一种基于深度学习的微表情特征提取与识别方法与流程
1.本发明涉及图像识别技术领域,具体涉及一种基于深度学习的微表情特征提取与识别方法。
背景技术:
2.微表情是一种自发产生、较为细微的面部表情动作信号。与宏观表情信号不同,微表情不会随主观意志而改变,持续时间大约在1/25到1/5秒内,幅度较小,研究表明微表情可以反映出人们在压抑状态下的潜在真实情绪。由于微表情表现形式与说谎时的心理状态存在极大相关性,微表情识别在国家安全、临床医学、案件侦破、司法审讯等领域具有良好的应用前景。
3.在微表情特征提取方面,现有光流法主要是在亮度恒定、小幅度运动的假定条件下,利用像素在时空域的相关性,计算出光流场中图像运动信息的一种方法。由于光流法结合感兴趣区域(region ofinterest,roi)可以对应面部行为编码系统(facial action coding system,facs)检测出表情动作变化,liu等人提出主方向平均光流(main directional mean optical-flow,mdmo)方法用于微表情特征提取,对不同roi的方向平均电流进行归一化统计,将所得mdmo特征向量通过支持向量机(support vector machine,svm)进行分类识别,可有效降低特征维数。lu等人提出一种基于运动边界直方图融合的特征提取方法,分别在水平和垂直方向计算其微分光流矢量,特征融合后通过loso协议进行验证和评估。以上方法对应用场景要求较为苛刻,需要进行相应修改以提升其泛化能力;另一方面,传统方法对图像序列进行直接光流计算,计算成本较大。
4.在分类模型方面,卷积神经网络可挖掘视觉图像深层特征,在多种图像分类数据集上有非常出色的表现。liong等人提出了一种双加权定向光流方法(bi-woof法),仅使用视频中的峰值帧和起始帧进行特征提取,之后输入到二维cnn进行分类,取得了较好的结果。然而,由于微表情数据库样本数量不足等因素,上述模型存在着过拟合问题,且模型的准确率较低。
5.为此,本发明提出了一种新的基于深度学习的微表情特征提取与识别方法。
技术实现要素:
6.为解决上述问题,本发明提供一种基于深度学习的微表情特征提取与识别方法。
7.本发明提供了如下的技术方案。
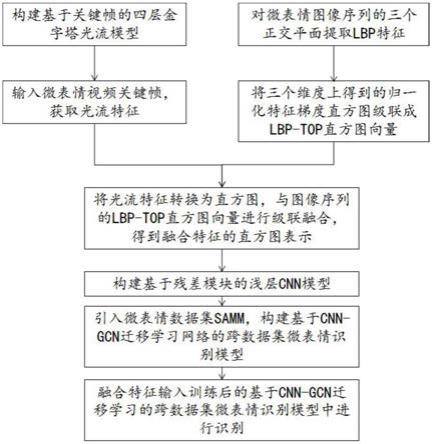
8.一种基于深度学习的微表情特征提取与识别方法,包括以下步骤:
9.构建基于关键帧的四层金字塔光流模型,输入微表情视频关键帧,获取光流特征;
10.对微表情图像序列的三个正交平面提取lbp特征,将三个维度上得到的归一化特征梯度直方图级联成lbp-top直方图向量;
11.将光流特征转换为直方图,与图像序列的lbp-top直方图向量进行级联融合,得到融合特征的直方图表示;
12.构建基于残差模块的浅层cnn模型,引入宏表情数据集和微表情数据集,构建基于cnn-gcn迁移学习网络的跨数据集微表情识别模型;
13.将融合特征输入到训练好的基于cnn-gcn迁移学习网络的跨数据集微表情识别模型中进行分类,获得微表情类型。
14.优选地,所述光流特征的获取,包括以下步骤:
15.对于尺寸为m*n的微表情视频关键帧i,进行下采样操作,用d表示,将视频关键帧i变换为m/2*n/2的新图像;
16.利用扭曲算子扭曲图像,进行双线性插值,采用独立且序列化的方式训练卷积网络;
17.输入新图像,从金字塔最顶层开始,初始化上一层光流场残差为0,与上一层光流场上采样结果相加,将计算所得光流场传递给注意力网络模型,对构建四层残差网络进行重复操作,计算残差,并最终计算出光流场,即获得光流特征;
18.其中,每一层金字塔级的残差光流表示为:
[0019][0020]
式中,{g0,l,gk}表示一组训练好的卷积神经网络模型,vk表示k层光流残差,由模型根据在k层的视频帧和及上一层的光流场上采样的结果u(v
k-1
)进行计算;w、u分别表示对图像执行扭曲和上采样操作,表示扭曲的新图片,由上一层的光流场上采样结果u(v
k-1
)对k层的第二张图片进行扭曲;vk表示第k层的光流场结果,通过上一层的光流场上采样结果u(v
k-1
)和当前层光流残差vk相加后获得,即:
[0021]vk
=u(v
k-1
)+vk。
[0022]
优选地,所述将三个维度上得到的归一化特征梯度直方图级联成lbp-top直方图向量,具体包括:
[0023]
采用均匀编码方式,将微表情图像序列从水平方向x、垂直方向y及时间轴向t三个维度上分为若干个互不重叠的块状结构;
[0024]
分别对微表情图像序列的三个正交平面提取lbp特征;
[0025]
其中,xy平面表示视频帧的空间信息,xt和yt平面分别表示沿时间轴扫描视频序列得到的水平和垂直方向的运动纹理信息,将三个维度上得到的归一化特征梯度直方图级联成lbp-top直方图向量。
[0026]
优选地,所述基于残差模块的浅层cnn模型的构建,包括以下步骤:
[0027]
将特征提取得到的特征数据集划分为训练集、测试集与验证集,以卷积层、池化层、全连接层和dropout层为核心搭建浅层cnn模型。
[0028]
优选地,还包括:
[0029]
利用跳跃的捷径连接模块,将浅层特征x输入至该训练模块的输出,作为初始残差;
[0030]
该训练模块中的深层特征表示为:
[0031]
h(x)=f(x)+x
[0032]
令f(x)无限逼近于0,得到近似恒等映射,通过学习残差函数f(x),将深层特征训练网络分解为多个基于残差结构的浅层多尺度训练模块:
[0033]
f(x)
→
0,h(x)≈x。
[0034]
优选地,所述基于cnn-gcn迁移学习网络的跨数据集微表情识别模型的构建,具体包括:
[0035]
将casme ii特征数据集作为训练集,samm作为测试集,并在宏表情数据集fer2013上进行预训练,利用宏表情定量优势辅助微表情识别,构建基于cnn-gcn迁移学习网络跨数据集微表情识别模型。
[0036]
优选地,所述基于cnn-gcn迁移学习网络的跨数据集微表情识别模型的网络框架包括基于cnn的图像特征训练模块和基于gcn的情感分类模块。
[0037]
优选地,所述将融合特征输入到训练好的基于cnn-gcn迁移学习网络的跨数据集微表情识别模型中进行分类,包括以下步骤:
[0038]
将融合特征输入到训练好的基于cnn-gcn迁移学习网络的跨数据集微表情识别模型中,对cnn学习到的图像特征进行最大池化,得到新的全局特征x:
[0039]
x=g[f
mp
(f
cnn
(ic,w
cnn
))]
[0040]
其中,ic代表输入图像的融合特征表示,w
cnn
表示cnn网络模型中的权值参数,f
cnn
为cnn模型隐含层迭代运算,f
mp
()代表最大池化函数,g()为池化特征的全局计算函数;
[0041]
通过关联不同微表情图像序列中关键人脸动作单元及对应情绪类别,采用gcn训练目标分类器,获得不同类别标签存在的隐藏关联信息;
[0042]
重复迭代当前网络的前置层节点特征作为该层输入,对节点特征进行更新,从而使得目标分类器对标签向量的策略建模,对微表情图像进行分类。
[0043]
本发明的有益效果:
[0044]
本方法首先利用深度学习网络模型对光流提取效果进行提升,结合残差网络思想,将光流速度矢量的近似估计转换为光流残差的策略求解问题,无需实现损失函数最小化,即可获得光流矢量自动更新,提升模型泛化能力;其次采用注意力机制构建基于关键帧的金字塔光流模型,赋予峰值帧更高权重,在提高计算精度的同时降低空间复杂度;进一步,由于所构建的光流模型仅对图像速度矢量进行计算,而忽略了图像序列的帧间运动信息,本方法将三正交平面的局部二值模式(local binary patterns from three orthogonalplanes,lbp-top)特征与光流特征融合得到最终特征表示,提取视频序列的时空纹理特征及光学应变信息,以弥补光流法缺少序列信息描述的不足,同时降低特征维数,减少计算成本。
[0045]
本方法对cnn网络架构进行改进,构建基于cnn-gcn迁移学习网络的微表情跨数据集识别模型,利用图卷积网络gcn的独有优势对图像融合特征和标签向量隐藏联系进行分析,根据基于权重的迁移学习网络思想,将模型在宏表情数据集上进行预训练,利用宏表情数据优势缓解网络模型过拟合问题,同时引入samm微表情数据集,增强数据样本多样性,进一步提升网络识别性能。
附图说明
[0046]
图1是本发明实施例的方法流程图;
[0047]
图2是本发明实施例的基于关键帧的金字塔残差光流特征计算过程示意图;
[0048]
图3是本发明实施例的lbp-top的分块特征提取及三正交平面示意图;
[0049]
图4是本发明实施例的基于光流运动特征与lbp-top特征的微表情识别模型图;
[0050]
图5是本发明实施例的加入残差模块的cnn模型图;
[0051]
图6是本发明实施例的基于cnn-gcn的微表情识别网络框架示意图。
具体实施方式
[0052]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0053]
实施例1
[0054]
本发明的一种基于深度学习的微表情特征提取与识别方法,如图1所示,具体包括以下步骤:
[0055]
s1、构建基于关键帧的四层金字塔光流模型,输入微表情视频关键帧,获取光流特征。具体的:
[0056]
本方法对光流法进行改进,在每层金字塔级训练cnn,对光流矢量进行自动优化更新,逐级细化求解图像运动边界及细节,无需实现损失函数最小化,在实时提高计算精度的同时降低空间复杂度,节省模型所占空间。同时,考虑到微表情的峰值帧包含了绝大多数光学应变信息,本方法在所构建光流模型基础上结合注意力机制,对峰值帧分配更多权重,获得更精准的光流矢量表达。
[0057]
算法描述如下:
[0058]
对于尺寸为m*n的微表情视频关键帧i,进行下采样操作,用d表示,将视频关键帧i变换为m/2*n/2的新图像;
[0059]
利用扭曲算子扭曲图像,进行双线性插值,采用独立且序列化的方式训练卷积网络;
[0060]
输入新图像,从金字塔最顶层开始,初始化上一层光流场残差为0,与上一层光流场上采样结果相加,将计算所得光流场传递给注意力网络模型,对构建四层残差网络进行重复操作,计算残差,并最终计算出光流场,即获得光流特征;
[0061]
其中,每一层金字塔级的残差光流表示为:
[0062][0063]
式中,{g0,l,gk}表示一组训练好的卷积神经网络模型,vk表示第k层光流残差,由模型根据在k层的视频帧和及上一层的光流场上采样的结果u(v
k-1
)进行计算;w、u分别表示对图像执行扭曲和上采样操作,表示扭曲的新图片,由上一层的光流场上采样结果u(v
k-1
)对k层的第二张图片进行扭曲;vk表示第k层的光流场结果,通过上一层的光流场上采样结果u(v
k-1
)和当前层光流残差vk相加后获得,即:
[0064]vk
=u(v
k-1
)+vk。
[0065]
基于关键帧的金字塔残差光流特征计算过程如图2所示。
[0066]
s2、对微表情图像序列的三个正交平面提取lbp特征,将三个维度上得到的归一化特征梯度直方图级联成lbp-top直方图向量。具体的:
[0067]
算法特征提取过程如图3所示,其中图3(a)为lbp-top的分块特征提取,图3(b)为
微表情序列的三个正交平面。
[0068]
在提取lbp-top特征的过程中,直接对图像序列进行运算会导致像素信息缺失,并不能很好地处理运动信息和图像细节,因此需要对微表情序列进行分块。采用均匀编码方式,将图像序列从水平方向x、垂直方向y及时间轴向t三个维度上分为若干个互不重叠的块状结构。分别对微表情图像序列的三个正交平面提取lbp特征,其中xy平面表示视频帧的空间信息,xt和yt平面分别表示沿时间轴扫描视频序列得到的水平和垂直方向的运动纹理信息,将三个维度上得到的归一化特征梯度直方图级联成lbp-top直方图向量,可以有效描述视频帧的时空纹理信息。
[0069]
s3、将光流特征转换为直方图,与图像序列的lbp-top直方图向量进行级联融合,得到融合特征的直方图表示。算法模型如图4所示。
[0070]
s4、构建基于残差模块的浅层cnn模型,基于此,引入宏表情数据集和微表情数据集,构建基于cnn-gcn迁移学习网络的跨数据集微表情识别模型,具体的:
[0071]
s4.1、基于残差模块的浅层cnn模型的构建,包括以下步骤:
[0072]
将特征提取得到的特征数据集划分为训练集、测试集与验证集,以卷积层、池化层、全连接层和dropout层为核心搭建浅层cnn模型。
[0073]
考虑到后续会与gcn结合构建深层网络模型,随着层数增加,网络训练将会变得愈发困难,针对这一问题,本方法对浅层cnn进一步改进,将总体cnn网络架构根据不同特征尺度分为若干个训练模块。
[0074]
利用跳跃的捷径连接模块,将浅层特征x输入至该训练模块的输出,作为初始残差;
[0075]
该训练模块中的深层特征表示为:
[0076]
h(x)=f(x)+x
[0077]
令f(x)无限逼近于0,得到近似恒等映射,通过学习残差函数f(x),将深层特征训练网络分解为多个基于残差结构的浅层多尺度训练模块:
[0078]
f(x)
→
0,h(x)≈x。
[0079]
改进后的模型如图5所示。
[0080]
s4.2、基于cnn-gcn迁移学习网络的跨数据集微表情识别模型的构建,具体包括:
[0081]
将casme ii特征数据集作为训练集,samm作为测试集,并在宏表情数据集fer2013上进行预训练,利用宏表情定量优势辅助微表情识别,构建基于cnn-gcn迁移学习网络跨数据集微表情识别模型。
[0082]
其中,基于cnn-gcn迁移学习网络的跨数据集微表情识别模型的网络框架包括基于cnn的图像特征训练模块和基于gcn的情感分类模块,原理图如图6所示。
[0083]
图6中,c代表数据集中的情绪类别数,f
cnn
表示采用cnn对图片进行特征提取,提取得到的特征维数为d
×h×
w,经过全局最大池化后,维数被降为d,在基于gcn的情感分类模块中,首先根据各个关键区域的人脸动作单元aus组合得到不同类别标签词嵌入向量,gc代表对各个标签向量进行图卷积操作,原始标签的词嵌入向量维数为d,经过特征映射后,标签向量维数变换为d,该维度由cnn中获取的图像特征表示维数决定。
[0084]
s5、将融合特征输入到训练好的基于cnn-gcn迁移学习网络的跨数据集微表情识别模型中进行分类,获得微表情类型。具体的:
[0085]
将融合特征输入到训练好的基于cnn-gcn迁移学习网络的跨数据集微表情识别模型中,对cnn学习到的图像特征进行最大池化,得到新的全局特征x:
[0086]
x=g[f
mp
(f
cnn
(ic,w
cnn
))]
[0087]
其中,ic代表输入图像的融合特征表示,w
cnn
表示cnn网络模型中的权值参数,f
cnn
为cnn模型隐含层迭代运算,f
mp
()代表最大池化函数,g()为池化特征的全局计算函数;
[0088]
通过关联不同微表情图像序列中关键人脸动作单元及对应情绪类别,采用gcn训练目标分类器,获得不同类别标签存在的隐藏关联信息;
[0089]
重复迭代当前网络的前置层节点特征作为该层输入,对节点特征进行更新,从而使得目标分类器对标签向量的策略建模,对微表情图像进行分类。
[0090]
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1