融合特征输入预先构建的竞争网络,得到q值函数;获取智能体的备选动作,根据q值函数,得到备选动作对应于环境状态的q值,将q值最大的备选动作作为智能体的执行动作。本技术能够有效预测对手动作,加快学习收敛速度,可以应对多种类型的对手。
[0135]
参考图2,其为本技术实施例提供的基于对手动作预测的智能体策略获取方法的数据流示意图。
[0136]
从智能体所处的环境中获取环境状态s;
[0137]
将环境状态s输入递归神经网络、卷积神经网络和全连接神经网络中的至少一种,对环境状态进行特征编码以提取环境状态的特征,得到环境状态特征h
t
;
[0138]
将环境状态特征h
t
分别输入两个全连接隐层;
[0139]
一个全连接隐层对环境状态特征h
t
进行特征提取,得到对手策略特征h
pi
;
[0140]
将对手策略特征h
pi
输入动作表示层,得到对手策略;
[0141]
另一个全连接隐层对环境状态特征h
t
进行特征提取,得到q值隐层特征hq;
[0142]
融合q值隐层特征hq和对手策略特征h
pi
,得到融合特征hc;
[0143]
将融合特征hc输入预先构建的竞争网络dueling,得到q值函数q(s,a)。
[0144]
为了进一步说明本技术提供的基于对手动作预测的智能体策略获取方法(dueling double deep q network-opponent action prediction,d3qn-oap)的有效性,本技术还提供了如下仿真实验:
[0145]
环境描述:
[0146]
1v1足球环境构成如图3所示。足球场环境由11*9的网格球场、分别属于两方阵营的球员以及足球组成。环境中存在红蓝两个阵营,每个阵营各有一个球员,球员用方块表示,左侧方块表示红方球员,右侧方块表示蓝方球员,用圆形表示足球。中间浅色区域为球场草坪(球坪),球坪内球员可以“自由”地活动,球坪左侧为红方半场,右侧为蓝方半场;边缘深色区域为球坪边界,球员不可进入;两侧区域为球门,相应地,左侧为红方球门,右侧为蓝方球门。
[0147]
初始时,环境中每个阵营中球员的位置随机放置于己方半场,而足球位于某一方
阵营的球员手中。球员的任务为成功控球并且将球运到对方球门即进球,便得到奖励100,对方阵营的球员则相应得到惩罚-100。一旦某一阵营进球则一个回合结束。如果在固定步数内没有任何阵营完成进球任务,则同样地一个回合结束,环境不给予任何奖励和惩罚。
[0148]
在每个时刻,每个球员可以选择向上、下、左、右四个方向移动一格或者保持静止共五个动作。如果某个球员预期到达的位置为球坪边界,则该动作不会生效,球员位置保持不变;如果预期位置已被其他球员占据,球员位置也不会变化且会触发碰撞传球现象。所谓碰撞传球,就是原本持有球的球员“被动”传球给与之发生碰撞的球员。
[0149]
实验设定:
[0150]
实验时,1v1足球场景中红方阵营球员为强化学习智能体,采用本技术提出的d3qn-oap进行学习和决策。d3qn-oap训练时采用的超参数如表1所示。此外,设定1v1足球环境的状态包含三部分信息,分别是我方智能体、对手以及足球在球坪中的位置编码。设置环境一局回合最大步长为20,提高环境难度以凸显本技术的性能。
[0151]
表1 d3qn-oap采用的超参数列表
[0152][0153]
蓝方阵营中的球员智能体采用规则rule策略进行决策,rule策略主要决策思想为:球员控球时,则伺机突围进球并防守敌方抢球;不控球时,若占有优势(离己方球门相对更近)则伺机抢球,若不占有优势,便防守己方球门防止敌方进球,rule策略决策树如图4所示。
[0154]
结果分析:
[0155]
(1)对手动作预测有效性验证
[0156]
在本技术所提出的d3qn-oap中,对手策略特征学习模块是后续对手策略特征融合到q值学习模块的基础,在验证本技术所提出方法的有效性和对抗性能之前,首先验证对手动作预测的有效性和准确性。
[0157]
模型训练过程中得到了对手动作预测oap网络的预测准确率oapacc和损失函数oaploss,其变化曲线分别如图5、6所示(其中episode表示进程)。可以看出随着训练的进行,预测准确率从0逐渐上升至95%保持稳定,而动作预测损失从1.6逐渐下降到0.1左右保持稳定,说明此时智能体已经掌握对手的行为信息。
[0158]
(2)学习性能对比
[0159]
比较了dqn、d3qn和d3qn-oap三种不同强化学习智能体模型的学习性能。实验过程中发现,随机数对方法的学习性能表现影响巨大,同一套超参数在不同的随机数种子下差异较大,为了降低随机数种子的影响,最大程度的保证每种方法的真实性能和实验公平性,模型训练过程中,不设置随机数种子,且每种方法固定一套超参数,随机训练30组模型,绘制学习曲线。评估方法的学习性能时,每组模型分别与设定的对手策略对抗1000次再取均值来对比方法性能。
[0160]
图7是三种方法在训练阶段的收敛曲线对比,可以看出d3qn-oap的收敛速度比d3qn和dqn快很多,特别是在训练的中前期(500-1500步),d3qn-oap所获得的奖励显著占优,说明相对于另外两种方法,采用对手动作预测的d3qn-oap能够在环境中更早地学到应对敌方的反制策略和为己方进带球射门的进攻策略。
[0161]
测试阶段比较了三种强化学习智能体与三种采用固定策略对手的对抗结果。对手球员的策略分别为固定进球路线normal策略、随机动作random策略以及图5所示的手工规则rule策略。方法评估时,学习智能体与对手智能体两两对抗,每个场次对抗1000次,所关注的对抗指标主要为智能体获得的环境奖励、平均对抗步长以及对抗胜率,每个场次对抗结果的均值分别如表2、3、4所示,其中最好的性能表现加粗标记。
[0162]
表2方法评估时环境奖励对比结果
[0163][0164]
表3方法评估时平均对抗步数对比结果
[0165][0166]
表4方法评估时对抗胜率对比结果
[0167][0168]
由对抗结果可知,无论对抗那种对手模型,d3qn-oap总是优于d3qn和dqn。d3qn-oap获得了相对最多的环境奖励,对抗胜率也最高,同时d3qn-oap的平均进球步长小于d3qn和dqn,能更早的结束比赛。综上,本技术所提出的d3qn-oap由于有效预测了对手的下一步动作,得到了对手隐藏的动作行为信息,因此,本技术提供的方法在训练时能够更快的收敛,评估时在对抗指标上也都取得了相对较高的结果。
[0169]
需要说明的是,本技术实施例的方法可以由单个设备执行,例如一台计算机或服务器等。本实施例的方法也可以应用于分布式场景下,由多台设备相互配合来完成。在这种分布式场景的情况下,这多台设备中的一台设备可以只执行本技术实施例的方法中的某一个或多个步骤,这多台设备相互之间会进行交互以完成所述的方法。
[0170]
需要说明的是,上述对本技术的一些实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于上述实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0171]
基于同一发明构思,与上述任意实施例方法相对应的,本技术还提供了一种基于对手动作预测的智能体策略获取装置。
[0172]
参考图8,所述基于对手动作预测的智能体策略获取装置,包括:
[0173]
环境状态特征获取模块,用于从智能体所处的环境中获取环境状态,并提取环境状态的特征,得到环境状态特征;
[0174]
对手策略特征获取模块,用于将环境状态特征输入预先构建的对手动作预测网络,得到对手策略特征;
[0175]
q值隐层特征获取模块,用于提取环境状态特征的隐层特征,得到q值隐层特征;
[0176]
融合特征获取模块,用于融合q值隐层特征和对手策略特征,得到融合特征;
[0177]
q值函数获取模块,用于将融合特征输入预先构建的竞争网络,得到q值函数;
[0178]
执行动作确定模块,用于获取智能体的备选动作,根据q值函数,得到备选动作对应于环境状态的q值,将q值最大的备选动作作为智能体的执行动作。
[0179]
为了描述的方便,描述以上装置时以功能分为各种模块分别描述。当然,在实施本技术时可以把各模块的功能在同一个或多个软件和/或硬件中实现。
[0180]
上述实施例的装置用于实现前述任一实施例中相应的基于对手动作预测的智能体策略获取方法,并且具有相应的方法实施例的有益效果,在此不再赘述。
[0181]
基于同一发明构思,与上述任意实施例方法相对应的,本技术还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上任意一实施例所述的基于对手动作预测的智能体策略获取方法。
[0182]
图9示出了本实施例所提供的一种更为具体的电子设备硬件结构示意图,该设备可以包括:处理器1010、存储器1020、输入/输出接口1030、通信接口1040和总线1050。其中处理器1010、存储器1020、输入/输出接口1030和通信接口1040通过总线1050实现彼此之间在设备内部的通信连接。
[0183]
处理器1010可以采用通用的cpu(central processing unit,中央处理器)、微处理器、应用专用集成电路(application specific integrated circuit,asic)、或者一个或多个集成电路等方式实现,用于执行相关程序,以实现本说明书实施例所提供的技术方案。
[0184]
存储器1020可以采用rom(read only memory,只读存储器)、ram(random access memory,随机存取存储器)、静态存储设备,动态存储设备等形式实现。存储器1020可以存储操作系统和其他应用程序,在通过软件或者固件来实现本说明书实施例所提供的技术方案
时,相关的程序代码保存在存储器1020中,并由处理器1010来调用执行。
[0185]
输入/输出接口1030用于连接输入/输出模块,以实现信息输入及输出。输入/输出模块可以作为组件配置在设备中(图中未示出),也可以外接于设备以提供相应功能。其中输入设备可以包括键盘、鼠标、触摸屏、麦克风、各类传感器等,输出设备可以包括显示器、扬声器、振动器、指示灯等。
[0186]
通信接口1040用于连接通信模块(图中未示出),以实现本设备与其他设备的通信交互。其中通信模块可以通过有线方式(例如usb、网线等)实现通信,也可以通过无线方式(例如移动网络、wifi、蓝牙等)实现通信。
[0187]
总线1050包括一通路,在设备的各个组件(例如处理器1010、存储器1020、输入/输出接口1030和通信接口1040)之间传输信息。
[0188]
需要说明的是,尽管上述设备仅示出了处理器1010、存储器1020、输入/输出接口1030、通信接口1040以及总线1050,但是在具体实施过程中,该设备还可以包括实现正常运行所必需的其他组件。此外,本领域的技术人员可以理解的是,上述设备中也可以仅包含实现本说明书实施例方案所必需的组件,而不必包含图中所示的全部组件。
[0189]
上述实施例的电子设备用于实现前述任一实施例中相应的基于对手动作预测的智能体策略获取方法,并且具有相应的方法实施例的有益效果,在此不再赘述。
[0190]
基于同一发明构思,与上述任意实施例方法相对应的,本技术还提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使所述计算机执行如上任一实施例所述的基于对手动作预测的智能体策略获取方法。
[0191]
本实施例的计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
[0192]
上述实施例的存储介质存储的计算机指令用于使所述计算机执行如上任一实施例所述的基于对手动作预测的智能体策略获取方法,并且具有相应的方法实施例的有益效果,在此不再赘述。
[0193]
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本技术的范围(包括权利要求)被限于这些例子;在本技术的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本技术实施例的不同方面的许多其它变化,为了简明它们没有在细节中提供。
[0194]
另外,为简化说明和讨论,并且为了不会使本技术实施例难以理解,在所提供的附图中可以示出或可以不示出与集成电路(ic)芯片和其它部件的公知的电源/接地连接。此外,可以以框图的形式示出装置,以便避免使本技术实施例难以理解,并且这也考虑了以下事实,即关于这些框图装置的实施方式的细节是高度取决于将要实施本技术实施例的平台的(即,这些细节应当完全处于本领域技术人员的理解范围内)。在阐述了具体细节(例如,
电路)以描述本技术的示例性实施例的情况下,对本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下或者这些具体细节有变化的情况下实施本技术实施例。因此,这些描述应被认为是说明性的而不是限制性的。
[0195]
尽管已经结合了本技术的具体实施例对本技术进行了描述,但是根据前面的描述,这些实施例的很多替换、修改和变型对本领域普通技术人员来说将是显而易见的。例如,其它存储器架构(例如,动态ram(dram))可以使用所讨论的实施例。
[0196]
本技术实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本技术实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1