检测域生成算法的系统和方法与流程
1.本发明涉及一种用于从域名系统(dns)记录流中检测表现出类似域生成算法(dga)行为的域名的系统和方法。具体而言,本发明涉及一种系统,该系统包括深度学习分类器(dl-c)模块,用于在已过滤的dns记录被提供给序列过滤器-分类器(sfc)模块之前,接收并过滤dns记录流,其中已过滤的dns记录被确定为拥有表现出dga行为的域名(在下文中,这些域名将可互换地称为dga域名或可能的dga域名)。
2.对于每个源互联网协议(ip)、目的地ip和分析时间段三元组,sfc模块随后将相关联的dga记录分组为各种序列。然后,对于每个序列,它会过滤掉如由dl-c模块确定地、不会表现出类似dga特征的dga域名及其相应的dns记录。接下来,sfc模块为存在于每个源ip、目的地ip和分析的时段之间的每个剩余dga记录序列打标(tag)标记。最后,sfc模块利用dns记录的时间戳来生成dga发生事件的时间序列,使用该发生事件的时间序列,确定整个分析时间段内的dga突发的数量。
3.然后,自动编码器-分类器(ae-c)通过基于dga发生事件的dga记录序列的相应时间序列,分析时间段内的相关性(correlation),为每个dga记录序列分配相干性分数。然后使用频谱分析器(fsa)模块将dga发生事件的时间序列转换为频谱,然后其识别在每个dga记录序列内发生的周期性dga突发。并行地,查找成功解析(fsr)模块利用如由sfc模块确定的每个序列的特征来查找解析到可能的命令和控制(c2)服务器的dga域名。然后,由fsr、fsa和ae-c模块生成的信息连同由sfc模块产生的可能的dga域名序列和其他丰富的细节被传递到警报模块,该警报模块然后使用该信息向用户呈现和优先化用文本和时间信息丰富的dga警报,允许用户将注意力更好地集中在具有如下这些的那些警报上:经评估表现出dga行为的域名序列中明显的文本相似性、由ae-c模块评估的更高相干性分数、由我们的fsa模块评估的周期性以及由fsr模块评估的对可能的c2服务器的可能解析。
背景技术:
4.域生成算法(dga)是恶意软件广泛使用的、用于在受感染的网络和恶意方的命令与控制(c2)服务器之间建立通信链路的算法。这种攻击很难检测和防止,因为恶意方的c2服务器通常没有静态域名,而是通常利用随机的动态域名,该随机的动态域名会随着时间不断变化。
5.因此,恶意软件需要在一段时间内和不同时刻查询多个域名(即类似突发的行为),以进行“暴力”搜索,从而确定攻击者的c2服务器当前所在的域。由于由dga生成的域名可以动态生成,因此使用简单的域名黑名单对于阻止dga威胁是无效的,因为相对于由dga生成的域名而言,黑名单可能并不穷举。
6.dga算法的一个有趣的副产品是,受感染的计算机发出的许多dns请求都会用响应代码(“rcode”)nxdomain进行回复,这指示该域不存在。这是因为在恶意软件进行的所有查询中,只有少数选定的域是正确的,这些域将以noerror rcode进行回复。这些就是c2服务器基础设施所在的域。由于接收到的nxdomain rcode数量很大,大多数反dga算法集中在这
些dns查询上,以确定网络中是否正在使用dga。如果大量检测到这样的dns查询,这将指示计算机/服务器正被恶意软件感染的可能性,因为恶意软件将试图与其c2服务器通信。
7.当前检测dga的行业实践是使用机器学习方法和广泛的特征工程学来确定由网络查询的nxdomain域名是否是由dga创建的。常用特征的例子包括字符的归一化熵、n-gram、符号字符比、元音字符比等。最近,研究人员进一步完善了这些实践,他们开始在字符级别上使用深度学习技术,特别是递归神经网络(rnn)和卷积神经网络(cnn)架构,来确定nxdomain域串(string)是否包含dga。
8.其他人试图利用机器学习算法,特别是随机森林,以首先标记出可能是潜在dga的串。特别地,手工设计的特征(hand engineered feature),如基于熵的特征(例如顶级域、二级域、三级域等的熵)和结构域特征(例如域名的长度、域级别的数量等)被随机森林算法用来确定特定的串是否是dga。接下来,相似的串随时间而被相关。如果串表现出相似的基于熵的和结构的域特征,则它们被定义为相似的。那些随时间相关的串随后被声明为dga,并存储在数据库中,用于随时间进一步完善随机森林算法。
9.其他人试图研究dga的发生事件,然后试图确定是否可以从这些研究中观察到任何有意义的时间结构。本领域技术人员已经表明,采用dga、特别是conficker和kraken类型的dga的恶意软件样本表现出一些时间行为。研究表明,通过手动设计的特征训练的决策树能够在非常小的样本集内检测到dga行为,该决策树是从恶意软件触发dga时的时间序列中获得的。然而,值得注意的是,他们无法从频谱分析中提取有用的特征,因此他们的分析侧重于提取手工设计的时域特征。此外,他们无法实现工作系统,因为他们的分析需要实际的恶意软件样本,这些样本不容易获得,并且如果可见性仅局限于网络流量数据,则无法工作。因此,他们用于分析的数据集相当小。最后,他们还得出结论,他们使用时域特征检测dga的方法导致高误报率,使其不适合大规模部署或实施。
10.上面提出的方法仅仅涉及关于一个域名或域名序列是否构成dga的二元(binary)分类,并且没有对由所识别的域名所显示的dga特征的类型进行任何分析。此外,当机器学习算法和/或方法与聚类一起使用时,用于训练这些模型的特征往往是手工设计的,并且这给输出设置了软约束,因为聚类的输出的结果将受到手工设计的特征类型的约束。换句话说,虽然聚类的输出可能更易于人工解释,但生成的聚类通常更受约束,因此,这阻碍了对dga的可能的新变异的发现。此外,据我们所知,迄今还远没有任何系统成功地利用时间特征来检测dga。
11.出于上述原因,本领域的技术人员一直在努力提出一种可扩展的系统和方法,该系统和方法能够提供更多的上下文信息和对表现出类dga(dga-like)行为的可疑dns记录的自动分析,从而可以对这些dns记录进行更彻底的分析,从而允许准确地检测到dga。
技术实现要素:
12.通过根据本发明的实施例所提供的系统和方法,解决了上述和其他问题,并且实现了本领域的进步。
13.根据本发明的系统和方法的实施例的第一个优点是,给定单个域名,本发明能够同时分类它是否是可能的dga,并且如果它被认为是可能的dga,则本发明将基于当前已知的dga族确定该域名表现出各种已知的dga族中的哪些特征。这种处理完全是自动完成的,
不需要任何手工设计的特征和人为定义的规则。
14.根据本发明的系统和方法的实施例的第二个优点是,本发明能够回顾特定源和目的地ip之间的分析时间段(在我们的实施例中,1天),以检测表现出相似特征的可能的dga,并丢弃其他的,而不需要任何手工设计的特征和人为定义的规则。
15.根据本发明的系统和方法的实施例的第三个优点是,本发明能够自动和有效地识别看起来相似但具有不同顶级域(top level domain)的可能dga序列,而不需要任何手工设计的特征和人为定义的规则。
16.根据本发明的系统和方法的实施例的第四个优点是,除了向用户提供一可能的dga域名序列之外,本发明还能够提供行业中任何其他系统或研究没有提供的其他丰富的信息源。
17.根据本发明的系统和方法的实施例的第五个优点是,本发明使用观察到相关联的dns记录时的时间戳来计算每个可能的dns序列的相干性分数。这为用户提供了任何dga序列的时间特征在相关性时间段(在我们的实施例中,1个月)内重复的频率的想法。较高的相干性分数指示相似的时间特征在相关性时间段内显示多次,指示更可疑的行为。
18.根据本发明的系统和方法的实施例的第六个优点是,本发明能够利用频谱分析器(fsa)模块来确定可能的dga的相关联的dns记录的时间戳是否表现出某种周期性行为,从而提供对存在自动软件/恶意软件的更多确认,因为人类行为往往是非周期性的。
19.根据本发明的系统和方法的实施例的第七个优点是,本发明能够利用本发明的串分析和时间分析能力来识别表现出尚不常见的行为的新的非dga威胁。
20.根据本发明的系统和方法的实施例的第八个优点是,本发明能够通过确定与给定的可能的dganxdomain dns记录序列相对应的每个可能的dga noerror dns记录在源ip、目的地ip和分析时间段方面是否具有与给定的可能的dga nxdomain dns记录序列中相似的dga特征,来识别dga恶意软件的实际成功dns解析。成功的解析不仅为用户提供了对结果更高的信心,还帮助他们确定工作的优先级,因为成功的解析意味着更高的紧急状态,因为它指示可能的数据泄露已经在发生。
21.根据本发明的方法的实施例以下列方式操作,提供了上述优点。
22.根据本发明的第一方面,公开了一种用于检测域生成算法(dga)行为的系统,该系统包括:深度学习分类器(dl-c)模块,被配置为:接收域名系统(dns)记录流;识别具有与dga相关联的域名和与dga相关联的域名中的每一个相关联的dga特征的dns记录,序列过滤器-分类器(sfc)模块,被配置为:基于与每个识别的dga dns记录相关联的源ip、目的地ip和分析时间段,将来自dl-c模块的识别的dns记录分组为序列;对于每个序列,对于每个序列,识别并选择nxdomain dga相关联的域名,nxdomain dga相关联的域名表现出该序列的最多的c个发生的dga特征中的至少一个作为其最多的k个特征之一,并基于最多的c个发生的dga特征标记该序列;基于每个序列的相关联的时间戳对每个序列进行排序,并且基于该序列的第一记录对每个序列中的时间戳进行归一化,以获得在分析时间段内dga发生事件的时间序列;向寻找成功解析(fsr)模块提供与识别的nxdomain dga dns记录不相关联的noerror dns记录,fsr模块被配置为从接收的dns记录中识别与命令和控制服务器相关联的dga域;自动编码器-分类器(ae-c)模块,包括合并成单个神经网络的自动编码器和分类器,该ae-c模块被配置为:对于从sfc模块获得的dga发生事件的每个时间序列,为每个标记
的序列生成相干性分数;移除相干性分数在预定阈值以下的序列;其中使用从sfc模块获得的发生事件的标记时间序列、和基于从序列的标记导出的单热向量的分量、分类器的softmax输出的维度和由系数α加权的重构损失的损失函数来训练自动编码器-分类器模块;频谱分析器(fsa)模块,被配置为:识别与dga发生事件的每个时间序列相关联的dga频域峰值,以便确定dga发生事件的每个时间序列内的周期性信号;为dga发生事件的每个时间序列内的每个周期性信号确定频率和相应的周期;识别对于每个确定的频率存在的相移信号的数量;警报模块,被配置为基于由sfc模块产生的dga发生事件的时间序列、由ae-c模块产生的时间序列、由fsa模块确定的相移信号的识别的数量以及由fsr模块确定的识别的dga域来对dga警报进行优先排序。
23.关于本发明的第一方面,该系统还包括:平滑过滤器和离散傅立叶变换模块,被配置为:将平滑过滤器应用于由sfc模块输出的dga发生事件的时间序列;和使用离散傅立叶变换算法将dga发生事件的过滤后的时间序列从时域转换到频域,使得ae-c模块的神经网络的输入包括频谱。
24.关于本发明的第一方面,该系统还包括:机器学习串分析器(ml-sa)模块,其中在深度学习分类器模块识别具有dga及其相关联的特征的dns记录之前,ml-sa模块被配置为:使用机器学习算法过滤dns记录,以从dns记录中移除与已知的dga不相关联的域名,由此使用以下标记的特征中的至少一个来训练机器学习算法:域名的长度、域名的熵、域名的字符n-gram、域名的不同字符计数、网络图或单词图相似性分数,以及由此使用标记的开源数据集、内部数据库和第三方数据库来训练机器学习算法。
25.关于本发明的第一方面,深度学习分类器模块包括:只看一次(yolo)架构,被配置为:基于字符级令牌化来训练自身,以产生一组嵌入,该组嵌入通过神经网络来产生二元决策,以确定域名串是否包括dga,以及如果确定域名串包括dga,则生成指示该域名串属于哪个已知的dga族的概率分布。
26.关于本发明的第一方面,其中yolo架构包括通信连接到深度神经网络的嵌入层,由此嵌入层被配置为将字符令牌(token)的列表转换为矩阵,并且其中深度神经网络被配置为使用基于二元交叉熵损失和分类交叉熵损失的复合损失函数,其中复合损失函数被定义为:
[0027][0028]
其中b被定义为指示特定串是否包括dga的标记,b被定义为指示特定串是否是dga的神经网络的sigmoid输出,ti被定义为仅在与特定dga串的族标记相对应的位置处被激活的单热向量的特定维度,被定义为由神经网络输出的softmax激活向量,n被定义为的维度的总数,其对应于用于训练模型的已知的dga族的总数,并且γ被定义为可调谐系数,其用于加权二元交叉熵损失和softmax交叉熵损失之间的相对重要性。
[0029]
关于本发明的第一方面,其中在sfc模块被dl-c模块应用于已经与dga域串相关联的dns记录之前,基于黑名单和规则的过滤模块被配置为:使用黑名单移除与类dga算法相
关联的合法域;并移除具有无效域和顶级域(tld)特征的域名。
[0030]
关于本发明的第一方面,其中用于训练自动编码器-分类器模块的损失函数被定义为:
[0031][0032]
其中,i
x
被定义为与sfc模块输出的dga发生事件的时间序列相关的输入信号,该输入信号作为输入被馈送到自动编码器,iy是自动编码器的输出信号,pi是从由sfc模块打标到该序列的标记中导出的单热点向量的第i维度,pi是分类器的softmax输出的第i维度,以及α是用于加权分类损失相对于重构损失的相对重要性的重构损失系数。
[0033]
关于本发明的第一方面,在用于计数dga突发的数量的sfc以及用于检测频谱中的峰值的fsa模块中使用的峰值检测和分层聚类算法包括用于峰值检测的恒定虚警率(constant false alarm rate,cfar)检测算法和用于分层聚类的凝聚聚类。
[0034]
关于本发明的第一方面,fsr模块还被配置为:从深度学习分类器模块获得具有dga相关联的域名但被dns服务器打标有noerror返回码的dns记录;从sfc模块获得由sfc模块输出的每个序列的最多的c个dga特征;从具有dga相关联的域名的noerror dns记录中,识别就源ip、目的地ip和分析时间段而言、对应于每个序列的dns记录,dns记录表现出相应的序列的最多的c个dga特征中的至少一个,作为它们的最多的k个dga特征之一,如sfc模块所确定的;以及向警报模块提供对应于每个序列的识别的域名。
[0035]
根据本发明的第二方面,一种使用系统来检测域生成算法(dga)行为的方法,其中系统包括深度学习分类器(dl-c)模块;序列过滤器-分类器(sfc)模块;寻找成功解析(fsr)模块;自动编码器-分类器(ae-c)模块,包括合并成单个神经网络的自动编码器和分类器;频谱分析器模块(fsa)和警报模块,所述方法包括:使用dl-c模块接收域名系统(dns)记录流;使用dl-c模块识别具有dga相关联的域名和与dga相关联的域名中的每一个相关联的dga特征的dns记录,使用sfc模块,基于与每个识别的dga dns记录相关联的源ip、目的地ip和分析时间段,将来自dl-c模块的识别的dns记录分组为序列,由此对于每个序列,识别并选择nxdomain dga相关联的域名,nxdomain dga相关联的域名表现出该序列的最多的c个发生的dga特征中的至少一个作为其最多的k个特征之一,并基于最多的c个发生的dga特征标记该序列;使用sfc模块,基于每个序列的相关联时间戳对每个序列进行排序,并且基于该序列的第一记录对每个序列中的时间戳进行归一化,以获得在分析时间段内dga发生事件的时间序列;使用sfc模块向寻找成功解析(fsr)模块提供与识别的nxdomain dga dns记录不相关联的noerror dns记录,fsr模块被配置为从接收的dns中识别与命令和控制服务器相关联的dga域;使用ae-c模块,为从sfc模块获得的dga发生事件的每个时间序列生成,每个标记序列的相干性分数,以及移除相干性分数在预定阈值以下的序列,其中使用从sfc模块获得的发生事件的标记时间序列、和基于从序列的标记导出的单热向量的分量、分类器的softmax输出的维度和由系数α加权的重构损失的损失函数来训练自动编码器-分类器模块;使用fsa模块识别与dga发生事件的每个时间序列相关联的dga频域峰值,以便确定dga发生事件的每个时间序列内的周期性信号;使用fsa模块确定dga发生事件的每个时间
序列内的每个周期性信号的频率和相应的周期;使用fsa模块识别对于每个确定的频率存在的相移信号的数量;以及使用警报模块,基于由sfc模块产生的dga发生事件的时间序列、由ae-c模块产生的时间序列、由fsa模块确定的相移信号的识别的数量以及由fsr模块确定的识别的dga域来对dga警报进行优先排序。
[0036]
根据本发明的第二方面,该方法还包括以下步骤:使用平滑过滤器和离散傅立叶变换模块,将平滑过滤器应用于由sfc模块输出的dga发生事件的时间序列;和使用离散傅立叶变换算法将dga发生事件的过滤后的时间序列从时域转换到频域,使得ae-c模块的神经网络的输入包括频谱。
[0037]
根据本发明的第二方面,在深度学习分类器模块识别具有dga及其相关联的特征的dns记录的步骤之前,所述方法还包括以下步骤:使用机器学习串分析器(ml-sa)模块,基于机器学习算法,过滤dns记录,以从dns记录中移除与已知的dga不相关联的域名,由此使用以下标记的特征中的至少一个来训练机器学习算法:域名的长度、域名的熵、域名的字符n-gram、域名的不同字符计数、网络图或单词图相似性分数,以及由此使用标记的开源数据集、内部数据库和第三方数据库来训练机器学习算法。
[0038]
根据本发明的第二方面,深度学习分类器模块包括:只看一次(yolo)架构,被配置为:基于字符级令牌化来训练自身,以产生一组嵌入,该组嵌入通过神经网络来产生二元决策,以确定域名串是否包括dga,以及如果确定域名串包括dga,则生成指示该域名串属于哪个已知的dga族的概率分布。
[0039]
根据本发明的第二方面,yolo架构包括通信连接到深度神经网络的嵌入层,由此嵌入层被配置为将字符令牌的列表转换为矩阵,并且其中深度神经网络被配置为使用基于二元交叉熵损失和分类交叉熵损失的复合损失函数,其中复合损失函数被定义为:
[0040][0041]
其中b被定义为指示特定串是否包括dga的标记,b被定义为指示特定串是否是dga的神经网络的sigmoid输出,ti被定义为仅在与特定dga串的族标记相对应的位置处被激活的单热向量的特定维度,被定义为由神经网络输出的softmax激活向量,n被定义为的维度的总数,其对应于用于训练模型的已知的dga族的总数,并且γ被定义为可调谐系数,其用于加权二元交叉熵损失和softmax交叉熵损失之间的相对重要性。
[0042]
根据本发明的第二方面,其中在通过dl-c模块将sfc模块应用于已经与dga域串相关联的dns记录的步骤之前,所述方法包括以下步骤:使用基于黑名单和规则的过滤模块移除与类dga算法相关联的合法域;并移除具有无效域和顶级域(tld)特征的域名。
[0043]
根据本发明的第二方面,其中用于训练自动编码器-分类器模块的损失函数被定义为:
[0044][0045]
其中,i
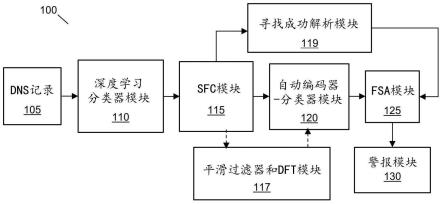
x
被定义为与sfc模块输出的dga发生事件的时间序列相关的输入信号,该
输入信号作为输入被馈送到自动编码器,iy是自动编码器的输出信号,pi是从由sfc模块打标到该序列的标记中导出的单热点向量的第i维度,pi是分类器的softmax输出的第i维度,以及α是用于加权分类损失相对于重构损失的相对重要性的重构损失系数。
[0046]
根据本发明的第二方面,在用于计数dga突发的数量的sfc以及用于检测频谱中的峰值的fsa模块中使用的峰值检测和分层聚类算法包括用于峰值检测的恒定虚警率(cfar)检测算法和用于分层聚类的凝聚聚类。
[0047]
根据本发明的第二方面,该方法还包括以下步骤:使用fsr模块从深度学习分类器模块获得具有dga相关联的域名但被dns服务器打标有noerror返回码的dns记录;使用fsr模块从sfc模块获得由sfc模块输出的每个序列的最多的c个dga特征;使用fsr模块从具有dga相关联的域名的noerror dns记录中,识别就源ip、目的地ip和分析时间段而言、对应于每个序列的dns记录,dns记录表现出相应的序列的最多的c个dga特征中的至少一个,作为它们的最多的k个dga特征之一,如sfc模块所确定的;和使用fsr模块向警报模块提供对应于每个序列的识别的域名。
附图说明
[0048]
根据本发明的系统和方法的特征和优点解决了上述和其他问题,该系统和方法在详细描述中描述并且在以下附图中示出。
[0049]
图1示出了可用于实现根据本发明的实施例的用于检测域生成算法(dga)行为的系统的模块的框图;
[0050]
图2示出了代表提供根据本发明的实施例的实施例的处理系统的框图;
[0051]
图3示出了可用于实现根据本发明的实施例的深度学习分类器模块的模块的框图;
[0052]
图4示出了根据本发明的实施例的绘制图,该绘制图示出了从可能的dga序列中提取的、由序列过滤器-分类器模块(sfc)输出的、被认为表现出相似的串特征的可能的dga发生事件的数量相对于时间的时间序列;
[0053]
图5示出了可用于实现根据本发明的实施例的自动编码器-分类器(ae-c)模块的框图;
[0054]
图6示出了根据本发明的实施例的、当周期t为0.1和0.05秒时、在时域及其相应的频域中表现出狄拉克(dirac)梳状属性的信号的绘制图;
[0055]
图7示出了根据本发明的实施例的时域中的多个相移信号的绘制图及其对应的频域绘制图;
[0056]
图8示出了根据本发明的实施例的用于检测dga行为的系统的多个实施例;
[0057]
图9示出了根据本发明的实施例的使用深度学习分类器模块、序列过滤器-分类器模块、自动编码器-分类器模块、频谱分析器模块、寻找成功解析模块和警报模块来检测dga行为的示例性过程;
[0058]
图10示出了时间分析在为现实生活中的dga警报提供更高可信度方面的重要性;和
[0059]
图11示出了尽管缺乏规则和手工设计的特征、本发明仍能检测到的新威胁。
具体实施方式
[0060]
本发明涉及一种用于从域名系统(dns)记录流中检测表现出类似域生成算法(dga)行为的域名的系统和方法。具体而言,本发明涉及一种系统,该系统包括深度学习分类器(dl-c)模块,用于在已过滤的dns记录被提供给序列过滤器-分类器(sfc)模块之前,接收并过滤dns记录流,其中已过滤的dns记录被确定为拥有表现出dga行为的域名(在下文中,这些域名将可互换地称为dga域名或可能的dga域名)。
[0061]
对于每个源互联网协议(ip)、目的地ip和分析时间段三元组,sfc模块随后将相关联的dga记录分组为各种序列。然后,对于每个序列,它会过滤掉如由dl-c模块确定的、不会表现出类似dga特征的dga域名及其相应的dns记录。接下来,sfc模块为存在于每个源ip、目的地ip和分析时间段之间的每个剩余dga记录序列打标标记。
[0062]
最后,sfc模块利用dns记录的时间戳来生成dga发生事件的时间序列,然后,使用这些发生事件的时间序列,确定整个分析时间段内dga突发的数量。
[0063]
然后,自动编码器-分类器(ae-c)通过根据dga发生事件的相应时间序列,分析相关性时间段内的相关性,为每个dga记录序列分配相干性分数。然后使用频谱分析器(fsa)模块将dga发生事件的时间序列转换为频谱,然后识别在每个dga记录序列内发生的周期性dga突发。并行地,查找成功解析(fsr)模块利用如由sfc模块确定的每个序列的特征来查找解析到可能的命令和控制(c2)服务器的dga域名。然后,由fsr、fsa和ae-c模块生成的信息连同由sfc模块产生的可能的dga域名序列和其他丰富的细节被传递到警报模块,该警报模块然后使用该信息向用户呈现和优先化用文本和时间信息丰富的dga警报,允许用户将注意力更好地集中在具有如下那些的警报上:经评估呈现出dga行为的域名序列中明显的文本相似性、由ae-c模块评估的更高相干性分数、由我们的fsa模块评估的周期性以及由fsr模块评估的对可能的c2服务器的可能解析。
[0064]
现在将参考如附图所示的几个实施例详细描述本发明。在以下描述中,阐述了许多具体特征,以便提供对本发明的实施例的透彻理解。然而,对于本领域的技术人员来说,显而易见的是,实施例可以在没有一些或全部特定特征的情况下实现。这样的实施例也应该落入本发明的范围内。此外,下文中的某些过程步骤和/或结构可能没有详细描述,读者将参考相应的引用,以免不必要地模糊本发明。
[0065]
此外,本领域技术人员将认识到,本说明书中的许多功能单元在整个说明书中都被标记为模块。本领域技术人员还将认识到,模块可以实现为电路、逻辑芯片或任何种类的分立组件,并且多个模块可以根据需要组合成单个模块或者分成子模块,而不脱离本发明。此外,本领域技术人员还将认识到,模块可以用软件来实现,然后可以由各种处理器来执行。在本发明的实施例中,模块还可以包括计算机指令或可执行代码,其可以指示计算机处理器基于接收到的指令执行一系列事件。模块实现的选择留给本领域技术人员作为设计选择,并不以任何方式限制本发明的范围。
[0066]
图1示出了根据本发明的实施例的用于检测表现出域生成算法(dga)行为的dns记录序列的系统。如图所示,系统100包括深度学习分类器(dl-c)模块110、序列过滤器-分类器(sfc)模块115、自动编码器-分类器(ae-c)模块120、频谱分析器(fsa)模块125、寻找成功解析(fsr)模块119、警报模块130以及可选的平滑过滤器和离散傅立叶变换(dft)模块117。
[0067]
在操作中,在感兴趣的时间段内收集dns记录流105,并将其提供给深度学习分类
器模块110。该时间段可以包括任意数量的天、周或月,并且留给本领域技术人员作为设计选择。随后,该感兴趣的时间段将被称为相关性时间段,因为我们基本上试图在该时间段内找到相关性,以确定应该被赋予更高置信度的警报。在本发明的实施例中,该时间段可以包括一个月或30天。
[0068]
深度学习分类器模块(dl-c)110然后分析包含在dns记录105中的每个域名,以确定该域名是否是dga域名,并确定该域名表现出的dga特征。换句话说,模块110将识别具有可能与dga相关联的域名的dns记录,并且对于这些识别的可能的dga域名,量化它们与每个已知的dga族的相似程度。例如,如果有87个已知的dga族,被dl-c模块认为是可能的dga域名的每个域名将具有相关联的87维向量,其中,向量的每个元素指示域名和特定族之间的相似性百分比。然后,模块110从dns记录中移除被dl-c模块认为不是dga的dns记录。参考图3,在后面的部分中更详细地描述预先训练的深度学习分类器模块110的详细工作(并且可选地可以随着其训练数据集的更新而更新)。剩余的dns记录然后被提供给sfc模块115。
[0069]
在模块115,剩余的dns记录基于源互联网协议(ip)、目的地ip和分析时间段(例如几天)被分组,并且该时间段被任意选择,使得时间序列特征可以在固定的时间段内被确定。在我们的实施例中,我们使用1天作为分析时间段。请注意,此分析时间段不同于相关性时间段。具体而言,将从该分析时间段中提取特征,以确定它们是否在相关性时间段内相关。因此,分析时间段是相关性时间段的子集。在此过程结束时,已被认为具有dga特征的各种dns记录将根据源-目的地ip对和分析时间段进行分组。这最终为我们提供了每个相关联的源-目的地ip对和分析时间段的可能的dga dns记录序列。该dns记录序列包含域名串及其相关联的时间戳,允许我们进行基于串和基于时间的分析。
[0070]
然后对每个潜在的dga dns记录序列应用过滤器,以过滤掉包含没有被dns服务器(未示出)用nxdomain响应代码(rcode)标记的域名的记录。模块115然后识别由用nxdomain rcode打标的各种可能的dga域名序列显示的dga特征的主要类型。然后,不表现出至少一个主要识别特征的nxdomain域名及其相关联的dns记录也会从相应序列中移除。到本模块结束时,每个域名序列也将被打标到已知的dga族之一。此外,应当注意,每个序列中的每个剩余项目也将显示由模块110确定的彼此相似的特征,因为模块110的输出被用于识别每个序列的主要dga特征。换句话说,只有表现出发生最多的几个dga特征(top few occurring dga characteristics)中的至少一个dga特征的可能的dga域名将被选择保留在每个序列中,然后每个序列基于与聚类相关联的发生最多的dga特征(top occurring dga characteristic)被标记。
[0071]
在本发明的示例性实施例中,序列过滤器-分类器可以被配置为执行以下方法:
[0072]
1.最初,由深度学习分类器模块110确定的每个序列中的每个域名表现出的最多的k个已知的dga特征被选择。例如,如果特定的序列包括n
total
个dns记录、以及相应的n
total
个域名串,将选择已知的dga类的n
total
×
k矩阵。
[0073]
2.没有打标为nxdomain的dns记录将被过滤掉,从而形成dga类的n
nxdomain
×
k矩阵。
[0074]
3.然后,n
nxdomain
×
k矩阵的模式m被用来将该序列标记为dgam。
[0075]
4.然后我们可以找到n
nxdomain
×
k矩阵中发生频率最多的c个特征,m1m2,
…
mc。
[0076]
5.然后,在它们的最多的k个类中没有m1m2,
…
mc中的至少一个的所有域都被过滤掉。
[0077]
在该过程结束时,每个dns记录序列将被标记为其相应的标记m,深度学习分类器模块110认为该标记是每个dns记录序列所显示的主要特征。此外,每个dns记录序列现在只包含nxdomain dns记录,这些记录表现该序列的最多的c个特征中的至少一个作为其最多的k个特征之一。在本发明的实施例中,k的值可以任意设置为5(并且通常基于dl-c模块在试图实现任意分类精度时的性能),c可以任意设置为1并且必须小于或等于k。
[0078]
然后基于每个序列的相关联的时间戳对每个序列进行排序(sort),然后在分析时间段对每个序列中的时间戳进行归一化。在本发明的实施例中,可以在将序列过滤器-分类器应用于每个序列之前,基于它们的相关联的时间戳对每个序列进行排序,并对时间戳进行归一化。在本发明的实施例中,这种排序是在序列内完成的,以确保记录是按时间顺序排序的。这是通过使用时间戳属性来完成的,时间戳属性是典型的dns记录结构的字段之一。
[0079]
因此,将生成多个dns记录序列,并且每个dns记录序列内的记录将在分析时间段内(例如1天)按时间顺序排序,并且将由深度学习分类器模块110分类,以将每个序列中发生频率最多的c个dga特征显示为它们的最多的k个特征之一。
[0080]
总之,到目前为止,每个dns记录序列都有标记m,并且该序列的每个元素都包含nxdomain类型的dns记录。然后,与每个序列中的每个dns记录相关联的时间戳被用于制定发生事件的时间序列,即dga发生事件的数量相对于时间的绘制图。为此,首先计算相对时间(即序列中的每个记录和序列中的第一记录之间的时间差-时间戳的归一化)。相对时间然后被分格为预定的时间间隔(即时间间隔分格被称为采样周期),由此在本发明的示例性实施例中,采样周期可以被设置为1分钟(即60秒)。
[0081]
如图4所示的绘制图400示出了相对于1天分析时间段绘制的可能的dga发生事件的数量,由此在该绘制图中,x轴被设置为1440分钟,这相当于1天的时间段。对于每一分钟(就相对时间而言),相对于第一记录,在该分钟内发生的记录数量被合并(即被分格)、计数和绘制。
[0082]
模块115的最后一步是利用典型的峰值检测和聚类算法来计算在整个分析时间段中发生的dga突发的数量。我们将dga突发定义为dga发生事件组,这些发生事件组可以相互链接,其中链的每个元素之间的间隔最多为tc分钟。这意味着,在下一次dga发生事件之前的至少tc分钟内,我们必须没有dga发生事件,才能宣布2次突发(即,在这tc分钟内发生的任何dga发生事件都将与第一次突发的其他元素链接在一起)。在一些实施例中,tc可以任意设置为5分钟。在我们的实施例中,该附加信息用于进一步丢弃在整个分析时间段中仅表现出单个突发的序列。在本发明的实施例中,恒定虚警率(cfar)算法和分层聚类被用于确定在整个分析时间段发生的dga突发的数量。由于cfar和分层聚类的使用在合成孔径雷达应用中被广泛使用和记录,为了简洁起见,将不再详细描述。
[0083]
这些时间序列然后被提供给自动编码器-分类器(ae-c)模块120,由此dga发生事件的各种时间序列和与每个可能的dga dns记录序列相关联的标记m被用于训练该模块。ae-c模块120的详细工作将在后面的部分中参照图5进行更详细的描述。一旦模块120已经使用这些序列被训练,训练的自动编码器-分类器模块120随后被应用于这些序列中的每一个,以生成相干性分数。模块120的目的是确定学习与每个被标记序列相关联的时域(或者在一些实施例中,频域)特征的容易程度,并且相应地,确定模块115已经给予相同标记的各序列之间是否存在相干性。较高的相干性分数指示,与相同标记的其他序列相比,特定序列
nxdomain dns记录序列相关联的每个可能的dga发生事件时间序列中存在的可能的频率和每个频率的相关联的信号的数量,以及(5)dns服务器解析的可能的noerror dga域名,指示可能的c2域。通过在这些附加的丰富数据字段中的每一个上设置阈值,dga警报可以被优先化并呈现给系统的用户,使得更高置信度的警报可以被快速地采取行动。
[0089]
在本发明的实施例中,来自警报模块130的输出可以包括如下nxdomain域名的列表或序列,该列表或序列已经被分类以显示:作为它们的最多的k个特征之一的特征m1,m2,
…
mc中的至少一个(其中mi是与已知的dga族相关联的标记)、在分析时间段内发生的dga突发的数量、指示独特的可学习的可以与由sfc模块115打标到每个dns记录序列的标记相关联的特征的存在的相干性分数、基于dga发生事件的时间序列计算的频率和每个频率处的信号的数量的列表(其中这种频率的存在指示自动化进行dga突发的软件的存在,因此可以用于指示恶意软件存在的增加的概率)、以及最后的相关联的已解析的noerror dga域名序列(其指示解析到可能的c2服务器的可能的dga域名)。
[0090]
在本发明的另一个实施例中,平滑过滤器和离散傅立叶变换(dft)模块117可以被配置为将与模块115输出的每个可能nxdomain dga dns记录序列相关联的可能nxdomain dga发生事件的时间序列从时域转换到频域(即频谱)。然后,自动编码器-分类器模块120将利用频谱来计算相干性分数,以代替可能的dga发生事件的时间序列。
[0091]
根据本发明的实施例,在图2中示出了表示处理系统200的组件的框图,该组件可以设置在模块110、115、120、125、130、117、119和用于实现根据本发明的实施例的实施例的系统的任何其他模块内。本领域技术人员将认识到,在这些模块中提供的每个处理系统的确切配置可能不同,并且处理系统200的确切配置可能不同,并且图2仅作为示例提供。
[0092]
在本发明的实施例中,系统100中的每个模块可以包括控制器201和用户接口202。用户接口202被设置成能够根据需要在用户和这些模块中的每一个之间进行手动交互,并且为此目的包括用户输入指令以向这些模块中的每一个提供更新所需的输入/输出组件。本领域的技术人员将认识到,用户接口202的组件可以因实施例而异,但是通常包括显示器240、键盘235和跟踪板236中的一个或多个。
[0093]
控制器201经由总线215与用户接口202进行数据通信,并且包括存储器220、安装在电路板上的处理用于执行本实施例的方法的指令和数据的处理器205、操作系统206、用于与用户接口202通信的输入/输出(i/o)接口230以及通信接口,在该实施例中,通信接口是网卡250的形式。例如,网卡250可以用于通过有线或无线网络从这些模块向其他处理设备发送数据,或者通过有线或无线网络接收数据。网卡250可以使用的无线网络包括但不限于无线保真(wi-fi)、蓝牙、近场通信(nfc)、蜂窝网络、卫星网络、电信网络、广域网(wan)等。
[0094]
存储器220和操作系统206通过总线210与cpu 205进行数据通信。存储器组件包括易失性和非易失性存储器以及每种类型的存储器中的一种以上,包括随机存取存储器(ram)220、只读存储器(rom)225和大容量存储设备245,后者包括一个或多个固态驱动器(ssd)。存储器220还包括安全存储器246,用于安全地存储密钥或私钥。本领域技术人员将认识到,上述存储器组件包括非暂时性计算机可读介质,并且应当被认为包括除暂时性传播信号之外的所有计算机可读介质。通常,指令作为程序代码存储在存储器组件中,但也可以硬连线。存储器220可以包括内核和/或编程模块,例如可以存储在易失性或非易失性存
储器中的软件应用。
[0095]
这里,术语“处理器”用于泛指能够处理这种指令的任何设备或组件,并且可以包括:微处理器、微控制器、可编程逻辑设备或其他计算设备。也就是说,处理器205可以由任何合适的逻辑电路提供,用于接收输入,根据存储在存储器中的指令处理它们并产生输出(例如到存储器组件或在显示器240上)。在该实施例中,处理器205可以是具有存储器可寻址空间的单核或多核处理器。在一个示例中,处理器205可以是多核的,包括例如8核cpu。在另一个例子中,它可以是并行运行以加速计算的cpu核的聚类。
[0096]
图3示出了根据本发明的实施例的可用于实现深度学习分类器模块110的模块。在操作中,模块110被配置为接收一批域名串305,并从该批中识别哪些域名包括可能的dga域名。对于这些识别出的可能的dga域名,模块110然后确定这些域名所表现的已知的dga族中的特征。通常,模块110利用修改的只看一次(you-only-look-once,yolo)架构和修改的损失函数来预训练深度学习模型。这是使用从标记的开源数据集、内部数据库和第三方数据库收集的数据来完成的。这些数据包括以下内容:(1)域名串,(2)域名串是否是dga,以及(3)如果域名串是dga,则相关联的dga族可以用于经由从yolo算法导出的复合损失函数来训练深度神经网络。
[0097]
如图3所示,域名串305首先被提供给令牌化和填充模块310。根据本发明的实施例,在模块310,域名串在字符级被令牌化,其中每个字符被分配整数。在该实施例中,以下字符可以被令牌化:
[0098]
a.26个小写字母:“a”到“z”[0099]
b.10个数字:“0”到“9”[0100]
c.1个子域分隔符:“.”[0101]
d.1个未登录(out-of-vocab)令牌,用于其他任何东西
[0102]
e.1个,用于填充
[0103]
本领域技术人员将认识到,在不脱离本发明的情况下,其他类型的字符也可以被令牌化。作为上述令牌化方法的结果,可以生成多达38个令牌,每个令牌对应于上述字符之一。然后向令牌中添加附加的令牌,以根据需要填充令牌。下面的表1说明了示例性的令牌化和填充过程,由此在串中的字符和它们对应的令牌之间进行映射:
[0104]
字符填充
‘a’‘b’…‘z’‘0’‘1’‘2’…‘’
其他任何东西令牌012
…
26272829
…
3738
[0105]
表1
[0106]
作为令牌化过程的示例,串“ab.ab”将根据表1中的映射转换为整数列表,如下所示[1,2,37,1,2]。在令牌化过程之后,每个整数列表将被预填充或截断到80(任意选择)的长度。这意味着包含少于80个令牌的整数列表将在列表前面添加令牌0,直到总长度为80。对于超过80个令牌的列表,将只考虑最后80个令牌。
[0107]
然后,各种列表被提供给嵌入层315。嵌入层315包括可训练层,并且其被配置为将32维向量分配给38个令牌中的每一个。本领域技术人员将认识到,在不脱离本发明的情况下,可以使用其他尺寸的维度向量。当每个列表通过嵌入层315时,该列表将被转换成32
×
80矩阵(行
×
列),由此80列中的每一列对应于32维向量,该向量由嵌入层315根据在特定字符位置找到的令牌来分配。
[0108]
该32
×
80矩阵然后被提供给深度学习神经网络317,包括序列模型320,序列模型320可以包括但不限于递归神经网络(rnn)、卷积神经网络(cnn)、变换器神经网络(transformer neural network,tnn)或三者的组合。序列模型320的输出然后可以被展平成单个向量,该向量然后可以被传递到多层感知器(mlp)层模型325以产生以下输出:
[0109]
1.由sigmoid函数激活的单个神经元,其指示域串是否为dga(1代表dga,
[0110]
0代表非dga),用符号b表示;或者
[0111]
2.由softmax函数共同激活的87个神经元的组合,其提供了在87个已知的dga类中,域串表现出哪些特征的指示。这个维度向量被表示为
[0112]
很明显,对于mlp 325模型的多个输出,需要复合损失函数。为了确定复合损失函数,二元交叉熵损失和分类交叉熵损失定义如下:
[0113]
二元交叉熵损失=-b log(b)-(1-b)log(1-b)
[0114][0115]
其中b被定义为特定串是否为dga的标记,即对于dga串为1,对于非dga串为0,b被定义为指示特定串是否为dga的神经网络的sigmoid输出,被定义为单热点向量,1对应于被标记的dga类,并且ti表示单热点向量的特定维度。
[0116]
在本发明的一个实施例中,在假设已知的87个dga类/族的情况下,单热点向量和维度向量都将包括87个维度向量,并且n表示维度的总数。因此,复合损失函数可定义如下:
[0117][0118]
其中γ是系数,该系数可以被调谐以加权两个损失函数的相对重要性。值得注意的是,在第二项中,b、作为布尔地面真值(boolean ground truth)标记(关于特定串是否为dga)也被用作系数。这个公式指示,分类交叉熵损失只有当域串被标记为dga时才被优化,否则只有二元交叉熵损失被优化。这类似于yolo算法的公式。这种方法是有利的,因为它允许神经网络经由神经网络的单个前向通路同时输出(1)特定串是dga的概率和(2)如果该特定串被确定为dga,则由该特定串显示的已知的dga的特征。
[0119]
一旦定义了复合损失函数,就可以使用如adam、随机梯度下降(sgd)等优化算法来训练模型。在本发明的实施例中,随机加权平均(swa)算法与不连续的循环学习速率一起用于训练深度学习模型317和嵌入层315。基于变换器的架构也用于降低损失函数的过拟合。
[0120]
一旦模型317和嵌入层315被训练,dga确定模块330可以使用模型317的二元输出b来确定域串是否是dga,并且dga族分类器335可以使用其输出向量来确定dga可能属于的dga族。此外,由于输出由于其softmax激活层而包括离散的概率分布,因此输出可以被解释为加权的特征,由此加权与输入域串表现出的dga特征成比例(相对于87个已知的dga类)。简而言之,在深度学习分类器模块110结束时,只有具有被模块110的dga确定模块330认为
是dga的域串的dns记录将保留,而其他记录将被丢弃。
[0121]
图5示出了可用于实现根据本发明的实施例的自动编码器-分类器(ae-c)模块120的模块。特别地,ae-c模块120包括复合自动编码器和分类器550,复合自动编码器包括模块510和520中的序列模型,分类器550包括模块530和535中的序列模型和多层感知器(mlp)的组合。编码515只是由编码器模块510输出的i
x 505的低维表示。解码器模块520将使用该低维表示来产生重构的输出iy,其理想地等同于i
x
。在本发明的实施例中,当输入i
x 505包括作为输入的时间序列(并且输出iy包括重构的时间序列)时,模块510、520、530和535可以包括基于存储器的模块、无存储器模块或者基于存储器/无存储器模块的组合。在本发明的另一个实施例中,当输入i
x 505包括经由dga发生事件的时间序列的离散傅立叶变换(dft)获得的频谱作为输入(并且输出iy包括重构的频谱)时,模块510、520、530和535可以包括多层感知器(mlp)。
[0122]
概括地说,来自sfc模块115的输出被提供给ae-c模块120。这些输出包括包含dga相关联的域名序列,这些域名表现出该序列的至少一个最多发生的c个dga特征作为其最多的k个特征之一。此外,这些序列中的每个序列中的dns记录已经基于它们的相关联的时间戳被排序,并且基于每个序列的第一记录被归一化,以产生在分析时间段内dga发生事件的次数的相关联的时间序列(例如,如图4所示的绘制图400)。这些序列中的每一个也被确定为在分析时间段内具有比预设阈值更多的dga突发,并且还基于与该序列相关联的最多发生的dga特征被标记。然后,自动编码器-分类器120被配置为使用这些序列作为标记数据集,以经由传统的监督学习技术训练深度学习模型。
[0123]
自动编码器-分类器120旨在确定在接收到的序列数据集中是否存在可学习的结构,特别是,如果使用模块117,则确定与每个dns记录序列或其相应的频谱相关联的dga发生事件的时间序列。换句话说,给定各种序列及其相关联的标记,自动编码器-分类器120将确定数学模型是否可能学习和区分各种标记之间的模式,如果可能,学习和区分到什么程度。这背后的想法是确定每个标记是否存在唯一的可辨别的数据结构。如果没有,数学模型的可信度就会很低,因为它本质上是在类似噪声的输入上进行训练。
[0124]
如图5所示,低维编码515被提供给分类器550。分类器550然后将确定模块120的输入是否具有结构,并且如果它确定存在结构,分类器550将继续学习输入的每个类的定义。
[0125]
在本发明的实施例中,训练自动编码器-分类器120的损失函数l可以定义如下:
[0126][0127]
其中pi是从与每个输入i
x
相关联的标记m导出的单热向量的第i分量,iy是解码器模块520的输出,其理想地是输入i
x
的重构,pi是分类器550的softmax输出的第i维度,并且α是重构损失的系数。
[0128]
在本发明的示例性实施例中,假设存在87个已知的dga类。因此,和都将包含87维向量。在本发明的一些实施例中,可以仅使用分类器550和编码器510,而不需要解码器520。这实质上把它变成了一个简单的分类问题。然而,在本发明的大多数实施例中,需要包括解码器520的自动编码器损失被用作一种正则化形式,以确保神经网络将其分类基于较
小维度的嵌入515,从该嵌入可以重构i
x
,而不是简单地记忆输入505。
[0129]
一旦自动编码器-分类器120使用损失函数l针对特定数量的时期(在我们的实施例的情况下为1000个时期)被训练,训练的自动编码器-分类器120然后可以被应用于用于训练它的相同数据。然后,自动编码器-分类器120为模块115产生的每个可能的dga序列产生作为其输出的相干性分数。相干性分数表示由自动编码器-分类器120给出的置信度分数,由此置信度分数越高,应该对特定dns记录序列给予的关注就越多,因为这意味着在分析时间段(在我们的实施例中为1天)内分析的其时间/频率特征已经被认为在相关性时间段(在我们的实施例中为1个月)内被多次观察到。
[0130]
重要的是要注意,在自动编码器-分类器120中训练的模型的目的是评估是否有任何时间特征(以及相应的频谱特征)可以与仅在相关性时间段内被打标到每个可能的dga dns记录序列的每个dga标记相关联。这样,自动编码器-分类器120中使用的模型并不意味着推广到其他相关性时间段(在我们的实施例中,其他月份的数据)。因此,一旦它在当前相关性时间段中输出每个序列的其置信度和分类,它就被丢弃。
[0131]
根据本发明的实施例,由sfc模块115输出并随后经由自动编码器-分类器120用相干性分数来丰富的序列然后被提供给fsa模块125。如前所述,fsa模块125旨在确定是否存在由与可能的dga dns记录序列相关联的时间戳显示的任何强时间上周期性的行为。fsa模块125对dga发生事件的时间序列应用平滑过滤器,随后是离散傅立叶变换(dft),以在进行深度频率分析之前将其从时域转换到频域,以列举信号内的可能频率和每个频率处相移信号的数量。
[0132]
值得注意的是,在此描述的方法不仅限于分析dga时间戳序列中的周期性,还可以用于检测显示类似特征的其他威胁,诸如信标(beaconing),信标被定义为源目的地ip对之间的周期性通信(即心跳)。
[0133]
根据本发明的实施例,fsa模块125如下工作:
[0134]
1.该模块的输入包括发生事件的时间序列。然后,通过将窗口函数/平滑过滤器(在我们的实施例中,汉宁过滤器)应用于发生事件的时间序列,可以获得经过过滤的发生事件的时间序列。
[0135]
2.当使用发生事件的时间序列时,周期性信号将在时域中显示其自身,如图6的绘制图605和615所示。可以看出,绘制图605和615描绘了分别每0.1和0.05秒重复一次的信号,每次一个发生事件。
[0136]
3.上述信号实际上类似于狄拉克梳(dirac comb)(也称为狄拉克列(dirac train))。狄拉克梳具有非常有用的性质,即以f1赫兹的频率重复(即,每秒重复一次)的狄拉克梳的傅里叶变换的幅度也是其狄拉克函数在频域中每f1赫兹重复的狄拉克梳。作为绘制图605的傅立叶变换的绘制图610和作为绘制图615的傅立叶变换的绘制图620说明了这个概念。
[0137]
4.数学上,它可以描述如下:
[0138][0139]
其中f()代表傅里叶变换,δ是狄拉克函数,t1是狄拉克序列的周期。
[0140]
5.在上面的等式中,有两件事需要注意:
[0141]
a.首先,狄拉克梳在时域中的频率可以通过观察狄拉克函数在频域中何时重复来确定。
[0142]
b.第二,狄拉克梳在频域中的幅度是这实际上是狄拉克函数在时域中的频率。
[0143]
6.使用以上两个推导,很明显,对于单个频率处的单个信号,可以通过识别狄拉克函数在频域中重复的位置来确定信号频率,并确保以f1(在频域中)的信号的幅度为
[0144]
7.接下来,应该注意的是:
[0145]
a.傅立叶变换是累加的。因此,时域中的多个信号(即,时域中多个信号的累加和)将仅仅是频域中的和。
[0146]
b.最后,应该指出:
[0147][0148]
上述等式表明,如果信号在时域中时移,它将在频域中表现为相移形式。因此,如果两个信号存在于相同的频率f1,但在不同的相位,频域幅度的幅度将不是2f1,而是
[0149]
下文阐述了fsa模块125的示例性伪代码。
[0150]
[0151][0152]
(中文翻译:
[0153]
1.输入:
[0154]
x
t
:汉宁过滤发生事件的时间序列2.计算xf=f(x
t
)
[0155]
3.对xf进行cfar和分层聚类,以确定峰值的位置。假设pf=
[0156]
{p0,p1,p2,
…
}是由cfar和分层聚类过程输出的频率的集合(按升序排序)。设mf=
{m0,m1,m2,
…
}是pf集合中每个频率的对应频谱幅度的集合。
[0157]
4.如果p0≠0hz,跳出算法,就此结束
[0158]
5.如果:p0=0hz
[0159]
zero_freq_mag=m0[0160]
分别从pf和mf的集合中移除p0和m0[0161]
6.初始化对象以存储最终输出:
[0162]
·
possible_freqs(可能的频率)=[]
[0163]
·
possible_freq_amplitude(可能的频率幅度)=[]
[0164]
·
possible_signal_count(可能的信号计数)=[]
[0165]
·
设min_num_sig为阈值最小信号数
[0166]
7.对于pf中的每个pn:
[0167]
使用计算频率pn下的信号数量n
s,tent
[0168]
如果:n
s,tent
>min_num_sig
[0169]
如果possible_freqs==[]:
[0170]
附加pn到possible_freqs
[0171]
附加mn到possible_freq_amplitude
[0172]
附加n
s,tent
到possible_signal_count
[0173]
否则:
[0174]
如果pn不能被possible_freqs中的任何项目整除:
[0175]
附加pn到possible_freqs
[0176]
附加mn到possible_freq_amplitude
[0177]
附加n
s,tent
到possible_signal_count
[0178]
否则:
[0179]
设div_freq是pn可被除尽的频率,并且n
s,tent,div
是div_freq上估计存在的信号数。
[0180]
如果:mn>div
freq
×ns,tent,div
[0181]
附加pn到possible_freqs
[0182]
附加m
n-(div
freq
×ns,tent,div
)到possible_freq_amplitude
[0183]
附加到possible_signal_count
[0184]
8.其中表示按元素划分的向上取整功能。
[0185]
9.unaccounted_magnitude=zero_freqs_mag-sum(possible_signal_count_rounded
×
possible_freqs)
[0186]
10.利用unaccount_magnitude以迭代地确定与unaccount_magnitude相加的possible_freqs中的pn的最佳组合,并将附加信号添加到相应的possible_signal_count_rounded的索引中。这个步骤可以通过众所周知的背包(knapsack)问题算法来解决,为了简洁起见,这里不再描述。
[0187]
11.在算法的最后,
[0188]
a.possible_freqs是一组可能的频率
[0189]
b.possible_signal_count_rounded是一个数组,它包含了possible_freqs中每个相应频率处的信号的数量
[0190][0191]
本领域技术人员将认识到,在不脱离本发明的情况下,可以使用其他形式的伪代码来执行fsa模块125的功能。利用上述算法和伪码,fsa模块将能够确定存在哪些周期性信号以及每个频率处的信号的数量。
[0192]
应该强调的是,即使狄拉克梳中存在多个频率,并且在每个频率上存在多个相移信号,上述方法也能够列举出存在的周期性信号。图7的绘制图705示出了这样一种情况,其中存在3个频率,多个信号处于其中一个频率。尽管如图7的绘制图710所示的傅立叶变换绘制图不再像图6的绘制图610和620那样一致,但是上述方法能够正确地列举和识别所有信号。
[0193]
图8示出了本发明的多个其他实施例,由此系统100可以包括但不限于附加模块的各种组合,诸如机器学习串分析器805和基于黑名单和规则的过滤模块810。
[0194]
在本发明的实施例中,机器学习串分析器(ml-sa)805可以被配置为在处理后的dns记录被提供给深度学习分类器模块110之前处理dns记录105。分析器805的主要目的是最初过滤大量的电信级dns记录,目的是移除显然不是dga的域名。为了执行该过滤步骤,本领域已知的任何基本机器学习模型,诸如随机森林算法,可以被预先训练并应用于dns记录的文本特征,以输出关于该串是否是可能的dga的二元决策。用于在ml-sa模块中训练模型的文本特征可以包括但不限于:
[0195]
i.长度
[0196]
ii.熵
[0197]
iii.字符n-gram(3,4,5)
[0198]
iv.不同字符计数
[0199]
v.网络图相似性分数:一个域与合法网络域的相似性
[0200]
vi.单词图相似性分数:一个域与词典单词的相似性
[0201]
需要注意的是,该模型的主要目的是减少系统的下游计算负荷。因此,设置了低阈值,使得真阳性被过滤掉的概率很低。随着越来越多的dga族为人所知,该模型可能会根据需要进行重新训练和更新。
[0202]
在本发明的其他实施例中,在序列过滤器-分类器模块115之前,基于黑名单和规则的过滤模块810被配置为使用黑名单来移除与类dga算法相关联的合法域和具有无效顶级域(tld)特征的域名。除了黑名单之外,模块810还将基于以下规则移除记录:
[0203]
1.与每个dns记录相关联的域名串查询必须是有效的域名。例如,必须至少有一个“.”在域名串查询中。
[0204]
2.域名串必须包含有效的tld。
[0205]
3.域名串中必须有有效字符。
[0206]
4.域名串中必须有有效的字符数。
[0207]
模块810使用的黑名单可以基于算法在延长的时间段内运行时获得的附加发现而随时间更新。此外,这些规则本质上非常简单,也可以根据用户的喜好进行修改。
[0208]
根据本发明的实施例的用于检测dns记录中的域生成算法(dga)行为的示例性系统或方法在以下步骤中阐述。由图1所示的系统实现的方法步骤如下:
[0209]
步骤1:使用深度学习分类器模块接收域名系统(dns)记录流;以及识别具有dga相关联的域名和与每个dga相关联的域名相关联的dga特征的dns记录;
[0210]
步骤2:使用序列过滤器-分类器(sfc)模块,基于与每个识别的可能的dga dns记录相关联的源ip、目的地ip和分析时间段,将来自深度学习分类器模块的识别的可能的dga dns记录分组为序列;将序列过滤器-分类器应用于每个序列,以选择表现出该序列的至少一个最多发生的c个dga特征的noerror dga相关联的域名作为它们各自的最多的k个特征之一,并基于该最多发生的c个dga特征标记该序列;基于每个序列的相关联的时间戳对每个序列进行排序,并且基于该序列的第一记录对每个序列中的时间戳进行归一化,以获得在分析时间段内dga发生事件的时间序列;以及对dga发生事件的时间序列应用峰值检测方法和分层聚类,以确定分析时间段内的dga突发的数量,并过滤掉dga突发少于特定预设量的相应序列。
[0211]
步骤3:对于从sfc模块获得的每个序列,使用包括合并在单个网络中的自动编码器和分类器的自动编码器-分类器模块来为由sfc模块用标记m打标的每个序列生成相干性分数,其中自动编码器-分类器模块使用从sfc模块获得的序列和标记以及基于从序列的标记导出的单热向量的分量、分类器的softmax输出的维度和按系数α加权的重构损失来训练;
[0212]
步骤4:使用频谱分析器(fsa)模块识别存在于dga发生事件时间序列中的周期性狄拉克梳信号、它们的相关联的频率以及每个频率处的相移信号的数量。
[0213]
步骤5:使用fsr模块识别解析到可能的c2服务器的可能的dga域名。
[0214]
步骤6:使用警报模块产生丰富的dga警报并对其进行优先排序,该警报具有数据字段,该数据字段包括从sfc模块获得的nxdomain dga dns记录序列及其相关联的突发的数量、从ae-c模块获得的相干性分数、从fsa模块获得的可能的周期性信号以及从fsr模块获得的解析到可能的c2服务器的可能的dga域。
[0215]
图9示出了根据本发明的实施例的检测dns记录中的dga行为的过程。过程900开始于步骤905,由此深度学习分类器模块被配置为接收dns记录流。然后,在步骤910,识别具有dga相关联的域名和与dga相关联的域名中的每一个相关联的dga特征的dns记录。过程900然后使用sfc模块基于与每个识别的dga dns记录相关联的分析时间段、源互联网协议(ip)和目的地ip,将识别的dns记录分组为序列。这在步骤915进行。
[0216]
在步骤920,过程900然后利用sfc模块来遍历每个序列,并选择表现出该序列的最多发生的c个dga特征中至少一个作为其最多的k个特征之一的dga相关联的域名;并基于最多发生的dga特征来标记该序列。这在步骤920进行。
[0217]
过程900然后再次利用sfc模块基于它们的相关联的时间戳对每个序列进行排序;以及基于聚类的第一记录来归一化每个序列中的时间戳,以获得在分析时间段内dga发生事件的数量的时间序列;并且经由典型的峰值检测和分层聚类算法来确定dga发生事件的每个时间序列的dga突发的数量;且过滤掉dga突发少于预设量的那些序列被丢弃。这在步骤925进行。
[0218]
过程900然后使用包括单个神经网络内的自动编码器和分类器的自动编码器-分类器模块,来为每个序列生成相干性分数。这在步骤930进行。
[0219]
在步骤935,过程900然后使用fsa模块识别存在于dga发生事件时间序列内的可能狄拉克梳信号,并根据确定它们的频率和每个频率处的信号的数量来列举它们。它首先对发生事件的时间序列应用适当的窗口函数,然后将其转换到频域进行深度频谱分析。
[0220]
在步骤940,使用fsr模块,过程900利用由sfc模块识别的序列的最多的c个特征来找到dga noerror dns记录,该记录也表现出这些特征中的至少一个作为它们的最多的k个特征之一,并且将它们声明为解析到c2服务器的dga域。
[0221]
过程900然后前进到步骤945,由此它使用警报模块,基于每个相关联的丰富数据字段的用户定义的阈值,产生具有丰富数据字段的dga警报并对其进行优先排序,丰富数据字段包括所有上述分析的结果。过程900然后结束。
[0222]
实验结果
[0223]
如图1所示,通过使用系统100对几个月的电信级流量数据进行的实验,发现系统100能够识别相似的dga记录并将这些dga记录分组在一起,从而显著减少威胁分析师的工作。对于文献中的大多数算法,dns记录被简单地分类,不管它是否是dga。这样做会导致大量的dga警报。与本领域技术人员已经提出的解决方案不同,系统100能够将电信数据月内的警报总数从900万个减少到227个,并且发现227个警报中的每一个都包含被认为具有相似串和可疑时间特征的域序列。在227个警报中,威胁分析师一眼就能确认其中85个警报是真正的阳性。其余的随后被发现是类dga的,但本质上没有恶意,因为一些合法的程序也为特定目的使用dga。这些可用于随后更新我们的内部数据库和黑名单。此外,发现系统100能够检测具有不同顶级域的dga串,而无需硬编码任何规则。此外,系统100能够检测多个dga序列,这些序列表现出如图10所示的时间行为。很明显,具有强烈的周期性信号,如频域中极其规则的模式所示,表明恶意软件行为的可能性很高。这突出了时间序列分析对于dga检测的重要性及其向系统用户提供显著更高置信度警报的能力。
[0224]
在我们的分析过程中,我们还选择了一些序列,如图11的绘制图1105所示。乍一看,本发明似乎获得了假阳性,因为这些域看起来并不相似。也有很多重复的领域。然而,在查看周期性分析后,如图11的绘制图1110所示,我们还发现了一些强周期性信号,这次是多个频率。在进行进一步深入分析后,我们的威胁分析师注意到,列表中的每个域都被独立的威胁情报源标记为恶意域。这说明了本发明能够检测新的威胁,尽管没有明确设计这样做。我们认为这源于最少使用规则和特征的手工设计,从而产生了算法,该算法可以更好地在电信级流量数据的大规模部署中进行推广。
[0225]
因此,我们发现,本发明能够以高效和有效的方式从电信级dns记录流中检测出dga,使用了据我们所知迄今为止还没有其他系统在这种规模上开发过的时间特征。本领域的技术人员可以确定许多其他的变化、替换、变化和修改,并且本发明旨在包括落入所附权利要求范围内的所有这些变化、替换、变化和修改。
[0226]
我们还展示了我们的fsa模块检测和拾取经由代码模拟(通过代码生成的周期性信号)和平台模拟(由实际生成的网络流量组成的周期性信号,这些流量在网络中连接的计算机之间传输,用于真实生活模拟)生成的周期性信号的能力。下表2显示了我们的结果。可以看出,在42个实际信号中,fsa模块能够准确检测到37个信号(准确率为88.1%)。事实上,在12个测试案例中,我们能够获得除1个案例之外的所有案例的所有频率;我们只错过了案例10中的90分钟周期性信号。这相当于92%的准确率。计算每个频率处的信号的数量是更
具挑战性的任务,因为频域中的相移使计算变得复杂。然而,在所有23个正确检测到的频率中,我们能够获得其中18个频率的正确信号数。
[0227]
这是78%的准确率。这个模块对其他网络应用非常有用,尤其是信标。
[0228][0229][0230]
表2。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1