一种非可控环境下的鲁棒中文车牌检测与校正方法
1.本发明属于图像处理领域,具体涉及中文车牌检测、深度学习等技术。
背景技术:
2.车牌号反映了车辆与车主的信息,准确的识别车牌号是智能交通的关键一步,而车牌检测的精确程度则大大影响着车牌识别的准确率。目前,车牌检测与识别已经在一些可控环境下得到了广泛应用,比如停车场、高速收费路口等等。当前绝大多数的车牌检测方法都是采用矩阵框定位,非可控环境下,如果车牌存在严重倾斜或者形变,会导致车牌定位不准确,即定位的车牌区域存在较多的背景或者定位不完整,会对后续的车牌识别造成干扰,影响识别的准确率。
3.xu等人构建了一个轻型网络rpnet,在车牌定位网络的最后一层,通过回归给出车牌的坐标。该方法的检测速度快,但不支持多车牌检测,且输入图像即便没有车牌网络也会输出车牌的位置。
4.silva等人把车牌检测分成两步,先通过采用yolov2(you only look once)检测车辆,接着通过wpod network检测车牌,检测头会输出仿射变换系数,用于后续的车牌校正。该方法能够定位并校正车牌,且能检测多张车牌,但是速度相对较慢。
技术实现要素:
5.针对非可控环境下车牌检测存在的定位不准、速度慢等问题,本发明提出了一种非可控环境下的鲁棒中文车牌检测方法。该方法基于yolov5框架实现,主要包括四个步骤:建立车牌检测数据集、输入图像预处理、网络结构设计以及车牌校正。
6.步骤1:车牌检测数据集的构建
7.卷积神经网络的性能建立在大量的训练数据基础上。为了训练车牌检测网络模型,需要建立车牌数据集。车牌数据集应包含不同环境条件下的车牌图像,以提高检测的鲁棒性。
8.步骤2:输入图像预处理
9.将图像送入网络之前,需要先进行预处理,主要包括两个步骤:
10.(1)输入图像尺寸归一化处理。由于采集设备不同,车牌图像的大小往往不一致,因此需要对输入的车牌图像尺寸进行归一化处理,通过双线性插值等方式调整到统一的大小。
11.(2)输入图像像素值归一化处理。将输入图像中的所有像素值归一化到0~1之间,使网络更容易收敛。
12.步骤3:网络结构设计
13.步骤3.1:网络整体架构
14.本发明设计的中文车牌检测网络建立在yolov5架构基础上。原有的yolov5网络输出的是矩形框车牌,而本发明输出的则是车牌的4个顶点位置坐标。整个车牌检测框架主要
包括两部分,分别是深度特征提取以及车牌坐标位置回归。
15.·
深度特征提取
16.为了保证检测的速度与精度,本发明对yolov5的骨干网络进行了改进。降低了yolov5骨干网络的深度与宽度,即卷积层数与通道数。此外,为了增强骨干网络对特征的提取以及表达能力,本发明将骨干网络中的bn(batch normalization)层替换成了rbn(representative batch normalization)层,rbn能够将各个样本独自的特征与每个批次样本的统计特征结合起来,可以更好地适应数据;另外,将骨干网络的激活函数替换成了acon(activate or not),acon激活函数能够自适应的选择是否激活神经元,可以提升网络的性能;在骨干网络的低层加入了可变形卷积,可变形卷积能够更好地关注特征点周围的区域。
17.·
车牌坐标位置回归
18.本发明对yolov5的检测头做了改进,通过改变检测头的卷积通道数,使得网络能够输出车牌的四个顶点坐标值。即将原本每个锚框的输出元素个数增加了8个,这8个值为车牌的顶点坐标值,通过回归确定车牌的坐标值。
19.步骤4:车牌校正
20.由于车牌可能存在倾斜、扭曲等情况,对车牌进行校正有利于后续的车牌识别。根据检测到的车牌顶点坐标,可通过计算透视变换矩阵对车牌图像进行倾斜校正。
21.与现有的车牌检测方法相比,本发明具有以下明显的优势和效果:
22.1、检测速度快、精度高;
23.2、检测结果为车牌的4个顶点坐标,可以对任意倾斜、长度的车牌进行定位,便于后续的倾斜车牌校正;
24.3、泛化性较强,鲁棒性好,能够应用于各种复杂的非可控场景。
附图说明
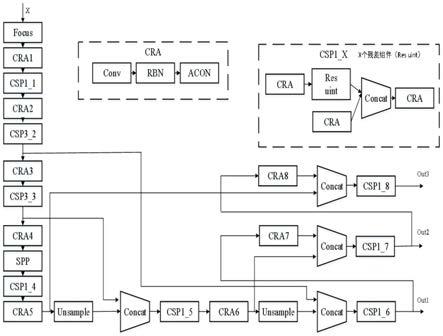
25.图1车牌检测方法整体框图
26.图2骨干网络结构
27.图3车牌校正示例
具体实施方式
28.以下结合附图,详细介绍本发明的具体实施方式。
29.本发明提出的中文车牌检测方法整体框图由输入预处理、深度特征提取、车牌坐标位置回归、车牌校正四部分构成,具体见图1。
30.每个步骤的实现细节如下:
31.步骤1:建立车牌检测数据集
32.本发明采用互联网下载、现场采集、利用已有数据集等方式获取了10万张车牌图像,并对其中的车牌区域进行人工标注,构建了车牌检测数据集,用于训练深度卷积神经网络模型。
33.步骤2:输入车牌预处理
34.步骤2.1:输入图像尺寸归一化处理
35.设定输入图像高为inputh,宽为inputw,图像的实际高度为imgh,实际宽度为imgw,若直接通过下采样等方式调整图像的尺寸,可能会导致图像中的车牌比例发生变化,影响检测的精度,故采用双线性插值加填充的方式调整图像尺寸,保持车牌的横纵比不变。
36.首先,计算尺寸调整因子,计算式如下:
[0037][0038][0039]
式(1)和(2)中,rw表示宽度调整因子,rh表示高度调整因子。
[0040]
然后,通过下式计算双线性插值后的图像尺寸:
[0041][0042][0043]
最后,通过填充的方式将双线性插值后w
′×h′
尺寸的图像调整到inputw×
inputh尺寸。
[0044]
步骤2.2:输入图像像素值归一化处理
[0045]
由于车牌图像每个颜色通道的最大值为255,因此本发明通过公式(5)将像素值归一化到-1~1之间,计算式如下:
[0046][0047]
其中,x
px
为原像素值,为归一化后的值。
[0048]
步骤3:整体网络架构
[0049]
车牌检测网络架构主要分为两部分,分别是深度特征提取以及车牌坐标位置回归。
[0050]
步骤3.1:深度特征提取
[0051]
众所周知,卷积神经网络不同层的特征图尺寸不同,为了适应不同尺寸车牌的检测需求,往往需要在不同层的特征图上进行检测。在本发明中,输入图像经由深度特征提取网络可得到三种尺度的特征图,检测头在这三种尺度特征图上分别进行检测,对三个检测结果进行融合后,得到最后的车牌位置。
[0052]
(1)骨干网络
[0053]
本发明的骨干网络结构如图2所示,结构中每层参数如表1所示。该部分的输入图像尺寸为(b,3,inputh,inputw),其中b为输入到网络中的样本数。csp6_1层、csp7_1层和csp8_1层的特征图尺寸分别为(b,128,inputh/8,inputw/8)、(b,256,inputh/16,inputw/16)和(b,128,inputh/32,inputw/32)。本发明将分别在这些特征图上进行车牌检测,对检测结果融合后,得到最终的车牌位置。
[0054]
表1骨干网络中每层参数
[0055]
网络层核大小输入通道输出通道激活函数标准化填充尺寸步长focus3
×
31232aconrbn11
dcra13
×
33264aconrbn12dcsp1_1-6464aconrbn
‑‑
dcra23
×
364128aconrbn12csp2_3-128128aconrbn
‑‑
cra33
×
3128256aconrbn12csp3_3-256256aconrbn
‑‑
cra43
×
3256512aconrbn12spp-512512aconrbn
‑‑
csp4_1-512512aconrbn
‑‑
cra51
×
1512256aconrbn01unsample
‑‑‑‑‑‑‑
concat
‑‑‑‑‑‑‑
csp5_1-512256aconrbn
‑‑
cra61
×
1256128aconrbn01concat
‑‑‑‑‑‑‑
csp6_1-256128aconrbn
‑‑
cra73
×
3128128aconrbn12concat
‑‑‑‑‑‑‑
csp7_1-256256aconrbn
‑‑
cra83
×
3256256aconrbn12concat
‑‑‑‑‑‑‑
csp8_1-512512aconrbn
‑‑
[0056]
表1中,unsample表示上采样层;concat为特征拼接层;spp(spatial pyramid pooling)为空间金字塔池化层;cra为普通卷积、rbn与acon构成的层,cra后面的数字代表层序号;dcra为可变形卷积、rbn与acon构成的层,dcra后面的数字代表层序号;csp1_1第一个数字表示层序号为1,第二个数字表示该层有1个残差组件,其他同理。dcsp为由可变形卷积构成的csp层。csp1_1中每层参数如表2所示。
[0057]
表2 csp1_1中每层参数
[0058]
网络层核大小输入通道输出通道激活函数标准化填充尺寸步长conv11
×
16432aconrbn01conv21
×
16432aconrbn01conv31
×
16464aconrbn01res uint-3232aconrbn
‑‑
[0059]
表2中,conv为普通卷积,conv后面的数字代表层序号;res uint为残差组件,每层参数如表3所示。
[0060]
表3 csp1_1中,res uint每层参数
[0061]
网络层核大小输入通道输出通道激活函数标准化填充尺寸步长conv11
×
13232aconrbn01conv23
×
33232aconrbn11
[0062]
(2)acon激活函数
[0063]
acon激活函数能够自适应选择是否激活神经元,通过替换原网络的激活函数,可以提升网络的性能。
[0064]
acon系列激活函数最广泛的形式为acon-c,其表达式如下:
[0065]
aconc=(p1-p2)x
·
σ(β(p1-p2)x)+p2x#(6)
[0066]
其中,x为激活函数的输入,σ为sigmoid函数,p1、p2为可学习的参数。
[0067]
β的表达式如下:
[0068][0069]
其中,β也是可学习的参数,c表示输入特征图的通道数,h和w分别表示输入特征图的高和宽。c、h、wd分别表示通道索引、高度索引以及宽度索引。网络训练15轮,取精确率最高的那轮所对应的p1、p2、β值作为p1、p2、β的最终值。
[0070]
(3)rbn
[0071]
bn层能够加速模型的收敛,降低梯度消失、爆炸的可能性。但是它比较依赖样本的均值和方差,忽视了在标准化过程中各个实例的区别。rbn将各个样本独自的特征与每个批次样本的统计特征结合起来,能够更好地适应数据。接下来介绍rbn的算法流程。
[0072]
首先对输入做中心校准:
[0073]
x
cm
=x+wm⊙km
#(8)
[0074]
其中,x为输入特征,x
cm
为中心校准后的特征,wm为可学习变量,km表示各个实例特征,接着做标准化处理:
[0075]
xm=x
cm-e(x
cm
)#(9)
[0076][0077]
其中,xm为x
cm
与x
cm
均值的差,e表示均值,var表示方差,xs是标准化后的特征,∈是一个很小的数,值在0到10-8
之间,用来防止0方差,接下来对xs做缩放校准:
[0078]
x
cs
=xs*r(wv⊙ks
+wb)#(11)
[0079]
其中,
⊙
为点积运算符,r()为受限函数,wv、wb为可学习参数,网络训练15轮,取精确率最高的那轮所对应的wv、wb值作为wv、wb的最终值。x
cs
表示缩放校准后的特征,最后对x
cs
做拉伸和偏移处理:
[0080]
y=γ*x
cs
+β
′
#(12)
[0081]
其中,y为rbn的输出,γ、β
′
为可学习的参数,网络训练15轮,取精确率最高的那轮所对应的γ、β
′
值作为γ、β
′
的最终值。
[0082]
(4)可变形卷积
[0083]
本发明在骨干网络的低层加入了可变形卷积,它能够更好地关注特征点周围的区域,从而提高检测精度。
[0084]
令l表示卷积核的感受野,l内元素个数n为卷积核参数个数,比如l=[(-1,-1),(-1,0),
…
,(0,1),(1,1)]表示3
×
3卷积核的感受野,n值为9。对于特征图的每一个位置p0,有:
[0085][0086]
其中,x为可变形卷积的输入,pn为l中的一个元素,y(p0)为对位置p0采用可变形卷积进行卷积计算的结果,δpn为偏移量,w为卷积核的权重。
[0087]
(5)检测头
[0088]
骨干网络输出三种尺度的特征图,在车牌检测时,采用三个卷积层分别与三种尺度特征图进行卷积运算,然后将三部分的检测结果拼接起来作为最终的检测输出。上述三个卷积层构成了检测头,每层参数如表4所示。此外,将原本每个锚框的输出元素个数增加了8个,这8个值为车牌的顶点坐标值,通过回归确定车牌的坐标值。
[0089]
表4检测头每层参数
[0090]
网络层核大小输入通道输出通道激活函数标准化填充尺寸步长conv13
×
312842
‑‑
11conv23
×
325642
‑‑
11conv33
×
351242
‑‑
11
[0091]
步骤3.2:车牌坐标位置回归
[0092]
车牌坐标的回归表达式如下:
[0093]
x
cd
=((0.5-σ(px
cd
))*4*aw+gridx)*stride#(14)
[0094]ycd
=((0.5-σ(py
cd
))*4*ah+gridy)*stride#(15)
[0095]
式(14)和(15)中,px
cd
,py
cd
为特征点的输出值,σ为sigmoid激活函数,aw为锚框相对于当前特征图的宽,ah为锚框相对于当前特征图的高,gridx、gridy当前特征点的横纵坐标,stride为输入特征图尺寸相对于当前特征图尺寸的倍数。σ(px
cd
)的取值在0到1之间,由于车牌顶点分布在当前特征点的不同方向,偏移量不一定是正数,故用0.5减去激活后的值,使其范围为(-0.5,0.5)。另外,车牌顶点与当前特征点的距离不一定小于0.5,故再将上一步的值乘以4倍的锚框尺寸,最后将车牌在当前特征图的坐标映射到输入图像上。
[0096]
步骤4:车牌校正
[0097]
根据检测到的车牌顶点坐标,可通过计算透视变换矩阵对车牌图像进行倾斜校正,校正公式如下:
[0098][0099]
其中,x
cd
、y
cd
为变换前的坐标,x
′
cd
、y
′
cd
、z
′
cd
为变换后的三维空间坐标,m
ij
(i,j=1,2,3)为透视变换的矩阵参数。
[0100]
通过下式将三维空间坐标转换为二维坐标。
[0101][0102]
x
′
cd
,y
′
cd
为转换后的二维坐标。经过校正后的车牌图像更有利于后续车牌的识别,示例如图3所示。
[0103]
本发明提出的中文车牌检测方法通过引入acon、rbn与可变形卷积,可以提升模型的特征提取能力,改进了检测头并设计了相应的坐标回归公式,能够准确地对任意倾斜的
车牌进行定位,在各种复杂的非可控环境下均能获得理想的检测结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1