一种基于改进PCANet模型的铣刀磨损预测方法
一种基于改进pcanet模型的铣刀磨损预测方法
技术领域
1.本发明属于刀具状态监测相关技术领域,更具体地,涉及一种基于改进pcanet模型的铣刀磨损预测方法。
背景技术:
2.铣削加工是一种常用的机加工方式,加工过程中铣刀的健康状态直接影响工件的加工质量和加工效率。因此,实时的刀具状态监测已经成为当前学界和业界关注的焦点。近年来,国内外诸多学者将以卷积神经网络(cnn)为代表的深度学习算法应用于刀具状态监测中,通过对加工过程中主轴振动、切削力、电流及声发射等相关信号的全面深入分析,搭建并训练了不同的网络模型,继而实现对当前刀具的磨损情况较为准确的预测。但是这些模型的特征自学习过程可解释性较差,相同参数下同一模型的预测结果差异较大,因此难以大规模推广应用。
3.作为一种新颖的cnn模型变种,主成分分析模型(pcanet)通过构造滑动窗口选取特征图局部信息,然后采用主成分分析(pca)确定卷积核参数,最后借助卷积操作实现特征自监督学习。基于pcanet的特征自提取过程明晰,可解释性强,识别准确率较高,近年来在图像识别领域中的相关应用已经引起了广泛关注。但目前将pcanet应用于工业现场仍处于前期探索阶段,且原始的pcanet结构也存在诸多不足,如模型主要采用线性运算单元,导致其泛化性能有限,难以分析非线性复杂信号;另外,输出层采用哈希编码和直方图处理,输出特征的冗余成分较多,致使后续状态识别过程计算量较大,对识别算法的泛化能力也有较高的要求。
技术实现要素:
4.针对现有技术的以上缺陷或改进需求,本发明提供了一种基于改进pcanet模型的铣刀磨损预测方法,所述预测方法具有一定的可解释性,通过对现有pcanet模型的结构进行改进,包括引入tanh激活函数以及采用最大池化层替代哈希编码和直方图处理,并应用支持向量回归模型(svr)来预测刀具磨损值。与现有技术相比,该方法能够有效解决现有基于深度学习的刀具状态监测模型所面临的可解释性较差、泛化能力局限等问题,大大地缩减了模型输出的参数规模,有效提高了模型的预测精度。
5.为实现上述目的,按照本发明的一个方面,提供了一种基于改进pcanet模型的铣刀磨损预测方法,所述预测方法主要包括以下步骤:
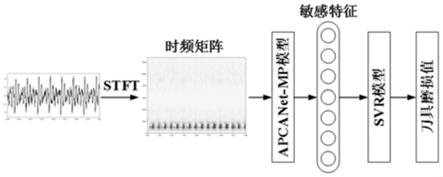
6.(1)将铣削加工过程中的信号数据组成的训练集输入到改进pcanet模型,以对pcanet模型进行训练;其中,改进pcanet模型分为apcanet-mp模型和svr模型两个部分,apcanet-mp模型又分为三个阶段,第一阶段和第二阶段的数据处理方式完全一致,都包括预处理层、pca卷积层和激活层;后处理阶段包括最大池化层和输出层;svr模型采用linear核函数;
7.(2)应用评价指标对训练后的改进pcanet模型进行评估,根据评估结果对改进
pcanet模型的结构参数进行优化;
8.(3)将待预测磨损的铣刀的信号数据输入优化后的改进pcanet模型,以进行铣刀磨损预测。
9.进一步地,svr模型对应的正则化参数c采用默认值1。
10.进一步地,apcanet-mp模型用于自适应提取数据特征;svr模型用于根据筛选出的敏感特征进行铣刀磨损量的预测。
11.进一步地,第一阶段及第二阶段均用于从输入的样本数据中自适应习得敏感特征;后处理阶段用于筛选敏感特征以供后续的铣刀磨损预测。
12.进一步地,第一阶段的预处理层中,输入数据为stft得到的时频矩阵,对于输入的训练样本集y=[y1,y2,
…
,yn]中的第p个样本n为样本数量,p=1,2,
…
,n;k表示特征图的边长,首先采用cnn网络卷积层中滑窗的方式处理y
p
;然后对y
p
中的每个样本都分别去均值,得到每个样本的均值为对应的m2个像素点的均值;对训练样本集y中的每一个样本进行相同的操作,得到去均值后的样本集
[0013]
进一步地,后续的pca卷积层首先借助pca变换计算去均值后的样本集对应的卷积核,然后再将卷积核与原始样本进行卷积操作,从而突出原始样本中隐藏的敏感特征信息。
[0014]
进一步地,设第一阶段中pca滤波器数量为l1,第r个pca滤波器滤波后获取的卷积核w
r1
的计算公式为:
[0015][0016]
其中,vec2mat函数用于将特征向量映射到卷积核;qr函数用于计算目标变量的第r个主成分对应的特征向量;
[0017]
然后,将得到的卷积核与原始输入样本按下式进行卷积运算:
[0018][0019]
其中,代表第一阶段pca卷积层的输出结果;*代表卷积运算;
[0020]
最后,经过激活层后即可获得第一阶段的输出值
[0021][0022]
其中,f
active
代表激活函数。
[0023]
进一步地,步骤(2)中,根据前期预实验结果来确定模型中参数的取值范围,再采用节点搜索法设计参数优化实验,最后应用回归评价指标均方根误差rmse和决定系数r2分别对不同参数组合的训练后模型进行定量评估,根据评估结果确定最优的模型结构参数组合,继而对改进pcanet模型的参数进行优化。
[0024]
进一步地,后处理阶段中,最大池化层采用滑窗的方式对目标特征图按照特定的操作取值,操作过程f
max_pooling
采用的公式为:
[0025]fmax_pooling
(y
wp
)=max{ym×
m,2
}
[0026]
其中,y
wp
代表待池化的特征图;ym×
m,2
代表通过滑窗选取的特征矩阵集合,滑窗尺寸为m
×
m,步长为2;max函数对集合中的每一个矩阵分别取最大值。
[0027]
进一步地,pca卷积层的滤波器数量lf为8,滤波器尺寸m为3;评价指标采用均方根误差rmse和决定系数r2,对应的计算公式分别为:
[0028][0029][0030]
其中,m代表样本的数量;s代表样本的序号;w=[w1,w2,
…
,wm]代表刀具真实磨损值;对应的代表刀具预测磨损值;代表刀具真实磨损值的均值。
[0031]
总体而言,通过本发明所构思的以上技术方案与现有技术相比,本发明提供的基于改进pcanet模型的铣刀磨损预测方法主要包括以下步骤:
[0032]
1.本发明所提供的基于改进pcanet模型的铣刀磨损预测方法,相较于传统的以cnn为代表的深度学习模型以及pcanet模型而言,在保证模型的可解释性和泛化能力的情况下,特征自提取过程的预测性能都得到了较大的提升。由于模型中引入了tanh激活函数,使其能够习得目标样本中所隐藏的非线性特征,极大地提升了模型的泛化能力;此外,模型中还应用了最大池化层,模型输出参数的规模大大缩减,有效提高了模型的分析计算效率。
[0033]
2.本发明涉及到算法结构,通过改变模型的输入与输出数据,经过重新训练和优化,该模型结构可以应用于其他诸多场合,包括基于图像的模式识别、回归预测等,因此本发明具备良好的通用性。
[0034]
3.滤波器数量设为8,以使得预测性能最大,少的话预测精度低,多的话则导致过拟合程度越来越深。
[0035]
4.滤波器尺寸m应为3,当m大于3时,模型的预测结果与真实值偏离越来越远,rmse逐渐增加而r2逐渐减小;而当m等于2时,模型的预测结果并没有达到最优。
[0036]
5.后处理阶段中,最大池化层采用滑窗的方式对目标特征图按照特定的操作取值,从而在不引入额外参数的情况下完成对输入特征图的尺寸压缩,大幅减低了模型的复杂度,加快了模型的收敛速度。
附图说明
[0037]
图1是本发明中铣削过程实验平台的示意图;
[0038]
图2是本发明中改进pcanet模型算法架构的示意图;
[0039]
图3是本发明中apcanet-mp模型的结构图;
[0040]
图4是本发明中基于不同模型的刀具磨损预测值与真实值对比图。
具体实施方式
[0041]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对
本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0042]
本发明提供的一种基于改进pcanet模型的铣刀磨损预测方法,所述预测方法主要包括以下步骤:
[0043]
步骤一,采集铣削加工过程中的信号,并对信号进行预处理。
[0044]
以铣削加工过程中主轴振动信号为主要分析对象。本实施方式中,考虑到深度学习模型一般对训练样本的规模有较高的要求,采用平均数据扩充算法,通过从较长的原始信号序列中均匀截取若干段长度较小的信号段用于后续分析,这样就能够有效扩充样本量,确保模型能够顺利拟合。假定原始信号长度为l,拟待分析信号段的长度为l,拟扩充的样本倍数为n,为确保扩充后的信号没有重叠部分干扰实验,需要满足l≥nl。此时,扩充后第i个样本的起始点位置ai满足下式:
[0045]ai
=(i-1)l,i=1,2,
…
,n
[0046]
由于加工过程中主轴振动信号往往处于非平稳状态,而时频分析在处理非平稳信号方面具有优势,故采用常见的时频分析方法——短时傅里叶变换(stft)对信号进行预处理。具体地,首先对非平稳信号添加小窗,由于小窗的尺度往往较小,可以认为小窗范围内的信号处于平稳状态;然后用傅里叶变换获取其频域信息;再通过滑动小窗,就可以同时获取待分析信号中隐藏的时域信息和频域信息。对于待分析信号x(t),其stft的结果x(f,u)按下式进行计算:
[0047][0048]
其中,ω代表窗函数;f代表频率,单位为hz;u代表小窗滑动的时间,单位为s;t代表时间,单位为s;j代表虚数单位,j2=-1。此外,信号经stft后得到的时频矩阵中时域信息分辨率δt和频域信息分辨率δf满足heisenberg不确定性原理,而时间窗长度a决定了δt和δf。
[0049]
在另一个实施方式中,为获取实验加工数据,基于tc-500机床搭建了实验平台,示意图如图1所示,并开展了一系列的铣削实验。刀具选用株洲钻石牌zcc-ct pml-4e-d6直柄四刃立铣刀,毛坯件材料为难加工不锈钢,牌号为gb s31608,横截面尺寸为100mm
×
100mm。加工过程中主轴转速设置为6000rpm,切削宽度设置为2.0mm,切削深度设置为0.6mm,进给率设置为1500mm/min。采用顺铣的方式加工零件,走刀方式为“zig”,去程加工,回程空转。实验重复开展3次,每次实验需加工100层平面。每加工5层平面使用keyence vhx-700f超景深显微镜测量一次铣刀四个刃的磨损值,并将其最大值视为当前刀具磨损值,再采用线性插值法确定加工中间平面时刀具磨损值。加速度传感器为dytran 3263a2,采集卡为ni9234,采样频率为25600hz。对应保存加工中间平面和最后一个平面时的z向振动信号。由于毛坯件尺寸难以控制,边缘毛刺较多,加工过程不稳定;而在每个毛坯件加工平面的最后几个去程中,由于毛坯侧壁较薄,加工过程也不稳定,因此,只选取第5个去程到第45个去程之间的振动信号用于后续的刀具磨损量预测。
[0050]
每次去程加工过程中要经历进刀、持续加工和退刀三个阶段,其中只有持续加工过程中信号较为平稳。因此只截取该部分信号较为稳定的部分用于后续分析,信号段长度
为80000。为了确保样本规模,采用从较长的原始信号中等间距采样获取较短的待分析样本的方法扩充样本量,按照前期实验经验,每个待分析样本长度设置为2048,每个原始信号都将通过上述方法获取10个待分析样本。扩充后第i个样本的起始点位置ai满足下式:
[0051]ai
=2048(i-1),i=1,2,
…
,10
[0052]
同时,将后两次加工过程中的数据设定为训练集,第一次加工过程中的数据设定为测试集。此时,训练集样本数为32000,测试集样本数为16000。
[0053]
对各样本集中的振动信号采用stft,可以同时获取数据的时域信息和频域信息。对于待分析信号x(t),其stft的结果x(f,u)按下式进行计算:
[0054][0055]
其中,ω代表窗函数,本实施例采用海宁窗(hann);f代表频率,单位为hz;u代表小窗滑动的时间,单位为s;t代表时间,单位为s;j代表虚数单位,j2=-1。此外,信号经stft后得到的时频矩阵中时域信息分辨率δt和频域信息分辨率δf满足heisenberg不确定性原理,而时间窗长度a能够决定δt和δf。因此,考虑到前期实验结果,时间窗长度a取64,得到的时频矩阵的边长为33。
[0056]
步骤二,将预处理后的训练集数据输入改进pcanet模型,以对pcanet模型进行训练。
[0057]
改进pcanet模型分为apcanet-mp模型(activated-pca network with max-pooling)和svr两个部分,前者自适应提取数据特征,后者根据筛选出的敏感特征进行铣刀磨损量的预测,算法架构如图2所示。其中apcanet-mp模型又分为三个阶段,第一阶段和第二阶段的数据处理方式完全一致,都包括预处理层、pca卷积层和激活层,主要用于从输入的样本数据中尽可能自适应习得敏感特征。后处理阶段包括最大池化层和输出层,主要用于筛选敏感特征以供后续的铣刀磨损预测。apcanet-mp模型结构如图3所示。
[0058]
第一阶段的预处理层中,输入数据为stft得到的时频矩阵(即特征图)。对于输入的训练样本集y=[y1,y2,
…
,yn](n为样本数量,如为32000)中的第p个样本(p=1,2,
…
,n;k表示特征图的边长),首先采用cnn网络卷积层中滑窗的方式处理y
p
。假定滑窗尺寸为m
×
m,步长为1。为了尽可能防止分析过程中丢失样本信息,并保证样本所有信息都能够同等分析,滑窗操作时需要在特征图四周补0。当m为奇数时,填补的长度设置为当m为偶数时,在特征图左端和上端填补长度设置为而在右端和下端填补长度设置为经过滑窗操作后,获得y
p
对应的滑窗样本集合k2为1089,然后对y
p
中的每个样本都分别去均值,得到每个样本的均值为对应的m2个像素点的均值。对训练样本集y中的每一个样本进行相同的操作,得到去均值后的样本集
[0059]
后续的pca卷积层首先借助pca变换计算去均值后的样本集对应的卷积核,然后再将卷积核与原始样本进行卷积操作,从而突出原始样本中隐藏的敏感特征信息。假定第一阶段中pca滤波器数量为l1,第r个pca滤波器滤波后获取的卷积核w
r1
按下式计算:
[0060][0061]
其中,vec2mat函数用于将特征向量映射到卷积核;qr函数用于计算目标变量的第r个主成分对应的特征向量。
[0062]
然后,将得到的卷积核与原始输入样本按下式进行卷积运算:
[0063][0064]
其中,代表第一阶段pca卷积层的输出结果;*代表卷积运算。
[0065]
在另一个实施方式中:
[0066][0067]
最后,经过激活层后即可获得第一阶段的输出值
[0068][0069]
其中,f
active
代表激活函数。考虑到去均值操作后特征的均值将会接近于0,故采用tanh激活函数,此时各像素点输出值主要分布在(-1,1)。在另一个实施方式中:
[0070][0071]
由于第二阶段的计算过程与第一阶段完全一致,假定第二阶段pca滤波器数量为l2,第二阶段的最终输出值为:
[0072][0073]
其中,代表第一阶段输出结果中的第p1个元素;代表第二阶段第r1个pca滤波器滤波后获取的卷积核。
[0074]
后处理阶段中,最大池化层采用滑窗的方式对目标特征图按照特定的操作取值,从而在不引入额外参数的情况下完成对输入特征图的尺寸压缩,大幅减低了模型的复杂度,加快了模型的收敛速度。具体操作过程f
max_pooling
按下式进行:
[0075]fmax_pooling
(y
wp
)=max{ym×
m,2
}
[0076]
其中,y
wp
代表待池化的特征图;ym×
m,2
代表通过滑窗选取的特征矩阵集合,滑窗尺寸为m
×
m(与预处理层中的滑窗尺寸保持一致),步长为2;max函数对集合中的每一个矩阵分别取最大值。最大池化层能够保证池化后的特征保持平移不变性,进一步凸显局部纹理特征。
[0077]
因此,对于待分析的特征图集合经过最大池化后得到的输出y
out
按下式获得:
[0078][0079]
其中,k1代表池化后输出特征图的尺寸。
[0080]
最后,为了便于后续预测铣刀磨损情况,在输出层中需要分别将原始训练样本集中的每个样本对应的高维特征(l1l2个特征图)直接拉平为向量。
[0081]
另外,svr模型采用linear核函数,正则化参数c采用默认值1,其他参数也按照默认设置。
[0082]
步骤三,应用评价指标对训练后的模型进行评估,根据评估结果对改进pcanet模型的结构参数进行优化。
[0083]
具体地,根据前期预实验结果,确定模型中参数的取值范围,再采用节点搜索法设计参数优化实验,最后应用回归评价指标均方根误差rmse和决定系数r2分别对不同参数组合的训练后模型进行定量评估,根据评估结果确定最优的模型结构参数组合。
[0084]
本实施方式中,采用回归评价指标均方根误差rmse和决定系数r2来定量评价模型的预测性能,计算方式如下所示:
[0085][0086][0087]
其中,m代表样本的数量;s代表样本的序号;w=[w1,w2,
…
,wm]代表刀具真实磨损值;对应的代表刀具预测磨损值;代表刀具真实磨损值的均值。显然,模型预测效果越好,rmse值越小,而r2值越大。同时,为了尽可能降低随机误差影响,每组模型重复运行5次,取评价指标的均值作为模型预测性能的最终评估结果,同时考虑预估结果的方差σ。
[0088]
在另一个实施方式中,待优化的模型结构参数主要包括滑窗/pca滤波器尺寸m与pca卷积层的滤波器数量l1、l2,为方便起见,取l1=l2=lf,其他参数按默认设置。训练后模型的回归评价指标均方根误差rmse和决定系数r2按下式进行计算:
[0089][0090][0091]
其中,m代表样本的数量(训练集m=32000,测试集m=16000);s代表样本的序号;w=[w1,w2,
…
,w
32000
]代表刀具真实磨损值;对应的代表刀具预测磨损值;代表刀具真实磨损值的均值。显然,模型预测效果越好,rmse值越小,而r2值越
大。同时,为了尽可能降低随机误差影响,每组模型重复运行5次,取评价指标的均值作为模型预测性能的最终评估结果,同时考虑预估结果的标准差σ。
[0092]
滤波器数量lf决定了特征自学习的深度。根据前期预实验结果,lf的取值范围为[4,8,12,16]。为了进一步确定最佳的滤波器数量lf,故设计了对比实验。滤波器尺寸m暂定为3,实验结果如表1所示。
[0093]
表1不同滤波器数量l下模型预测性能
[0094][0095]
由表1可知,当滤波器数量lf低于8时,rmse随lf的增加而减小,r2随lf的增加而增加,模型预测精度也越来越高;但是当滤波器数量lf大于8时,模型的过拟合程度开始越来越深,rmse随lf的增加而增加,r2随lf的增加而减小。因此,滤波器数量lf应设为8,此时模型预测性能最优。
[0096]
与此同时,滤波器尺寸m决定了特征自学习的宽度,从而影响模型特征自学习的结果。由于m必须大于1,根据经验,m取值范围为[2,3,5,7,9],故设计对比实验以确定滤波器尺寸m的最佳值。实验结果如表2所示。
[0097]
表2不同滤波器尺寸m下模型预测性能
[0098][0099]
由表2易知,当m大于3时,模型的预测结果与真实值偏离越来越远,rmse逐渐增加而r2逐渐减小;而当m等于2时,模型的预测结果并没有达到最优。因此,最佳的滤波器尺寸m应为3。
[0100]
步骤四,将待预测磨损的铣刀的信号数据输入优化后的模型,以进行铣刀磨损预测。
[0101]
将测试集数据输入采用了训练优化后的模型进行测试,并应用评价指标rmse与r2评估模型的预测性能。为了验证改进pcanet模型在铣刀磨损预测性能方面的提升,引入mfb-dcnn、pcanet-svr和多层感知机(mlp)等深度学习模型以及pca-svr等传统机器学习模
型来进行对比实验,分析不同模型预测结果的rmse和r2的均值和标准差。其中,mfb-dcnn模型按照原始模型默认结构参数设定;pcanet-svr模型中,采用原始的模型结构pcanet用于特征自学习,再引入svr模型用于刀具磨损值预测,滤波器数量、滤波器尺寸和模型其他参数设置与改进pcanet模型保持一致;mlp模型为4层全连接结构,节点数按照经验设置,分别为1089、64、8和1;pca-svr模型中,pca降维时保留95%的主成分,svr设置与改进pcanet模型保持一致。所有算法均采用python3.6及其相关库函数实现,其中神经网络模型均采用pytorch实现,svr模型采用scikit-learn实现。服务器配置为两个intel(r)xeon(tm)e5 2640v4处理器,128g ddr4 ecc内存,系统为ubuntu 16.04lts。实验结果如表3所示。
[0102]
表3不同模型预测性能对比
[0103][0104]
从表3中不难看出,深度学习模型的泛化能力较强,模型的预测性能明显优于传统机器学习模型。而改进pcanet模型的预测性能相较传统的深度学习模型以及原始pcanet模型而言又有了一定的提升。
[0105]
为了进一步地了解模型对于铣刀磨损值的预测情况,分析了不同模型刀具磨损预测值与真实值之间的差距。根据表3的结果,选取改进pcanet模型、pcanet-svr和mfb-dcnn模型进行分析,结果如图4所示。分析图4可知,在刀具轻度磨损阶段,apcanet-mp-svr模型和mfb-dcnn模型都能够较为准确的预测出刀具磨损值,pcanet-svr模型预测结果与真实值差距较大;刀具进入中度磨损阶段后,三种模型的预测结果都与真实值差距较小;而当刀具磨损较为严重后,apcanet-mp-svr模型预测的刀具磨损值与真实值更为接近,mfb-dcnn模型和pcanet-svr模型仅能大致预测出刀具磨损趋势,二者的预测结果与真实值都差距较大。由此可见,本发明提出的改进pcanet模型能够更为准确地预测出刀具劣化趋势。由于其自身结构的可解释性较好,该模型具有更广阔的应用前景。
[0106]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1