一种基于Resnet50结合注意力机制和特征金字塔的图像分类方法
一种基于resnet50结合注意力机制和特征金字塔的图像分类方法
技术领域
1.本发明涉及图像处理技术领域,特别是涉及一种基于resnet50结合注意力机制和特征金字塔的图像分类方法。
背景技术:
2.resnet作为深度学习经典骨干框架通过提出残差模块(residual bloack),解决了深层次网络难以训练,存在梯度消失和梯度爆炸问题,使神经网络提取特征的能力大大增强。resnet在提升神经网络训练速度方面取得显著效果,但具体应用于计算机视觉的分类、定位、检测和分割有待提升。
3.但本技术发明人在实现本技术实施例中发明技术方案的过程中,发现上述技术至少存在如下技术问题:
4.在图像分类领域,由于分类目标在每张图像尺度大小差异较大,目标大小不一致增加了图片的分类难度,导致最终分类效果差强人意。
5.例如,利用数据集cifar-10进行分类任务,该数据集包括60000张32x32的彩色图像,其中训练集50000张,测试集10000张。cifar-10一共标注为10类,每一类图片6000张。这10类分别是airplane(飞机),automobile(汽车),bird(鸟),cat(猫),deer(鹿),dog(狗),frog(青蛙),horse(马),ship(船)和truck(卡车),其中没有任何的重叠情况,即airplane只包括飞机,automobile只包括小型汽车,也不会在同一张照片中出现两类事物。其中cifar-10含有的是现实世界中真实的物体,不仅噪声很大,分辨率低,而且物体的比例、特征都不尽相同,这为识别带来很大困难。
6.基于此,本发明设计了一种基于resnet50结合注意力机制和特征金字塔的图像分类方法,以解决上述问题。
技术实现要素:
7.为了解决目前背景技术提及的技术问题,本发明的目的是提供一种基于resnet50结合注意力机制和特征金字塔的图像分类方法。
8.为了实现上述目的,本发明采用如下技术方案:
9.一种基于resnet50结合注意力机制和特征金字塔的图像分类方法,包括以下步骤:
10.s1、采集输入图片,并对图像进行数据预处理;
11.s2、将预处理后的图像导入分类模型,输出三个不同卷积层的特征图;
12.s3、对各特征图进行分别的分类预测,取可信度最大分类器,输出最终预测分类结果。
13.优选的,所述数据预处理包括:
14.将输入图像格式(c,h,w)处理为(c,7h,7w);
15.其中,c为图片通道数,h为图片高度,w为图片高度。
16.优选的,所述分类模型的处理包括:
17.对预处理图像进行focus模块处理,提取不同特征;
18.经cbam注意力机制模块处理得到有意义的特征;
19.提取图像特征,并在bottom-top各层输出特征层;
20.对特征层卷积后降通道操作,获取统一通道数的中间特征层;
21.对应bottom-top各层融合输出特征层。
22.优选的,所述focus模块处理包括:
23.将输入图片进行切片操作后连接成新图片,其中,新图片的通道数为输入图片的一半,新图片大小为输入图片的4倍;
24.卷积输出特征图,并将平面上的信息切换到通道维度,经卷积的方式提取不同特征。
25.优选的,所述cbam注意力机制模块处理包括:
26.空间注意力注意特征图中的重点关注的目标区域,获取关注目标的细节信息,并抑制其他无用信息。
27.优选的,所述融合输出特征层包括:
28.将上层特征图中低分辨率高级抽象语义信息通过add融合到低层高分辨率低语义特征。
29.优选的,所述分类预测包括:
30.将三个不同特征特征层作为输出结果进行全连接层fc操作;
31.对各特征层全连接后分类处理,并为每个类别输出一个概率值;
32.取概率值最大的分类结果作为最终的输出预测值。
33.本发明实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
34.1、本发明通过结合注意力模块cbam和特征金字塔fpn结构,提升了resnet50模型的特征提取效果;
35.2、本发明通过基于fpn不同层特征层三分类器的优化算法,充分利用融合后不同层的特征信息,提升了分类的准确率;
36.综上所述,本发明具有图像分类准确率高、提取质量高等优点。
附图说明
37.以下结合附图和具体实施方式来进一步详细说明本发明:
38.图1为本发明图像分类模型的处理流程图;
39.图2为本发明p4、p5和p6图。
具体实施方式
40.以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效。
41.实施例一
42.本发明提供一种技术方案:一种基于resnet50结合注意力机制和特征金字塔的图
像分类方法,包括以下步骤:
43.s1、采集输入图片,并对图像进行数据预处理;
44.s2、将预处理后的图像导入分类模型,输出三个不同卷积层的特征图;
45.s3、对各特征图进行分别的分类预测,取可信度最大分类器,输出最终预测分类结果。
46.通过上述步骤不难发现,在本发明的图像分类过程中,该分类模型为基于resnet50和注意力机制模块、fpn模块结合构建的图像处理模型,通过基于fpn的三个分类器,最终取分类准确率最高的一个分类器,作为最后的分类结果。再结合注意力模块cbam的轻量级通用性,增强了整体网络的框架的提取特征能力,最后,在cifar10公用数据集上,本发明通过改进的类resnet50网络结构,在分类准确性方面可提升resnet50约1.28%的准确率。
47.需要说明的是,在本发明中,cbam为注意力机制,fpn为特征金字塔。
48.为了更好的实现将图像数据对focus模块的输入,所述数据预处理包括:
49.将输入图像格式(c,h,w)处理为(c,7h,7w);
50.其中,c为图片通道数,h为图片高度,w为图片高度。
51.在本实施例中,需要补充的是,每次卷积层之后,均进行归一化层(bn)和激活层(relu);例如在输入的图片数据格式为(3,32,32),经过数据预处理transform后为(3,224,224)。
52.为了实现三个不同卷积层特征图输出,所述分类模型的处理包括:
53.对预处理图像进行focus模块处理,提取不同特征;
54.经cbam注意力机制模块处理得到有意义的特征;
55.提取图像特征,并在bottom-top各层输出特征层;
56.对特征层卷积后降通道操作,获取统一通道数的中间特征层;
57.对应bottom-top各层融合输出特征层。
58.再进一步的,所述focus模块处理包括:
59.将输入图片进行切片操作后连接成新图片,其中,新图片的通道数为输入图片的一半,新图片大小为输入图片的4倍;
60.卷积输出特征图,并将平面上的信息切换到通道维度,经卷积的方式提取不同特征。
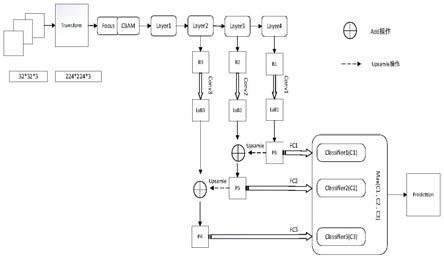
61.在本实施例中,通过将输入图片首先进行切片操作,然后通过concat操作连接到一起,形成图片大小为输入图片的一半通道数为输入图像的4倍,最后进行卷积输出特征图。将平面上的信息转换到通道维度,再通过卷积的方式提取不同特征,采用focus层的目的是下采样,focus层能够有效减少下采样带来的信息损失,同时减少计算量。
62.为了更好的完成特征提取,所述cbam注意力机制模块处理包括:
63.空间注意力注意特征图中的重点关注的目标区域,获取关注目标的细节信息,并抑制其他无用信息。
64.在本实施例中,由于每个特征图相当于捕获了原图中的某一个特征,通道注意力有助于筛选出有意义的特征,即告诉cnn原图哪一部分特征具有意义,由于特征图中一个像素代表原图中某个区域的某种特征,空间注意力相当于告诉网络应该注意原图中哪个区域
的特征,获得需要重点关注的目标区域,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
65.为了实现对输出特征层的融合,所述融合输出特征层包括:
66.将上层特征图中低分辨率高级抽象语义信息通过add融合到低层高分辨率低语义特征。
67.在本实施例中,在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与bottom-up过程中相应的具有丰富的空间信息(高分辨率,有利于定位)的特征图进行add融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图。
68.需要说明的是,本发明还提供了一种基于resnet50结合注意力机制和特征金字塔的图像分类方法的一种具体实施过程,如图1所示,包括以下步骤:
69.step1:输入的图片数据格式为(3,32,32),经过数据预处理transform后为(3,224,224),再经过focus模块,借鉴yolov5的思想,进行下采样,有效减少下采样带来的信息损失,同时减少计算量,数据格式现为(12,112,112);
70.step2:经过cbam注意力机制模块后,数据格式不变;由于每个特征图相当于捕获了原图中的某一个特征,通道注意力有助于筛选出有意义的特征,即告诉cnn原图哪一部分特征具有意义,获得需要重点关注的目标区域,以获取更多所需要关注目标的细节信息,而抑制其他无用信息;
71.step3:经过resnet50的layer1层卷积后,输出(256,56,56);layer2层卷积后,输出b3(512,28,28);layer3层卷积后,输出b2(1024,14,14);layer4层卷积后,输出b1(2048,7,7);
72.step4:b1、b2、b3通过卷积后降图像通道数,全部统一为512通道,latb1(512,7,7),latb2(512,14,14),latb3(512,28,28);
73.step5:fpn的up-bottom过程,将上层特征图中低分辨率高级抽象语义信息通过add融合到低层高分辨率低语义特征,实现信息互补作用。p6=latb1,p5=add(upsample(p6),latb2),p4=add(upsample(p5),latb3),此时p6(512,7,7),p5(512,14,14),p4(512,28,28),p4、p5、p6为fpn的top-bottom各层的融合输出特征层,其中upsample操作采取最近邻插值法,可以在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与bottom-up过程中相应的具有丰富的空间信息(高分辨率,有利于定位)的特征图进行add融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图;
74.step6:一般图像分类器只有一个,并且是从网络模型最后一个特征层全连接后,进行分类预测,分别在p6、p5、p4后分别经过全连接层后,设置3个分类器,充分利用融合后不同层的特征图对不同尺度的分类目标敏感度,将三个分类器的输出分类概率值取最大值输出作为最终预测。具体举例原理就是:p6层的classifier1输出鸟类的概率是0.56,p5层的classifier2输出猫类的概率是0.63,p4层的classifier3输出鸟类的概率是0.50,那么最终的输出结果就识别图像分类的结果为猫。通过这种优化,鼓励模型在训练过程中能较快速的寻找全局最优,不会因为只有最后一层分类器输出结果,而反复寻找局部最优点。
75.需要说明的是,fc1、fc2、fc3分别代表三个不同特征层是输出结果进行全连接层fc操作;
76.c1、c2、c3分别代表三个不同特征层全连接后进行分类,给每个类别输出一个概率
值;
77.max(c1,c2,c3)为本发明设计的分类算法,其是将三个不同特征层,得到三个全连接层,进行比较;利用融合后的各层特征,充分识别不同尺度的分类目标大小,取概率值最大的分类结果,作为最终的输出预测值。
78.如图2所示,通过使用grad-cam类激活可视化fpn的p4、p5、p6特征层,正常分类器通过最后一层p6全连接层后分类,但如图2所示,第二行第一列的画红框中的鹿图像,在最后的特征提取阶段对分类的贡献效果为0,反而p4和p5层,保留了一定的图像信息。同样画黄框中的船图像,在最后层特征效果也不好,在p4、p5层具有一定的分类信息。
79.举例说明:通过利用本发明设计的网络模型,在cifar10数据集上,分训练集为5万张图片,测试集图片为1万张图片,共训练120epoch,batchsize=20,learning-rate=0.1,学习率在30、60,90epoch时,每次学习率降低10倍;通过与resnet50模型top1准确率90.39%做对比,本模型的top1准确率达到了91.67%,提升了1.28%的精度,证明了本模型设计的合理性,有助于分类准确率的提升;因此,可以将该方法推广到其他图片分类领域,实现更广泛的应用。
80.上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1