一种基于主动学习的问答方法、系统、设备及介质与流程
1.本发明涉及智能问答领域,尤其是涉及一种基于主动学习的问答方法、系统、设备及介质。
背景技术:
2.可以实现与用户的闲聊,随着企业对客户服务的重视,聊天机器人从娱乐领域逐渐向客户服务等领域发展。
3.由于聊天机器人无法自行回答技术问题,现在通常的做法是收集许多由“问题-答案”组成的问答对,构建知识库来提供支持。当用户提问时,聊天机器人在知识库中搜索最为相关的问题,提取答案进行回复。
4.知识库的完善程度决定了用户的体验,无论搜索技术与相似匹配技术多么完善,如果相关的问题在知识库中没有存储,聊天机器人就无法回答用户的问题。为了完善知识库,可以会定期收集问答系统无法回答的问题,交由专家标注,向知识库中补充相应问答对。但由于专家的人力有限,未解答的问题的数量级又比较大,专家不仅难以及时标注所有问题,也无法从众多候选中找到高频的问题进行优先标注。当多个专家同时标注时,还可能因为相似问题产生重复标注,浪费人力。
技术实现要素:
5.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于主动学习的问答方法、系统、设备及介质。
6.本发明的目的可以通过以下技术方案来实现:
7.一种基于主动学习的问答方法,包括以下步骤:
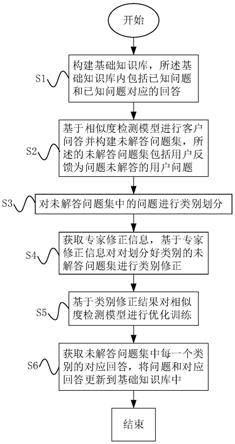
8.s1:构建基础知识库,所述基础知识库内包括已知问题和已知问题对应的回答;
9.s2:基于相似度检测模型进行客户问答并构建未解答问题集,所述的未解答问题集包括用户反馈为问题未解答的用户问题;
10.s3:对未解答问题集中的问题进行类别划分;
11.s4:获取专家修正信息,基于专家修正信息对对划分好类别的未解答问题集进行类别修正;
12.s5:基于类别修正结果对相似度检测模型进行优化训练;
13.s6:获取未解答问题集中每一个类别的对应回答,将问题和对应回答更新到基础知识库中。
14.优选地,所述的步骤s2具体包括:
15.s21:建立文本相似度检测模型;
16.s22:获取用户待答问题并在基础知识库中通过文本相似度检测模型搜索相似度最高的已知问题的回答作为回答输出;
17.s23:构建未解答问题集,获取用户反馈,若用户反馈为问题未解答,则将对应问题
存入未解答问题集中。
18.优选地,所述的步骤s3具体包括:
19.s31:在未解答问题集中选取第一问题作为第一类别的基准问题;
20.s32:在未解答问题集中选取待分类问题与所有类别的基准问题逐个进行相似度计算,若所有类别中存在类别的基准问题与待分类问题的相似度大于相似度阈值,则将待分类问题判定为该类别,否则将待分类问题作为新的类别的基准问题;
21.s33:重复步骤s32直到未解答问题集所有的问题都完成类别划分。
22.所述的步骤s3还包括:步骤s34:按每个类别中问题的数量对类别进行排序。
23.优选地,所述的专家修正信息包括类型合并指令、类型拆分指令、问题移动指令,
24.所述的类型合并指令为将未解答问题集中的两个类别及对应的问题合并为一个类型;
25.所述的类型拆分指令为将未解答问题集中的一个类别及问题分为两个类型及对应的问题;
26.所述的问题移动指令为将一类别中的一个或多个问题移动到另一类别中。
27.优选地,所述的相似度检测模型为基于bert模型的语义相似度模型。
28.一种基于主动学习的问答系统,包括基础知识库模块、问答模块、类别划分模块、修正模块、答案补充模块,
29.所述的基础知识库模块用于构建基础知识库,所述基础知识库内包括已知问题和已知问题对应的回答;
30.所述的问答模块用于基于相似度检测模型进行客户问答并构建未解答问题集,所述的未解答问题集包括用户反馈为问题未解答的用户问题;
31.所述的类别划分模块用于对未解答问题集中的问题进行类别划分,获取专家修正信息,基于专家修正信息对对划分好类别的未解答问题集进行类别修正,基于类别修正结果对相似度检测模型进行优化训练;
32.所述的答案补充模块用于获取未解答问题集中每一个类别的对应回答,将问题和对应回答更新到基础知识库中。
33.优选地,所述的问答模块进行用户问答和未解答问题集构建的具体步骤包括:
34.建立文本相似度检测模型;
35.获取用户待答问题并在基础知识库中通过文本相似度检测模型搜索相似度最高的已知问题的回答作为回答输出;
36.构建未解答问题集,获取用户反馈,若用户反馈为问题未解答,则将对应问题存入未解答问题集中。
37.优选地,所述的类别划分模块进行类别划分的具体步骤包括:
38.步骤一:在未解答问题集中选取第一问题作为第一类别的基准问题;
39.步骤二:在未解答问题集中选取待分类问题与所有类别的基准问题逐个进行相似度计算,若所有类别中存在类别的基准问题与待分类问题的相似度大于相似度阈值,则将待分类问题判定为该类别,否则将待分类问题作为新的类别的基准问题;
40.步骤三:重复步骤三直到未解答问题集所有的问题都完成类别划分。
41.一种基于主动学习的问答设备,包括存储器、处理器和存储在所述存储器上的计
算机程序,所述处理器执行所述计算机程序时实现上述的基于主动学习的问答方法的步骤。
42.一种非易失性计算机存储介质,所述非易失性计算机存储介质存储有可执行程序,所述可执行程序被处理器执行实现上述的基于主动学习的问答方法的步骤。
43.与现有技术相比,本发明具有如下优点:
44.(1)本发明利用相似度检测模型获取客户问题并在知识库中进行搜索回答,记录未解答问题根据预设规则进行分类、标注和专家修正,进一步对相似度检测模型进行训练,构成主动学习机制,有效提高问题回答的精度和可靠性,能够不断基于收集到的未解答问题进行基础知识库的扩充,提高问答量,进一步提高用户体验。
45.(2)本发明采用分类模型和规则对未解答问题进行与分类,由专家进行类型的修正和回答,有效解放人力成本,避免重复标注提高,工作效率。
附图说明
46.图1为本发明的流程图。
具体实施方式
47.下面结合附图和具体实施例对本发明进行详细说明。注意,以下的实施方式的说明只是实质上的例示,本发明并不意在对其适用物或其用途进行限定,且本发明并不限定于以下的实施方式。
48.实施例
49.一种基于主动学习的问答方法,如图1所示,包括以下步骤:
50.s1:构建基础知识库,所述基础知识库内包括已知问题和已知问题对应的回答。
51.s2:基于相似度检测模型进行客户问答并构建未解答问题集,未解答问题集包括用户反馈为问题未解答的用户问题
52.步骤s2具体包括:
53.s21:建立文本相似度检测模型。此步骤用的是sts(文本相似度检测)模型,具体使用的是基于bert模型的语义相似度模型,将相似度最高的问答对作为最为相关的问题进行输出。
54.s22:获取用户待答问题并在基础知识库中通过文本相似度检测模型搜索相似度最高的已知问题的回答作为回答输出。本实施例中,通过设置在问答装置上的语音获取装置如麦克风获取并通过语音识别算法转化用户待答问题或通过文本输入、接口获取用户待答问题文本。
55.s23:构建未解答问题集,获取用户反馈,若用户反馈为问题未解答,则将对应问题存入未解答问题集中。通过用户的选择,收集用户反馈。选项包括未解答、已解答。将选择为未解答的问题全部存入未解答问题库。
56.s3:对未解答问题集中的问题进行类别划分
57.步骤s3具体包括:
58.s31:在未解答问题集中选取第一问题作为第一类别的基准问题;
59.s32:在未解答问题集中选取待分类问题与所有类别的基准问题逐个进行相似度
计算,若所有类别中存在类别的基准问题与待分类问题的相似度大于相似度阈值,则将待分类问题判定为该类别,否则将待分类问题作为新的类别的基准问题;
60.s33:重复步骤s32直到未解答问题集所有的问题都完成类别划分。
61.具体地,举例说明:
62.a未解答问题集一共有m个问题,随机取一个问题x1作为类别1的基准问题
63.b随机取一个问题x2通过sts模型计算其与问题x1的相似度是否大于相似度阈值,本实施例中相似度阈值区0.9,如果是,则也放入类别1,如果不是,将x2作为类别2的基准问题;
64.c继续取问题x3重复步骤b,如果x3与x1相似,则放入类别1内;否则计算其与类别2基准问题是否相似,以此类推。直到所有问题都被分到某个类别为止。
65.所述的步骤s3还包括:步骤s34:按每个类别中问题的数量对类别进行排序,让专家标注时更关注于高频、热点问题,投入产出比高。
66.s4:获取专家修正信息,基于专家修正信息对对划分好类别的未解答问题集进行类别修正。
67.专家修正信息包括类型合并指令、类型拆分指令、问题移动指令,
68.类型合并指令为将未解答问题集中的两个类别及对应的问题合并为一个类型;
69.类型拆分指令为将未解答问题集中的一个类别及问题分为两个类型及对应的问题;
70.问题移动指令为将一类别中的一个或多个问题移动到另一类别中。
71.s5:基于类别修正结果对相似度检测模型进行优化训练;
72.s6:获取未解答问题集中每一个类别的对应回答,将问题和对应回答更新到基础知识库中。
73.本发明还提供了一种基于主动学习的问答系统,包括基础知识库模块、问答模块、类别划分模块、修正模块、答案补充模块,
74.基础知识库模块用于构建基础知识库,所述基础知识库内包括已知问题和已知问题对应的回答;
75.问答模块用于基于相似度检测模型进行客户问答并构建未解答问题集,未解答问题集包括用户反馈为问题未解答的用户问题;
76.类别划分模块用于对未解答问题集中的问题进行类别划分,获取专家修正信息,基于专家修正信息对对划分好类别的未解答问题集进行类别修正,基于类别修正结果对相似度检测模型进行优化训练;
77.答案补充模块用于获取未解答问题集中每一个类别的对应回答,将问题和对应回答更新到基础知识库中。
78.本实施例中,问答模块进行用户问答和未解答问题集构建的具体步骤包括:
79.建立文本相似度检测模型;
80.获取用户待答问题并在基础知识库中通过文本相似度检测模型搜索相似度最高的已知问题的回答作为回答输出;
81.构建未解答问题集,获取用户反馈,若用户反馈为问题未解答,则将对应问题存入未解答问题集中。
82.本实施例中,类别划分模块进行类别划分的具体步骤包括:
83.步骤一:在未解答问题集中选取第一问题作为第一类别的基准问题;
84.步骤二:在未解答问题集中选取待分类问题与所有类别的基准问题逐个进行相似度计算,若所有类别中存在类别的基准问题与待分类问题的相似度大于相似度阈值,则将待分类问题判定为该类别,否则将待分类问题作为新的类别的基准问题;
85.步骤三:重复步骤三直到未解答问题集所有的问题都完成类别划分。
86.一种基于主动学习的问答设备,包括存储器、处理器和存储在所述存储器上的计算机程序,所述处理器执行所述计算机程序时实现上述的基于主动学习的问答方法的步骤。
87.一种非易失性计算机存储介质,所述非易失性计算机存储介质存储有可执行程序,所述可执行程序被处理器执行实现上述的基于主动学习的问答方法的步骤。
88.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
89.上述实施方式仅为例举,不表示对本发明范围的限定。这些实施方式还能以其它各种方式来实施,且能在不脱离本发明技术思想的范围内作各种省略、置换、变更。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1